系列文章目录
Kafka第一章:环境搭建
Kafka第二章:生产者案例
文章目录
- 系列文章目录
- 前言
- 一、创建项目
- 1.创建包
- 2.添加依赖
- 二、编写代码
- 1.普通异步发送
- 2.同步发送
- 三.生产者发送消息的分区策略
- 1.指定分区
- 2.自定义分区
- 总结
前言
上次完成了Kafka的环境搭建,这次来完成一些有关生产者的项目。
一、创建项目
1.创建包
com.atguigu.kafka.producer
2.添加依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.4.0</version>
</dependency>
</dependencies>
二、编写代码
1.普通异步发送
需求:创建 Kafka 生产者,采用异步的方式发送到 Kafka Broker
注:不带回调
CustomProducer.java
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducer {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2.发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first","atguigu"+i));
}
// 3.关闭资源
kafkaProducer.close();
}
}
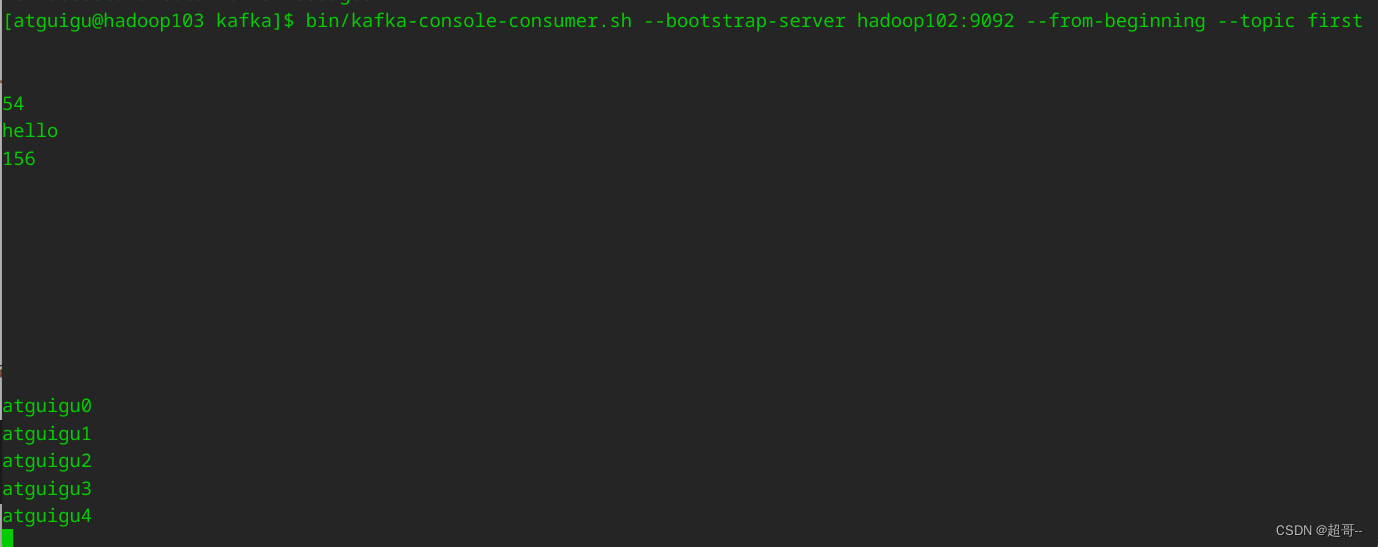
建议先用命令行启动环境,然后发送几条数据,确认集群可以正常使用。

运行文件
加回调函数
