目录
URL
urlencode和urldecode
http请求格式
http响应格式
http请求解析
http响应发送
http的方法
GET vs POST
http的状态码
重定向
http常见报头属性
URL
首先我们需要知道以下几点,
1.我们请求的图片,html,css,js,视频,音频,标签,文档,等这些都称之为"资源"。
2.服务器后台,是用Linux做的。
3.IP + Port唯一的确定一个进程。
4.公网IP地址是唯一确认一台主机的,而我们所谓的网络"资源"都一定是存在于网络中的一台Linux机器上。Linux或者传统的操作系统,保存资源的方式,都是以文件的方式保存的。单Linux 系统,标识一个唯一资源的方式,就是通过路径
5.所以:IP+Linux路径,就可以唯一的确认一个网络资源
6.IP地址通常是以域名的方式呈现的。路径可以通过目录名+/确认。
URL(Uniform Resource Locator)——统一资源定位符,通过URL可以定位到互联网中某个确定的资源。

1.协议:用哪种协议来获取这个资源
2.登录信息:可以用表单的方式认证。
3.服务器地址:也叫作域名,和每个IP地址形成映射。
4.服务器端口号:一般的协议名和这个端口号是紧密联系的,确定了协议,一般端口号就被确定了,所以这里的端口号一般都会省略。(比如你是http协议,那我就知道端口号是80)
5.带层次的文件路径:当前IP地址对应的linux主机下对应资源的绝对路径。
6.?后面的是参数
urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转码
我们在百度里面搜c++,会看到后面的参数里面有wd,wd的值就是我们要搜索的内容。但是我们发现c++变成了c%2B%2B,因为+是特殊字符,需要对这种字符进行转码。
转码的规则:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
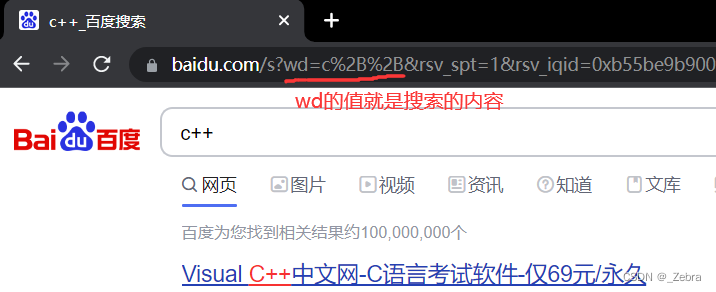
"+" 被转码成了 "%2B"
urlencode:称为编码/转码
urldecode就是urlencode的逆过程,称为解码
一般由浏览器帮我们编码,服务器可能要自己解码
http请求格式
无论是请求还是响应,基本上http都是按照行(\n)为单位进行构建请求或者响应的!
无论是请求还是响应,几乎都是由3或者4部分组成。(4部分就是包含空行了
- 请求行:也就是首行第一行的内容,包括1.请求方法; 2.url;3.http协议的版本
- 请求报头:每个请求报头占一行,这里是由多个请求报头。以key-value形式的属性构成,最后的分隔符是\n
- 空行:请求报头和请求正文之间有一个空行\n
- 请求正文:不一定有,主要存放用户提交的数据(比如登录的时候提交的用户名和密码)
注:请求行+请求报头 = http请求报头
请求正文 = 有效载荷
http响应格式
- 状态行:也就是首行第一行的内容:1.http协议的版本;2.状态码(404);3.状态码描述
- 响应报头:每个响应报头占一行,这里是由多个响应报头。以key-value形式的属性构成,最后的分隔符是\n
- 空行:响应报头和响应正文之间有一个空行\n
- 响应正文:服务器根据用户请求响应给用户的内容
注:响应行+响应报头 = http响应报头
响应正文 = 有效载荷
http请求解析
1.读到空行\n,就表示报头部分读完了;
2.如果在报头中读取到Content-Length,那就说明有正文部分(否则就是没有正文),Content-Length的值就是正文部分的长度(也就是有效载荷的长度)。如果有正文,我们根据Content-Length长度的字节即可。(Content-Length是一个自描述字段)
具体什么时候会没有正文,和请求方法有关。
http响应发送
read和write可以使用recv和send函数替换,后两个函数是Linux操作系统针对网络通信的。
当我们返回响应的时候,也需要按照http协议,发送一个字符串作为响应。
Http协议,如果自己写的话,本质是,我们要根据协议内容来进行文本分析
每一行就像是一个成员,我们在每个成员后面加上\n,把它组成一个字符串的过程,实际上就是序列化的过程。
简单构建并发送响应的部分代码:
ssize_t s = recv(sock, buffer, sizeof(buffer), 0);
if(s > 0)
{
buffer[s] = 0;
std::cout << buffer; //查看http的请求格式! for test
std::string http_response = "http/1.0 200 OK\n";
http_response += "Content-Type: text/plain\n"; //text/plain,正文是普通的文本
http_response += "\n"; //空行
http_response += "hello,zebra!";
send(sock, http_response.c_str(), http_response.size(), 0); //ok??
