常用组件大白话说
如果想要官方的,详细的信息,请看官方文档。
https://kubernetes.io/zh-cn/docs/concepts/overview/components/
现在介绍一些核心的概念:
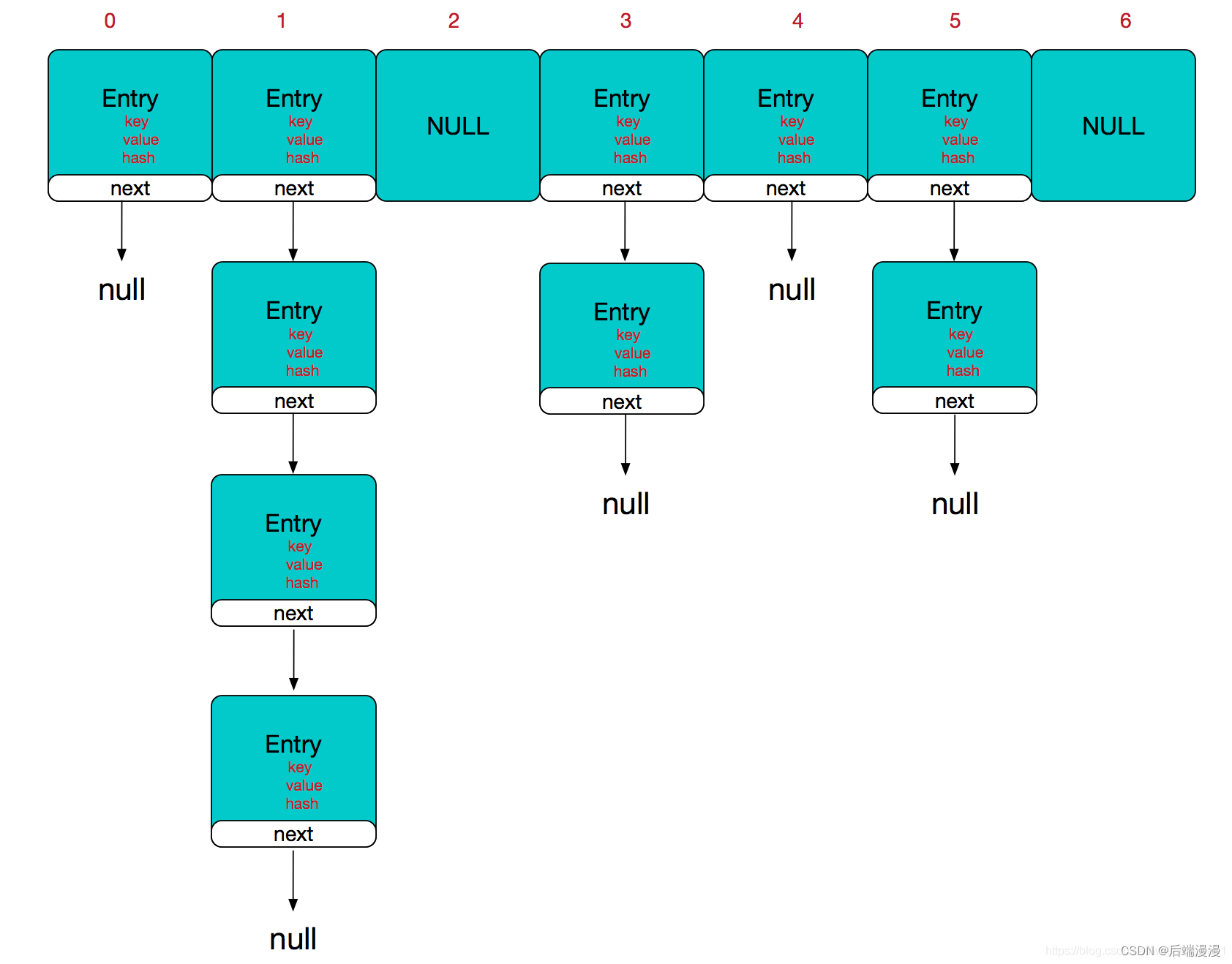
- etcd:存储所有节点的信息,节点上部署的容器信息等都存在数据库,这是一个key-value的数据库,和redis差不多。
- api-server:k8s作为一个高级的容器管理平台,对每一个发来的请求都要进行校验,该请求是否被集群允许。删除集群中的一个容器组,是否被允许。k8s默认运行后,6个组件每一个组件的请求,都要经过api-server进行校验。
- controller manager:具体部署容器到目标节点,使用的控制器。容器负载均衡部署,Deployment控制器就是其中之一。
- scheduler:运维写nginx.yaml(描述信息),预期部署3个nginx容器到k8s-node2节点上。将Pod调度到相应的Node机器上。
- kubelet:管理目标节点中Pod的进程。
- kubectl:在master节点上敲打的命令。
- kube-proxy:在node节点中我们可以看到有kubectl和kube-proxy。kubectl用于和master的api-server通信决定容器创建时的信息获取,信息更新。而kube-proxy则是pod要对外提供网络访问,底层基于iptables的规则转发数据包,修改数据包。
我们来用一个例子来理解生动的理解这些东西。
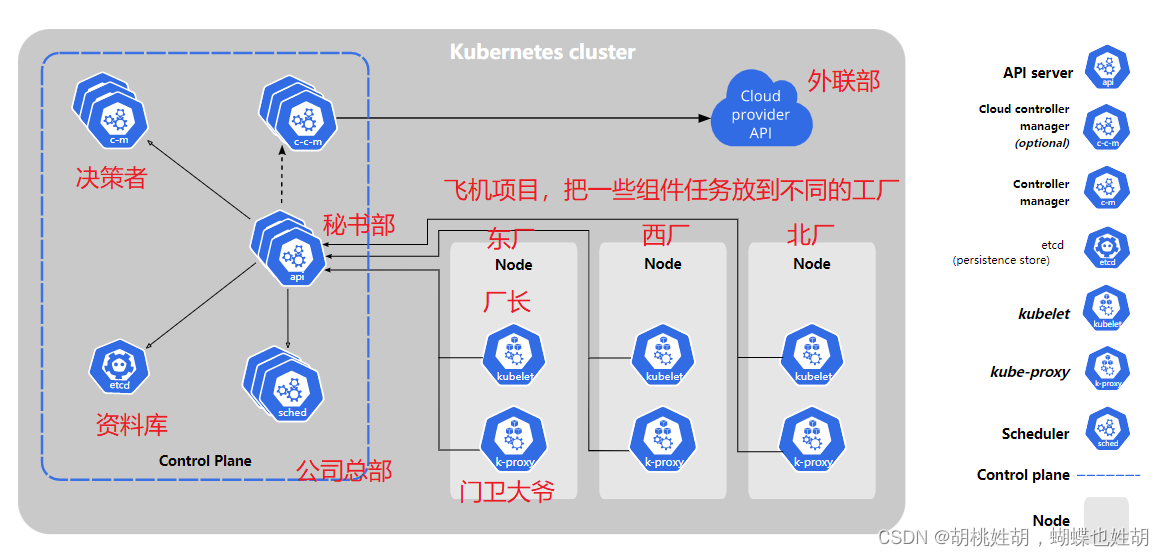
Kubernetes cluster成为硅谷集团,类似于腾讯集团,阿里集团。
而Master集群就是硅谷集团的总部(Controller Plane),负责决策的。节点集群就是硅谷集团用来专门做事情的工厂(Node)。
每一个Node节点所擅长的不一样,比如有的Node内存大,有的Node存储空间大,有的Node在当前的情况下网络环境比较好等等。