CustomProducerCallback.java
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducerCallback {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2.发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "atguigu" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
System.out.println("主题: "+recordMetadata.topic()+"分区: "+recordMetadata.partition());
}
}
});
}
// 3.关闭资源
kafkaProducer.close();
}
}
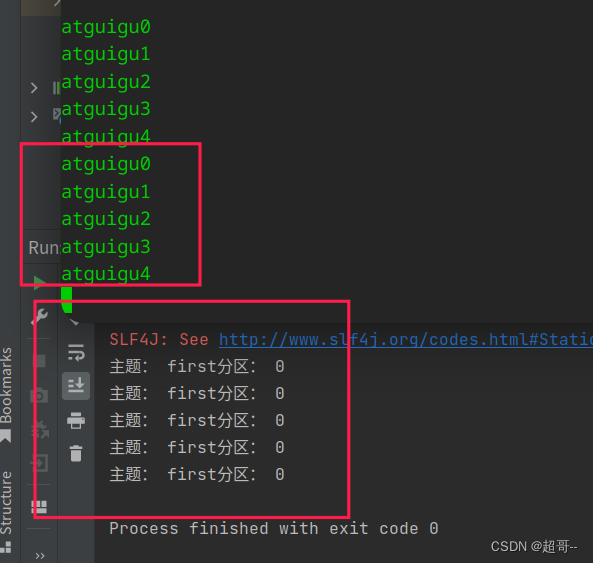
2.同步发送
只需在异步发送的基础上,再调用一下 get()方法即可。
CustomProducerSync.java
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducerSync {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 0 配置
Properties properties = new Properties();
// 连接集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2.发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first","atguigu"+i)).get();
