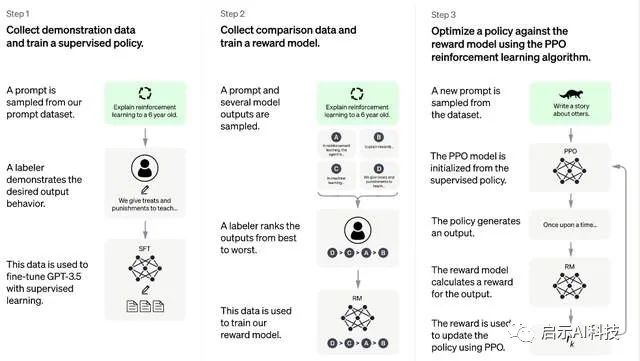
文章目录
- 一、HashMap源码
- 二、HashMap数据结构模型图
- 三、HashMap中如何确定元素位置
- 四、关于equals与hashCode函数的重写
- 五、阅读源码
- 基本属性
参考文章:史上最详细的 JDK 1.8 HashMap 源码解析
参考文章:Hash详解
参考文章:hashCode源码分析
参考文章:hashCode方法
参考文章:Java 细品 重写equals方法 和 hashcode 方法
参考文章:native
参考文章:HashMap中确定数组位置为什么要用hash进行扰动
一、HashMap源码
JDK官方文档源码,方便后面对照学习
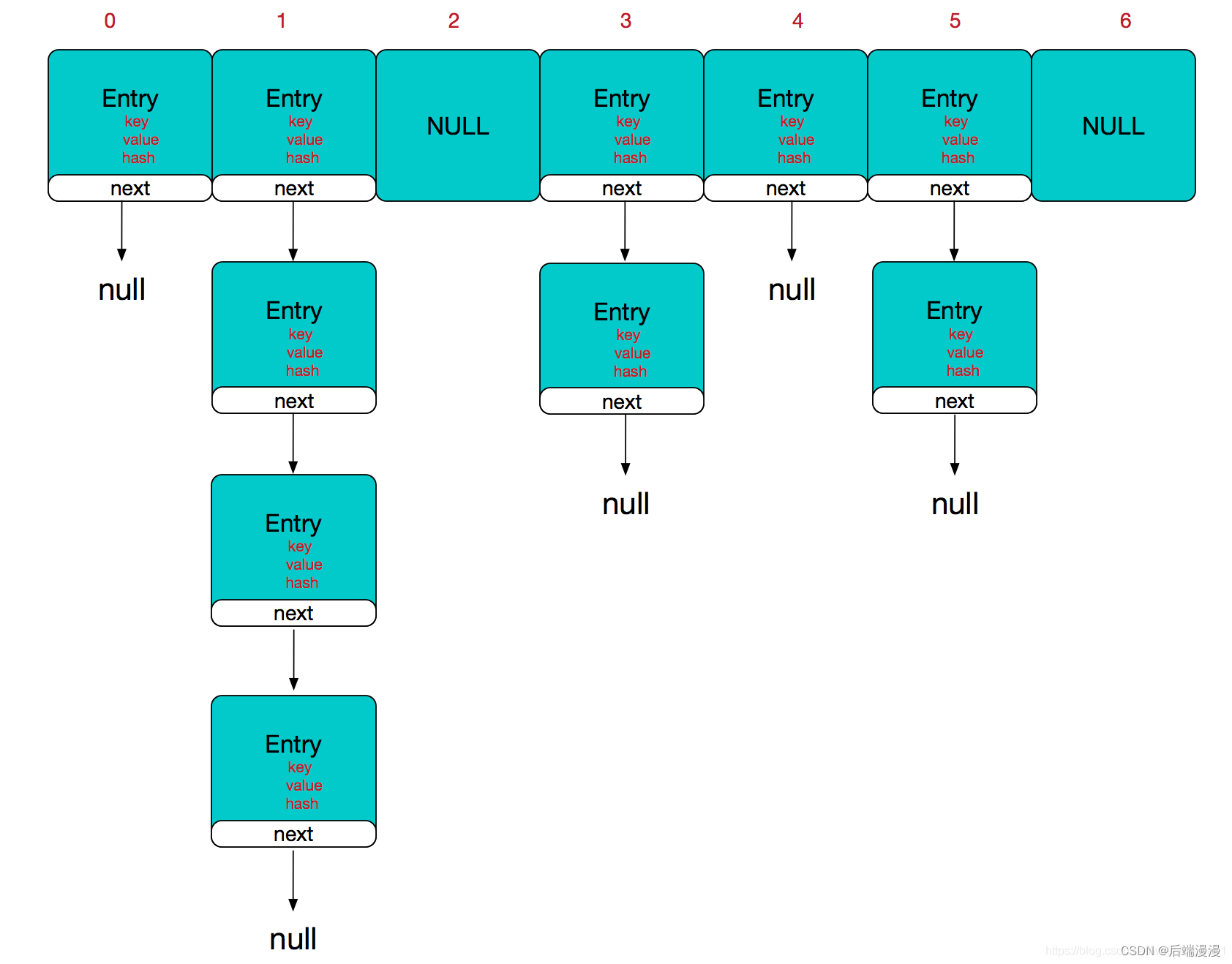
二、HashMap数据结构模型图
JDK1.8对HashMap进行了比较大的优化,底层实现由之前的“数组+链表”改为“数组+链表+红黑树”。JDK1.8的HashMap的数据结构如下图所示,当链表结点较少时仍然是以链表存在,当链表结点较多时(大于8)会转为红黑树。
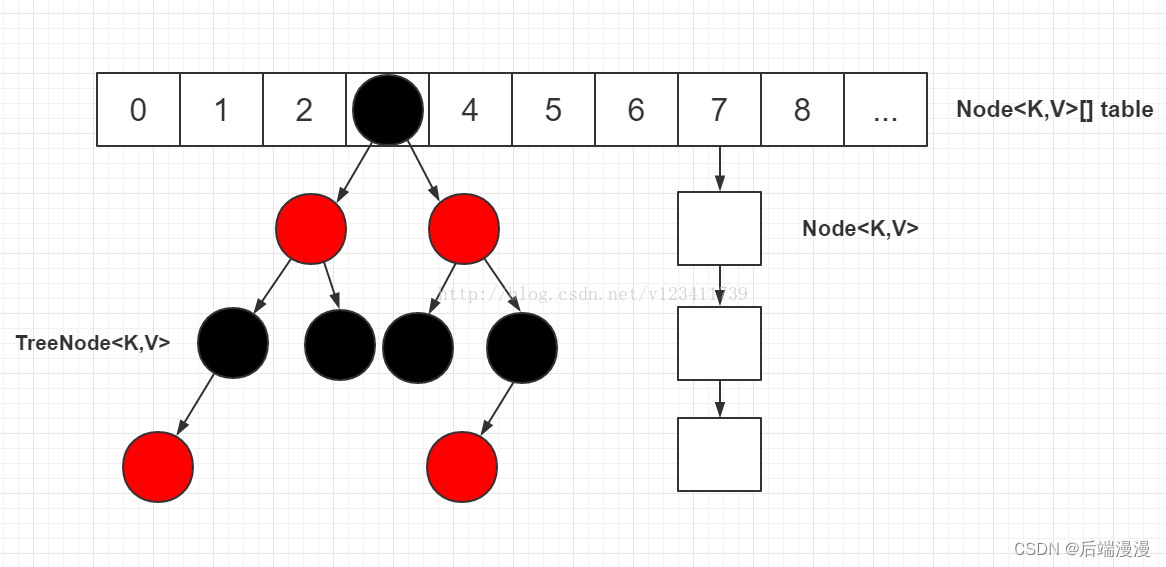
三、HashMap中如何确定元素位置
- 通过key.hashcode(),根据key获得hashcode值
- 通过扰动函数hash(),根据hashcode获得hash值
- 通过**(n-1)&hash**判断当前元素存放的位置,这里的n指的是数组的长度
- 上面三个“通过”才可以获取真正意义上hashCode,即table的位置。
- 如果当前位置存在元素的话,equals() 就判断该元素与要存入的元素的hash值以及key是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突
其中jdk1.8中扰动函数hash的源码:
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
其中看到在获得hash值时将key的hashCode异或上其无符号右移16位,Hashmap这么做原因:
防止一些实现比较差的 hashCode() 方法,使用扰动函数之后可以减少碰撞,进一步降低hash冲突的几率。
四、关于equals与hashCode函数的重写
首先我们必须知道,如果我们要使用HashMap来添加以对象作为key的键值对,那么就必须重写equals和hashCode函数。具体看 “三、HashMap中如何确定元素位置。”
我们先来看一下,没有重写的hashCode和equals的源码,不用怀疑,这就是全部源码。
//返回对象在JVM中的32位内存地址,native解释请看参看文章
public native int hashCode();
//比较两个对象的32位内存地址
public boolean equals(Object obj) { return (this == obj); }
为什么我们需要重写hashCode和equals呢?不重写会怎样呢?看看下面示例
public class Student {
private String name;
