网络编程
文章目录
- 网络编程
- 前置概念
- 1- 字节序
- 高低地址与高低字节
- 高低地址:
- 高低字节
- 字节序大端小端例子
- 代码判断当前机器是大端还是小端
- 为何要有字节序
- 字节序转换函数
- 需要字节序转换的时机
- 例子一
- 例子二
- 2- IP地址转换函数
- 早期(不用管)
- 举例
- 现在
- 与字节序转换函数相比:
- **例子(点分十进制串转成网络大端数据)**
- 3 - 套接字(地址)结构体
- **1、通用套接字(地址)结构体类型(最初的套接字(地址)结构体)**
- 2- ipv4套接字结构体
- 例子
- 3 - ipv6套接字结构体
- 4- 新的通用套接字地址结构
- 5 套接字地址结构比较
- 进入正式篇章
- 1、网络中进程之间如何通信?
- 2、什么是Socket?
- 3、socket的基本操作
- 3.1、socket()函数
- 3.2、bind()函数
- 网络字节序与主机字节序
- 3.3、listen()、connect()函数
- 3.4、accept()函数
- 3.5、read()、write()等函数
- 3.6、close()函数
- 4 , Socket通信过程
- 客户端过程
- 代码描述
- 服务端过程
- 代码描述
- 5 , socket中TCP连接释放详解
- 三次握手
- 四次挥手
- 套接字格式
- 流格式套接字(SOCK_STREAM)
- 数据报格式套接字(SOCK_DGRAM)
- 数据报格式套接字(SOCK_DGRAM)
前置概念
1- 字节序
字节序经常被分为两类:
-
Big-Endian(大端):高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
-
2.
Little-Endian(小端):低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
高低地址与高低字节
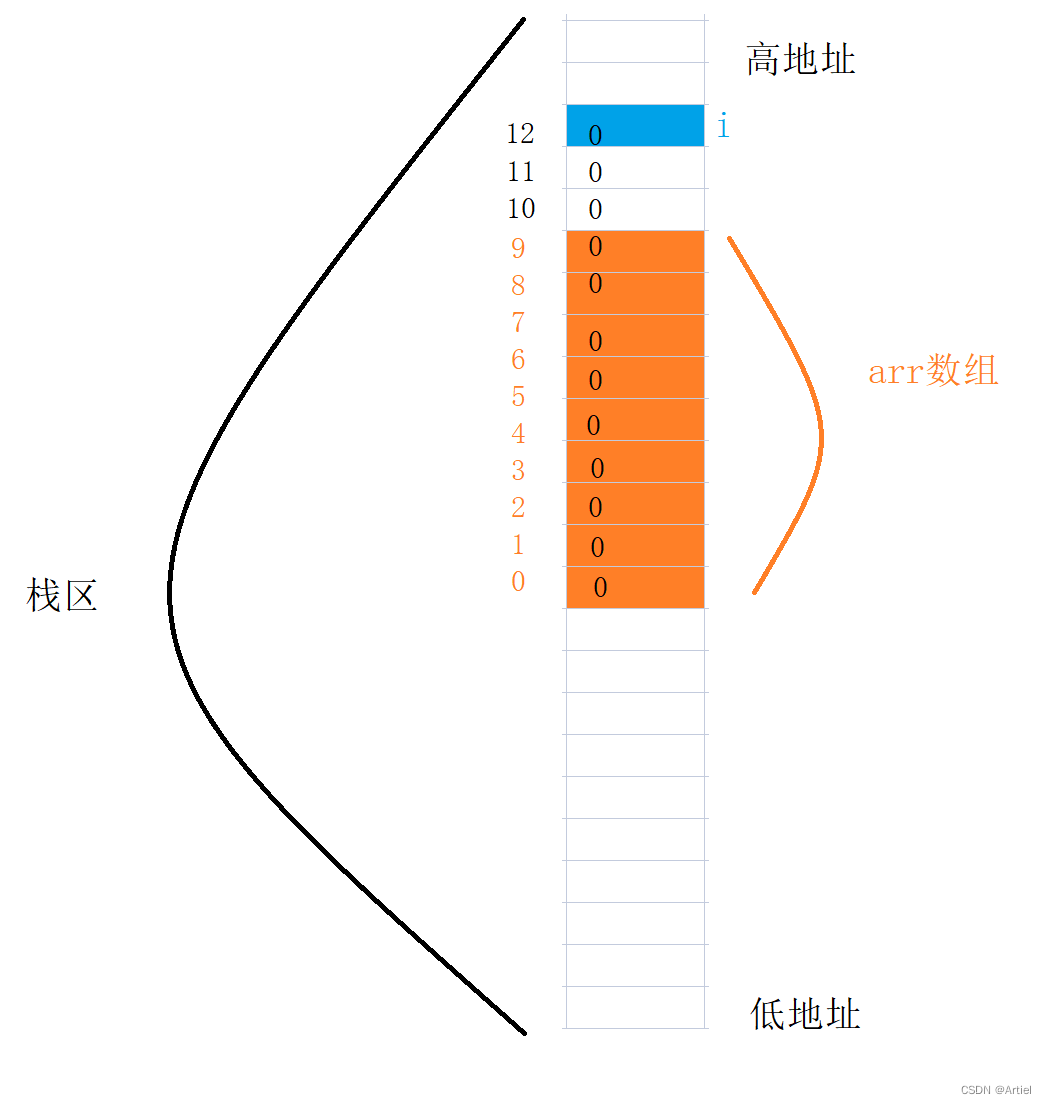
高低地址:
C程序映射中内存的空间布局大致如下:
最高内存地址 0xFFFFFFFF
栈区(从高内存地址,往 低内存地址发展。即栈底在高地址,栈顶在低地址)
堆区(从低内存地址 ,往 高内存地址发展)
全局区(常量和全局变量)
代码区
最低内存地址 0x00000000
高低字节
在十进制中靠左边的是高位,靠右边的是低位,在其他进制也是如此。例如 0x12345678,从高位到低位的字节依次是0x12、0x34、0x56和> 0x78。
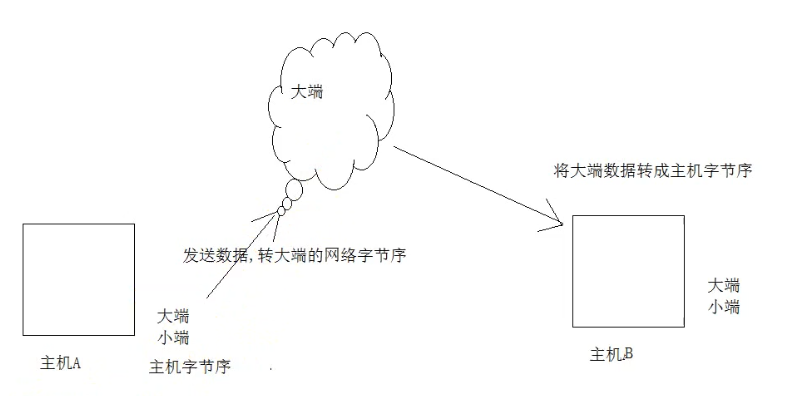
网络字节序 就是 大端字节序:4个字节的32 bit值以下面的次序传输,首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit
主机字节序 就是 小端字节序,现代PC大多采用小端字节序。
字节序大端小端例子
对于数据 0x12345678,假设从地址0x4000开始存放,在大端和小端模式下,存放的位置分别为:
| 内存地址 | 小端模式 | 大端模式 |
|---|---|---|
| 0x4003 | 0x12 | 0x78 |
| 0x4002 | 0x34 | 0x56 |
| 0x4001 | 0x56 | 0x34 |
| 0x4000 | 0x78 | 0x12 |
采用Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。
小端存储后:0x78563412 大端存储后:0x12345678
代码判断当前机器是大端还是小端
void byteorder()
{
union
{
short value;
char union_bytes[sizeof(short)];
}test;
test.value = 0x0102;
if (sizeof(short) == 2)
{
if (test.union_bytes[0] == 1 && test.union_bytes[1] == 2)
cout << "big endian" << endl;
else if (test.union_bytes[0] == 2 && test.union_bytes[1] == 1)
cout << "little endian" << endl;
else
cout << "unknown" << endl;
}
else
{
cout << "sizeof(short) == " << sizeof(short) << endl;
}
return ;
}
上述代码,使用了联合体union,所有成员共用同一块内存的特性。
一般,主机字节序,都是小端模式。
为何要有字节序
很多人会问,为什么会有字节序,统一用大端序不行吗?答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。在计算机内部,小端序被广泛应用于现代 CPU 内部存储数据;而在其他场景,比如网络传输和文件存储则使用大端序。
字节序转换函数
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
