Abstract
本研究的目的是使用 LiDAR 点云数据开发单棵树级别的自动化城市森林清单的新算法。激光雷达数据包含三维结构信息,可用于估算树高、基高、树冠深度和树冠直径。这使得精确的城市森林库存可以细化到单棵树。与大多数已发布的从 LiDAR 派生的栅格表面检测单个树木的算法不同,我们直接使用 LiDAR 点云数据来分离单个树木并估计树木指标。在典型城市森林中的测试结果令人鼓舞。未来的工作将致力于通过数据融合技术协同 LiDAR 数据和光学图像来表征城市树木。
Keywords: LiDAR; individual tree extraction; tree metrics estimation
1. Introduction
城市森林被定义为生长在城市、城镇或郊区的森林或树木的集合。城市森林提供了许多好处,例如节约能源和减少空气污染。为了最大限度地发挥这些效益,出于规划和管理目的,通常需要一份城市森林清单。然而,城市林业数据库很少见、不完整且不经常更新,因为传统的地面调查耗时、昂贵且劳动密集。因此,人们对城市森林资源知之甚少。随着光探测和测距 (LiDAR) 技术的出现,预计城市森林清查可以实现自动化。
LiDAR 能够通过树冠的开口“看到”地面并检测树木的 3-D 结构。 LiDAR 在森林中的应用研究始于 80 年代。早期的工作主要集中在林分水平上使用分析 LiDAR 系统对森林进行量化 [1,2]。对于天然林管理而言,林分水平测量比个体树木水平更重要。然而,城市森林是许多不同物种和年龄的马赛克,通常具有较高程度的空间异质性。因此,社区管理者通常需要更详细的信息。
由于采样率的大幅提高,现代扫描 LiDAR 技术允许在单个树级别估计库存元素。已经探索了一系列方法来检测单棵树,其中许多方法基于 LiDAR 衍生的树冠高度模型 (CHM),这是一个从 LiDAR 点插值到树冠表面的栅格表面(例如,[3–17] ).这些算法在许多商业和业务环境中受到青睐,主要是因为处理速度快,并且通常使用规则间隔数据(即栅格)的软件易于访问。使用这些方法存在几个问题。首先,由于所选择的插值方法和网格间距,CHM 的推导引入了误差和不确定性 [18]。这最终会影响后续树度量的估计[19]。其次,用于减轻冠层粗糙表面的高斯平滑步骤可能导致低估或高估树高 [20]。
如图 1 所示,实际上可以从 LiDAR 点云中估算树高、基高、树冠深度和树冠直径等几个基本树参数。树高是沿主轴从树梢到树根的长度树。树冠深度是沿主轴线从树梢到树冠底部的长度。基高是从树冠基部到树基部的长度。树冠直径,也称为树冠宽度,是树冠的跨度。一些研究人员开发了从 LiDAR 点云中提取单棵树的自动化方法,取得了不同程度的成功。 Mosdorf 等人 (2004) [21] 应用 k-means 聚类算法来检测个体树。他们的聚类方法依赖于从 LiDAR 衍生的 CHM 中提取的种子点,因此该方法不是仅依赖点云的方法。Reiberger 等人 (2009) [22] 使用归一化切割分割方法将树木区域细分为一个体素空间,然后从已识别的图中提取单棵树。 Lee 等人 (2010) [23] 开发了一种自适应聚类方法来分割单个树冠。 Tittmann 等人 (2011) [24] 开发了一种基于随机样本共识 (RANSAC) 的方法,使用几何模型拟合策略来识别单个树冠。 Li et al (2012) [25] 提出了一种基于间距的混合针叶林树木分割算法。 