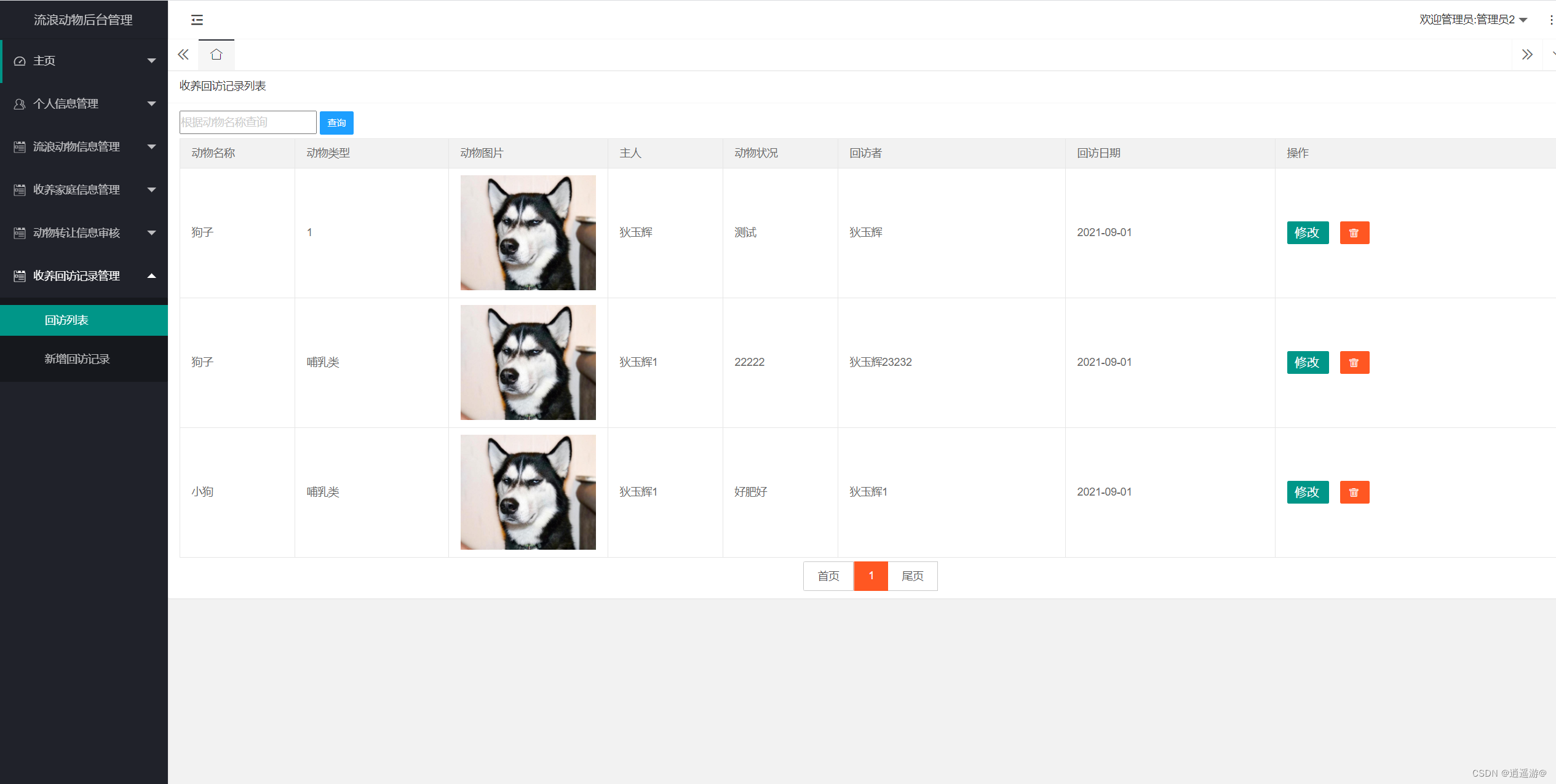
文章目录
- CUDA中的流序内存分配
- 1. Introduction
- 2. Query for Support
- 3. API Fundamentals (cudaMallocAsync and cudaFreeAsync)
- 4. Memory Pools and the cudaMemPool_t
- 注意:设备的内存池当前将是该设备的本地。因此,在不指定内存池的情况下进行分配将始终产生流设备本地的分配。
- 注意:`cudaMemPoolSetAttribute` 和 `cudaMemPoolGetAttribute` 控制内存池的属性。
- 5. Default/Impicit Pools
- 6. Explicit Pools
- 7. Physical Page Caching Behavior
- 8. Resource Usage Statistics
- 9. Memory Reuse Policies
- 9.1. cudaMemPoolReuseFollowEventDependencies
- 9.2. cudaMemPoolReuseAllowOpportunistic
- 9.3. cudaMemPoolReuseAllowInternalDependencies
- 9.4. Disabling Reuse Policies
- 10. Device Accessibility for Multi-GPU Support
- 11. IPC Memory Pools
- 11.1. Creating and Sharing IPC Memory Pools
- 11.2. Set Access in the Importing Process
- 11.3. Creating and Sharing Allocations from an Exported Pool
- 11.4. IPC Export Pool Limitations
- 11.5. IPC Import Pool Limitations
- 12. Synchronization API Actions
- 13. Addendums
- 13.1. cudaMemcpyAsync Current Context/Device Sensitivity
- 13.2. cuPointerGetAttribute Query
- 13.3. cuGraphAddMemsetNode
- 13.4. Pointer Attributes
CUDA中的流序内存分配
1. Introduction
使用 cudaMalloc 和 cudaFree 管理内存分配会导致 GPU 在所有正在执行的 CUDA 流之间进行同步。 Stream Order Memory Allocator 使应用程序能够通过启动到 CUDA 流中的其他工作(例如内核启动和异步拷贝)来对内存分配和释放进行排序。这通过利用流排序语义来重用内存分配来改进应用程序内存使用。分配器还允许应用程序控制分配器的内存缓存行为。当设置了适当的释放阈值时,缓存行为允许分配器在应用程序表明它愿意接受更大的内存占用时避免对操作系统进行昂贵的调用。分配器还支持在进程之间轻松安全地共享分配。
对于许多应用程序,Stream Ordered Memory Allocator 减少了对自定义内存管理抽象的需求,并使为需要它的应用程序创建高性能自定义内存管理变得更加容易。对于已经具有自定义内存分配器的应用程序和库,采用 Stream Ordered Memory Allocator 可以使多个库共享由驱动程序管理的公共内存池,从而减少过多的内存消耗。此外,驱动程序可以根据其对分配器和其他流管理 API 的感知执行优化。最后,Nsight Compute 和 Next-Gen CUDA 调试器知道分配器是其 CUDA 11.3 工具包支持的一部分。
2. Query for Support
用户可以通过使用设备属性 cudaDevAttrMemoryPoolsSupported 调用 cudaDeviceGetAttribute() 来确定设备是否支持流序内存分配器。
