写在前面
在2023年新年伊始,科技界最为爆火一款产品无疑是OpenAI公司出品的ChatGPT了,作为一名NLP领域从业者,似乎也好久没有看到如此热闹的技术出圈场景了。诚然从现象来看,无论从效果惊艳度、社会效应、商业价值、科技发展方向的任何一方面来说,ChatGPT都是一个里程碑式的作品,更是AI发展的一记强心剂。
本文旨在简单过一下相关模型原理,基于之前的Transformer相关知识点,快速了解相关原理。
GPT
GPT论文
要想了解chatGPT的原理,初代GPT是一个不能被忽视的模型。
GPT发布在Transformer之后、BERT之前,GPT其实是由Transformer的Decoder部分演变而来,而BERT则是由Transformer的Encoder部分发展而来,两者走了不一样的技术路线,但事实上,在ChatGPT出来之前,BERT的影响范围实际上是要大于GPT的。或许我们能从GPT的原理以及它与BERT的差异中找到答案。
在Transformer出来之后,OpenAI团队就在思考一个问题,NLU的任务就很多啊,但是现实存在的能够用于训练这些任务模型的已标注数据却很少,反倒是大量的未标注数据没有得到好的利用,那我们能不能用这些未标注数据训练一个大的预训练模型,然后再利用少量的标注数据在不同任务上去做微调呢?听起来好像是可以的,那就试试呗!