}
// 3.关闭资源
kafkaProducer.close();
}
}
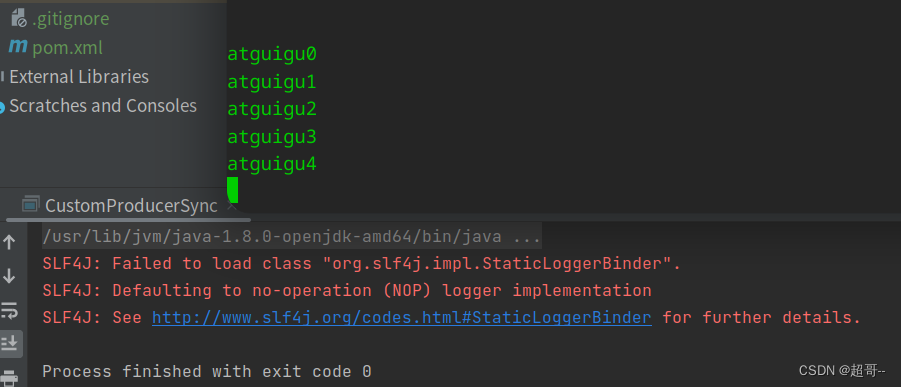
由于数据量小,结果和异步发送没区别
三.生产者发送消息的分区策略
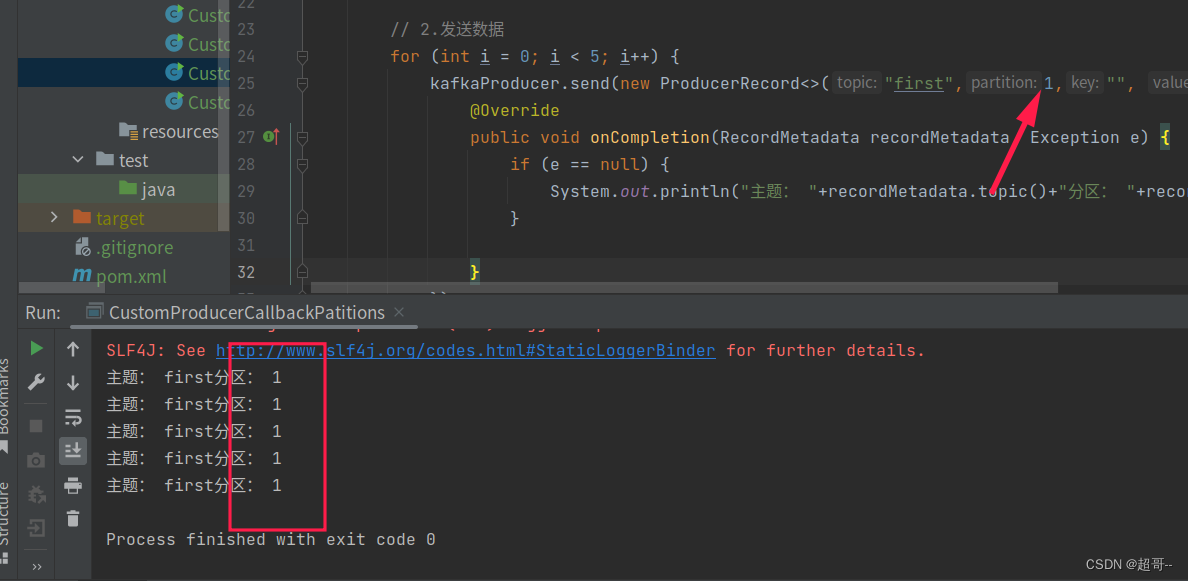
1.指定分区
CustomProducerCallbackPatitions.java
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducerCallbackPatitions {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// 1.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2.发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first",1,"", "atguigu" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
System.out.println("主题: "+recordMetadata.topic()+"分区: "+recordMetadata.partition());
}
}
});
}
// 3.关闭资源
kafkaProducer.close();
}
}
2.自定义分区