从 CUDA 11.3 开始,可以使用 cudaDevAttrMemoryPoolSupportedHandleTypes 设备属性查询 IPC 内存池支持。 以前的驱动程序将返回 cudaErrorInvalidValue,因为这些驱动程序不知道属性枚举。
int driverVersion = 0;
int deviceSupportsMemoryPools = 0;
int poolSupportedHandleTypes = 0;
cudaDriverGetVersion(&driverVersion);
if (driverVersion >= 11020) {
cudaDeviceGetAttribute(&deviceSupportsMemoryPools,
cudaDevAttrMemoryPoolsSupported, device);
}
if (deviceSupportsMemoryPools != 0) {
// `device` supports the Stream Ordered Memory Allocator
}
if (driverVersion >= 11030) {
cudaDeviceGetAttribute(&poolSupportedHandleTypes,
cudaDevAttrMemoryPoolSupportedHandleTypes, device);
}
if (poolSupportedHandleTypes & cudaMemHandleTypePosixFileDescriptor) {
// Pools on the specified device can be created with posix file descriptor-based IPC
}
在查询之前执行驱动程序版本检查可避免在尚未定义属性的驱动程序上遇到 cudaErrorInvalidValue 错误。 可以使用 cudaGetLastError 来清除错误而不是避免它。
3. API Fundamentals (cudaMallocAsync and cudaFreeAsync)
API cudaMallocAsync 和 cudaFreeAsync 构成了分配器的核心。 cudaMallocAsync 返回分配,cudaFreeAsync 释放分配。 两个 API 都接受流参数来定义分配何时变为可用和停止可用。 cudaMallocAsync 返回的指针值是同步确定的,可用于构建未来的工作。 重要的是要注意 cudaMallocAsync 在确定分配的位置时会忽略当前设备/上下文。 相反,cudaMallocAsync 根据指定的内存池或提供的流来确定常驻设备。 最简单的使用模式是分配、使用和释放内存到同一个流中。
void *ptr;
size_t size = 512;
cudaMallocAsync(&ptr, size, cudaStreamPerThread);
// do work using the allocation
kernel<<<..., cudaStreamPerThread>>>(ptr, ...);
// An asynchronous free can be specified without synchronizing the CPU and GPU
cudaFreeAsync(ptr, cudaStreamPerThread);
用户可以使用 cudaFreeAsync() 释放使用 cudaMalloc() 分配的内存。 在自由操作开始之前,用户必须对访问完成做出同样的保证。
cudaMalloc(&ptr, size);
kernel<<<..., stream>>>(ptr, ...);
cudaFreeAsync(ptr, stream);
用户可以使用 cudaFree() 释放使用 cudaMallocAsync 分配的内存。 通过 cudaFree() API 释放此类分配时,驱动程序假定对分配的所有访问都已完成,并且不执行进一步的同步。 用户可以使用 cudaStreamQuery / cudaStreamSynchronize / cudaEventQuery / cudaEventSynchronize / cudaDeviceSynchronize 来保证适当的异步工作完成并且GPU不会尝试访问分配。
cudaMallocAsync(&ptr, size,stream);
