开场
最近chatgpt已经火爆了,几乎是家喻户晓老少皆知啊,公测推出60天后就已经是UV人数过亿,日访问量号称也是过亿。投资chatgpt研发团队的微软也是2个月内迅速推出自己的chatgpt的bing搜索,股票下载量都是暴增啊。前面文章已经介绍过chatgpt技术可能会对整个人类组织分工带来的影响以及原因,这里就不在继续歪歪了。
chatgpt的一些思考
从这篇文章开始,我打算实现一个mini版本的chatgpt,把背后的原理算法、数据准备工作都会介绍到。这系列文章预计会有7-8篇,主要是讲实现,不会介绍transformer模型技术细节、ppo数学推理。
到最后大家可以收获一个问答式的文本生成工具,大家也可以根据自己需要定制训练自己的模型做自己想要做的事,比如一个跟懂自己智能助理、解读论文的神器、可以通过语音方式理解需求帮你控制智能家居、通过语音帮你画一幅你想要的画...
第一篇先介绍整个RLHF大训练框架,介绍SFT模型训练:数据、基本模型。先介绍单个模型大家先熟悉代码在自己机器上试跑训练下数据。
第二部分会对模型改造、代码封装,让代码能够在多卡多机上训练;更工业风。
第三部分把流程封装,三部分的代码做一个整合,到这边你就可以得到一个真正能够训练中文语料的链路框架,并且可以自己准备训练标注语料。
第四部分会给大家介绍基于这个小的chatgpt引擎做的各种应用探索。
宏观介绍

整个链路包括三块:
文本生成AGGENT,为了得到一个不错Agent我们需要用‘输入-输出’语料对训练一个不错基准模型,把这个过程叫做sft
评判文本生成好坏的Reward,为了得到Reward模型我们需要用‘输入-输出list’语料做一个排序打分模型,把这个过程叫做Reward
利用Reward反馈调试Agent模型PPO调控器

fig1.sft训练过程
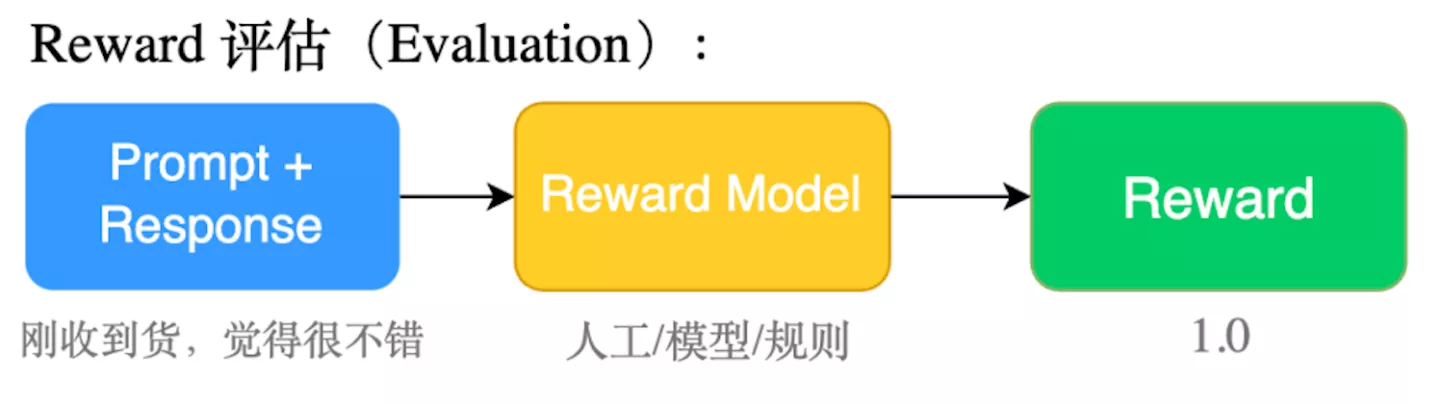
fig2.reward训练过程
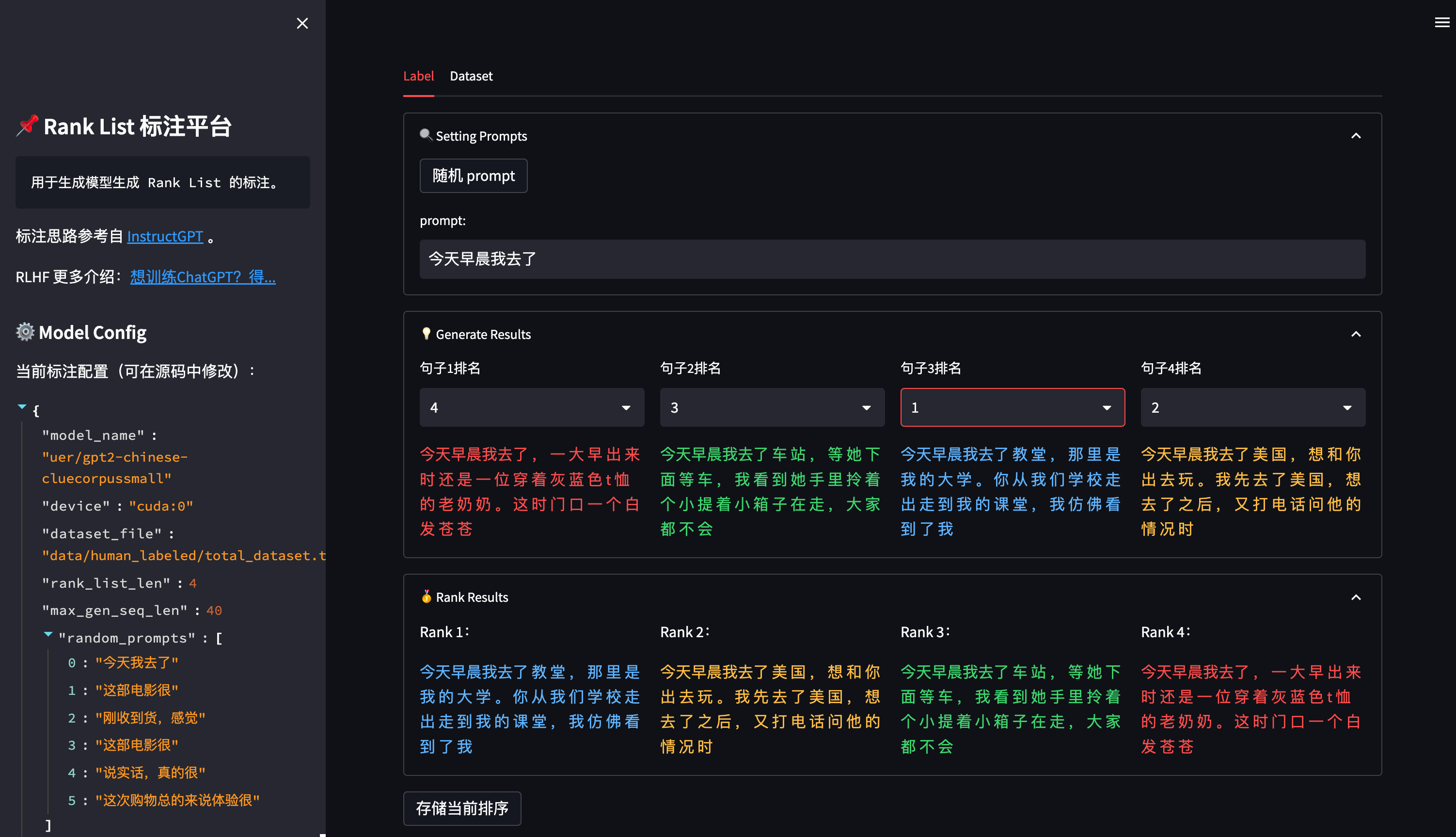
Rank数据打标
SFT实现
先训练一个基本的有文本生成能力的模型,可以选用GPT或者T5框架模型来做训练。
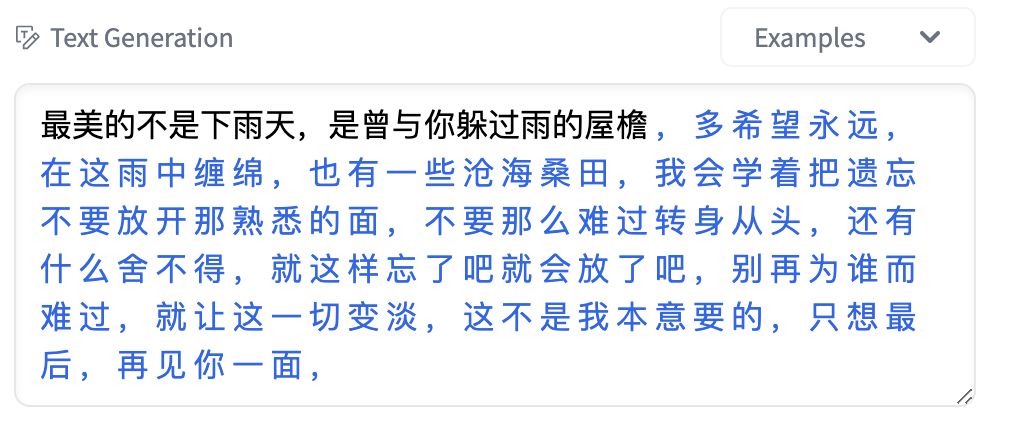
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-lyric")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-lyric")
text_generator = TextGenerationPipeline(model, tokenizer)
text_generator("最美的不是下雨天,是曾与你躲过雨的屋檐", max_length=100, do_sample=True)GPT2
数据样式:
{"id": 0, "article": [12, 43, 27912, 12, 8100, 532, 21095, 33, 12, 1377, 7214, 4621, 286, 262, 890, 5041, 351, 257, 474, 5978, 284, 534, 17627, 764, 775, 1965, 1312, 6207, 3816, 284, 2648, 5205, 286, 511, 4004, 7505, 3952, 5636, 2171, 764], "abstract": [9787, 503, 8100, 13, 785, 7183, 705, 7505, 3952, 5205, 764, 1471, 19550, 287, 319, 262, 995, 705, 82, 27627, 6386, 1660, 19392, 764]}#这部分代码拷贝命名'dataset.py'
import os