}http的方法

GET vs POST
一.概念
GET方法叫做获取,是最常用的方法,默认一般获取所有的网页,都是GET方法。但是如果GET要提交参数(GET方法是可以提交参数的),通过URL来进行参数拼接从而提交给server端。
POST方法叫做推送,是提交参数比较常用的方法,但是如果提交参数,一般是通过正文部分提交的,但是你不要忘记,Content-Length: XX表示参数的长度,这个属性要在报头中给出。
二.区别
参数提交的位置不同,(想要真的安全,就是要加密)
1、参数提交的位置不同,POST方法比较私密(私密!=安全),不会回显到浏览器的url输入框!get方法不私密,会将重要信息回显到url的输入框中,增加了被盗取的风险。
2. get是通过url传参的,而url是有大小限制的!和具体的浏览器有关!POST方法,是由正文部分传参的,一般大小没有限制!
三.如何选择
1.如果提交的参数,不敏感,数量非常少,可以采用GET
2.POST:否则,就使用POST方法
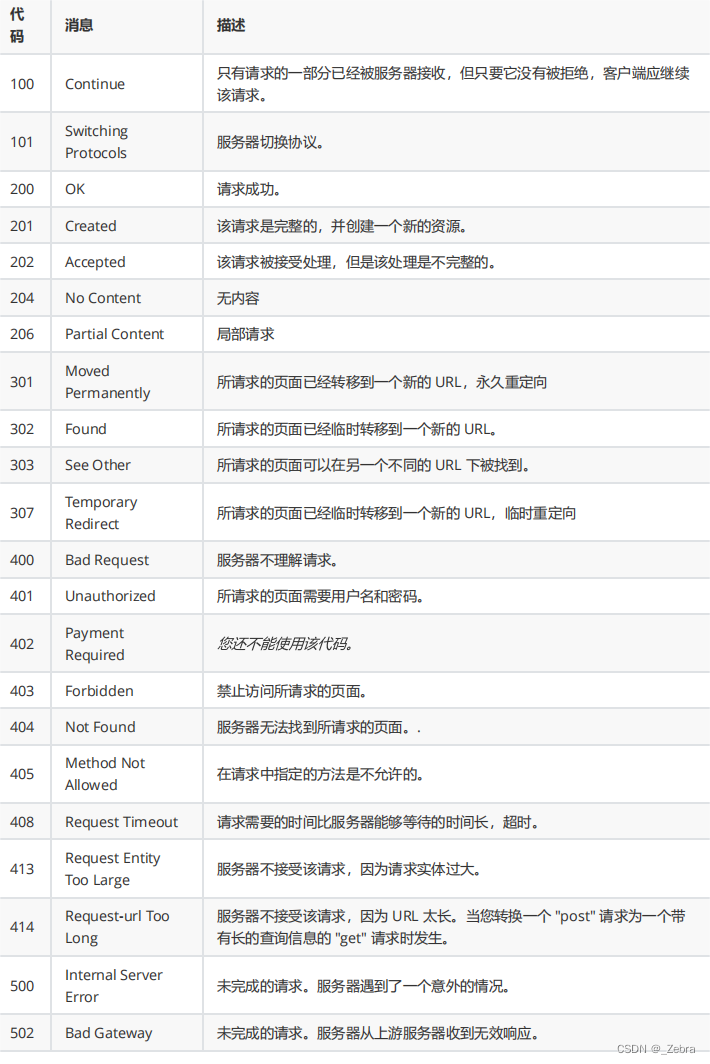
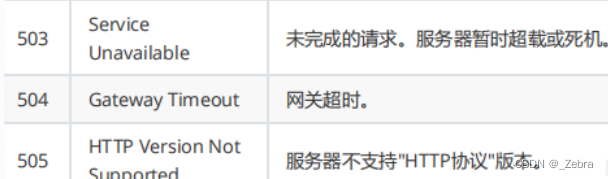
http的状态码

1.比如404状态码,对浏览器并没有意义,不管状态码如何,浏览器就是正常显示服务端提供的界面。浏览器针对404并不会专门做处理。
2.4开头的是客户端的错误;5开头的是服务器端的错误
重定向
1.重定向概念
类似以下的现象就叫做重定向:
1.当访问某一个网站的时候,会让我们跳转到另一个网址。(比如老网站不用了,如果有人访问老网站,就自动重定向跳转到新网站)
2.等我访问某种资源的时候,提示我登录,跳转到了登录页面,输入完毕密码,登录的时候,会自动跳转回来(登录,美团下单)
2.永久重定向:
服务器不提供服务,而是告诉客户端去对一个新的网站重新发起请求。当浏览器收到服务端永久重定向的信息,就会把用户收藏夹(书签等)里面的旧网址也替换成新网址。
使用场景:网站搬迁,域名更换。
3.临时重定向:
等我访问某种资源的时候,提示我登录,跳转到了登录页面,输入完毕密码,登录的时候,会自动跳转回来,这种就是临时重定向,每天都有可能发生,是一种业务的需求。
4.注意事项:
1.重定向是需要浏览器提供支持的,所以浏览器需要认识3开头的状态码。
2.server让浏览器重定向的时候,需要告诉浏览器要重定向到哪里,所以需要一个Location字段在http报头中
部分代码如下所示,只需要设置好状态码和Location字段,即可实现页面的重定向。(301是永久重定向;302,307是临时重定向)
std::string response = "http/1.1 302 Found\n";
response += "Location: https://www.qq.com/\n";
response += "\n";
send(sock, response.c_str(), response.size(), 0);注:如果自己收藏网站,就可以明显观察到永久重定向和临时重定向的区别。(这里在Chrome浏览器里面测试。收藏网址后,即使服务器关闭,发生永久重定向以后访问收藏的网页还是会直接跳转到腾讯首页;当时如果是临时重定向就不会直接跳转到腾讯首页)
http常见报头属性
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
cookie和session