kernel<<<..., stream>>>(ptr, ...);
// synchronize is needed to avoid prematurely freeing the memory
cudaStreamSynchronize(stream);
cudaFree(ptr);
4. Memory Pools and the cudaMemPool_t
内存池封装了虚拟地址和物理内存资源,根据内存池的属性和属性进行分配和管理。内存池的主要方面是它所管理的内存的种类和位置。
所有对 cudaMallocAsync 的调用都使用内存池的资源。在没有指定内存池的情况下,cudaMallocAsync API 使用提供的流设备的当前内存池。设备的当前内存池可以使用 cudaDeviceSetMempool 设置并使用 cudaDeviceGetMempool 查询。默认情况下(在没有 cudaDeviceSetMempool 调用的情况下),当前内存池是设备的默认内存池。 cudaMallocFromPoolAsync 的 API cudaMallocFromPoolAsync 和 c++ 重载允许用户指定要用于分配的池,而无需将其设置为当前池。 API cudaDeviceGetDefaultMempool 和 cudaMemPoolCreate 为用户提供内存池的句柄。
注意:设备的内存池当前将是该设备的本地。因此,在不指定内存池的情况下进行分配将始终产生流设备本地的分配。
注意:cudaMemPoolSetAttribute 和 cudaMemPoolGetAttribute 控制内存池的属性。
5. Default/Impicit Pools
可以使用 cudaDeviceGetDefaultMempool API 检索设备的默认内存池。 来自设备默认内存池的分配是位于该设备上的不可迁移设备分配。 这些分配将始终可以从该设备访问。 默认内存池的可访问性可以通过 cudaMemPoolSetAccess 进行修改,并通过 cudaMemPoolGetAccess 进行查询。 由于不需要显式创建默认池,因此有时将它们称为隐式池。 设备默认内存池不支持IPC。
6. Explicit Pools
API cudaMemPoolCreate 创建一个显式池。 目前内存池只能分配设备分配。 分配将驻留的设备必须在属性结构中指定。 显式池的主要用例是 IPC 功能。
// create a pool similar to the implicit pool on device 0
int device = 0;
cudaMemPoolProps poolProps = { };
poolProps.allocType = cudaMemAllocationTypePinned;
poolProps.location.id = device;
poolProps.location.type = cudaMemLocationTypeDevice;
cudaMemPoolCreate(&memPool, &poolProps));
7. Physical Page Caching Behavior
默认情况下,分配器尝试最小化池拥有的物理内存。 为了尽量减少分配和释放物理内存的操作系统调用,应用程序必须为每个池配置内存占用。 应用程序可以使用释放阈值属性 (cudaMemPoolAttrReleaseThreshold) 执行此操作。
释放阈值是池在尝试将内存释放回操作系统之前应保留的内存量(以字节为单位)。 当内存池持有超过释放阈值字节的内存时,分配器将尝试在下一次调用流、事件或设备同步时将内存释放回操作系统。 将释放阈值设置为 UINT64_MAX 将防止驱动程序在每次同步后尝试收缩池。
Cuuint64_t setVal = UINT64_MAX;
cudaMemPoolSetAttribute(memPool, cudaMemPoolAttrReleaseThreshold, &setVal);
将 cudaMemPoolAttrReleaseThreshold 设置得足够高以有效禁用内存池收缩的应用程序可能希望显式收缩内存池的内存占用。 cudaMemPoolTrimTo 允许此类应用程序这样做。 在修剪内存池的占用空间时,minBytesToKeep 参数允许应用程序保留它预期在后续执行阶段需要的内存量。
