目录
一、DMA
(一)理解DMA,一个协处理器
(二) Kafka 的实现原理
二、数据的完整性
(一)单比特翻转:软件解决不了的硬件错误
(二)海明码
1、海明码的纠错原理
2、海明距离
一、DMA
无论 I/O 速度如何提升,比起 CPU,总还是太慢。如果对 I/O 的操作,都是由 CPU 发出对应的指令,然后等待 I/O 设备完成操作之后返回,那 CPU 有大量的时间都是在等待 I/O 设备完成操作。
然而对 I/O 设备的大量操作,其实都只是把内存里面的数据,传输到 I/O 设备而已。在这种情况下, CPU 只是在傻等。特别是当传输的数据量比较大的时候,比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。
因此,计算机工程师们,就发明了 DMA 技术,也就是直接内存访问(Direct Memory Access)技术,来减少 CPU 等待的时间。
(一)理解DMA,一个协处理器
DMA 技术本质上就是在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor),协助”CPU,完成对应的数据传输工作。
DMAC 最有价值的应用是,要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
比如说,用千兆网卡或者硬盘传输大量数据的时候,如果都用 CPU 来搬运的话,肯定忙不过来,所以可以选择 DMAC。而当数据传输很慢的时候,DMAC 可以等数据到齐了,再发送信号,给到 CPU 去处理,而不是让 CPU 在那里忙等待。
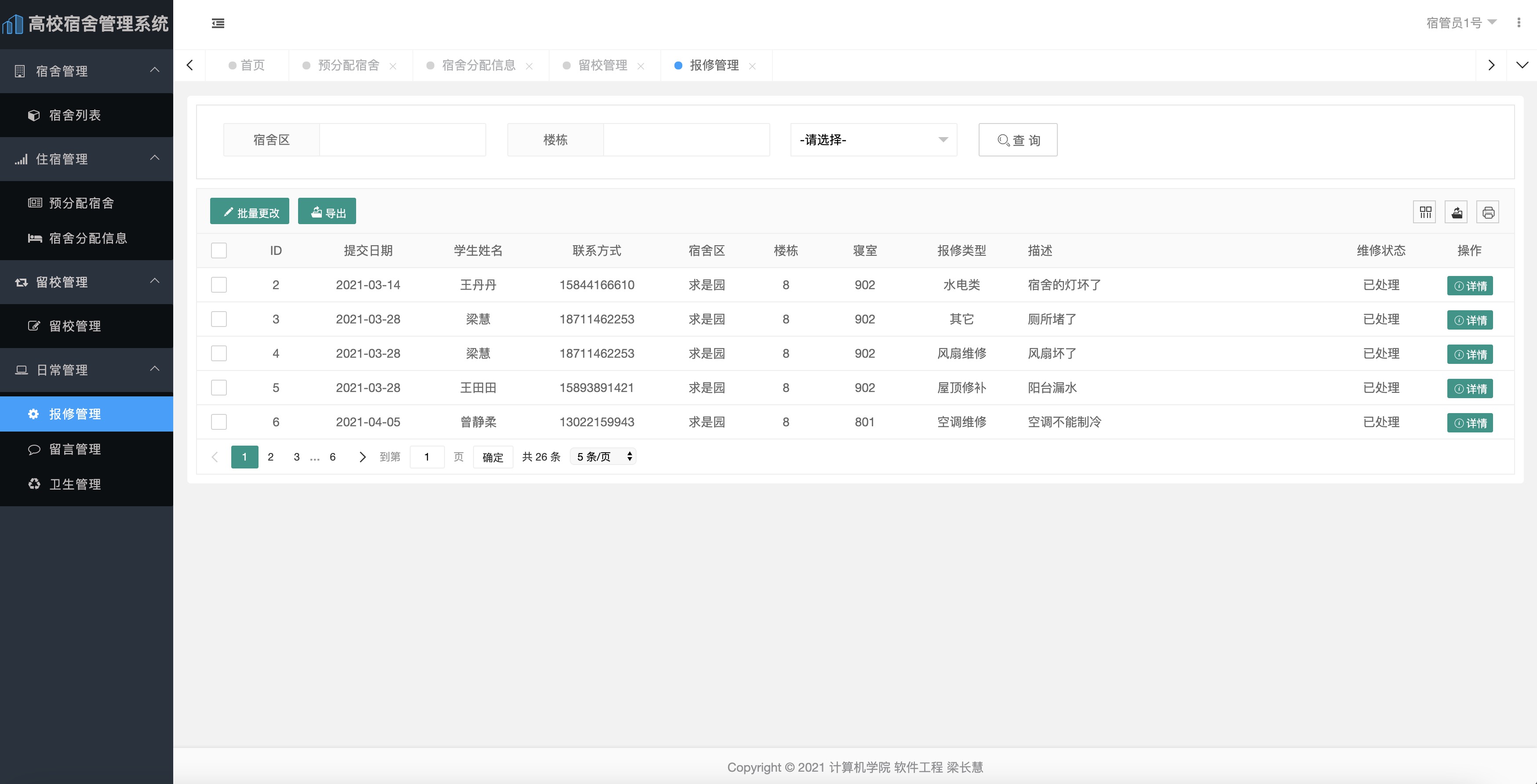
DMAC 是一个特殊的 I/O 设备,它和 CPU 以及其他 I/O 设备一样,通过连接到总线来进行实际的数据传输。总线上的设备有两种:一种是主设备(Master),另外一种,是从设备(Slave)。
想要主动发起数据传输,必须要是一个主设备才可以,CPU 就是主设备。从设备(比如硬盘)只能接受数据传输。所以,如果通过 CPU 来传输数据,要么是 CPU 从 I/O 设备读数据,要么是 CPU 向 I/O 设备写数据。
I/O 设备可以向主设备发起请求,不过发送的不是数据内容,而是控制信号。I/O 设备可以告诉 CPU,我这里有数据要传输给你,但是实际数据是 CPU 拉走的,而不是 I/O 设备推给 CPU 的。
DMAC 就不一样了,对 CPU 来说,它是一个从设备;对于硬盘这样的 IO 设备来说,它又变成了一个主设备。那使用 DMAC 进行数据传输的过程究竟是什么样的呢?