import json
import numpy as np
import torch
from torch.utils.data import Dataset
from utils import add_special_tokens
class GPT21024Dataset(Dataset):
def __init__(self, root_dir, ids_file, mode='train',length=None):
self.root_dir = root_dir
self.tokenizer = add_special_tokens()
# with open(ids_file,'r') as f:
# if mode=='train':
# self.idxs = np.array(json.load(f)['train_ids'])
# elif mode=='valid':
# self.idxs = np.array(json.load(f)['valid_ids'])
# elif mode=='test':
# self.idxs = np.array(json.load(f)['test_ids'])
# self.idxs = self.idxs -min(self.idxs)
self.idxs = os.listdir(root_dir)
self.mode = mode
if len == None:
self.len = len(self.idxs)
else:
self.len = length
def __len__(self):
return self.len
def __getitem__(self,idx):
if self.mode=='valid':
idx = self.idxs[-idx]
elif self.mode=='test':
idx = self.idxs[-idx-self.len] # assuming valid and test set of same sizes
else:
idx = self.idxs[idx]
# file_name = os.path.join(self.root_dir,str(idx)+".json")
file_name = os.path.join(self.root_dir,str(idx))
with open(file_name,'r') as f:
data = json.load(f)
text = self.tokenizer.encode(self.tokenizer.pad_token)*1024
content = data['article'] + self.tokenizer.encode(self.tokenizer.sep_token) + data['abstract']
text[:len(content)] = content
text = torch.tensor(text)
sample = {'article': text, 'sum_idx': len(data['article'])}
return sample#训练部分代码
import argparse
from datetime import datetime
import os
import time
import numpy as np
from transformers import GPT2LMHeadModel,AdamW, WarmupLinearSchedule
from torch.utils.tensorboard import SummaryWriter
import torch
from torch.nn import CrossEntropyLoss
import torch.nn.functional as F