加入说有一天,我准备完成一个飞机项目,那么我的硅谷总部需要做一些决策,计划的实施等,而飞机项目的具体实现就交给Node节点来做。我们首先需要一个决策者。决策者(c-m)负责这个项目的具体操作步骤,例如撰写相关的实施方案和资料。当然,我们撰写了相关的实施方案和资料之后,需要交给一个人去管理这些资料,把这些资料存放在一个地方整理起来,因此我们需要一个资料库,etcd(这个就是键值对的数据库而已)。而我的决策者可不能直接把资料给资料库,我们需要一个中间人,你看到过哪个领导没有秘书的吗,这也算是一种任务分工,一种解耦合。我们c-m需要把资料先给秘书部(API Server)。这个时候我的Controller Plane硅谷总部准备过去看一下工厂的项目执行进度,或者做一些指导,所以我们需要一个调度者(scheduler),当然调度者做这一间事情也是通过秘书去做的。当我要查看东厂的时候,一个厂(Node)里面一定是有一个门卫(kube-proxy)的,一些非法人士是无法进入我的工厂的,并且如果你假如要去西厂,但是你走错厂了,去了东厂,那么东厂的门卫大爷就会对你进行一些指导,引导你去相应的位置,引导你的网络访问。当我去一个工厂视察的时候,我不可能逐一的询问工厂里面的每一个员工,所以我们一定要有一个厂长(kubulet),厂长可以有决策权把这个厂停了,或者进行只会,Master里面也会有一个厂长。厂长对本工厂的健康情况等进行一个汇总和汇报。我们知道,一个公司,例如阿里云,它不可能是孤身一人的,它一定是会有合作伙伴,或者是一些其他帮手的,也就是Master里面的c-c-m,我们可以理解成外联部,外联部提供一些其他的支持以及合作。外联部就Cloud provider API了,为什么叫做云,云其实就是不是你自己的东西,你用的别人的东西,其实就是云。
了解了kubernetes的基本组件之后,我们来讲述一下k8s组件的工作流程。
kubernetes组件的工作流程
我们先自定义一个需求背景:
创建一个无状态的nginx引用,部署一个pod即可
流程如下:
-
在master节点写yaml描述你对容器的运行要求,创建pod的要求。install-pod.yaml
-
使用kubectl命令去创建,应用这个资源描述文件,因此k8s组件交互发出请求,我要创建一个pod去运行nginx了,那么请求应该发给谁呢?