Cuuint64_t setVal = UINT64_MAX;
cudaMemPoolSetAttribute(memPool, cudaMemPoolAttrReleaseThreshold, &setVal);
// application phase needing a lot of memory from the stream ordered allocator
for (i=0; i<10; i++) {
for (j=0; j<10; j++) {
cudaMallocAsync(&ptrs[j],size[j], stream);
}
kernel<<<...,stream>>>(ptrs,...);
for (j=0; j<10; j++) {
cudaFreeAsync(ptrs[j], stream);
}
}
// Process does not need as much memory for the next phase.
// Synchronize so that the trim operation will know that the allocations are no
// longer in use.
cudaStreamSynchronize(stream);
cudaMemPoolTrimTo(mempool, 0);
// Some other process/allocation mechanism can now use the physical memory
// released by the trimming operation.
8. Resource Usage Statistics
在 CUDA 11.3 中,添加了池属性 cudaMemPoolAttrReservedMemCurrent、cudaMemPoolAttrReservedMemHigh、cudaMemPoolAttrUsedMemCurrent 和 cudaMemPoolAttrUsedMemHigh 来查询池的内存使用情况。
查询池的 cudaMemPoolAttrReservedMemCurrent 属性会报告该池当前消耗的总物理 GPU 内存。 查询池的 cudaMemPoolAttrUsedMemCurrent 会返回从池中分配且不可重用的所有内存的总大小。
cudaMemPoolAttr*MemHigh 属性是记录自上次重置以来各个 cudaMemPoolAttr*MemCurrent 属性达到的最大值的水印。 可以使用 cudaMemPoolSetAttribute API 将它们重置为当前值。
// sample helper functions for getting the usage statistics in bulk
struct usageStatistics {
cuuint64_t reserved;
cuuint64_t reservedHigh;
cuuint64_t used;
cuuint64_t usedHigh;
};
void getUsageStatistics(cudaMemoryPool_t memPool, struct usageStatistics *statistics)
{
cudaMemPoolGetAttribute(memPool, cudaMemPoolAttrReservedMemCurrent, statistics->reserved);
cudaMemPoolGetAttribute(memPool, cudaMemPoolAttrReservedMemHigh, statistics->reservedHigh);
cudaMemPoolGetAttribute(memPool, cudaMemPoolAttrUsedMemCurrent, statistics->used);
cudaMemPoolGetAttribute(memPool, cudaMemPoolAttrUsedMemHigh, statistics->usedHigh);
}
// resetting the watermarks will make them take on the current value.