OpenAI选用了Transformer中的Decoder部分来作为模型的基础,因为Encoder部分只是一个特征提取器,并不具备生成能力,而Decoder刚好符合“generative pre-training”的设想(找补的后话了,GPT早于BERT,站在当时的时间节点上,GPT只是先选择了一个技术路线,后来者BERT又选择了另外一条而已。)
OpenAI团队认为在实现这样一个生成式的预训练模型的路上有两个问题需要解决:
- 目标函数怎么选?
- 在不同的子任务上如何微调?
论文中给出了答案:
因为是预训练过程是无监督的,目标函数采用类似于w2v中才用的方式,其实也就是最大化一个似然函数(核心是语言模型中窗口内单词一起出现的联合概率)。在有监督的子任务上微调时,往往在最后一层Decoder层输出上做一个softmax。在不同任务上的微调如下图所示:
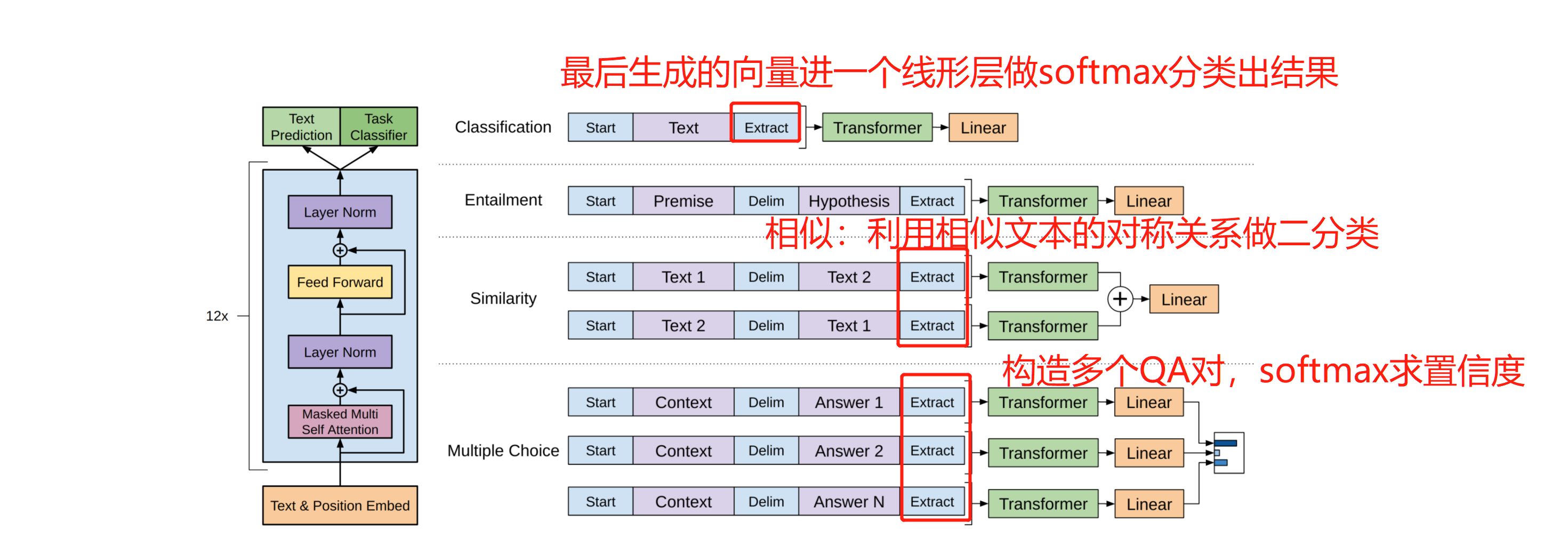
此外论文中还提到一点就是GPT的网络层数是12层、隐藏层维度768,后面的BERT-base也正是基于此做的对比。
GPT2
GPT2论文
GPT2发布在BERT之后,彼时BERT已经大放光彩,GPT既然选了生成式预训练这条道,就得继续走啊,然后GPT2干了件啥事呢?训练更大的模型,大力出奇迹,15亿的训练参数,然后提出我这种方式可以“zero-shot”(模型在预训练完成之后不需要任何下游任务的标注数据来进行微调,而是直接进行预测)啊,这就是它的卖点之一。