-
h表示host,指小端,n表示network指大端,l表示32位长整数,s表示16位短整数。
-
注意:32位是用来转换IP地址的,16位是用来转换端口号的
需要字节序转换的时机
端口和IP地址是16位或者32为多字节数据,需要大小端转换,但是在数据传输过程中,都是以字符串的形式传输的,字符串中每个字符只有8位,也就是一个字节,无论在大端还是小端,结果都是一样的(这需要对大小端概念有一个比较清晰的理解)
比如 “scsadvsdvsad” 和 “中文名” 都是串 都不需要转
例子一
printf_bin(int num) 这个函数将整形变量以二进制的形式打印出来
#include <stdio.h>
#include <arpa/inet.h>
void printf_bin(int num) // 这个函数将整形变量以二进制的形式打印出来
{
int i, j, k;
unsigned char *p = (unsigned char *)&num + 3; // p先指向num后面第3个字节的地址,即num的最高位字节地址
for (i = 0; i < 4; i++) // 依次处理4个字节(32位)
{
j = *(p - i); // 取每个字节的首地址,从高位字节到低位字节,即p p-1 p-2 p-3地址处
for (int k = 7; k >= 0; k--) // 处理每个字节的8个位,注意字节内部的二进制数是按照人的习惯存储!
{
if (j & (1 << k)) // 1左移k位,与单前的字节内容j进行或运算,如k=7时,00000000&10000000=0 ->该字节的最高位为0
printf("1");
else
printf("0");
}
printf(" "); // 每8位加个空格,方便查看
}
printf("\r\n");
}
int main()
{
int n = 10;
printf("打印出n的32位数据\n");
printf_bin(n);
printf("进行大小端转换\n");
unsigned int n1 = htonl(n);
printf("打印出n的32位数据\n");
printf_bin(n);
printf("打印出n1的32位数据\n");
printf_bin(n1);
}
运行结果:
打印出n的32位数据
00000000 00000000 00000000 00001010
进行大小端转换
打印出n的32位数据
00000000 00000000 00000000 00001010
打印出n1的32位数据
00001010 00000000 00000000 00000000
可见整型变量 n 就像是一个容器,能存放 32 位的数据, 数据默认是小端存储的, htonl 转换n容器 后, n原先的大小端存储方式没变,但返回出了大小端存储方式转换的容器n1 .
例子二
// todo 网络字节序和本地字节序的转换 (大端二进制和小端二进制的转换)
#include <stdio.h>
#include <arpa/inet.h>
void printf_bin(int num) // 这个函数将整形变量以二进制的形式打印出来
{
int i, j, k;
unsigned char *p = (unsigned char *)&num + 3; // p先指向num后面第3个字节的地址,即num的最高位字节地址
for (i = 0; i < 4; i++) // 依次处理4个字节(32位)
{
j = *(p - i); // 取每个字节的首地址,从高位字节到低位字节,即p p-1 p-2 p-3地址处
for (int k = 7; k >= 0; k--) // 处理每个字节的8个位,注意字节内部的二进制数是按照人的习惯存储!
{
if (j & (1 << k)) // 1左移k位,与单前的字节内容j进行或运算,如k=7时,00000000&10000000=0 ->该字节的最高位为0
printf("1");
else
printf("0");
}
printf(" "); // 每8位加个空格,方便查看
}
printf("\r\n");
}
int main()
{
char buf[4] = {192, 168, 1, 2}; // 32位
// todo1 将 4字节(32位)的数据存放在 num容器(int 类型, 32位)中
// todo 也就是取出32位数据
unsigned int num = *(unsigned int *)buf; // int*把buf(char类型的数组首地址强转为int*类型的地址),
// 再*(解引用)取出四个字节的数据,而int 类型刚好是4字节,就能存放这四字节数据
// 你可以把 int num 当成是定义了一个能存放32位数据的容器,只是这32位存放的是
// 192.168.1.2 的用二进制(01)表示的情况
printf("打印出num容器中的32位数据\n");
printf_bin(num);
printf("打印出num的值\n");
printf("%u\n", num); //%u用于打印 unsigned int .