void resetStatistics(cudaMemoryPool_t memPool)
{
cuuint64_t value = 0;
cudaMemPoolSetAttribute(memPool, cudaMemPoolAttrReservedMemHigh, &value);
cudaMemPoolSetAttribute(memPool, cudaMemPoolAttrUsedMemHigh, &value);
}
9. Memory Reuse Policies
为了服务分配请求,驱动程序在尝试从操作系统分配更多内存之前尝试重用之前通过 cudaFreeAsync() 释放的内存。 例如,流中释放的内存可以立即重新用于同一流中的后续分配请求。 类似地,当一个流与 CPU 同步时,之前在该流中释放的内存可以重新用于任何流中的分配。
流序分配器有一些可控的分配策略。 池属性 cudaMemPoolReuseFollowEventDependencies、cudaMemPoolReuseAllowOpportunistic 和 cudaMemPoolReuseAllowInternalDependencies 控制这些策略。 升级到更新的 CUDA 驱动程序可能会更改、增强、增加或重新排序重用策略。
9.1. cudaMemPoolReuseFollowEventDependencies
在分配更多物理 GPU 内存之前,分配器会检查由 CUDA 事件建立的依赖信息,并尝试从另一个流中释放的内存中进行分配。
cudaMallocAsync(&ptr, size, originalStream);
kernel<<<..., originalStream>>>(ptr, ...);
cudaFreeAsync(ptr, originalStream);
cudaEventRecord(event,originalStream);
// waiting on the event that captures the free in another stream
// allows the allocator to reuse the memory to satisfy
// a new allocation request in the other stream when
// cudaMemPoolReuseFollowEventDependencies is enabled.
cudaStreamWaitEvent(otherStream, event);
cudaMallocAsync(&ptr2, size, otherStream);
9.2. cudaMemPoolReuseAllowOpportunistic
根据 cudaMemPoolReuseAllowOpportunistic 策略,分配器检查释放的分配以查看是否满足释放的流序语义(即流已通过释放指示的执行点)。 禁用此功能后,分配器仍将重用在流与 cpu 同步时可用的内存。 禁用此策略不会阻止 cudaMemPoolReuseFollowEventDependencies 应用。
cudaMallocAsync(&ptr, size, originalStream);
kernel<<<..., originalStream>>>(ptr, ...);
cudaFreeAsync(ptr, originalStream);
// after some time, the kernel finishes running
wait(10);
// When cudaMemPoolReuseAllowOpportunistic is enabled this allocation request
// can be fulfilled with the prior allocation based on the progress of originalStream.
cudaMallocAsync(&ptr2, size, otherStream);
9.3. cudaMemPoolReuseAllowInternalDependencies
如果无法从操作系统分配和映射更多物理内存,驱动程序将寻找其可用性取决于另一个流的待处理进度的内存。 如果找到这样的内存,驱动程序会将所需的依赖项插入分配流并重用内存。
cudaMallocAsync(&ptr, size, originalStream);
kernel<<<..., originalStream>>>(ptr, ...);
cudaFreeAsync(ptr, originalStream);
// When cudaMemPoolReuseAllowInternalDependencies is enabled
// and the driver fails to allocate more physical memory, the driver may
// effectively perform a cudaStreamWaitEvent in the allocating stream
// to make sure that future work in ‘otherStream’ happens after the work
// in the original stream that would be allowed to access the original allocation.