Sima 和 Nüchter (2012) [26] 对 LiDAR 点云使用了基于图形的分割方法。这些方法已经在以针叶树为主的天然林中进行了测试。一些研究人员报告了 LiDAR 数据在城市森林中的适用性。 Haala 和 Brenner (1999) [27] 通过对光栅化 LiDAR 数据和多光谱图像进行分类来提取城市环境中的建筑物和树木。 Wu 等人 (2013) [28] 开发了一种基于体素的方法来识别单个行道树并根据移动激光扫描数据估计形态参数。Liu 等人 (2013) [29] 应用表面生长算法从中分割单个树冠激光雷达点云数据。 Holopainen 等人 (2013) [30] 评估了用于城市树木测绘的机载、地面和移动激光扫描方法的准确性和效率。这些方法都不是为了估计城市森林清查目的的树木指标而设计的。最近,Saarinen 等人 (2014) [31] 尝试使用多源单树库存更新城市树木属性。
使用激光雷达对城市森林进行清查的挑战主要来自三个方面:城市地区的复杂性、城市森林的空间异质性以及城市树木结构和形状的多样性。城市地区是建筑物、道路、河流、树木和其他地表特征的马赛克,这使得 LiDAR 过滤过程(地面点与非地面 LiDAR 点的分离)更加困难。城市森林的空间异质性也是一个挑战。与天然林中的树木在空间相邻时往往具有相似的树冠特征不同,城市环境中的树木通常是单棵树或孤立的树群,具有可变的高度和树冠宽度,以及多个树梢。城市森林还富含许多不同树种和树龄的混合物,形状各异。阔叶树和针叶树经常相互混合。这些综合因素使得自动化城市森林清查变得非常困难。
已经进行了一些尝试,仅使用 LiDAR 数据或使用 LiDAR 和光学图像的协同作用(例如,[27-34])来检测和模拟城市环境中的森林,但是将 LiDAR 数据应用于单棵树的城市森林清查水平还是比较低的。为此,本研究的主要目标是开发从 LiDAR 点云中分离个体树木并估计树木指标(树高、基高、树冠深度和树冠直径)的新方法,这可以带来自动化的城市森林清查下降到单个树级别。

图 1. 使用原始 LiDAR 数据估算树木指标的图示。
2. Study Area and Data
德克萨斯州达拉斯北部的 Turtle Creek Corridor 被选为我们的研究区域(图 2)。该地区的地形以 Turtle Creek 为主,它始于达拉斯中北部(北纬 32°51’,西经 96°48’),向西南流经高地公园和大学公园 5 英里,到达三一河口河流(北纬 32°48’,西经 96°50’)。研究区域的海拔从 112 米到 156 米不等,小溪上方海拔较低,小溪沿岸海拔较高。该场地是一个典型的城市区域,具有植被、建筑物、道路、小溪和其他人造特征的复杂空间组合。 Turtle Creek 地区拥有复杂的生态系统,100 多年来一直是达拉斯的兴趣和发展中心。为了更好地管理这一资产,帮助了解当前的生态系统,并鼓励该地区优先发展,Turtle Creek 协会于 2008 年 8 月进行了实地调查,随后同时采集了小型离散激光雷达数据和高空间2008 年 9 月 24 日分辨率高光谱图像。
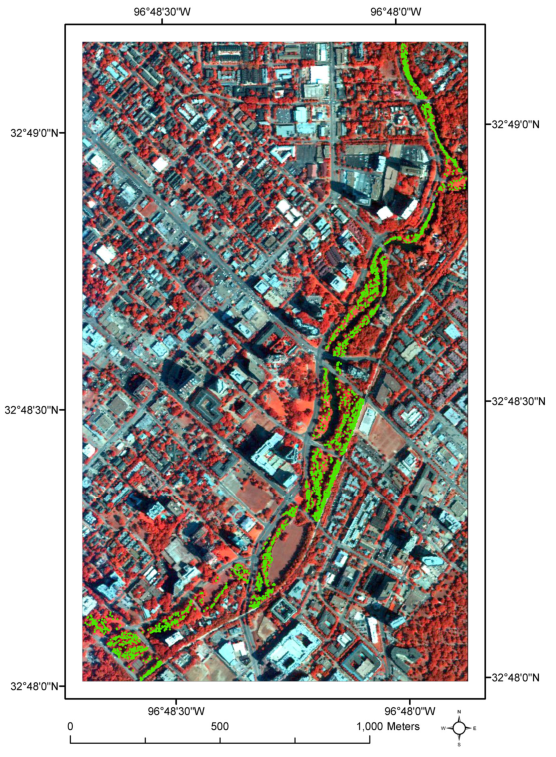
图 2. 研究地点以收集到的高光谱数据的彩色合成图显示。测量的树木位置以绿点显示。