1、CPU 作为一个主设备,向 DMAC 设备发起请求,其实就是在 DMAC 里面修改配置寄存器。
2、CPU 修改 DMAC 的配置的时候,会告诉 DMAC 这样几个信息:
- 源地址的初始值以及传输时候的地址增减方式(大的地址向小的地址传输,还是从小的地址往大的地址传输)。
- 目标地址初始值和传输时候的地址增减方式。
- 要传输的数据长度。
3、设置完信息,DMAC 变成一个空闲的状态(Idle)。
4、如果要从硬盘上往内存里加载数据,硬盘就会向 DMAC 发起一个数据传输请求。这个请求不是通过总线,而是通过一个额外的连线。
5. DMAC 需要再通过一个额外的连线响应申请。
6、DMAC芯片,向硬盘的接口发起要总线读的传输请求。数据硬盘里面,读到了 DMAC 的控制器里面。
7、DMAC向内存发起总线写的数据传输请求,把数据写入到内存里面。
8、DMAC 反复进行上面第 6、7 步的操作,直到 DMAC 的寄存器里面设置的数据长度传输完成。
9、 数据传输完成之后,DMAC 重新回到第 3 步的空闲状态。
整个数据传输的过程中,不是通过 CPU 来搬运数据,而是由 DMAC 这个芯片来搬运数据。但是 CPU 在这个过程中也是必不可少的。因为传输什么数据,从哪里传输到哪里,其实还是由 CPU 来设置的。所以,DMAC 被叫作“协处理器”。
最早,计算机里是没有 DMAC 的,所有数据都是由 CPU 来搬运的。随着人们数据传输的需求越来越大,先是出现了主板上独立的 DMAC 控制器。到了今天,各种 I/O 设备越来越多,数据传输的需求越来越复杂,使用的场景各不相同。加之显示器、网卡、硬盘对于数据传输的需求都不一样,所以各个设备里面都有自己的 DMAC 芯片了。
(二) Kafka 的实现原理
Kafka是一个用来处理实时数据的管道,我们常常用它来做一个消息队列,或者用来收集和落地海量的日志。作为一个处理实时数据和日志的管道,瓶颈自然也在 I/O 层面。Kafka很好地利用了 DMA 的数据传输方式,通过 DMA 的方式实现了非常大的性能提升。
Kafka 里面会有两种常见的海量数据传输的情况:一种是从网络中接收上游的数据,然后需要落地到本地的磁盘上,确保数据不丢失。另一种是从本地磁盘上读取出来,通过网络发送出去。
从磁盘读数据发送到网络上去,最直观的办法自然是用一个文件读操作,从磁盘上把数据读到内存里面来,然后再用一个 Socket,把这些数据发送到网络上去。这个过程中,数据一共发生了四次传输。其中两次是 DMA 的传输,另外两次,则是通过 CPU 控制的传输。
