来源:投稿 作者:橡皮
编辑:学姐
带你学习跨域小样本系列1-简介篇
跨域小样本系列2-常用数据集与任务设定详解
跨域小样本系列3:元学习方法解决CDFSL以及两篇SOTA论文讲解(本篇)
跨域小样本系列4:finetune方法解决CDFSL以及两篇SOTA论文讲解
跨域小样本系列5:除此之外一些奇门异路的论文讲解
CDFSL设置的SOTA论文选讲

主要贡献: 提出了一种带有批量谱正则化(BSR)的特征变换集成模型。提出了在特征提取网络之后,通过不同的特征变换来构建一个集成预测模型。
然后,提出的模型在目标领域进行微调,以解决小样本分类问题。
进一步添加标签传播、熵最小化和数据增强模块来缓解目标域标记数据的不足。
1.1整体框架:Feature Transformation Ensemble Model
作者通过增加特征表示空间的多样性来构建集成模型,同时保持每个预测分支网络对整个训练数据的使用。

1.2创新1:Batch Spectral Regularization(BSR)
受到先前研究启发:惩罚特征矩阵的较小奇异值可以帮助缓解微调中的负迁移。
作者将该惩罚器扩展到全谱,并提出了一种批处理谱正则化(BSR)机制来抑制批处理特征矩阵在训练前的所有奇异值,旨在避免对源域的过拟合,提高对目标域的泛化能力。
该正则化方法同样适用于集成模型的每个分支网络。
对于一种基于SGD的训练算法,我们使用批量训练。给定一批训练实例其特征矩阵为
,其中b为batch size
为每个batch中第i个实例的特征向量。
BSR:
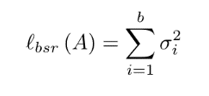
其中 σ1,σ2,…,σb 为每个batch的特征矩阵A的奇异值,每个batch的谱正则化训练损失为:
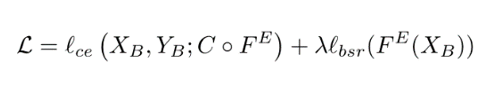
1.3创新2:Label Propagation(LP)
由于目标域中缺乏标记数据,使用支持集进行微调的模型很容易对查询实例做出错误的预测。提出了一种标签传播(LP)方法,利用提取的特征空间中未标记的测试数据的语义信息,对原始分类结果进行细化。在使用微调分类器Ct的查询实例上,给定一个预测分数矩阵 ,保持每个类别中预测分数最高的列,并将其他值设置为0,只传播最可信的预测。然后,我们基于提取的特征查询实例上构建k-NN图。
使用每一对图像之间的平方欧氏距离
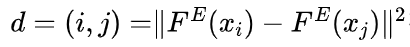
:确定k-NN图。基于RBF核的亲和力矩阵W的计算方法如下:
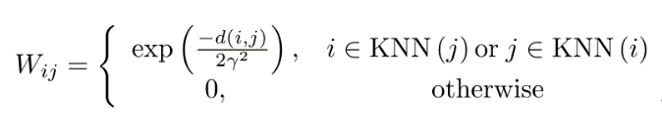
然后进行标签传播,提供以下精细化的预测分数矩阵:
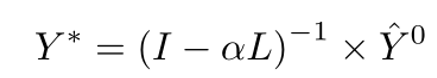
其中I为单位矩阵, 为权衡参数。在LP之后,
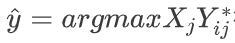
被用作第i个图像的预测类。
1.4创新3:Entropy Minimization(EM)
通过最小化无标签查询集上的预测熵,将半监督学习机制扩展到目标域的fine-tuning阶段:

将这一项加入到支持集的每批(XsB, Y sB)上原有的交叉熵损失中,形成一个转导性的微调损失函数:
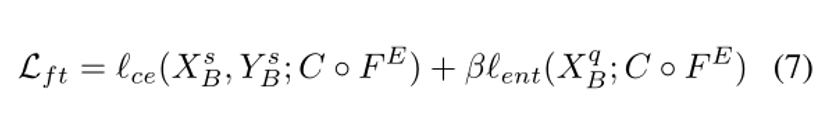