例如我们实现一个分区器实现,发送过来的数据中如果包含 atguigu,就发往 0 号分区,不包含 atguigu,就发往 1 号分区。
MyPartitioner.java
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class MyPartitioner implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
//获取数据 atguigu hello
String msgValues = o1.toString();
int partition;
if (msgValues.contains("atguigu")) {
partition=0;
}else {
partition=1;
}
return partition;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
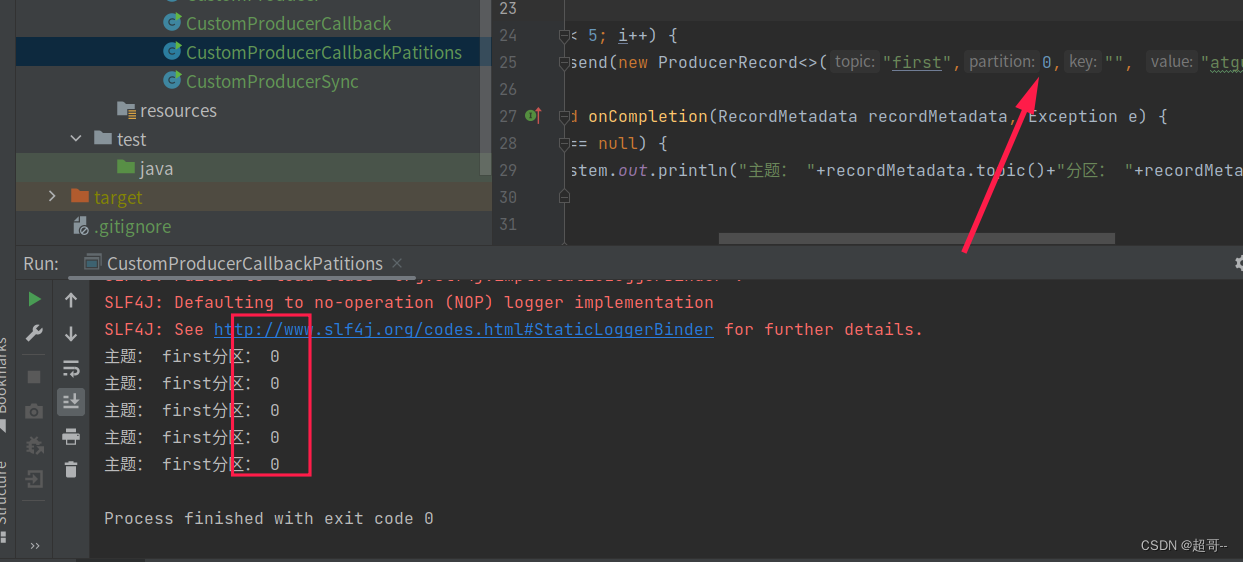
将自定义分区代码,与之前的代码相关联
在CustomProducerCallbackPatitions.java中简单修改
新添加一行代码
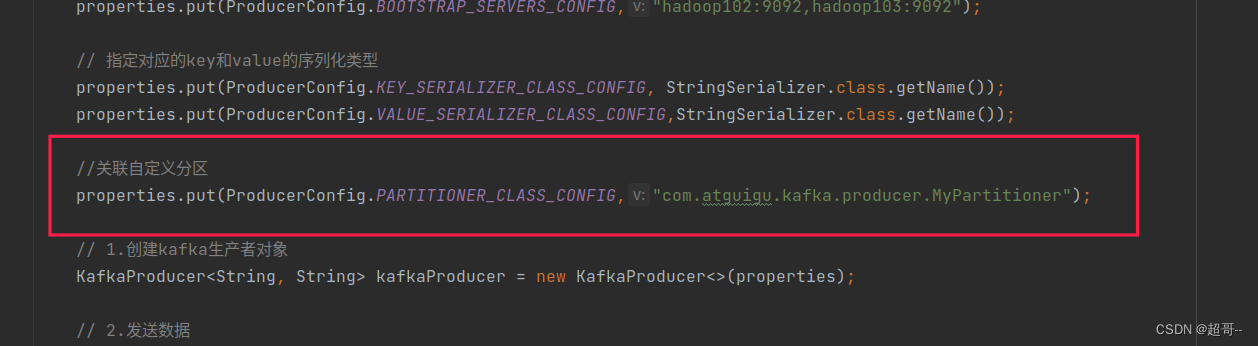
然后将指定分区的数字和key都取消
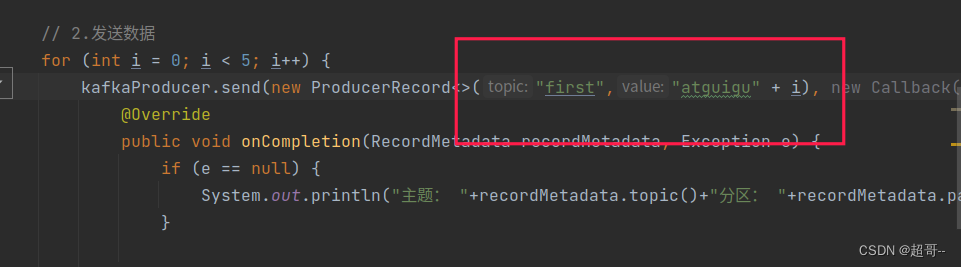
修改后的代码
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducerCallbackPatitions {
public static void main(String[] args) {
// 0 配置