kubectl create -f install-nginx.yaml这个请求发给api-server。
-
api-server此时会验证kubectl命令发来的请求是否被允许。利用本地https证书,这个证书是直接写入Kubectl配置文件里面的,该请求被允许之后才会执行。
-
api-server将nginx-pod创建的信息记录到etcd数据库中(数据库记录了一些信息,例如nginx镜像版本,容器名,是否要端口暴露)。
-
api-server会通知下一个组件,调度器组件,scheduler准备pod调度。
-
scheduler调度,会去etcd里面查询,部署的pod信息到底是如何,然后判定出一个合适的node节点去部署pod(选择了好了具体的机器,但是还没有执行)
-
scheduler调度器,会告诉api-server自己决定pod要部署到哪台node节点上。
-
api-server会把这个信息再次写入到etcd中,数据更新了(nginx本身的容器信息+绑定关系,部署到哪个机器上面)
-
此时api-server会通知远程的具体机器,比如k8s-node2上的工作进程kubelet,去读取etcd里面的信息,根据这些信息创建nginx镜像,以及创建Pod(nginx容器)。
首先我们的运行环境必须是容器运行时的环境,例如Docker,因为容器具有隔离性。
我们的Master和Node之间的交互必须要通过api-server来进行转发,包括Master内部。kube-proxy是实现网络转发的,是实现负载均衡的一个重要器具。kubelet有权利让Node里面如何做事情。
现在我们来进行一些过程的描述。
假如我的的一个Node里面的应用2直接崩了,那么我的kubelet厂长会定时对Node里面的应用进行探测,kubelet会随时对工厂里面的流水线进行探测。当kubelet发现应用二崩了,那么它就有权利直接把应用2停了。如果我们的kubelet发现我们的当前的Node已经无法完成这个任务了的话,那么kubelet就会把这个情况直接发给api-server,api-server会转发给决策者controller-manager,然后决策者就可以进行决策了,决策者可以指定,那么这个任务我不搞了,或者给其他的厂去搞。然后把这个决策给api-server,api-server会把这个决策转发到ETCD数据库进行保存。如果是交给其他的厂来搞的话,那么如何知道那些厂可以完成这个任务呢?这个时候api-server就会把这个任务发送给scheduler,scheduler得知这个任务之后,我们的scheduler决策者就会去轮询的查找符合条件的节点,然后选择一个最佳的节点,scheduler把它选择的节点给api-server,然后api-server就把这一条记录存放到ETCD数据库里面了。
这次决策完成之后,kubelet和api-server会经常“通电话”进行联系,如果要换厂的话,那么他们是可以知道这个信息的。知道了这个信息之后对应的kubelet就会启动相应的应用。并且kubelet每过一段时间就要向api-server进行汇报。就跟厂长跟老板汇报工作一样。
如果这个项目跑起来了,需要别人访问怎么办?
kube-proxy是门卫大爷,而且门卫大爷都很喜欢相互打电话联系,所以知道其他的情况。例如我的应用1想要访问应用3的话,那么kube-proxy会告诉你所有的应用三的地址。
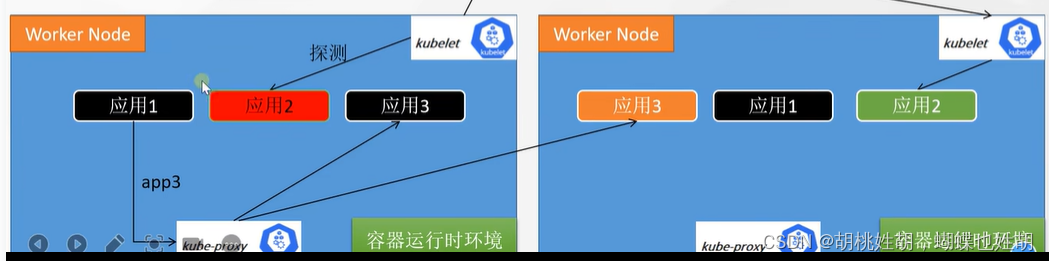
门卫大爷互相同步
所以kube-proxy是用来决定我的应用去哪里访问的,是负载均衡实现的源头。