// 打印结果 33663168 . 这么大是因为 他不会每八位隔断,每八位分别做二进制转换
//(像把 00000010 00000001 10101000 11000000)隔断为 192.168.1.2 而是
// 直接将这个32位的数作为整体进行二进制转换
printf("================\n");
int n1 = 33663168; // 实际上这个十进制数用二进制的表示就是 00000010 00000001 10101000 11000000
printf("打印出n1容器中的32位数据\n");
printf_bin(n1);
// todo2 htol() 函数的作用是将一个32位数从主机字节顺序转换成网络字节顺序。
unsigned int sum = htonl(num);
printf("打印出sum容器中的32位数据\n");
printf_bin(sum); // 11000000 10101000 00000001 00000010 和 num中的二进制位是相反的
// todo 3 每四位取出数据.
printf("sum容器中32位数据,每四位取出,并打印\n");
unsigned char *p = ∑
printf("%d %d %d %d\n", *p, *(p + 1), *(p + 2), *(p + 3));
// todo 逆过程 ntohl 函数的作用是将一个32位数从网络字节顺序转换成主机字节顺序
printf("sum2容器中32位数据,每四位取出,并打印\n");
unsigned int sum2 = ntohl(sum);
unsigned char *p2 = &sum2;
printf("%d %d %d %d\n", *p2, *(p2 + 1), *(p2 + 2), *(p2 + 3));
}
大家这里会有疑惑的是
char buf[4] = {192, 168, 1, 2}; // 32位
unsigned int num = *(unsigned int *)buf;
第一行这里是定义了一个 32位的数组存放 ip的字符串
第二行定义了一 个 (int *) 类型的指针,并进行解引用, 就相当于是取了 4个字节的数据 . 也就是把32位字符数组的全部内容存放在了能存放32位数据的整型变量 num 中 .
(这里有疑惑的可以看我的指针的步长及意义(c语言基础))其中有讲到对不同指针解引用,会取出不同的地址
VS下常见指针类型解引用时取出的字节数分别为:
char *:1个字节(通常需要强转)
指针解引用时取出数据的字节数不同
VS下常见指针类型解引用时取出的字节数分别为:
char *:1个字节(通常需要强转)
int * :4个字节
2- IP地址转换函数
点分十进制串 转 为一个 32位 无符号数
早期(不用管)
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int inet_aton(const char *cp,struct in_addr *inp);
in_addr_t inet_addr(const char *cp);
char *inet_ntoa(struct in_addr in);
in_addr_t inet_network(const char *cp);
-
inet_aton转换网络主机地址(点分十进制)为网络字节序二进制值.1输入参数string包含ASCII表示的IP地址。
2 输出参数addr是将要用新的IP地址更新的结构。
inet_aton("127.0.0.1",&adr_inet.sin_addr)
inet_addr转换网络主机地址(点分十进制)为网络字节序二进制值,如果参数 char *cp 无效则返回-1(INADDR_NONE),但这个函数有个缺点:在处理地址为255.255.255.255时也返回-1,虽然它是一个有效地址,但inet_addr()无法处理这个地址。
in_addr_t inet_addr(const char *cp);
那inet_aton和inet_addr有什么区别呢?
inet_addr不支持255.255.255.255,inet_aton支持255.255.255.255
inet_ntoa() 和 inet_network 有什么区别?
inet_ntoa() 支持255.255.255.255 和 inet_network 不支持255.255.255.255
inet_ntoa()函数转换网络字节序地址->标准的点分十进制地址。该函数返回值指向保存点分十进制的字符串地址的指针,该字符串的空间为静态分配 的,所以在第二次调用这个函数时,意味着上一次调用并保存的结果将会被覆盖(重写)。so creazy!!!- 好了那就来证实一下,inet_ntoa()的静态返回值吧!!
char *add1,add2;
src.sin_addr.s_addr = inet_addr("192.168.1.123");
add1 =inet_ntoa(src.sin_addr);
src.sin_addr.s_addr = inet_addr("192.168.1.124");
add2 = inet_ntoa(src.sin_addr);
printf("a1:%s\n",add1);
printf("a2:%s\n",add2);
最终的printf结果是:
a1:192.168.1.124
a2:192.168.1.124
总结:
inet_aton计算出来的是网络字节序的二进制IP 支持255.255.255.255
inet_network计算出来的是主机字节序的二进制IP 不支持255.255.255.255
inet_addr计算出来的是网络字节序的二进制IP 不支持255.255.255.255
inet_ntoa计算出来的是主机字节序的二进制IP 支持255.255.255.255 静态覆盖问题
- 均只能处理Pv4的ip地址
- 均为不可重入函数
举例
inet_addr、inet_network、inet_aton
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/types.h>
int main()
{
char ip[] = "192.168.0.74";
long r1, r2, r3; //long
struct in_addr addr;
r1 = inet_addr(ip); //返回网络字节序
if(-1 == r1){
printf("inet_addr return -1/n");
}else{
printf("inet_addr ip: %ld/n", r1);
}
r2 = inet_network(ip); //返回主机字节序
if(-1 == r2){
printf("inet_addr return -1/n");
}else{
printf("inet_network ip: %ld/n", r2);
printf("inet_network ip: %ld/n", ntohl(r2)); //ntohl: 主机字节序 ——> 网络字节序
}
r3 = inet_aton(ip, &addr); //返回网络字节序
if(0 == r3){
printf("inet_aton return -1/n");
}else{
printf("inet_aton ip: %ld/n", addr.s_addr);
}
/***** 批量注释的一种方法 *****/
#if 0
r3 = inet_aton(ip, addr);
if(0 == r3){
printf("inet_aton return -1/n");
}else{
printf("inet_aton ip: %ld/n", ntohl(addr.s_addr));
}
#endif
return 0;
}
运行结果:
[work@db-testing-com06-vm3.db01.baidu.com net]$ gcc -W -o inet_addr inet_addr.c
[work@db-testing-com06-vm3.db01.baidu.com net]$ ./inet_addr
inet_addr ip: 1241557184
inet_network ip: -1062731702
inet_network ip: 1241557184
inet_aton ip: 1241557184
现在
#include <arpa/inet.h>
int inet_pton(int af,const char src,void *dst); //点分十进制串转字节序而且是 主机字节序转网络字节序
const char inet_ntop(int af,const void *src,char *dst,socklen_t size);// 网络字节序转主机字节序
其中 af 是 地址协议 ,AF_INET (ipv4) 和 AF_INET(ipv6)
src 是源 ip地址串 . dst 是万能引用类型, 也就是只要 能存放32位数的 变量就行
inet_pton和inet_ntop不仅可以转换IPv4的in_addr,还可以转换IPv6的in6_addr。
- 这样来看的话,我认为如果有需要最好是用inet_pton()、inet_ntop()代替inet_ntoa()、inet_addr().