Properties properties = new Properties();
// 连接集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// 指定对应的key和value的序列化类型
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//关联自定义分区
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atguigu.kafka.producer.MyPartitioner");
// 1.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 2.发送数据
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first","atguigu" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
System.out.println("主题: "+recordMetadata.topic()+"分区: "+recordMetadata.partition());
}
}
});
}
// 3.关闭资源
kafkaProducer.close();
}
}
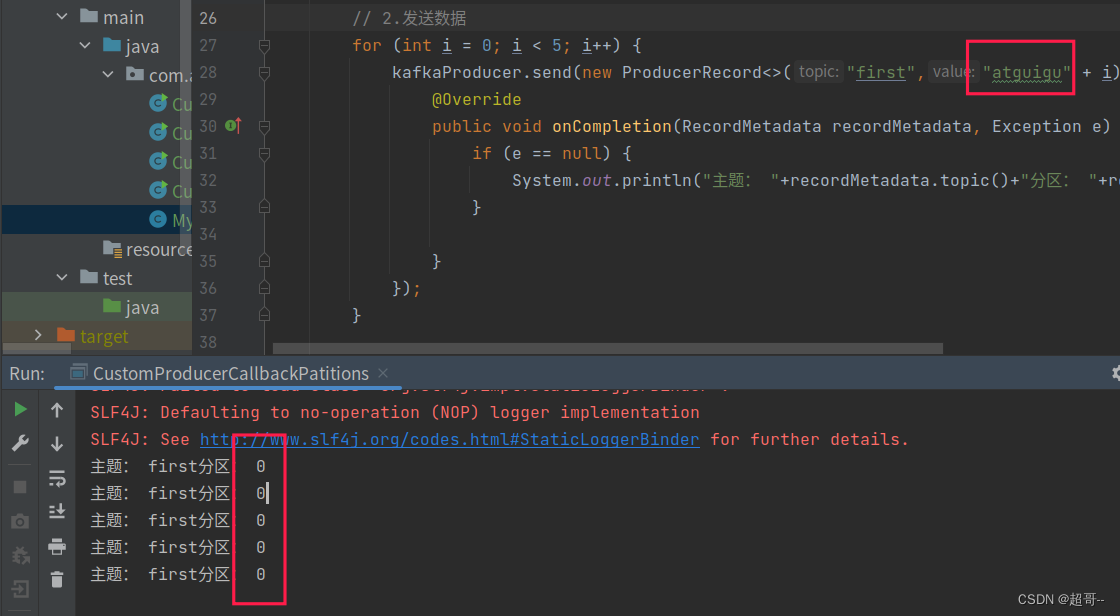
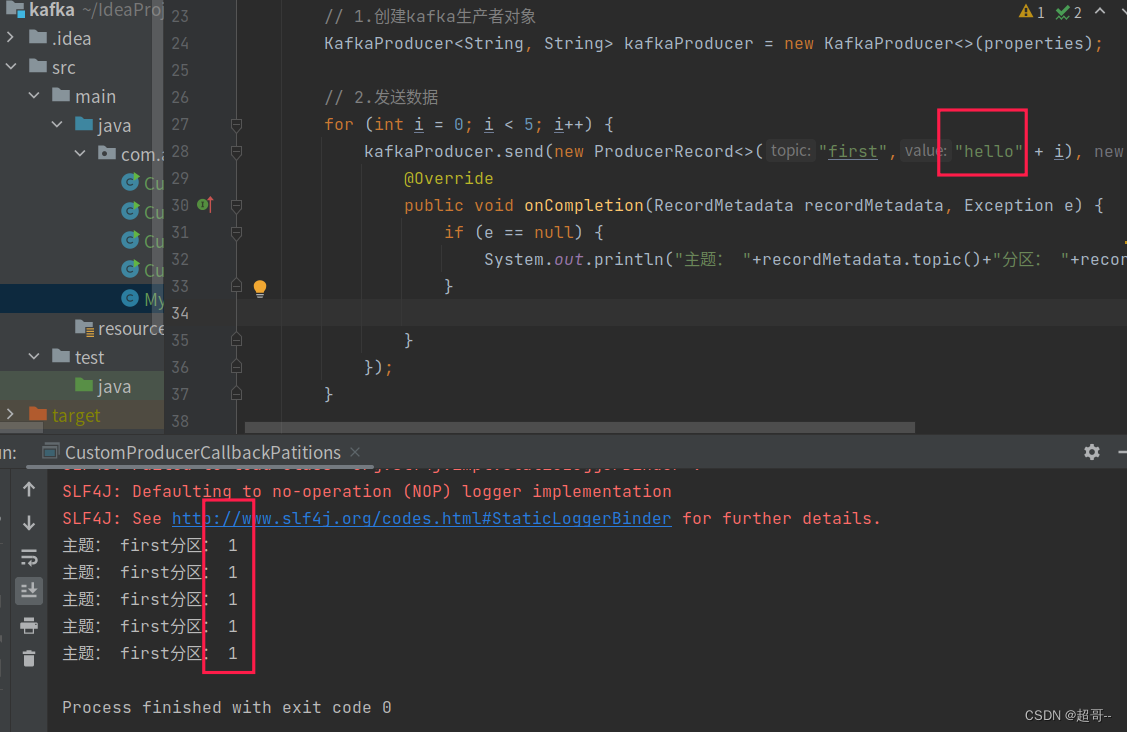
总结
Kafka第二次博客就暂时到这里,后边其实还有一些内容,但我觉得,那些对于新手来说,有些深入了,以后在写吧。