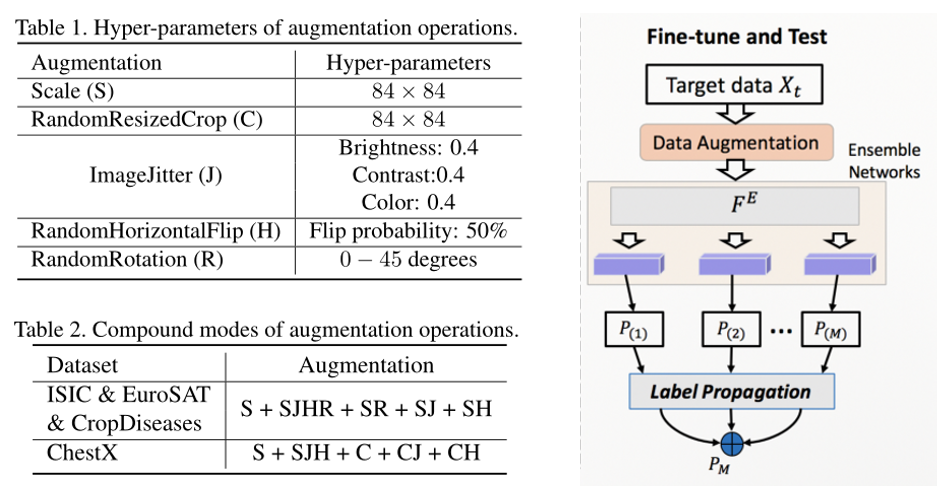
1.5数据增强Data Augmentation(DA)
利用数据增强(DA)策略,补充支持集,使模型在更多的变化中学习。特别地,作者使用一些操作的组合,如图像缩放,随机裁剪,随机翻转,随机旋转和颜色抖动为每个图像生成一些变体。可以对增强支持集进行微调。同样的增强也可以用于查询集,其中可以生成每个图像的多个变体,以共享相同的标签。因此,对每幅图像的预测结果可以通过平均同一幅图像的所有增强变量的预测结果来确定。
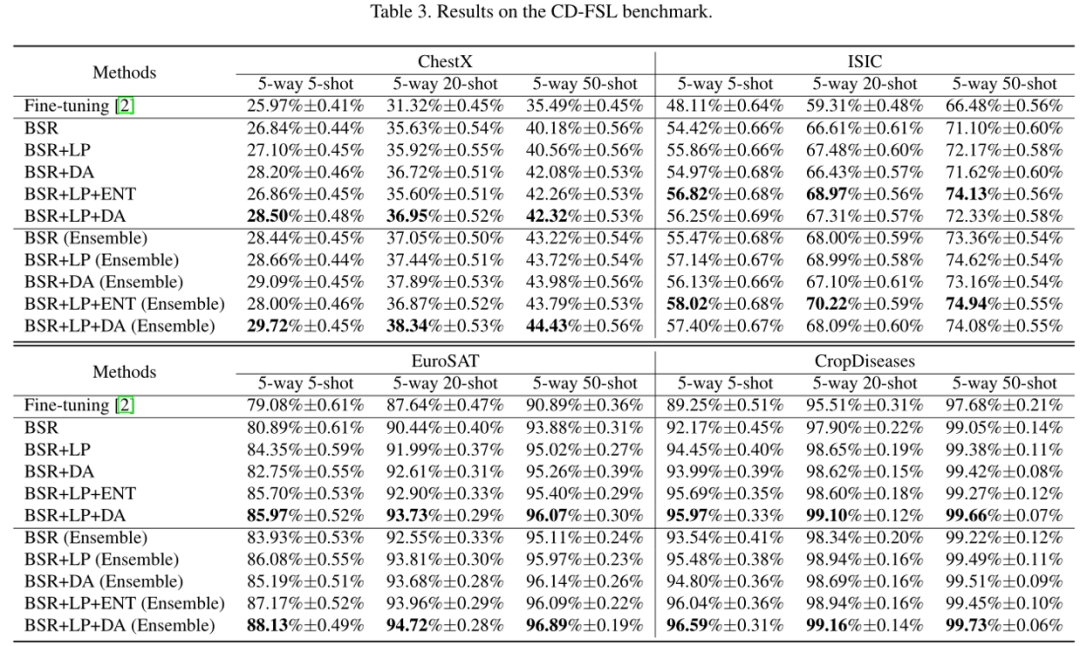
2.实验结果

ACM Multimedia 2021
主要贡献: 为了解决域跨度较大的FSL问题,重新研究了中层特征,以探索其可转移性和可鉴别性,这在主流FSL工作中很少研究。
为了增强中层特征的可分辨性,提出了一个残差预测任务来探索每类特征的独特性。
提出的方法不仅适用于域跨度较大的FSL问题,而且适用于域内FSL和域跨度较小的CDFSL问题。以上两种设定下,在六个公开数据集上进行实验实现SOTA。
1.先验事实
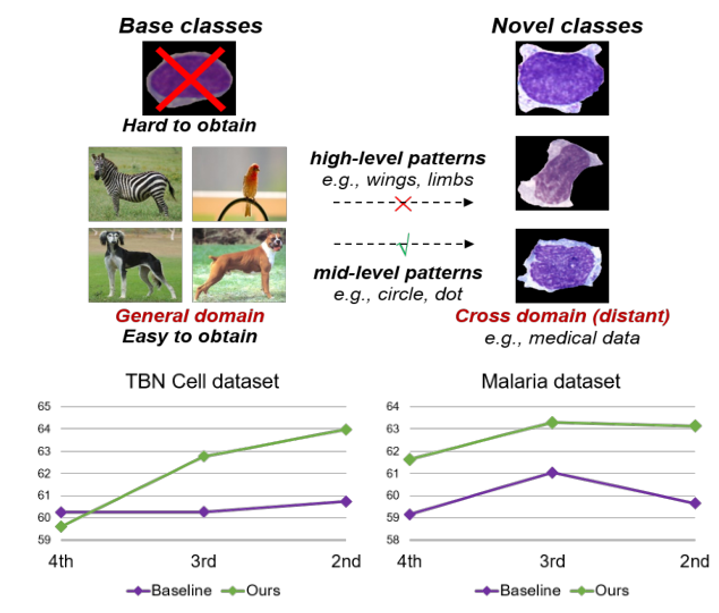
作者首先给出了一些先验事实:
上图:一般域中的样本很容易获得,而在可能远离一般域的特殊域(例如医疗数据)中可能很难获得。为了将知识从一般域中易于获得的基类转移到遥远领域中的新类(跨领域小样本识别的一个具有挑战性的子集),我们重新研究了比高级模式(eg.翅膀、四肢)更具可转移性的中级模式(eg.圆圈、点)。
下图:在将基类的训练模型转移到较远跨域数据集时,对ResNet不同块提取的特征进行定量评估,其中中级特征(第3和第2块)与高级特征(第4块,即最后一层)相比,性能更好。