- 第一次传输,从硬盘上读到操作系统内核的缓冲区里。通过 DMA 搬运的。
- 第二次传输,把内核缓冲区里面的数据复制到应用分配的内存里面。通过 CPU 搬运的。
- 第三次传输,从应用的内存里写到操作系统的 Socket 的缓冲区里面去。是由 CPU 搬运的。
- 最后一次传输,需要从 Socket 的缓冲区里写到网卡的缓冲区里面去。通过 DMA 搬运的。
事实上,Kafka 做的事情是,把这个数据搬运的次数,从上面的四次,变成了两次,并且只有 DMA 来进行数据搬运,而不需要 CPU。
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}Kafka 的代码调用了 Java NIO 库,具体是 FileChannel 里面的 transferTo 方法。数据并没有读到中间的应用内存里面,而是直接通过 Channel,写入到对应的网络设备里。并且,对于 Socket 的操作,也不是写入到 Socket 的 Buffer 里面,而是直接根据描述符(Descriptor)写入到网卡的缓冲区里面。于是,在这个过程之中,只进行了两次数据传输。
这个方法里面,没有在内存层面去“复制(Copy)”数据,所以这个方法,也被称之为零拷贝(Zero-Copy)。
二、数据的完整性
(一)单比特翻转:软件解决不了的硬件错误
单比特翻转(Single-Bit Flip)
内存里面的单比特翻转或者错误,并不是一个特别罕见的现象。无论是因为内存的制造质量造成的漏电,还是外部的射线,都有一定的概率会造成单比特错误。不管是硬盘还是内存,都存在普通版和企业版,普通版硬件会更可能出现问题。而内存层面的数据出错,软件工程师并不知道,而且这个出错很有可能是随机的。遇上随机出现难以重现的错误,大家肯定受不了。我们必须要有一个办法,避免这个问题。
ECC 内存的全称是 Error-Correcting Code memory,中文名字叫作纠错内存。顾名思义,就是在内存里面出现错误的时候,能够自己纠正过来。
在 ECC 内存发明之前,工程师们通过奇偶校验的方式,来发现这些错误。
奇偶校验的思路很简单:把内存里面的 N 位比特当成是一组。常见的,比如 8 位就是一个字节。然后,用额外的一位去记录,这 8 个比特里面有奇数个 1 还是偶数个 1。如果是奇数个 1,那额外的一位就记录为 1;如果是偶数个 1,那额外的一位就记录成 0。那额外的一位,就称之为校验码位。
如果在这个字节里面,不幸发生了单比特翻转,那么数据位计算得到的校验码,就和实际校验位里面的数据不一样。我们的内存就知道出错了。