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from tqdm import tnrange, tqdm_notebook
from dataset import GPT21024Dataset
from utils import add_special_tokens, generate_sample, set_seed
#please change default arguments if needed
parser = argparse.ArgumentParser()
parser.add_argument("--lr",default=5e-5, type=float, help="learning rate")
parser.add_argument("--seed",default=42, type=int, help="seed to replicate results")
parser.add_argument("--n_gpu",default=1, type=int, help="no of gpu available")
parser.add_argument("--gradient_accumulation_steps",default=2, type=int, help="gradient_accumulation_steps")
parser.add_argument("--batch_size",default=1, type=int, help="batch_size")
parser.add_argument("--num_workers",default=4, type=int, help="num of cpus available")
parser.add_argument("--device",default=torch.device('cpu'), help="torch.device object")
parser.add_argument("--num_train_epochs",default=1, type=int, help="no of epochs of training")
parser.add_argument("--output_dir",default='./output', type=str, help="path to save evaluation results")
parser.add_argument("--model_dir",default='./weights', type=str, help="path to save trained model")
parser.add_argument("--max_grad_norm",default=1.0, type=float, help="max gradient norm.")
parser.add_argument("--root_dir",default='./CNN/gpt2_1024_data', type=str, help="location of json dataset.")
parser.add_argument("--ids_file",default='./CNN/ids.json', type=str, help="location of train, valid and test file indexes")
args = parser.parse_args([])
print(args)
def train(args, model, tokenizer, train_dataset, valid_dataset, ignore_index):
""" Trains GPT2 model and logs necessary details.