private Integer age;
}
/*
我现在用同一个人(John,21),创建两个对象student1和student2。
由于这两个对象是同一个人,所以这两个对象是相等的,但是结果却是false。
*/
public static void main(String[] args) {
Student student1 = new Student();
student1.setName("John");
student1.setAge("21");
Student student2 = new Student();
student2.setName("John");
student2.setAge("21");
System.out.println(student1.equals(student2)); //false
System.out.println(student1.hashCode() == student2.hashCode()); //false
}
明明是同一个人(John,22),为什么两个对象就不相等呢?因为我们认为的两个对象相等是根据属性的值来判断的,例如student1和student2都是name=John、age=21,那么我就认为他们是相等的。但是我们再来看看Object的hashCode和equals源码,它才不管student1和student2的属性值是否相等,只要两个对象内存地址不一样就是不相等。
这时候我们就知道要重写hashCode和equals,那么我们重写这两个方法的原则是什么?
- hashCode重写:要根据类的属性值来生成hashCode
- equals重写:要根据类的属性值来进行判断
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
boolean nameCheck=false;
boolean ageCheck=false;
if (this.name == student.name) {
nameCheck = true;
} else if (this.name != null && this.name.equals(student.name)) {
nameCheck = true;
}
if (this.age == student.age) {
ageCheck = true;
} else if (this.age != null && this.age.equals(student.age)) {
ageCheck = true;
}
if (nameCheck && ageCheck){
return true;
}
return false;
@Override
public int hashCode() {
int result = 17;
result = 31 * result + name.hashCode();
result = 31 * result + age;
return result;
}
现在再来测试一下
public static void main(String[] args) {
Student student1 = new Student();