校验位有一个很大的优点,就是计算非常快,往往只需要遍历一遍需要校验的数据,通过一个 O(N) 的时间复杂度的算法,就能把校验结果计算出来。
校验码的思路,在很多地方都会用到。比如,我们下载一些软件的时候,你会看到,除了下载的包文件,还会有对应的 MD5 这样的哈希值或者循环冗余编码(CRC)的校验文件。当我们把对应的软件下载下来之后,可以计算一下对应软件的校验码,和官方提供的校验码去做个比对,看看是不是一样。如果不一样,你就不能轻易去安装这个软件了。因为有可能,这个软件包是坏的。但是,还有一种更危险的情况,就是你下载的这个软件包,可能是被人植入了后门的。安装上了之后,你的计算机的安全性就没有保障了。
使用奇偶校验,有两个比较大的缺陷:
- 奇偶校验只能发现奇数个位的错误。
- 只能发现错误,不能纠正错误。即使在内存里面发现数据错误了,也只能中止程序,而不能让程序继续正常地运行下去。
所以,我们需要一个比简单的校验码更好的解决方案,一个能够发现更多位的错误,并且能够把这些错误纠正过来的解决方案,也就是ECC 内存所使用的解决方案。
这个策略,叫作纠错码(Error Correcting Code)。纠错码需要更多的冗余信息,通过这些冗余信息,我们不仅可以知道哪里的数据错了,还能直接把数据给改对。它还有一个升级版本,叫作纠删码(Erasure Code),不仅能够纠正错误,还能够在错误不能纠正的时候,直接把数据删除。无论是我们的 ECC 内存,还是网络传输,乃至硬盘的 RAID,其实都利用了纠错码和纠删码的相关技术。
(二)海明码
最知名的纠错码就是海明码。海明码(Hamming Code)是以他的发明人 Richard Hamming(理查德·海明)的名字命名的。这个编码方式早在上世纪四十年代就被发明出来了。而直到今天,我们使用的 ECC 内存,也还在通过海明码来纠错。
最基础的海明码叫 7-4 海明码。这里的“7”指的是实际有效的数据,一共是 7 位(Bit),“4”,指的是额外存储了 4 位数据,用来纠错。纠错码的纠错能力是有限的。事实上,在 7-4 海明码里面,只能纠正某 1 位的错误。
4 位的校验码,一共可以表示 2^4 = 16 个不同的数。根据数据位计算出来的校验值,一定是确定的。所以,如果数据位出错了,计算出来的校验码,一定和确定的那个校验码不同。那可能的值,就是在 2^4 - 1 = 15 那剩下的 15 个可能的校验值当中。
15 个可能的校验值,其实可以对应 15 个可能出错的位。这个时候你可能就会问了,既然数据位只有 7 位,那为什么要用 4 位的校验码呢?用 3 位不就够了吗?2^3 - 1 = 7,正好能够对上 7 个不同的数据位啊!