Args:
args: dict that contains all the necessary information passed by user while training
model: finetuned gpt/gpt2 model
tokenizer: GPT/GPT2 tokenizer
train_dataset: GPT21024Dataset object for training data
ignore_index: token not considered in loss calculation
"""
writer = SummaryWriter('./output/logs')
train_sampler = RandomSampler(train_dataset)
train_dl = DataLoader(train_dataset,sampler=train_sampler,batch_size=args.batch_size,num_workers=args.num_workers)
loss_fct = CrossEntropyLoss(ignore_index=ignore_index) #ignores padding token for loss calculation
optimizer = AdamW(model.parameters(),lr=args.lr)
scheduler = WarmupLinearSchedule(optimizer,100,80000)
global_step = 0
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = tnrange(int(args.num_train_epochs), desc="Epoch")
set_seed(args)
for _ in train_iterator:
epoch_iterator = tqdm_notebook(train_dl, desc="Training")
for step, batch in enumerate(epoch_iterator):
inputs, labels = batch['article'].to(args.device), batch['article'].to(args.device)
model.train()
logits = model(inputs)[0]
# only consider loss on reference summary just like seq2seq models
shift_logits = logits[..., batch['sum_idx']:-1, :].contiguous()
shift_labels = labels[..., batch['sum_idx']+1:].contiguous()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss = loss/args.gradient_accumulation_steps
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
writer.add_scalar('lr', scheduler.get_lr()[0], global_step)
writer.add_scalar('loss', (tr_loss - logging_loss)/args.gradient_accumulation_steps, global_step)
logging_loss = tr_loss
print("loss:", loss.item(), end='\n\n')
if (step + 1)/args.gradient_accumulation_steps == 1.0:
print('After 1st update: ', end='\n\n')
generate_sample(valid_dataset, tokenizer, model, num=2, eval_step=False,device=args.device)
if (step + 1) % (10*args.gradient_accumulation_steps) == 0:
results = evaluate(args, model, valid_dataset, ignore_index, global_step)
for key, value in results.items():
writer.add_scalar('eval_{}'.format(key), value, global_step)
print('After', global_step+1,'updates: ', end='\n\n')
generate_sample(valid_dataset, tokenizer, num=2, eval_step=True,device=args.device)
# creating training and validation dataset object
train_data = GPT21024Dataset(args.root_dir,args.ids_file,mode='train',length=3000) #training on only 3000 datasets
valid_data = GPT21024Dataset(args.root_dir,args.ids_file,mode='valid',length=500) #validation on only 500 datasets
# load pretrained GPT2
tokenizer = add_special_tokens()
ignore_idx = tokenizer.pad_token_id
model = GPT2LMHeadModel.from_pretrained('gpt2')
model.resize_token_embeddings(len(tokenizer))
model.to(args.device)
#training the model
start = time.time()
train(args, model, tokenizer, train_data, valid_data, ignore_idx)
print('total time: ', (time.time()-start)/60, " minutes", end='\n\n')
print('Saving trained model...')
model_file = os.path.join(args.model_dir, 'model_data{}_trained_after_{}_epochs_only_sum_loss_ignr_pad.bin'.format(len(train_data),args.num_train_epochs))
config_file = os.path.join(args.model_dir, 'config_data{}_trained_after_{}_epochs_only_sum_loss_ignr_pad.json'.format(len(train_data),args.num_train_epochs))
torch.save(model.state_dict(), model_file)
model.config.to_json_file(config_file)这部分代码,我同步会整理到我的github整理完会把链接发上来。
T5
下次迭代更新



![[测开篇]设计测试用例的方法如何正确描述Bug](https://img-blog.csdnimg.cn/dbffcb7fef8d4aad9df362500724103d.png#pic_center)