1.cookie+session的本质:提高用户访问网站或者平台的体验。(因为http是一种无状态的协议,如果不使用cookie和session,每次访问服务器资源的时候都需要让你登录来认证你当前这个用户,有了cookie和session以后,你只要登录了,就可以在一定时间内访问对应的服务器资源,而不需要重新登录)
2.http是一种无状态的协议:http并不会记录这次请求的上下文信息,它不知道历史上这个人有没有发起过请求,也不会记录这次请求。
——因为是一种无状态的协议,所以http协议实现起来比较简单
3.但是我们在访问网站的时候,会有浏览记录,登录以后会自动保存密码,登录成功以后某段时间内不需要重新登录,在网页间跳转的时候不需要重复登录。
——这些并不是http本身要解决的问题,http可以提供一些技术支持,来保证网站具有“会话保持”的功能。(会话管理)
cookie
1.对于浏览器: cookie其实是一个文件,该文件里面保存的是我们的用户的私密信息。
2.对于 http协议:一旦该网站对应有cookie,在发起任何请求的时候,都会自动在request中携带该cookie信息。
-如何使用:
登录成功后,浏览器会把用户信息(如用户身份,用户名密码等),放在本地的一个cookie文件里面,然后之后每一次对这个网站发起请求的时候,每一个请求中都会携带对应的cookie信息代表用户的身份。
-保存位置:
1.文件版(cookie信息放在本地的文件中,在安装目录或者用户目录下);
2.内存版(存放在内存中,浏览器一旦关闭就cookie信息就没了)
-使用方法:在请求报头中加入Set-Cookie字段,也可以写在一个Set-Cookie里面。
http_response += "Set-Cookie: id=zebra\n";
http_response += "Set-Cookie: password=123456\n";
-注意事项:如果别人盗取我们的cookie文件,别人
1.可以凭借我的身份进行认证访问特定的资源
2.如果保存的是用户名密码,那么就非常糟糕了
3.单纯使用cookie,是具有一定的安全隐患的。
session
单纯使用cookie,是具有一定的安全隐患的。现在的网络通信中一般是cookie+session一起用。
核心思路就是:把用户的私密信息,保存在服务端。
使用方式:
当用户输入用户名密码登录,发起请求的时候,服务端会根据为当前用户生成一个session文件,里面保存了用户的用户名密码等私密信息,同时会为当前用户随机生成一个唯一的session_id,并放在Set-Cookie里面返还给浏览器,浏览器拿到Set-Cookie里面的session_id以后,在客户端生成一个cookie文件,之后每次发起请求的时候,都带上cookie的内容。
用了session为什么会更加安全?
如果客户端本地的cookie被盗取,别人拿着session_id访问相同的网站,还是可行,但是相比于只用cookie,会更加安全一些。
防盗方式:
根据IP地址可以知道当前主机的位置,中国各个省的IP地址是不一样的,所以可以根据IP地址知道你主机的实际地址。(想想为什么b站的评论区会直接显示你位于哪个省份)
如果发现你在不同的地点登录,服务端就可以废弃掉原先的session_id,让用户重新登录,从而为用户生成一个新的session_id。
——像这样就可以在服务端进行判断,从而提高安全性。(如果发现被盗取了,服务端直接废弃掉用户的session文件废弃掉即可。)