你别忘了,单比特翻转的错误,不仅可能出现在数据位,也有可能出现在校验位。校验位本身也是可能出错的。所以,7 位数据位和 3 位校验位,如果只有单比特出错,可能出错的位数就是 10 位,2^3 - 1 = 7 种情况是不能找到具体是哪一位出错的。
事实上,如果数据位有 K 位,校验位有 N 位。那么需要满足下面这个不等式,才能确保能够对单比特翻转的数据纠错。这个不等式就是:
K + N + 1 <= 2^N
1、海明码的纠错原理
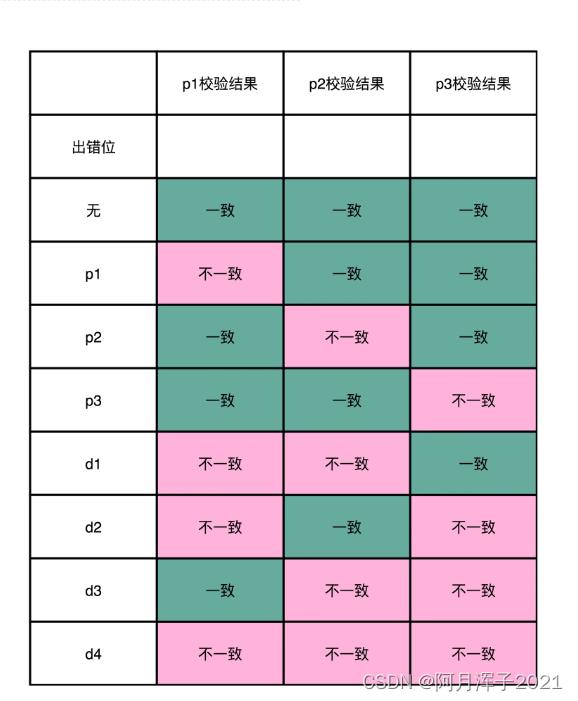
为了算起来简单一点,我们少用一些位数,来算一个 4-3 海明码(也就是 4 位数据位,3 位校验位)。把 4 位数据位,分别记作 d1、d2、d3、d4。把 3 位校验位,分别记作 p1、p2、p3。
从 4 位的数据位里面,拿走 1 位,然后计算出一个对应的校验位。这个校验位的计算用之前讲过的奇偶校验就可以了。比如,我们用 d1、d2、d4 来计算出一个校验位 p1;用 d1、d3、d4 计算出一个校验位 p2;用 d2、d3、d4 计算出一个校验位 p3。

当数据码出错的时候,至少会有 2 位校验码的计算是不一致的。当校验码出错,只有一个校验码的计算是不一致的。所以校验码不一致,一共有 2^3-1=7 种情况,正好对应了 7 个不同的位数的错误。
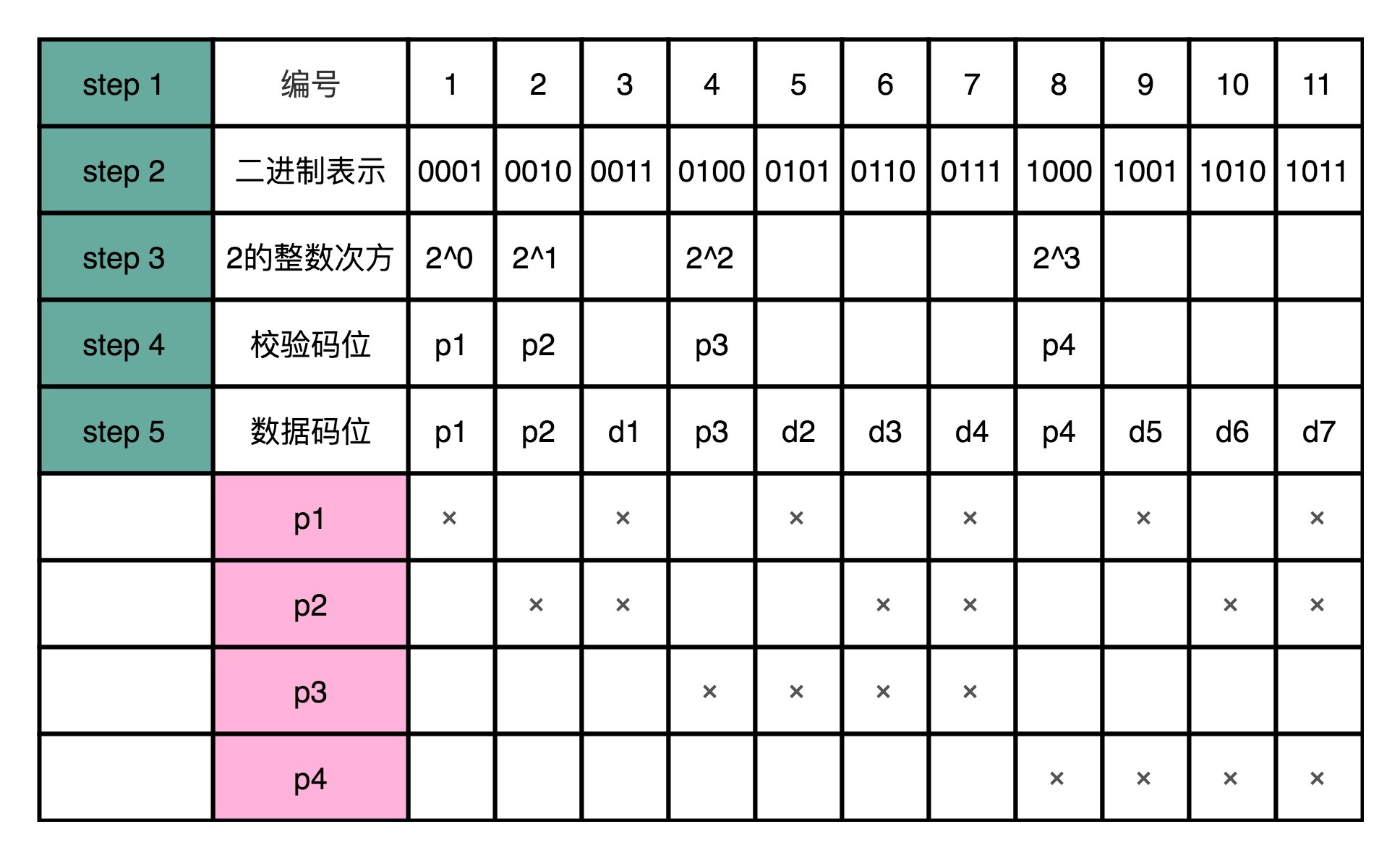
生成海明码的步骤:
- 先确定编码后,要传输的数据是多少位。比如 7-4 海明码,就是一共 11 位。
- 给这 11 位数据从左到右进行编号,并且也把它们的二进制表示写出来。