整体原理上GPT2与GPT1没有太大区别,有几个细节可以稍微看一下:
- 因为是zero-shot,所以训练数据里边的那些分隔符就都不能要了,因为也没有对应的标签了;
- 训练数据没有使用 Common Crawl 的公开网页爬取数据,因为信噪比太低,作者去Reddit 上爬取了大量数据,然后选取了karma值不小于3的进行保留;
- 举个机器翻译的例子,要用 GPT-2 做 zero-shot 的机器翻译,只要将输入给模型的文本构造成
translate english to chinese, [englist text], [chinese text]就好了。比如:translate english to chinese, [machine learning], [机器学习]。这种做法就是日后鼎鼎大名的 prompt。
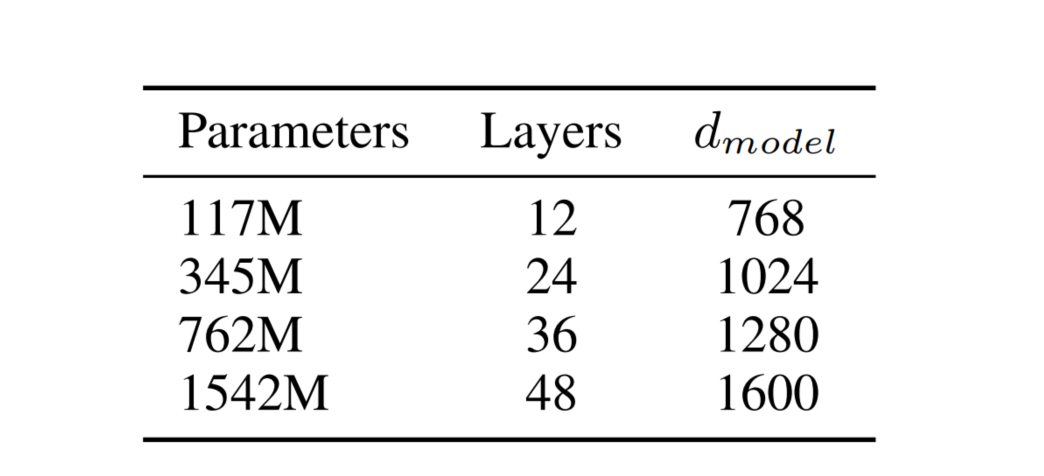
最后看一下GPT2的参数量:
GPT3
GPT3论文
GPT3的论文名字《Language Models are Few-Shot Learners》有点意思哈,看得出来,GPT3其实是想要沿用GPT2的卖点,但是完全的zero-shot其实效果上又没有那么的好,最好还是给一点标注数据(Few-Shot),这样在不同的子任务上的微调会见效更快。