用
inet_pton(AF_INET, cp, &src.sin_addr);
代替
src.sin_addr.s_addr = inet_addr(cp);
用
char str[INET_ADDRATRLEN];
ptr = inet_ntop(AF_INET, &src.sin_addr, str, sizeof(str));
代替
ptr = inet_ntoa(src.sin_addr);
与字节序转换函数相比:
-
uint32_t htonl(unin32_t host32bitvalue);
参数是32bit的二进制数值,在转换地址时就是32位的主机字节序ip地址(经常用点分十进制)
用法: -
servaddr.sin_addr.s_addr=htonl(127.0.0.1); servaddr.sin_addr.s_addr=htonl(INADDR_ANY); // INADDR_ANY真实值为0.0.0.0 -
int inet_pton(int family,const char *strptr,void *addrptr);
该函数完成两个功能:1.字符串->二进制数值 2.主机字节序->网络字节序(所以调用此函数后不需htonl了)
第二个参数是ip地址字符串的指针 -
用法:
- ```
inet_pton(AF_INET,argv[1],&servaddr.sin_addr);
第三个参数使用&servaddr.sin_addr.s_addr也可以通过
```
总结:数值型的ip地址转换用htonl,字符串类型的用inet_pton
例子(点分十进制串转成网络大端数据)
// 点分十进制串转成网络大端数据 (字符串和网络大端数据(二进制)的转换)
#include <stdio.h>
#include <arpa/inet.h>
void func()
{
// todo 准备一个待转换的点分十进制
char buf[] = "192.168.1.4";
// todo 准备一个能存放32位网络数据的容器
unsigned int num = 0;
// inet_pton //todo 将点分十进制串转成32位网络大端的数据
if (1 == inet_pton(AF_INET, buf, &num)) // 转换成功返回1
{
printf("转换成功\n");
// todo 每四位取出数据
unsigned char *p2 = (unsigned char *)#
printf("%d %d %d %d\n", *p2, *(p2 + 1), *(p2 + 2), *(p2 + 3));
}
}
void func2()
{
// todo 准备一个待转换的点分十进制
char buf[] = "192.168.1.4";
// todo 准备一个能存放32位网络数据的容器
unsigned int num = 0;
inet_pton(AF_INET, buf, &num);
// todo 现在将大端网络数据num转成点分十进制传
char ip[16] = {0};
const char *p = inet_ntop(AF_INET, &num, ip, sizeof(ip)); // 返回值:存储点分制串数组首地址
printf("点分十进制串为 %s\n", p);
}
int main()
{
func();
func2();
}
3 - 套接字(地址)结构体
1、通用套接字(地址)结构体类型(最初的套接字(地址)结构体)
struct sockaddr
{
sa_family_t sa_family; //协议簇
char sa_data[14]; //协议簇数据
}
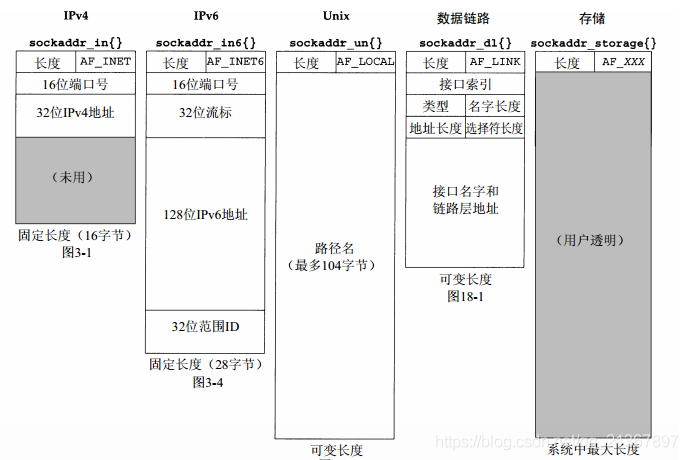
通用套接字结构体可以在不同的协议簇之间进行强制转化,Socket网络编程中几乎所有套接字API函数的形参都是通用套接字结构体struct sockaddr。(因为历史遗留)
- 通用套接字结构体对编程的角度来说,设置很不方便,我们以以太网协议来说,当要设置端口号、IP地址等,那么我需要将端口号与IP地址进行数据组合绑定,然后赋值给该结构,是不能独立赋值。
- 为解决上述问题,以太网协议中经常用到的是下述结构体,这样就可以给人以直观的方式去填充套接字结构体。
2- ipv4套接字结构体
struct sockaddr_in
{
u8 sin_len;
u8 sin_family;
u16 sin_port;
struct in_addr sin_addr;
char sin_zero[8];
}
- 结构体成员列表
| 结构体成员 | 参数含义 | 备注 |
|---|---|---|
| u8 sin_len | 结构体sockaddr_in的长度 | 一般大小为固定16字节 |
| u8 sin_family | 协议族类型 | 见下表 |
| u16 sin_port | 16位端口号 | XXX |
| struct in_addr sin_addr | 32位IP地址 | INADDR_ANY //表示可以与任何主机通信 |
| char sin_zero[8] | //未使用 | 填充位,一般都设置为0 |
- 协议簇列表
协议簇类型(sin_family) | 参数含义 |
|---|---|
| AF_INET | 以太网/IPv4协议 |
| AF_INET6 | 以太网/IPv6协议 |
| AF_LOCAL | Unix域协议/只在本机内通信的套接字 |
| AF_ROUTE | 路由套接口 |
| AF_KEY | 密钥套接口 |
***Note : *** 我们主要使用的是以太网,所以
sin_family成员一般都为AF_INET,有时候我们看到协议簇类型是PF_\*而不是AF\*,这是因为glibc的实现机制是posix,其实都是同一个东西。
存在问题:
- Socket网络编程中几乎所有套接字API函数的形参都是通用套接字结构体
struct sockaddr,而我们初始化传递的参数是以太网套接字结构体struct sockaddr类型,这样是否就存在类型不一致的问题?
Exzampp:
// API函数: fun(struct sockaddr)
// 用户实际调用:
int main()
{
struct sockaddr_in;
fun(sockaddr_in); //是否存在问题?