cudaMallocAsync(&ptr2, size, otherStream);
9.4. Disabling Reuse Policies
虽然可控重用策略提高了内存重用,但用户可能希望禁用它们。 允许机会重用(即 cudaMemPoolReuseAllowOpportunistic)基于 CPU 和 GPU 执行的交错引入了运行到运行分配模式的差异。 当用户宁愿在分配失败时显式同步事件或流时,内部依赖插入(即 cudaMemPoolReuseAllowInternalDependencies)可以以意想不到的和潜在的非确定性方式序列化工作。
10. Device Accessibility for Multi-GPU Support
就像通过虚拟内存管理 API 控制的分配可访问性一样,内存池分配可访问性不遵循 cudaDeviceEnablePeerAccess 或 cuCtxEnablePeerAccess。相反,API cudaMemPoolSetAccess 修改了哪些设备可以访问池中的分配。默认情况下,可以从分配所在的设备访问分配。无法撤销此访问权限。要启用其他设备的访问,访问设备必须与内存池的设备对等;检查 cudaDeviceCanAccessPeer。如果未检查对等功能,则设置访问可能会失败并显示 cudaErrorInvalidDevice。如果没有从池中进行分配,即使设备不具备对等能力,cudaMemPoolSetAccess 调用也可能成功;在这种情况下,池中的下一次分配将失败。
值得注意的是,cudaMemPoolSetAccess 会影响内存池中的所有分配,而不仅仅是未来的分配。此外,cudaMemPoolGetAccess 报告的可访问性适用于池中的所有分配,而不仅仅是未来的分配。建议不要频繁更改给定 GPU 的池的可访问性设置;一旦池可以从给定的 GPU 访问,它应该在池的整个生命周期内都可以从该 GPU 访问。
// snippet showing usage of cudaMemPoolSetAccess:
cudaError_t setAccessOnDevice(cudaMemPool_t memPool, int residentDevice,
int accessingDevice) {
cudaMemAccessDesc accessDesc = {};
accessDesc.location.type = cudaMemLocationTypeDevice;
accessDesc.location.id = accessingDevice;
accessDesc.flags = cudaMemAccessFlagsProtReadWrite;
int canAccess = 0;
cudaError_t error = cudaDeviceCanAccessPeer(&canAccess, accessingDevice,
residentDevice);
if (error != cudaSuccess) {
return error;
} else if (canAccess == 0) {
return cudaErrorPeerAccessUnsupported;
}
// Make the address accessible
return cudaMemPoolSetAccess(memPool, &accessDesc, 1);
}
11. IPC Memory Pools
支持 IPC 的内存池允许在进程之间轻松、高效和安全地共享 GPU 内存。 CUDA 的 IPC 内存池提供与 CUDA 的虚拟内存管理 API 相同的安全优势。
在具有内存池的进程之间共享内存有两个阶段。 进程首先需要共享对池的访问权限,然后共享来自该池的特定分配。 第一阶段建立并实施安全性。 第二阶段协调每个进程中使用的虚拟地址以及映射何时需要在导入过程中有效。
11.1. Creating and Sharing IPC Memory Pools
共享对池的访问涉及检索池的 OS 本机句柄(使用 cudaMemPoolExportToShareableHandle() API),使用通常的 OS 本机 IPC 机制将句柄转移到导入进程,并创建导入的内存池(使用 cudaMemPoolImportFromShareableHandle() API)。 要使 cudaMemPoolExportToShareableHandle 成功,必须使用池属性结构中指定的请求句柄类型创建内存池。 请参考示例以了解在进程之间传输操作系统本机句柄的适当 IPC 机制。 该过程的其余部分可以在以下代码片段中找到。
// in exporting process
// create an exportable IPC capable pool on device 0
cudaMemPoolProps poolProps = { };
poolProps.allocType = cudaMemAllocationTypePinned;
poolProps.location.id = 0;
poolProps.location.type = cudaMemLocationTypeDevice;
// Setting handleTypes to a non zero value will make the pool exportable (IPC capable)
poolProps.handleTypes = CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR;
cudaMemPoolCreate(&memPool, &poolProps));
// FD based handles are integer types
int fdHandle = 0;
// Retrieve an OS native handle to the pool.