实地调查是通过与 Halff Associates, Inc. 签订的合同进行的。只有胸径 (DBH) 大于 4 英寸的树木才会被测量并标上识别号,因此海龟区总共调查了 2602 棵树木溪走廊。记录了每棵测量树的树木位置、物种属性、胸径和健康状况。图 2 以绿点显示了这些被调查树木的位置。遗憾的是,此次调查并未测量树高、基高、树冠深度和树冠半径。因此,我们于 2010 年 8 月前往实地并使用 TruPulse 360 激光测距仪和 Trimble GeoXT GPS 设备测量了 144 棵树。
LiDAR 数据由 Terra Remote Sensing Inc. (TRSI) 使用专有的 Lightwave Model 110 whisk broom 扫描 LiDAR 系统收集。由于航班之间有意有 80% 的重叠,获得了 3.5 p/m2 的平均点密度。原始 LiDAR 点云数据由 TRSI 使用 Microstation Terrasolid 和 TRSI 专有软件处理。最终产品以常用的 LAS LiDAR 格式提供,投影为 NAD_1983_UTM_Zone_14N。此外,使用 AISA 双高光谱传感器与 LiDAR 数据同时获取精细空间分辨率光学高光谱图像。以 1.6 m 的空间分辨率获取具有 492 个光谱带的高光谱图像。辐射校准和几何校正由供应商执行。通过使用增益和偏移应用逐像素校正,将原始收集的图像从原始数字转换为辐射率。偏移量是从存储在“暗”文件中的数据中提取的,这些文件是快门关闭时的传感器读数,用于估计传感器噪声。增益是从传感器制造商提供的校准文件中提取的。在从原始值到辐射值的转换过程中,还应用了对掉线和光谱偏移的进一步校正。然后使用 ATCOR 将整个图像数据集从辐射率转换为表面反射率,ATCOR 是一种基于 Modtran 的代码,专门开发用于执行大气校正。对于几何校正,供应商使用 LiDAR 位置信息来计算数据集中每个像素的真实世界坐标,然后对高光谱图像进行重新采样。然后对研究区域的预处理图像进行镶嵌和裁剪。研究地点的高光谱数据的假彩色合成如图 2 所示。
3. Methodology
3.1. A Framework to Combine LiDAR and Hyperspectral Data for Urban Forest Inventory
为了检测每棵树并估计其相关指标(树高、基高、树冠深度、树冠直径),需要多个数据处理步骤。这些在图 3 中进行了总结。LiDAR 数据过滤是将地面点与地上点分开的第一步。然后使用地面点构建数字地形模型 (DTM),这将有助于消除局部地形对树木指标的影响估计。在所有地上点中,需要将植被点与非植被点分开。这是通过使用源自高光谱数据的归一化差异植被指数 (NDVI) 实现的。为了提取单棵树,需要将撞击树冠表面的 LiDAR 点与穿透树冠的点隔离开来提取这些点。在此之后,应用树梢检测算法(称为爬树法)来识别每棵树的树梢,然后使用树边界提取算法(称为甜甜圈扩展和滑动法)来隔离个体树。所有单独的树木级别属性,包括树木位置、高度、基础高度、树冠深度和树冠直径都存储在树木库存数据库中。 LiDAR 检测到的每棵树的物种都可以使用高光谱数据来识别,Zhang 和 Qiu (2012) [35] 对此进行了报道。该框架分为三个主要步骤:LiDAR 数据过滤、树梢检测和个体树提取。它们在以下小节中描述。
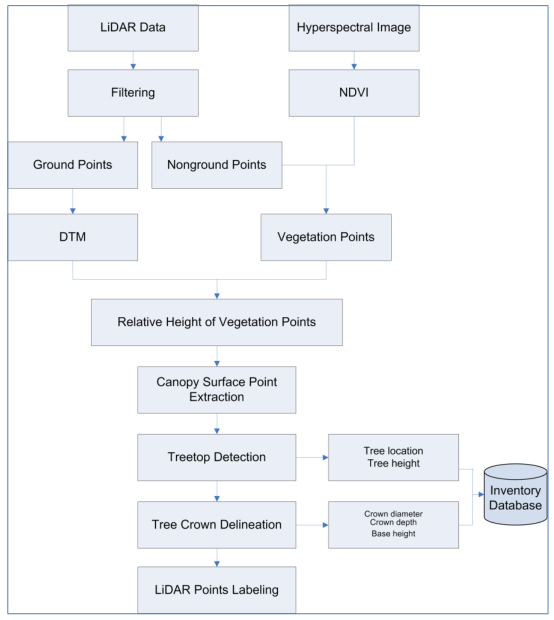
图 3. 设计的框架将 LiDAR 和高光谱数据结合起来用于单棵树级别的城市森林清查。