2.作者的insight:
来自较浅(中层)层的特征比来自较深层层的特征更容易转移。
假设每个类都有其独特的特性,这不能被其他类的高级模式很容易地描述,而中级模式可以更有效地描述它。
直观地说,用狗的知识来描述斑马,很容易把脚、尾巴等高级模式转移到斑马身上。但对于斑马独特的特征,即斑马条纹来说,很难将高级模式特征进行转移,这时候就需要使用中间特征。
为了提高中级特征的可识别性,作者提出了一个使用已知类进行训练的残差预测任务,该任务鼓励中级特征学习每个样本中的判别信息。
3.解决方案:
3.1总体框架:
上图:首先提取每个基类样本(例如,斑马)的特征,骨干网络通过分类损失进行训练。然后,对于每个样本,作者设计使用其他类别(例如狗、鸟、人)的高级模式来重建提取的特征(高级重建),并从提取的特征中删除重建的特征(例如,没有条纹的斑马,可能是白马),输出判别残差特征(例如条纹),包含适用于中级特征学习的该样本的判别信息。最后,作者约束中间层特征来预测这种判别残差特征,从而推动中级层的特征具有判别性。
下图:在测试新类时,分别为遥远域和域内/近邻域的新类提供了两种类型的特征。
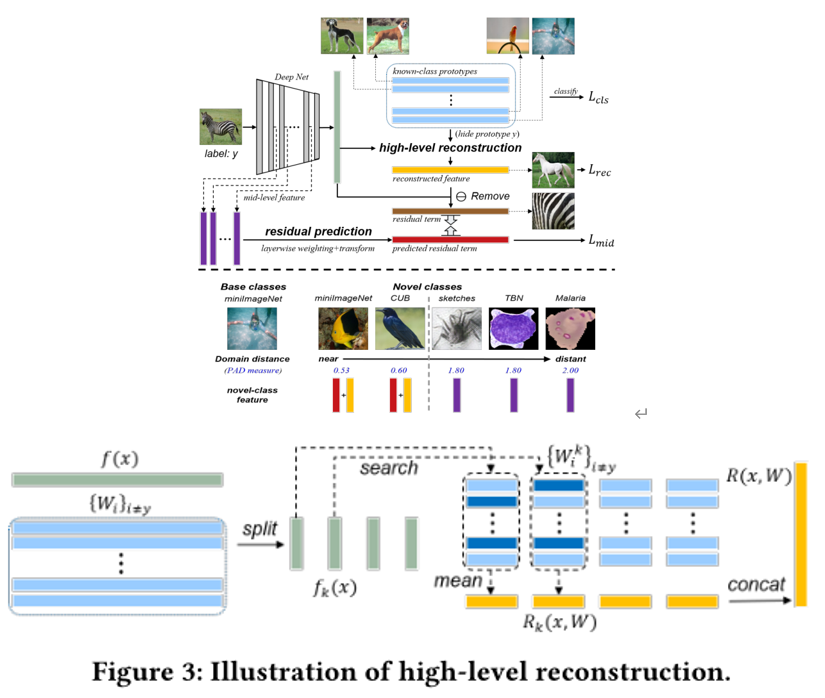
3.2 高层特征重建
其中:
X:样本;y:X的标签;F(x):使用其他基类的高级模式来表示(重建)提取的特征。
W:基类FC参数(视作基类原型),每一行W(蓝),包含相应类的总体信息,它指的是高级模式,因为它与主干的最后一层存在于相同的特征空间中。