student1.setName("John");
student1.setAge("21");
Student student2 = new Student();
student2.setName("John");
student2.setAge("21");
System.out.println(student1.equals(student2)); //true
System.out.println(student1.hashCode() == student2.hashCode()); //true
}
重写equals和hashCode,是指我们在开发项目的时候,要根据自己创建对象来重写。例如我创建了Student类里面有name,id,那么我在重写equals和hashCode时候就要有对name和id的比较判断,如果我创建了Animal类里面有age,owner,那么我在重写equals和hashCode时候就要有对age和owner的比较判断
其实在java 7 有在Objects里面新增了我们需要重新的这两个方法,所以我们重写equals和hashCode还可以使用java自带的Objects,如:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Pig pig = (Pig) o;
return Objects.equals(name, pig.name) &&
Objects.equals(age, pig.age);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
那么如果还是觉得有点麻烦呢? 那就使用lombok的注解,让它帮我们写,我们自己就写个注解!
@EqualsAndHashCode(exclude = {"Age"}) //设置重写不包含的字段
public class Student{
private String name;
private Integer age;
}
五、阅读源码
HashMap在重点其实就是第三、四点,这里对源码再解读一下。
基本属性
// 默认容量16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认负载因子0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表节点转换红黑树节点的阈值, 当链表结点大于8时,转成红黑树结点
static final int TREEIFY_THRESHOLD = 8;
// 红黑树节点转换链表节点的阈值, 当红黑树结点小于7时,转成链表结点
static final int UNTREEIFY_THRESHOLD = 6;
// 转红黑树时, table的最小长度
static final int MIN_TREEIFY_CAPACITY = 64;
// 链表节点, 继承自Entry
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// ... ...
}
// 红黑树节点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
// ...
}