3.2. LiDAR Data Filtering and Canopy Points Separation
已经开发了各种方法来自动化 LiDAR 数据过滤过程。 Sithole 和 Vosselman (2004) [36] 比较了八种滤波器,发现这些滤波器在平坦的乡村景观中表现良好,但在复杂的城市地区和植被粗糙的地形中产生了较大的误差。由于我们的研究中存在多种特征类型区域,这八个过滤器都不可能达到令人满意的结果。在这项研究中,使用了一种基于向量的过滤技术,称为 k 互最近邻聚类算法 [37]。该算法的思想是,共享相似 LiDAR 属性的邻域中的点应属于代表地面或地上的同一簇。该算法的一个主要优点是直接使用原始 LiDAR 点云不会丢失信息。该算法的更多细节可以在 Chang (2011) [37] 中找到。过滤结果的准确性是使用基于随机选择的参考点的普遍采用的遗漏和佣金误差方法来评估的。数据过滤后,地面派生点用于生成 DTM,对原始 LiDAR 高程数据进行归一化,以消除地形影响。
要在地上 LiDAR 点云中提取单个树木,需要识别击中树冠的点,以便非树点不会干扰单个树木的隔离。来自窄带高光谱数据的 NDVI 可用于此目的。我们从高光谱数据(波段:860 nm 和 660 nm)中导出了 NDVI 图像,然后在空间上叠加了地上 LiDAR 点云。然后提取 LiDAR 点所在单元格的 NDVI 值作为该点的附加属性。然后将 NDVI 值大于零的 LiDAR 点视为植被点。
3.3. Treetop Detection
为了有效且高效地找到树梢,需要通过将撞击树冠表面的 LiDAR 点与穿透树冠的点隔离开来提取这些点。这是通过以非重叠方式在研究区域上移动一个方形窗口并在其中保留最高的第一返回脉冲来实现的。在此之后,应用树顶检测算法、爬树算法来识别每棵树的最高点(即树顶)。
局部最大值算法通常用于树梢检测,方法是在 LiDAR 派生的 CHM 中找到固定或可变大小窗口内的局部最大值(例如,[5,8,12])。这种方法的主要问题是会产生较大的佣金误差,即非树顶局部最大值可能会被错误地分类为树顶 [12]。使用 LiDAR 点云数据进行树梢检测的具有可变大小窗口的局部最大值方法遇到与基于 CHM 的方法相同的问题 [20]。
在这项研究中,基于对局部最大值方法的改进,开发了一种使用 LiDAR 点云的树梢检测算法。该算法涉及几个步骤。第一步是选择研究区域的第一个 LiDAR 点。第二步是获取局部最大值,即以所选点为中心的圆内的最高点。第三步,将局部极大点指定为新的中心,如果局部极大点处的高程高于当前选择点(即当前中心)的高程,则重复步骤二和三;否则,将当前选择的点标记为潜在的树梢并停止搜索局部最大点。对剩余的点云将继续此过程,直到识别出所有树梢。这个寻树过程被称为爬树算法,因为树顶可以从任何方向到达。
上面描述的爬树算法可能适用于具有单个定义明确的顶点的树,例如大多数针叶树。但是,对于具有多个顶部或凹形树冠形状的树木,可能会再次出现佣金错误。城市树木通常就是这种情况,因为它们大多是形状复杂的阔叶树。在这些情况下可能会检测到假树梢。解决此问题的一种简单有效的方法是使用水平阈值 (H) 来去除假树梢。在使用爬树算法检测到的所有树梢中,如果两个树梢的水平欧氏距离小于定义的阈值,则较低的树梢将被丢弃,较高的树梢将被保留以供进一步分析。这种改进的树梢检测方法被称为约束爬树算法,因为它结合了水平阈值。另请注意,地上 LiDAR 植被点可能来自灌木;因此,如果检测到的树木高度小于 1.5 m,则将检测到的树木视为要丢弃的灌木。