}
问题解答:
- 上述操作完全可以,因为这两个结构体在内存上的大小完全一致都是16个字节,所以隐式的转换不存在其它问题。
- struct sockaddr = struct sockaddr_in 。 (不存在问题)
但一般使用的时候都会强制转换一下,以便 struct sockaddr 形参 能接受 struct sockaddr_in 的实参
例子
// todo 创建服务器socket地址结构体
struct sockaddr_in serv_addr;
// 端口
serv_addr.sin_port = htonl(6500);
// ip协议
serv_addr.sin_family = AF_INET;
// 绑定地址
// 方式一
// serv_addr.sin_addr.s_addr =htons(INADDR_ANY);//这个宏返回任何可用的ip地址(二进制类型0.0.0.0)
int num;
inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr.s_addr);
// todo 建立和服务器的链接(这里强转)
int ret = connect(cfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
3 - ipv6套接字结构体
struct sockaddr_in6定义在in6.h中;
struct in6_addr {
union {
__u8 u6_addr8[16];
__be16 u6_addr16[8];
__be32 u6_addr32[4];
} in6_u;
#define s6_addr in6_u.u6_addr8
#define s6_addr16 in6_u.u6_addr16
#define s6_addr32 in6_u.u6_addr32
};
struct sockaddr_in6 {
unsigned short int sin6_family; /* AF_INET6 */
__be16 sin6_port; /* Transport layer port # */
__be32 sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
__u32 sin6_scope_id; /* scope id (new in RFC2553) */
};
4- 新的通用套接字地址结构
相对比于struct sockaddr,struct sockaddr_storage有如下区别:
(1)、struct sockaddr_storage结构足以容纳系统所支持的任何套接字地址结构;
(2)、struct sockaddr_storage结构满足最苛刻的字节对齐要求;
#define _K_SS_MAXSIZE 128 /* Implementation specific max size */
#define _K_SS_ALIGNSIZE (__alignof__ (struct sockaddr *))
/* Implementation specific desired alignment */
typedef unsigned short __kernel_sa_family_t;
struct __kernel_sockaddr_storage {
__kernel_sa_family_t ss_family; /* address family */
/* Following field(s) are implementation specific */
char __data[_K_SS_MAXSIZE - sizeof(unsigned short)];
/* space to achieve desired size, */
/* _SS_MAXSIZE value minus size of ss_family */
} __attribute__ ((aligned(_K_SS_ALIGNSIZE))); /* force desired alignment */
5 套接字地址结构比较
这里参考《UNIX套接字编程卷一》给出BSD实现下的各个套接字地址结构的比较,只作参考;
进入正式篇章
1、网络中进程之间如何通信?
本地的进程间通信(IPC)有很多种方式,但可以总结为下面4类:
- 消息传递(管道、FIFO、消息队列)
- 同步(互斥量、条件变量、读写锁、文件和写记录锁、信号量)
- 共享内存(匿名的和具名的)
- 远程过程调用(Solaris门和Sun RPC)
但这些都不是本文的主题!我们要讨论的是网络中进程之间如何通信?首要解决的问题是如何唯一标识一个进程,否则通信无从谈起!在本地可以通过进程PID来唯一标识一个进程,但是在网络中这是行不通的。其实TCP/IP协议族已经帮我们解决了这个问题,网络层的“ip地址”可以唯一标识网络中的主机,而传输层的“协议+端口”可以唯一标识主机中的应用程序(进程)。这样利用三元组(ip地址,协议,端口)就可以标识网络的进程了,网络中的进程通信就可以利用这个标志与其它进程进行交互。
使用TCP/IP协议的应用程序通常采用应用编程接口:UNIX BSD的套接字(socket)和UNIX System V的TLI(已经被淘汰),来实现网络进程之间的通信。就目前而言,几乎所有的应用程序都是采用socket,而现在又是网络时代,网络中进程通信是无处不在,这就是我为什么说“一切皆socket”。
2、什么是Socket?
上面我们已经知道网络中的进程是通过socket来通信的,那什么是socket呢?socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。我的理解就是Socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭),这些函数我们在后面进行介绍。
3、socket的基本操作
既然socket是“open—write/read—close”模式的一种实现,那么socket就提供了这些操作对应的函数接口。下面以TCP为例,介绍几个基本的socket接口函数。
3.1、socket()函数
int socket(int domain, int type, int protocol);
socket函数对应于普通文件的打开操作。普通文件的打开操作返回一个文件描述字,而**socket()**用于创建一个socket描述符(socket descriptor),它唯一标识一个socket。这个socket描述字跟文件描述字一样,后续的操作都有用到它,把它作为参数,通过它来进行一些读写操作。
正如可以给fopen的传入不同参数值,以打开不同的文件。创建socket的时候,也可以指定不同的参数创建不同的socket描述符,socket函数的三个参数分别为:
- domain:即协议域,又称为协议族(family)。常用的协议族有,
AF_INET(IPV4)、AF_INET6(IPV6)、AF_LOCAL(或称AF_UNIX,Unix域socket)、AF_ROUTE等等。协议族决定了socket的地址类型,在通信中必须采用对应的地址,如AF_INET决定了要用ipv4地址(32位的)与端口号(16位的)的组合、AF_UNIX决定了要用一个绝对路径名作为地址。 - type:指定socket类型。常用的socket类型有,
SOCK_STREAM(tcp)、SOCK_DGRAM(udp)、SOCK_RAW、SOCK_PACKET、SOCK_SEQPACKET等等(socket的类型有哪些?)。 - protocol:故名思意,就是指定协议。常用的协议有,
IPPROTO_TCP、IPPTOTO_UDP、IPPROTO_SCTP、IPPROTO_TIPC等,它们分别对应TCP传输协议、UDP传输协议、STCP传输协议、TIPC传输协议(这个协议我将会单独开篇讨论!)。
注意:并不是上面的type和protocol可以随意组合的,如SOCK_STREAM不可以跟IPPROTO_UDP组合。当protocol为0时,会自动选择type类型对应的默认协议。
当我们调用socket创建一个socket时,返回的socket描述字它存在于协议族(address family,AF_XXX)空间中,但没有一个具体的地址。如果想要给它赋值一个地址,就必须调用bind()函数,否则就当调用connect()、listen()时系统会自动随机分配一个端口。
3.2、bind()函数
正如上面所说bind()函数把一个地址族中的特定地址赋给socket。例如对应AF_INET、AF_INET6就是把一个ipv4或ipv6地址和端口号组合赋给socket。
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
函数的三个参数分别为:
-
sockfd:即socket描述字,它是通过socket()函数创建了,唯一标识一个socket。bind()函数就是将给这个描述字绑定一个名字。
-
addr:一个const struct sockaddr *指针,指向要绑定给sockfd的协议地址。这个地址结构根据地址创建socket时的地址协议族的不同而不同,如ipv4对应的是:
struct sockaddr_in { sa_family_t sin_family; in_port_t sin_port; struct in_addr sin_addr; }; struct in_addr { uint32_t s_addr; };ipv6对应的是:
struct sockaddr_in6 { sa_family_t sin6_family; in_port_t sin6_port; uint32_t sin6_flowinfo; struct in6_addr sin6_addr; uint32_t sin6_scope_id; }; struct in6_addr { unsigned char s6_addr[16]; };Unix域对应的是:
#define UNIX_PATH_MAX 108 struct sockaddr_un { sa_family_t sun_family; char sun_path[UNIX_PATH_MAX]; }; -
addrlen:对应的是地址的长度。
通常服务器在启动的时候都会绑定一个众所周知的地址(如ip地址+端口号),用于提供服务,客户就可以通过它来接连服务器;而客户端就不用指定,有系统自动分配一个端口号和自身的ip地址组合。这就是为什么通常服务器端在listen之前会调用bind(),而客户端就不会调用,而是在connect()时由系统随机生成一个。
网络字节序与主机字节序
主机字节序就是我们平常说的大端和小端模式:不同的CPU有不同的字节序类型,这些字节序是指整数在内存中保存的顺序,这个叫做主机序。引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
网络字节序:4个字节的32 bit值以下面的次序传输:首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit。这种传输次序称作大端字节序。**由于TCP/IP首部中所有的二进制整数在网络中传输时都要求以这种次序,因此它又称作网络字节序。**字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序,一个字节的数据没有顺序的问题了。
所以: 在将一个地址绑定到socket的时候,请先将主机字节序转换成为网络字节序,而不要假定主机字节序跟网络字节序一样使用的是Big-Endian。由于 这个问题曾引发过血案!公司项目代码中由于存在这个问题,导致了很多莫名其妙的问题,所以请谨记对主机字节序不要做任何假定,务必将其转化为网络字节序再 赋给socket。
3.3、listen()、connect()函数
如果作为一个服务器,在调用socket()、bind()之后就会调用listen()来监听这个socket,如果客户端这时调用connect()发出连接请求,服务器端就会接收到这个请求。
int listen(int sockfd, int backlog);
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
listen函数的第一个参数即为要监听的socket描述字,第二个参数为相应socket可以排队的最大连接个数。socket()函数创建的socket默认是一个主动类型的,listen函数将socket变为被动类型的,等待客户的连接请求。
connect函数的第一个参数即为客户端的socket描述字,第二参数为服务器的socket地址,第三个参数为socket地址的长度。客户端通过调用connect函数来建立与TCP服务器的连接。
3.4、accept()函数
TCP服务器端依次调用socket()、bind()、listen()之后,就会监听指定的socket地址了。TCP客户端依次调用socket()、connect()之后就想TCP服务器发送了一个连接请求。TCP服务器监听到这个请求之后,就会调用accept()函数取接收请求,这样连接就建立好了。之后就可以开始网络I/O操作了,即类同于普通文件的读写I/O操作。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
accept函数的第一个参数为服务器的socket描述字,第二个参数为指向struct sockaddr *的指针,用于返回客户端的协议地址,第三个参数为协议地址的长度。如果accpet成功,那么其返回值是由内核自动生成的一个全新的描述字,代表与返回客户的TCP连接。
注意:accept的第一个参数为服务器的socket描述字,是服务器开始调用socket()函数生成的,称为监听socket描述字;而accept函数返回的是已连接的socket描述字。一个服务器通常通常仅仅只创建一个监听socket描述字,它在该服务器的生命周期内一直存在。内核为每个由服务器进程接受的客户连接创建了一个已连接socket描述字,当服务器完成了对某个客户的服务,相应的已连接socket描述字就被关闭。
3.5、read()、write()等函数
万事具备只欠东风,至此服务器与客户已经建立好连接了。可以调用网络I/O进行读写操作了,即实现了网咯中不同进程之间的通信!网络I/O操作有下面几组:
- read()/write()
- recv()/send()
- readv()/writev()
- recvmsg()/sendmsg()
- recvfrom()/sendto()
我推荐使用recvmsg()/sendmsg()函数,这两个函数是最通用的I/O函数,实际上可以把上面的其它函数都替换成这两个函数。它们的声明如下:
#include
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
#include
#include
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags);
ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags);
read函数是负责从fd中读取内容.当读成功时,read返回实际所读的字节数,如果返回的值是0表示已经读到文件的结束了,小于0表示出现了错误。如果错误为EINTR说明读是由中断引起的,如果是ECONNREST表示网络连接出了问题。
write函数将buf中的nbytes字节内容写入文件描述符fd.成功时返回写的字节 数。失败时返回-1,并设置errno变量。在网络程序中,当我们向套接字文件描述符写时有俩种可能。1)write的返回值大于0,表示写了部分或者是 全部的数据。2)返回的值小于0,此时出现了错误。我们要根据错误类型来处理。如果错误为EINTR表示在写的时候出现了中断错误。如果为EPIPE表示 网络连接出现了问题(对方已经关闭了连接)。
其它的我就不一一介绍这几对I/O函数了,具体参见man文档或者baidu、Google,下面的例子中将使用到send/recv。
3.6、close()函数
在服务器与客户端建立连接之后,会进行一些读写操作,完成了读写操作就要关闭相应的socket描述字,好比操作完打开的文件要调用fclose关闭打开的文件。
#include
int close(int fd);
close一个TCP socket的缺省行为时把该socket标记为以关闭,然后立即返回到调用进程。该描述字不能再由调用进程使用,也就是说不能再作为read或write的第一个参数。
注意:close操作只是使相应socket描述字的引用计数-1,只有当引用计数为0的时候,才会触发TCP客户端向服务器发送终止连接请求。
4 , Socket通信过程
Socket 保证了不同计算机之间的通信,也就是网络通信。对于网站,通信模型是服务器与客户端之间的通信。两端都建立了一个 Socket 对象,然后通过 Socket 对象对数据进行传输。通常服务器处于一个无限循环,等待客户端的连接。
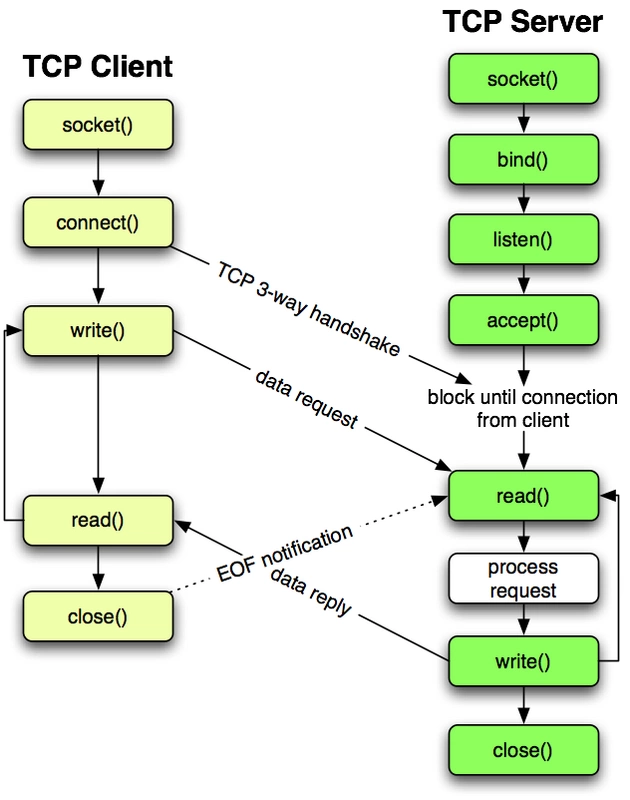
下面是面向连接的 TCP 时序图:

客户端过程
客户端的过程比较简单,创建 Socket,连接服务器,将 Socket 与远程主机连接(注意:只有 TCP 才有“连接”的概念,一些 Socket 比如 UDP、ICMP 和 ARP 没有“连接”的概念),发送数据,读取响应数据,直到数据交换完毕,关闭连接,结束 TCP 对话。
- 调用 socket函数创建客户端 socket
- 调用 connect 函数尝试连接服务器
- 连接成功以后调用 send 或 recv 函数开始与服务器进行数据交流
- 通信结束后,调用 close 函数关闭侦听socket
代码描述
/**
* TCP客户端通信基本流程
* DJX2022 1.23
* */
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <unistd.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
static const char* data = "hello world";
static const ssize_t len = strlen(data);
int main(int argc, char* argv[])
{
if(argc != 3)
{
std::cout << "Usage: " << argv[0] << " ip + port" << std::endl;
