8.1、resultMap处理字段和属性的映射关系
若字段名和实体类中的属性名不一致,则可以通过resultMap设置自定义映射
<!--
resultMap:设置自定义映射
属性:
id:表示自定义映射的唯一标识
type:查询的数据要映射的实体类的类型
子标签:
id:设置主键的映射关系
result:设置普通字段的映射关系
association:设置多对一的映射关系
collection:设置一对多的映射关系
属性:
property:设置映射关系中实体类中的属性名
column:设置映射关系中表中的字段名
-->
<resultMap id="userMap" type="User">
<id property="id" column="id"></id>
<result property="userName" column="user_name"></result>
<result property="password" column="password"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
</resultMap>
<!--List<User> testMohu(@Param("mohu") String mohu);-->
<select id="testMohu" resultMap="userMap">
<!--select * from t_user where username like '%${mohu}%'-->
select id,user_name,password,age,sex from t_user where user_name like concat('%',#{mohu},'%')
</select>
若字段名和实体类中的属性名不一致,但是字段名符合数据库的规则(使用_),实体类中的属性名符合Java的规则(使用驼峰)
此时也可通过以下两种方式处理字段名和实体类中的属性的映射关系
- 可以通过为字段起别名的方式,保证和实体类中的属性名保持一致
- 可以在MyBatis的核心配置文件中设置一个全局配置信息mapUnderscoreToCamelCase,可以在查询表中数据时,自动将_类型的字段名转换为驼峰
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
例如:字段名user_name,设置了mapUnderscoreToCamelCase,此时字段名就会转换为userName
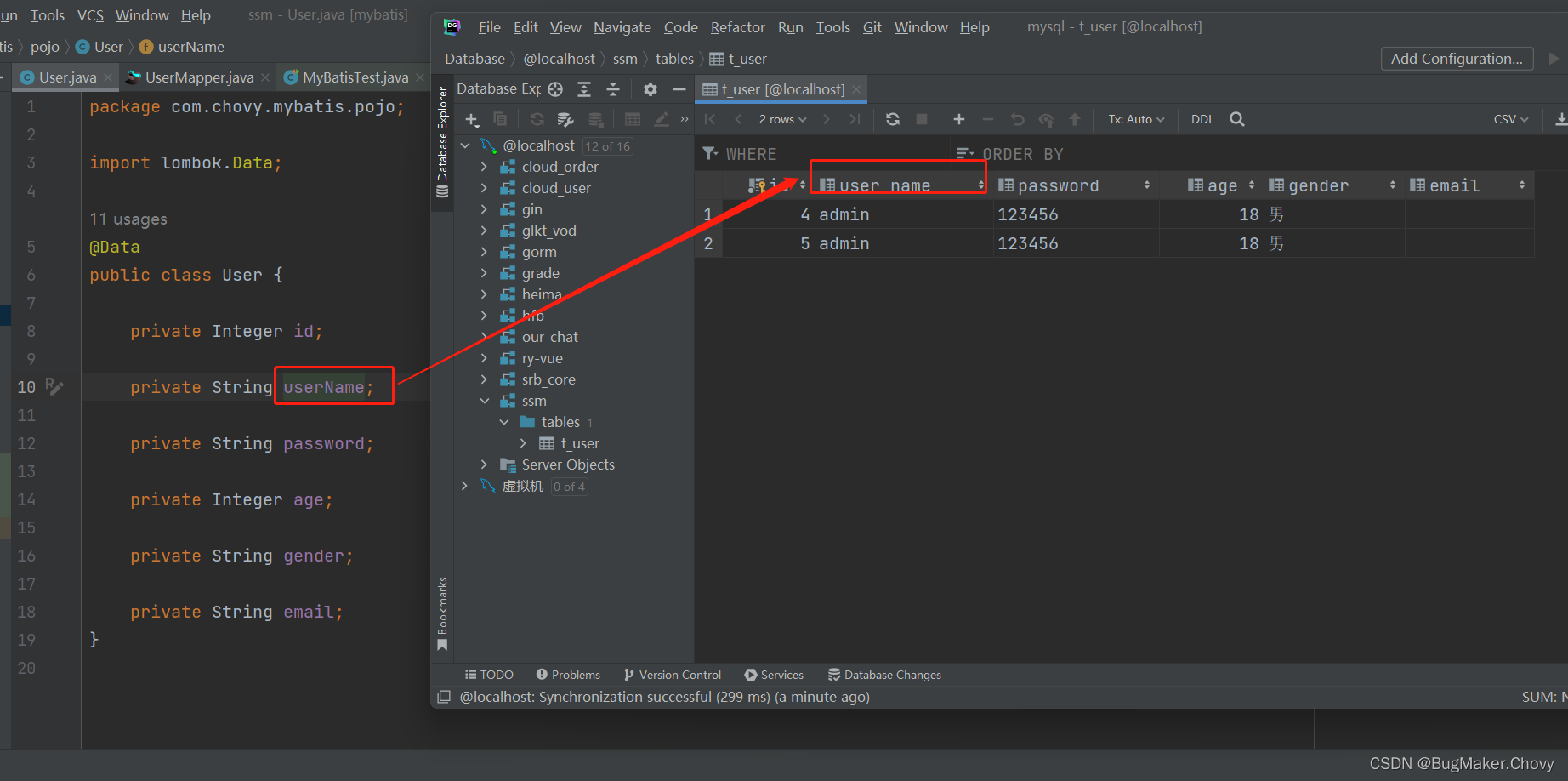
List<User> getAllUser();
<select id="getAllUser" resultType="User">
select * from t_user
</select>
查询结果:
[User(id=4, userName=admin, password=123456, age=18, gender=男, email=), User(id=5, userName=admin, password=123456, age=18, gender=男, email=)]
8.2、多对一映射处理
场景模拟:
查询员工信息以及员工所对应的部门信息
8.2.1、级联方式处理映射关系
<resultMap id="empDeptMap" type="Emp">
<id column="eid" property="eid"></id>
<result column="ename" property="ename"></result>
<result column="age" property="age"></result>
<result column="sex" property="sex"></result>
<result column="did" property="dept.did"></result>
<result column="dname" property="dept.dname"></result>
</resultMap>
<!--Emp getEmpAndDeptByEid(@Param("eid") int eid);-->
<select id="getEmpAndDeptByEid" resultMap="empDeptMap">
select emp.*,dept.* from t_emp emp left join t_dept dept on emp.did = dept.did where emp.eid = #{eid}
</select>
8.2.2、使用association处理映射关系
<resultMap id="empDeptMap" type="Emp">
<id column="eid" property="eid"></id>
<result column="ename" property="ename"></result>
<result column="age" property="age"></result>
<result column="sex" property="sex"></result>
<association property="dept" javaType="Dept">
<id column="did" property="did"></id>
<result column="dname" property="dname"></result>
</association>
</resultMap>
<!--Emp getEmpAndDeptByEid(@Param("eid") int eid);-->
<select id="getEmpAndDeptByEid" resultMap="empDeptMap">
select emp.*,dept.* from t_emp emp left join t_dept dept on emp.did = dept.did where emp.eid = #{eid}
</select>
8.2.3、分步查询
1、查询员工信息
/**
* 通过分步查询查询员工信息
* @param eid
* @return
*/
Emp getEmpByStep(@Param("eid") int eid);
<resultMap id="empDeptStepMap" type="Emp">
<id column="eid" property="eid"></id>