- 把这 11 个数据中的二进制的整数次幂找出来。在这个 7-4 海明码里面,就是 1、2、4、8。这些数,就是校验码位,把他们记录做 p1~p4。如果从二进制的角度看,它们是这 11 个数当中,唯四的,在 4 个比特里面只有一个比特是 1 的数值。
- 剩下的 7 个数,就是 d1-d7 的数据码位了
- 校验码位还是用奇偶校验码。但是每一个校验码位,不是用所有的 7 位数据来计算校验码。而是 p1 用 3、5、7、9、11 来计算。也就是,在二进制表示下,从右往左数的第一位比特是 1 的情况下,用 p1 作为校验码。
- 剩下的 p2,用 3、6、10、11 来计算校验码,也就是在二进制表示下,从右往左数的第二位比特是 1 的情况下,用 p2。p3 自然是从右往左数,第三位比特是 1 的情况下的数字校验码。而 p4 则是第四位比特是 1 的情况下的校验码。
任何一个数据码出错了,至少会有对应的两个或者三个校验码对不上,这样就能反过来找到是哪一个数据码出错了。如果校验码出错了,那么只有一位校验码对不上,那就是校验码出错了。
2、海明距离
两个二进制表示的数据之间有差异的位数,称为海明距离。比如 1001 和 0001 的海明距离是 1,因为他们只有最左侧的第一位是不同的。而 1001 和 0000 的海明距离是 2,因为他们最左侧和最右侧有两位是不同的。
所进行一位纠错,就是所有和要传输的数据的海明距离为 1 的数,都能被纠正回来。
任何两个实际传输的数据,海明距离都至少要是 3。如果是 2 的话,那么就会有一个出错的数,到两个正确的数据的海明距离都是 1。当我们看到这个出错的数的时候,就不知道究竟应该纠正到那一个数了。
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间