// Note that a pointer to the handle memory is passed in here.
cudaMemPoolExportToShareableHandle(&fdHandle,
memPool,
CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR,
0);
// The handle must be sent to the importing process with the appropriate
// OS specific APIs.
// in importing process
int fdHandle;
// The handle needs to be retrieved from the exporting process with the
// appropriate OS specific APIs.
// Create an imported pool from the shareable handle.
// Note that the handle is passed by value here.
cudaMemPoolImportFromShareableHandle(&importedMemPool,
(void*)fdHandle,
CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR,
0);
11.2. Set Access in the Importing Process
导入的内存池最初只能从其常驻设备访问。 导入的内存池不继承导出进程设置的任何可访问性。 导入过程需要启用从它计划访问内存的任何 GPU 的访问(使用 cudaMemPoolSetAccess)。
如果导入的内存池在导入过程中属于不可见的设备,则用户必须使用 cudaMemPoolSetAccess API 来启用从将使用分配的 GPU 的访问。
11.3. Creating and Sharing Allocations from an Exported Pool
共享池后,在导出进程中使用 cudaMallocAsync() 从池中进行的分配可以与已导入池的其他进程共享。由于池的安全策略是在池级别建立和验证的,操作系统不需要额外的簿记来为特定的池分配提供安全性;换句话说,导入池分配所需的不透明 cudaMemPoolPtrExportData 可以使用任何机制发送到导入进程。
虽然分配可以在不以任何方式与分配流同步的情况下导出甚至导入,但在访问分配时,导入过程必须遵循与导出过程相同的规则。即,对分配的访问必须发生在分配流中分配操作的流排序之后。以下两个代码片段显示 cudaMemPoolExportPointer() 和 cudaMemPoolImportPointer() 与 IPC 事件共享分配,用于保证在分配准备好之前在导入过程中不会访问分配。
// preparing an allocation in the exporting process
cudaMemPoolPtrExportData exportData;
cudaEvent_t readyIpcEvent;
cudaIpcEventHandle_t readyIpcEventHandle;
// IPC event for coordinating between processes
// cudaEventInterprocess flag makes the event an IPC event
// cudaEventDisableTiming is set for performance reasons
cudaEventCreate(
&readyIpcEvent, cudaEventDisableTiming | cudaEventInterprocess)
// allocate from the exporting mem pool
cudaMallocAsync(&ptr, size,exportMemPool, stream);
// event for sharing when the allocation is ready.
cudaEventRecord(readyIpcEvent, stream);
cudaMemPoolExportPointer(&exportData, ptr);
cudaIpcGetEventHandle(&readyIpcEventHandle, readyIpcEvent);
// Share IPC event and pointer export data with the importing process using
// any mechanism. Here we copy the data into shared memory
shmem->ptrData = exportData;
shmem->readyIpcEventHandle = readyIpcEventHandle;
// signal consumers data is ready
// Importing an allocation
cudaMemPoolPtrExportData *importData = &shmem->prtData;
cudaEvent_t readyIpcEvent;
cudaIpcEventHandle_t *readyIpcEventHandle = &shmem->readyIpcEventHandle;
// Need to retrieve the IPC event handle and the export data from the
// exporting process using any mechanism. Here we are using shmem and just
// need synchronization to make sure the shared memory is filled in.
cudaIpcOpenEventHandle(&readyIpcEvent, readyIpcEventHandle);
// import the allocation. The operation does not block on the allocation being ready.
cudaMemPoolImportPointer(&ptr, importedMemPool, importData);
// Wait for the prior stream operations in the allocating stream to complete before
// using the allocation in the importing process.