<result column="ename" property="ename"></result>
<result column="age" property="age"></result>
<result column="sex" property="sex"></result>
<!--
select:设置分步查询,查询某个属性的值的sql的标识(namespace.sqlId)
column:将sql以及查询结果中的某个字段设置为分步查询的条件
-->
<association property="dept" select="com.atguigu.MyBatis.mapper.DeptMapper.getEmpDeptByStep" column="did">
</association>
</resultMap>
<!--Emp getEmpByStep(@Param("eid") int eid);-->
<select id="getEmpByStep" resultMap="empDeptStepMap">
select * from t_emp where eid = #{eid}
</select>
2、根据员工所对应的部门id查询部门信息
/**
* 分步查询的第二步: 根据员工所对应的did查询部门信息
* @param did
* @return
*/
Dept getEmpDeptByStep(@Param("did") int did);
<!--Dept getEmpDeptByStep(@Param("did") int did);-->
<select id="getEmpDeptByStep" resultType="Dept">
select * from t_dept where did = #{did}
</select>
8.3、一对多映射处理
8.3.1、collection
/**
* 根据部门id查新部门以及部门中的员工信息
* @param did
* @return
*/
Dept getDeptEmpByDid(@Param("did") int did);
<resultMap id="deptEmpMap" type="Dept">
<id property="did" column="did"></id>
<result property="dname" column="dname"></result>
<!--
ofType:设置collection标签所处理的集合属性中存储数据的类型
-->
<collection property="emps" ofType="Emp">
<id property="eid" column="eid"></id>
<result property="ename" column="ename"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
</collection>
</resultMap>
<!--Dept getDeptEmpByDid(@Param("did") int did);-->
<select id="getDeptEmpByDid" resultMap="deptEmpMap">
select dept.*,emp.* from t_dept dept left join t_emp emp on dept.did = emp.did where dept.did = #{did}
</select>
8.3.2、分步查询
1、查询部门信息
/**
* 分步查询部门和部门中的员工
* @param did
* @return
*/
Dept getDeptByStep(@Param("did") int did);
<resultMap id="deptEmpStep" type="Dept">
<id property="did" column="did"></id>
<result property="dname" column="dname"></result>
<collection property="emps" fetchType="eager" select="com.atguigu.MyBatis.mapper.EmpMapper.getEmpListByDid" column="did">
</collection>
</resultMap>
<!--Dept getDeptByStep(@Param("did") int did);-->
<select id="getDeptByStep" resultMap="deptEmpStep">
select * from t_dept where did = #{did}
</select>
备注:javaType和ofType都是用来指定对象类型的,但是javaType是用来指定pojo中属性的类型,而ofType指定的是映射到list集合属性中pojo的类型。
2、根据部门id查询部门中的所有员工
/**
* 根据部门id查询员工信息
* @param did
* @return
*/
List<Emp> getEmpListByDid(@Param("did") int did);
<!--List<Emp> getEmpListByDid(@Param("did") int did);-->
<select id="getEmpListByDid" resultType="Emp">
select * from t_emp where did = #{did}
</select>
分步查询的优点:可以实现延迟加载
但是必须在核心配置文件中设置全局配置信息:
lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载
aggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载
也可以通过association和collection中的fetchType属性设置当前的分步查询是否使用延迟加载, fetchType=“lazy(延迟加载)|eager(立即加载)”
更多关于延迟加载的资料可以参考:https://www.cnblogs.com/zbh355376/p/14986307.html
本文章参考B站 【尚硅谷】SSM框架全套教程,MyBatis+Spring+SpringMVC+SSM整合一套通关,仅供个人学习使用,部分内容为本人自己见解,与尚硅谷无关。