return 0;
}
// 1 创建连接套接字结构体
int clientSock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if(clientSock < 0)
{
std::cerr << "socket() error" << std::endl;
exit(-1);
}
// 2 初始化连接套接字结构体((这个结构体的参数是和服务器的监听套接字结构体的参数是一致的))
sockaddr_in serverAddr;
socklen_t serverAddrLen = sizeof(sockaddr_in);
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = inet_addr(argv[1]);
serverAddr.sin_port = htons(atoi(argv[2]));
int ret = connect(clientSock, (sockaddr*)&serverAddr, serverAddrLen);
if(ret < 0)
{
std::cerr << "connect() error" << std::endl;
close(clientSock);
exit(-1);
}
char buf[BUFSIZ] = {0};
ssize_t ret_send = 0;
ssize_t ret_recv = 0;
// 3 进行数据交互
for(; ; )
{
ret_send = send(clientSock, data, len, 0);
if(ret_send != len)
{
std::cerr << "send() data error" << std::endl;
break;
}
memset(buf, 0x00, BUFSIZ);
ret_recv = recv(clientSock, buf, BUFSIZ-1, 0);
if(ret_recv > 0)
{
buf[ret_recv] = '\0';
std::cout << "recv data successfully, data: " << buf << std::endl;
}
else if(ret_recv == 0)
{
std::cerr << "peer close connection" << std::endl;
break;
}
else
{
std::cerr << "recv error" << std::endl;
break;
}
sleep(3);
}
//4 关闭客户端的连接
close (clientSock);
return 0;
}
./client 127.0.0.1 9092
服务端过程
服务端先初始化 Socket,建立流式套接字,与本机地址及端口进行绑定,然后通知 TCP,准备好接收连接,调用 accept() 阻塞,等待来自客户端的连接。如果这时客户端与服务器建立了连接,客户端发送数据请求,服务器接收请求并处理请求,然后把响应数据发送给客户端,客户端读取数据,直到数据交换完毕。最后关闭连接,交互结束。
- 调用 socket 函数创建 socket(侦听socket)
- 调用 bind 函数 将 socket绑定到某个ip和端口的二元组上
- 调用 listen 函数 开启侦听
- 当有客户端请求连接上来后,调用 accept 函数接受连接,产生一个新的 socket(客户端 socket)
- 基于新产生的 socket 调用 send 或 recv 函数开始与客户端进行数据交流
- 通信结束后,调用 close 函数关闭侦听 socket
代码描述
/**
* TCP服务器通信基本流程
* DJX2022 1.23
*/
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
int main(int argc, char* argv[])
{
// 0. 在启动服务器之前做一点准备工作
// 服务器一般是要绑定 ip 和 port 的
// 服务器的启动方式为 ./server ip port
if(argc != 3)
{
std::cout << "Usage: " << argv[0] << " ip + port" << std::endl;
return 0;
}
// 1. 创建监听套接字
int listenSock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if(listenSock < 0)
{
std::cerr << "socket() error" << std::endl;
exit(-1);
}
// 2. 初始化服务器地址
sockaddr_in serverAddr;
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = inet_addr(argv[1]);
serverAddr.sin_port = htons(atoi(argv[2]));
socklen_t serverAddrLen = sizeof(sockaddr_in);
int ret = bind(listenSock, (sockaddr*)&serverAddr, serverAddrLen);
if(ret < 0)
{
std::cerr << "bind() error " << std::endl;
close(listenSock);
exit(-1);
}
// 3. 启动侦听
ret = listen(listenSock, 5);
if(ret < 0)
{
std::cerr << "listen() error" << std::endl;
close(listenSock);
exit(-1);
}
char buf[BUFSIZ] = {0};
ssize_t ret_recv = 0;
ssize_t ret_send = 0;
for(; ;)
{
sockaddr_in clientAddr;
socklen_t clientAddrLen = sizeof(sockaddr_in);
// 4. 接收客户端连接
int clientSock = accept(listenSock, (sockaddr*)&clientAddr, &clientAddrLen);
if(clientSock < 0)
{
std::cerr << "accept() error" << std::endl;
break;
}
for(; ; )
{
memset(buf, 0x00, BUFSIZ);
// 5. 从客户端接收数据
ret_recv = recv(clientSock, buf, BUFSIZ-1, 0);
if(ret_recv > 0)
{
buf[ret_recv] = '\0';
std::cout << "recv data from client, data: " << buf << std::endl;
// 6. 将收到的数据原封不动的发给客户端
ret_send = send(clientSock, buf, ret_recv, 0);
if(ret_send < 0 || ret_send != ret_recv)
{
std::cerr << "send data error." << std::endl;
break;
}
}
else if(ret_recv == 0)
{
std::cout << "peer close connection." << std::endl;
break;
}
else
{
std::cerr << "recv data error." << std::endl;
break;
}
}
close(clientSock);
}
// 7. 关闭侦听socket
close(listenSock);
return 0;
}
./server 127.0.0.1 9092

5 , socket中TCP连接释放详解
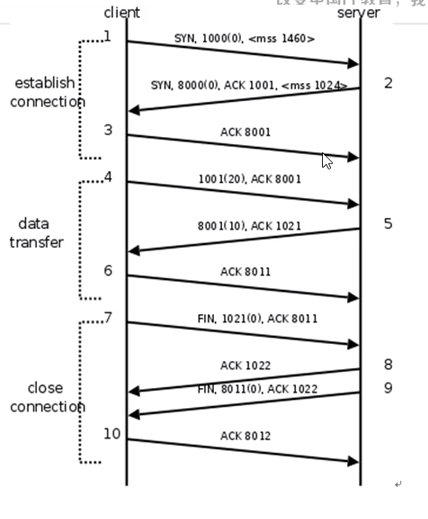
三次握手
四次挥手
套接字格式
流格式套接字(SOCK_STREAM)
流格式套接字(Stream Sockets)也叫“面向连接的套接字”,是一种可靠的、双向的通信数据流,数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送。
其特点:
-
数据在传输过程中不会消失;
数据是按照顺序传输的;
数据的发送和接收不是同步的(有的教程也称“不存在数据边界”)。
可以将 SOCK_STREAM 比喻成一条传送带,只要传送带本身没有问题(不会断网),就能保证数据不丢失;同时,较晚传送的数据不会先到达,较早传送的数据不会晚到达,这就保证了数据是按照顺序传递的。
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达并且没有错误。
你也许见过 TCP,是因为你经常听说“TCP/IP”。TCP 用来确保数据的正确性,IP(Internet Protocol,网络协议)用来控制数据如何从源头到达目的地,也就是常说的“路由”。
那么,“数据的发送和接收不同步”该如何理解呢?