cudaStreamWaitEvent(stream, readyIpcEvent);
kernel<<<..., stream>>>(ptr, ...);
释放分配时,需要先在导入过程中释放分配,然后在导出过程中释放分配。 以下代码片段演示了使用 CUDA IPC 事件在两个进程中的 cudaFreeAsync 操作之间提供所需的同步。 导入过程中对分配的访问显然受到导入过程侧的自由操作的限制。 值得注意的是,cudaFree 可用于释放两个进程中的分配,并且可以使用其他流同步 API 代替 CUDA IPC 事件。
// The free must happen in importing process before the exporting process
kernel<<<..., stream>>>(ptr, ...);
// Last access in importing process
cudaFreeAsync(ptr, stream);
// Access not allowed in the importing process after the free
cudaIpcEventRecord(finishedIpcEvent, stream);
// Exporting process
// The exporting process needs to coordinate its free with the stream order
// of the importing process’s free.
cudaStreamWaitEvent(stream, finishedIpcEvent);
kernel<<<..., stream>>>(ptrInExportingProcess, ...);
// The free in the importing process doesn’t stop the exporting process
// from using the allocation.
cudFreeAsync(ptrInExportingProcess,stream);
11.4. IPC Export Pool Limitations
IPC 池目前不支持将物理块释放回操作系统。 因此,cudaMemPoolTrimTo API 充当空操作,并且 cudaMemPoolAttrReleaseThreshold 被有效地忽略。 此行为由驱动程序控制,而不是运行时控制,并且可能会在未来的驱动程序更新中发生变化。
11.5. IPC Import Pool Limitations
不允许从导入池中分配; 具体来说,导入池不能设置为当前,也不能在 cudaMallocFromPoolAsync API 中使用。 因此,分配重用策略属性对这些池没有意义。
IPC 池目前不支持将物理块释放回操作系统。 因此,cudaMemPoolTrimTo API 充当空操作,并且 cudaMemPoolAttrReleaseThreshold 被有效地忽略。
资源使用统计属性查询仅反映导入进程的分配和相关的物理内存。
12. Synchronization API Actions
作为 CUDA 驱动程序一部分的分配器带来的优化之一是与同步 API 的集成。 当用户请求 CUDA 驱动程序同步时,驱动程序等待异步工作完成。 在返回之前,驱动程序将确定什么释放了保证完成的同步。 无论指定的流或禁用的分配策略如何,这些分配都可用于分配。 驱动程序还在这里检查 cudaMemPoolAttrReleaseThreshold 并释放它可以释放的任何多余的物理内存。
13. Addendums
13.1. cudaMemcpyAsync Current Context/Device Sensitivity
在当前的 CUDA 驱动程序中,任何涉及来自 cudaMallocAsync 的内存的异步 memcpy 都应该使用指定流的上下文作为调用线程的当前上下文来完成。 这对于 cudaMemcpyPeerAsync 不是必需的,因为引用了 API 中指定的设备主上下文而不是当前上下文。
13.2. cuPointerGetAttribute Query
在对分配调用 cudaFreeAsync 后在分配上调用 cuPointerGetAttribute 会导致未定义的行为。 具体来说,分配是否仍然可以从给定的流中访问并不重要:行为仍然是未定义的。
13.3. cuGraphAddMemsetNode
cuGraphAddMemsetNode 不适用于通过流排序分配器分配的内存。 但是,分配的 memset 可以被流捕获。
13.4. Pointer Attributes
cuPointerGetAttributes 查询适用于流有序分配。 由于流排序分配与上下文无关,因此查询 CU_POINTER_ATTRIBUTE_CONTEXT 将成功,但在 *data 中返回 NULL。 属性 CU_POINTER_ATTRIBUTE_DEVICE_ORDINAL 可用于确定分配的位置:这在选择使用 cudaMemcpyPeerAsync 制作 p2h2p 拷贝的上下文时很有用。 CU_POINTER_ATTRIBUTE_MEMPOOL_HANDLE 属性是在 CUDA 11.3 中添加的,可用于调试和在执行 IPC 之前确认分配来自哪个池。
更多精彩内容:
https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561