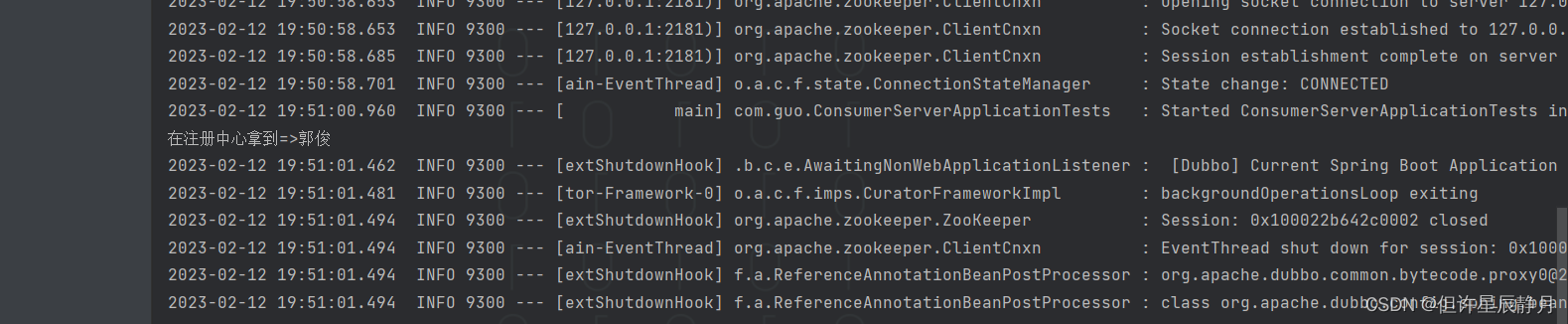
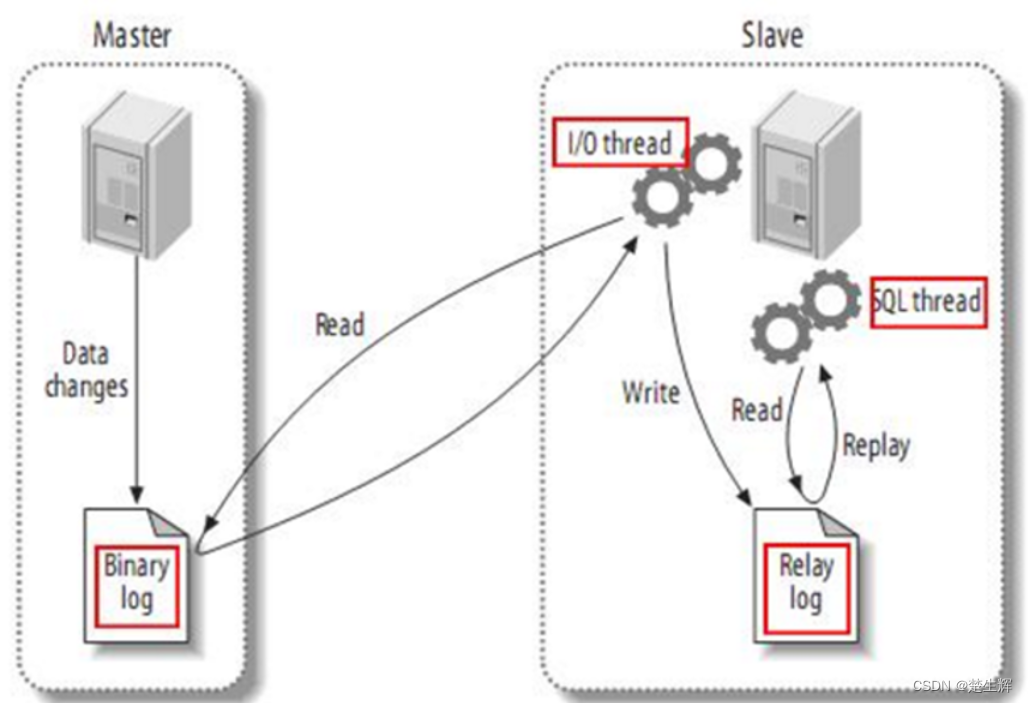
声明:下边的例子均表示下标从1开始的数组
ne数组的定义:
next[i] 就是使子串 s[1…i] 有最长相等前后缀的前缀的最后一位的下标。ne[i]也可以表示相等子串的长度
准备执行j=ne[j]时, 表示当前s[i]!=p[j+1] , 如果ne[j]=1 ,那么下一次匹配从p数组的第二个字符(也就是p[j+1])开始比较是否s[i]=p[j+ 1]
a b a b a b c a b
1 2 3 4 5 6 7 8 9
a b a b a b c a b
1 2 3 4 5 6 7 8 9
同理:ne数组的建立也是这样的,从数组的第二个字符开始枚举,因为第一个字符没有相同的字串,从i=2,j=0,开始枚举,
i=2,j=0 p[i] != p[j+1] ne[2]=0;
i=3,j=0 p[i]==p[j+1] ,j++,ne[3]=1;
i=4,j=1 p[i]==p[j+1] ,j++,ne[4]=2;
i=5,j=2 p[i]==p[j+1] ,j++,ne[5]=3;
i=6,j=3 p[i]==p[j+1] ,j++,ne[6]=4;
i=7,j=4 p[i]!=p[j+1] (此时两者不相等,那么执行j=ne[j] ,j=2,(刚才想样例时发现,为什么下一次比较不直接比较j+1=5,i=7呢?想了一下,其实这和在s数组中和p数组相等的字串问题一样,此时p数组才走到j=4,那么 j 退一下,只能退到 j = ne[i] ) 发现p[i]!=p[j+1],继续执行j=ne[j] ,j=0,所以下一次比较就从0开始比较)
(其实直接看ne数组的更新比较绕,可以对比s数组和p数组的匹配,两者其实是一样的,就上边最后一步 j -----> 0来说,下一次s数组的s[i]要和p数组的p[1]比较)

KMP数组的应用

分析:观察样例发现,每次后边加的都是剔除字符串t的最长的前缀和后缀相等的子串后剩下的字符串,那么就可以用KMP求最长字串的长度(也就是 ne[n] )
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 55;
int n, m;
char str[N];
int ne[N];
int main()
{
scanf("%d%d", &n, &m);
scanf("%s", str + 1);
for (int i = 2, j = 0; i <= n; i ++ )
{
while (j && str[i] != str[j + 1]) j = ne[j];
if (str[i] == str[j + 1]) j ++ ;
ne[i] = j;
}
// cout<<ne[n]<<endl;
printf("%s", str + 1);
for (int i = 0; i < m - 1; i ++ )
printf("%s", str + 1 + ne[n]);
return 0;
}