假设传送带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持同步,只要根据自己的节奏来装袋即可,不用管传送带传送了几批,也不用每到一批就装袋一次,可以等到凑够了 100 个水果再装袋。
流格式套接字的内部有一个缓冲区(也就是字符数组),通过 socket 传输的数据将保存到这个缓冲区。接收端在收到数据后并不一定立即读取,只要数据不超过缓冲区的容量,接收端有可能在缓冲区被填满以后一次性地读取,也可能分成好几次读取。
也就是说,不管数据分几次传送过来,接收端只需要根据自己的要求读取,不用非得在数据到达时立即读取。传送端有自己的节奏,接收端也有自己的节奏,它们是不一致的。
流格式套接字有什么实际的应用场景吗?浏览器所使用的 http 协议就基于面向连接的套接字,因为必须要确保数据准确无误,否则加载的 HTML 将无法解析。
数据报格式套接字(SOCK_DGRAM)
数据报格式套接字(Datagram Sockets)也叫“无连接的套接字”。计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。
因为数据报套接字所做的校验工作少,所以在传输效率方面比流格式套接字要高。
-
有以下特征:
强调快速传输而非传输顺序;
传输的数据可能丢失也可能损毁;
限制每次传输的数据大小;
数据的发送和接收是同步的
众所周知,速度是快递行业的生命。用摩托车发往同一地点的两件包裹无需保证顺序,只要以最快的速度交给客户就行。这种方式存在损坏或丢失的风险,而且包裹大小有一定限制。因此,想要传递大量包裹,就得分配发送。
另外,用两辆摩托车分别发送两件包裹,那么接收者也需要分两次接收,所以“数据的发送和接收是同步的”;换句话说,接收次数应该和发送次数相同。
总之,数据报套接字是一种不可靠的、不按顺序传递的、以追求速度为目的的套接字。
数据报套接字也使用 IP 协议作路由,但是它不使用 TCP 协议,而是使用 UDP 协议(User Datagram Protocol,用户数据报协议)。
QQ 视频聊天和语音聊天就使用 SOCK_DGRAM 来传输数据,因为首先要保证通信的效率,尽量减小延迟,而数据的正确性是次要的,即使丢失很小的一部分数据,视频和音频也可以正常解析,最多出现噪点或杂音,不会对通信质量有实质的影响。
注意:SOCK_DGRAM 没有想象中的糟糕,不会频繁的丢失数据,数据错误只是小概率事件。
的“路由”。
那么,“数据的发送和接收不同步”该如何理解呢?
假设传送带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持同步,只要根据自己的节奏来装袋即可,不用管传送带传送了几批,也不用每到一批就装袋一次,可以等到凑够了 100 个水果再装袋。
流格式套接字的内部有一个缓冲区(也就是字符数组),通过 socket 传输的数据将保存到这个缓冲区。接收端在收到数据后并不一定立即读取,只要数据不超过缓冲区的容量,接收端有可能在缓冲区被填满以后一次性地读取,也可能分成好几次读取。
也就是说,不管数据分几次传送过来,接收端只需要根据自己的要求读取,不用非得在数据到达时立即读取。传送端有自己的节奏,接收端也有自己的节奏,它们是不一致的。
流格式套接字有什么实际的应用场景吗?浏览器所使用的 http 协议就基于面向连接的套接字,因为必须要确保数据准确无误,否则加载的 HTML 将无法解析。
数据报格式套接字(SOCK_DGRAM)
数据报格式套接字(Datagram Sockets)也叫“无连接的套接字”。计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。
因为数据报套接字所做的校验工作少,所以在传输效率方面比流格式套接字要高。
-
有以下特征:
强调快速传输而非传输顺序;
传输的数据可能丢失也可能损毁;
限制每次传输的数据大小;
数据的发送和接收是同步的
众所周知,速度是快递行业的生命。用摩托车发往同一地点的两件包裹无需保证顺序,只要以最快的速度交给客户就行。这种方式存在损坏或丢失的风险,而且包裹大小有一定限制。因此,想要传递大量包裹,就得分配发送。
另外,用两辆摩托车分别发送两件包裹,那么接收者也需要分两次接收,所以“数据的发送和接收是同步的”;换句话说,接收次数应该和发送次数相同。
总之,数据报套接字是一种不可靠的、不按顺序传递的、以追求速度为目的的套接字。
数据报套接字也使用 IP 协议作路由,但是它不使用 TCP 协议,而是使用 UDP 协议(User Datagram Protocol,用户数据报协议)。
QQ 视频聊天和语音聊天就使用 SOCK_DGRAM 来传输数据,因为首先要保证通信的效率,尽量减小延迟,而数据的正确性是次要的,即使丢失很小的一部分数据,视频和音频也可以正常解析,最多出现噪点或杂音,不会对通信质量有实质的影响。
注意:SOCK_DGRAM 没有想象中的糟糕,不会频繁的丢失数据,数据错误只是小概率事件。