3.4. Individual Tree Extraction
检测到的树梢将用作进一步分割单个树木的起点。开发了一种基于爬树方法的逆运算的算法来实现这一点。该算法称为甜甜圈扩展滑动法,由以下步骤组成:
(1) 从树梢检测算法中随机选择一个检测到的树梢 pt(xt, yt, zt)。
(2) 计算落在以所选树梢(xt, yt, zt)为中心的水平圆内的所有点(xi, yi, zi)的平均高程:
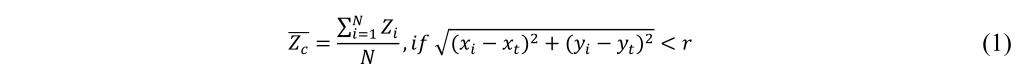
其中
Z
c
‾
\overline{Z_c}
Zc是落入半径为 r 的圆内的 N 个点的平均高程,(xi, yi, zi) 是每个点的 3-D 坐标,(xt, yt, zt) 是圆心,N 为圆内点的总数。圆的初始半径 ® 是在地面清单中观察到的最小树冠尺寸。
(3) 将平均高程 ( Z c ‾ ) \left(\overline{Z_c}\right) (Zc)与所选树梢的高程 ( Z t ) \left(Z_t\right) (Zt) 进行比较。如果 Z c ‾ > Z t \overline{Z_c}>Z_t Zc>Zt,将r减小到一个较小的值 ( r − Δ r ) (r-\Delta r) (r−Δr)并重复步骤2和3直到 Z c ‾ < Z t \overline{Z_c}<Z_t Zc<Zt,然后导出圆的半径作为估计的树冠半径。否则,对于 ( Z c ‾ < Z t ) \left(\overline{Z_c}<Z_t\right) (Zc<Zt)将圆的半径增加 Δ r \Delta r Δr并得到一个扩大的圆。然后计算落在由前一个圆和扩展圆定义的水平甜甜圈 ( Z d 1 ‾ ) \left(\overline{Z_{d 1}}\right) (Zd1)内的点的平均高程:
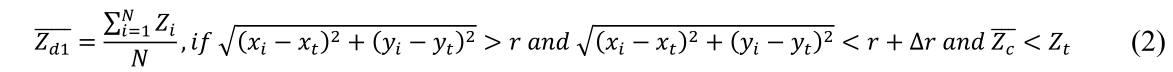
其中
Δ
r
\Delta r
Δr是用户指定的正值,用于定义扩展步长。
(4) 将 Z d 1 ‾ \overline{Z_{d 1}} Zd1与 Z c ‾ \overline{Z_c} Zc进行比较。如果是 Z d 1 ‾ > Z c ‾ \overline{Z_{d 1}}>\overline{Z_c} Zd1>Zc或 Z d 1 ‾ = 0 \overline{Z_{d 1}}=0 Zd1=0,说明甜甜圈扩展到树木的边界,然后导出圆的半径作为估计的树冠半径。否则,对于 Z d 1 ‾ < Z c ‾ \overline{Z_{d 1}}<\overline{Z_c} Zd1<Zc再次将半径增加 Δ r \Delta r Δr并得到一个新扩展的甜甜圈,这意味着与之前的甜甜圈相比,甜甜圈向下滑动。然后计算落入由增加的圆及其前一个圆定义的扩展的新甜甜圈 ( Z d 2 ‾ ) \left(\overline{Z_{d 2}}\right) (Zd2)中的点的平均高程:
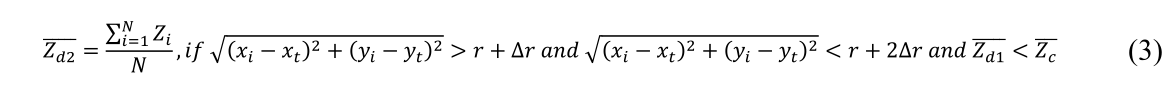
(5) 将
Z
d
2
‾
\overline{Z_{d 2}}
Zd2与
Z
d
1
‾
\overline{Z_{d 1}}
Zd1进行比较。如果是
Z
d
2
‾
>
Z
d
1
‾
\overline{Z_{d 2}}>\overline{Z_{d 1}}
Zd2>Zd1或
Z