因此,原型被用来重建f(x),其他N-1种基类的原型对于x表示为原型集。具体地说,使用提取的特征f(x)来应用最近邻搜索,并查询最高余弦相似的原型形成邻近的原型集,然后,重建特征计算为所有查询原型的平均值。
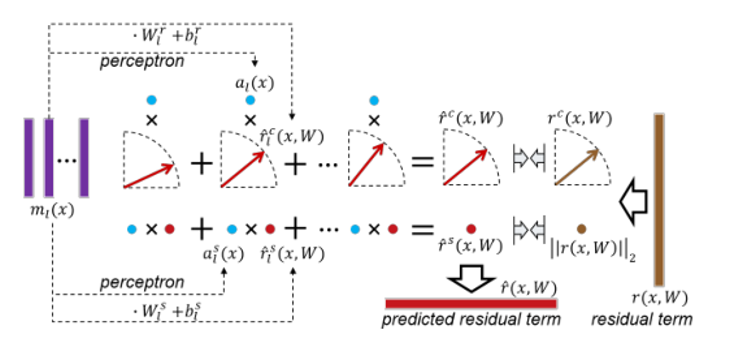
3.3正交剩余项设置
直观上说,剩余项和高级重构项不应该相互代表,这意味着它们应该是正交的。
残余特征为提取特征与重建特征之差进行计算。来自多个中层的终极特征将被动态加权,以线性预测残差项。
每个圆代表一个标量,扇形区域中的每个箭头表示一个L2归一化向量,蓝色圆圈表示层权重。由于向量可以分解为两个方向(L2归一化向量)和长度(L2范数),我们分别预测残差项的方向rc(x,W),即棕色箭头和长度,即棕色圆圈。
最终预测向量的方向rchat和长度rshat是每个方向的加权组合rl,其中rslhat是从中间层转换而来的,并通过层特定权重和als加权(蓝圆圈)而来。
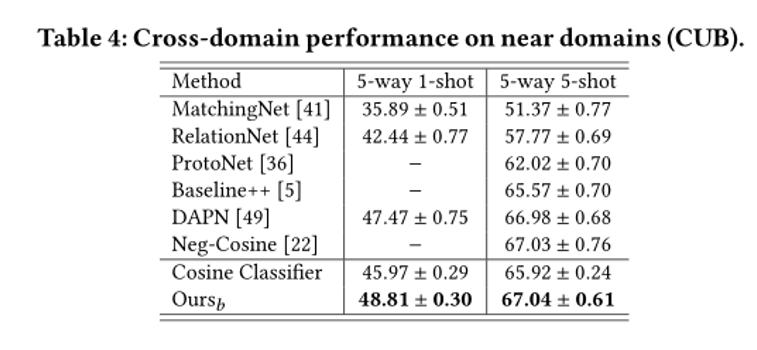
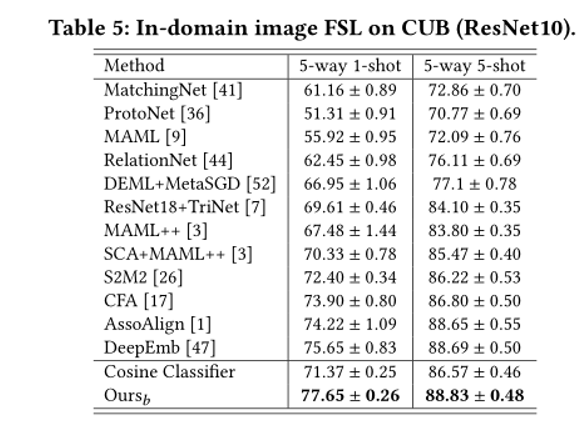
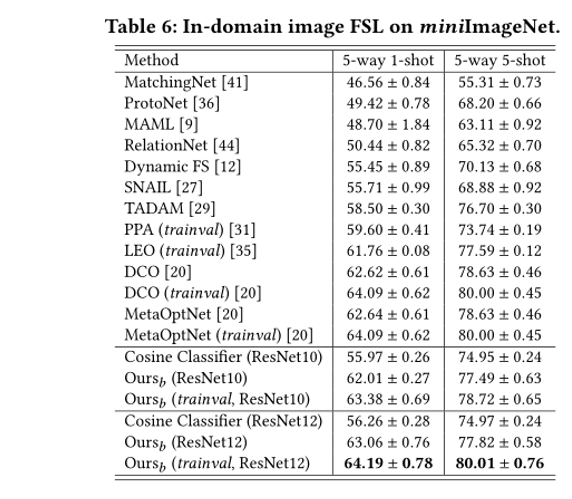
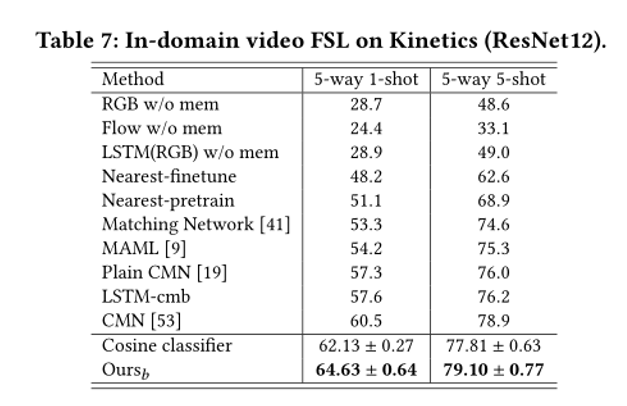
4.实验结果:

点击下方卡片关注《学姐带你玩AI》🚀🚀🚀
持续更新跨域小样本系列
220+篇人工智能必读论文PDF免费领
码字不易,欢迎大家点赞评论收藏!











![[SSD固态硬盘技术 9] FTL详解](https://img-blog.csdnimg.cn/img_convert/9216fea96be3478986df13d923878edd.png)