d
2
‾
=
0
\overline{Z_{d 2}}=0
Zd2=0,将后续甜甜圈的半径导出为估计的冠半径。否则对于
Z
d
2
‾
<
Z
d
1
‾
\overline{Z_{d 2}}<\overline{Z_{d 1}}
Zd2<Zd1,意味着甜甜圈再次滑动,重复步骤 4 中的过程,增加半径 r 并得到一个扩展的新甜甜圈,并再次计算落入扩展的新甜甜圈的点的平均高程。
这种甜甜圈展开滑动算法只用点打在冠层表面来测试展开甜甜圈的向下方向。为了有效地找到树冠的边界,必须去除穿透树冠的激光雷达点。在推导树冠大小后,落在树冠圆体内的激光雷达点在树冠表面和树冠表面下方(穿透点)被分配给检测到的个体树木。然后从 LiDAR 点云中分离出一棵单独的树。为了确保来自较低树的点不会被错误地分配给相邻的较高树,该算法可以从最低的树开始并逐步到最高的树。这是通过根据相应的相对高度对检测到的树梢进行排序来实现的。
每棵树的基高和树冠深度也可以通过这种甜甜圈扩展和滑动方法来估计。一棵树的基本高度基本上是从落入最外圈的 LiDAR 点的最小高度得出的。然后可以通过从树顶高程中减去基础高度来估算树冠深度。
5. Conclusions
在这项研究中,我们开发了新的算法来检测单棵树木并从 LiDAR 点云估计相关树木指标以用于城市森林清查目的。这些算法在典型的城市森林中进行了测试。结果表明,使用所提出的爬树算法可以从 LiDAR 点云数据中检测到个体树木,并且可以使用甜甜圈扩展和滑动方法描绘树冠。可以根据原始 LiDAR 数据估算树木指标(树高、树冠直径、树冠深度和基高),并且精度合理。查看森林中的个别树木很重要,应该是城市森林清查的第一步。 LiDAR 点云数据提供了有效估计森林树木数量及其位置的可能性。所提出的算法自动有效地估计树木指标的能力很重要,因为它们是预测其他森林参数的关键变量。研究证明,激光雷达是确定这些参数的合适技术。
请注意,在 LiDAR 树处理中仅使用了从高光谱数据生成的 NDVI 图像。使用数据融合技术进一步整合 LiDAR 和高光谱数据可以提高个体树木描绘、指标估计和物种分类的准确性。例如,光谱信息可用于通过排除在树的边缘具有非常不同光谱的 LiDAR 点来提供更好的树提取。这可能会在表征城市森林方面带来显着的收益,从而加速 LiDAR 和高光谱在各自领域的应用,从科学兴趣到商业运营实施。将两种数据源完全融合用于森林应用是未来研究的主要方向之一。
与使用点云数据的其他 LiDAR 算法类似,所提出的树梢检测和个体树提取方法非常耗时,因为需要处理大量点云数据。为了解决这个问题,未来可以采用两种解决方案。第一个是基于软件的 LiDAR 算法优化。另一种解决方案是基于硬件的。使用基于图形处理单元 (GPU) 的计算系统来并行化所提出的算法应该会大大减少处理时间。事实上,结合这些软件和硬件解决方案可能会完全解决基于原始 LiDAR 数据的树木库存的计算瓶颈问题。
到目前为止,所设计的算法仅在达拉斯市区进行了测试。在具有不同物种、森林组成和传感器的其他城市地区需要进行大量额外研究,以检查这些技术的稳健性和可扩展性。还预计该算法可以在非城市森林中工作,并进行修改以适应自然环境,这将是未来研究的主要任务。










![[转]深度学习 Transformer架构解析](https://img-blog.csdnimg.cn/img_convert/ca36d743d00a5e8479c5475ca412cb0a.png)