GPT3作者们发现:预训练+微调的模式虽然在NLP很多领域都取得了不错的成绩,但是大多数时候我们还是需要一定的标注数据用于特定任务上的微调,但是相比之下人类的学习过程却不是这样,人类通常只需要几个例子或者简单的指令就可以完成一项新的语言任务。于是作者训练了一个1750亿参数的模型,然后不在特定任务上做任何的微调或者梯度更新(可以认为是超巨量的可学习参数已经学到了海量的知识,足以应对不同的任务)。
具体我们看看怎么做的:
文中提出一个新的叫法:meta-learning,其实也就是在多种不同形式的数据上进行学习。如下图所示
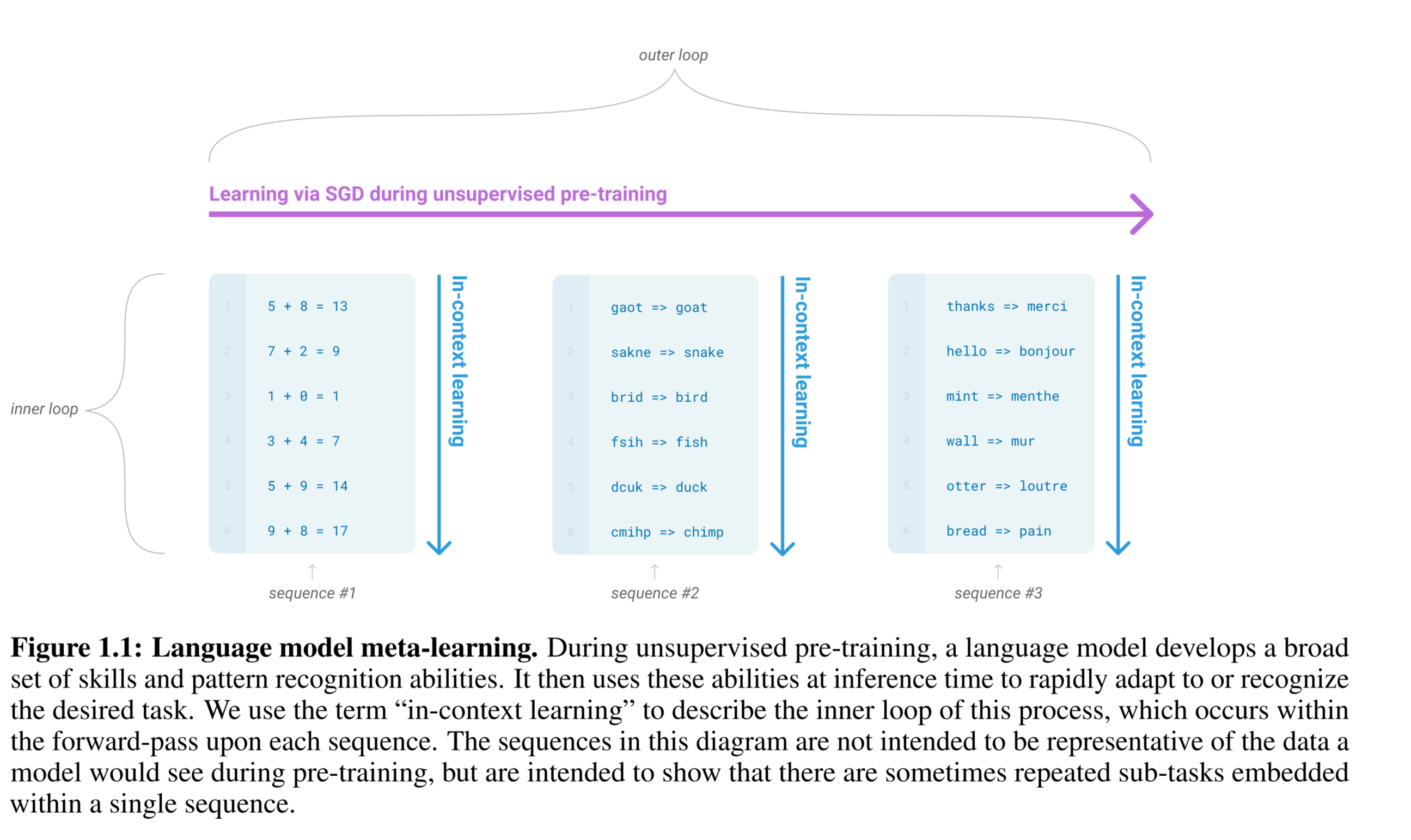
模型基本还是上一代的模型,然后在我们使用的时候,只需要给一定的提示即可,我们可以看到在不同数量的提示下,实验得到的结果:
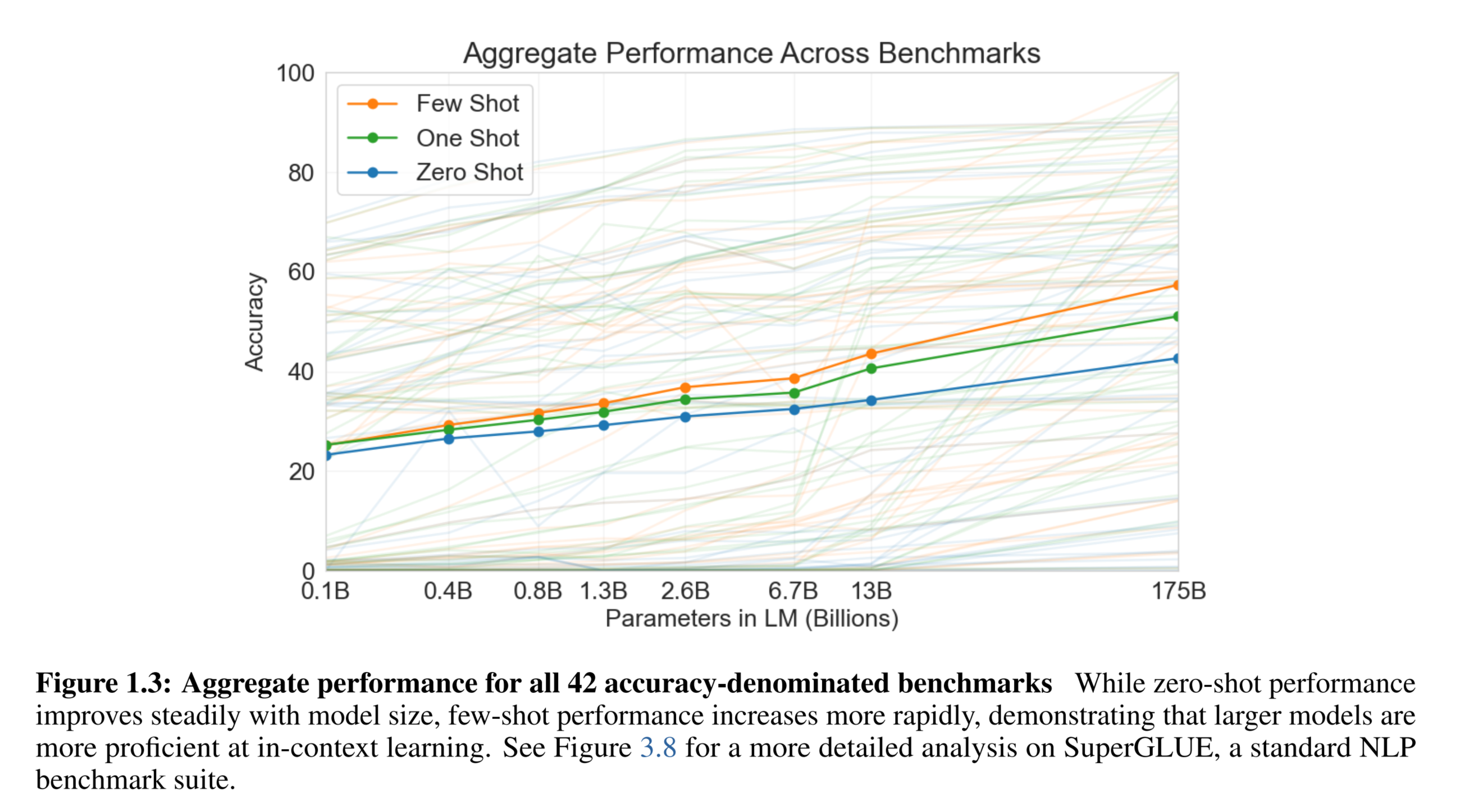
看得出来,给的提示越多,其效果越好。我们可以具体看到三种提示的直观对比:

其他的好像没有什么特别需要说明的,哦,有一点,GPT3在GPT2的基础上做了一个改变(在Transformer层中交替使用稠密和本地带状稀疏注意力机制),为了减少过拟合的发生。然后贴一个各种GPT3的网络参数吧。
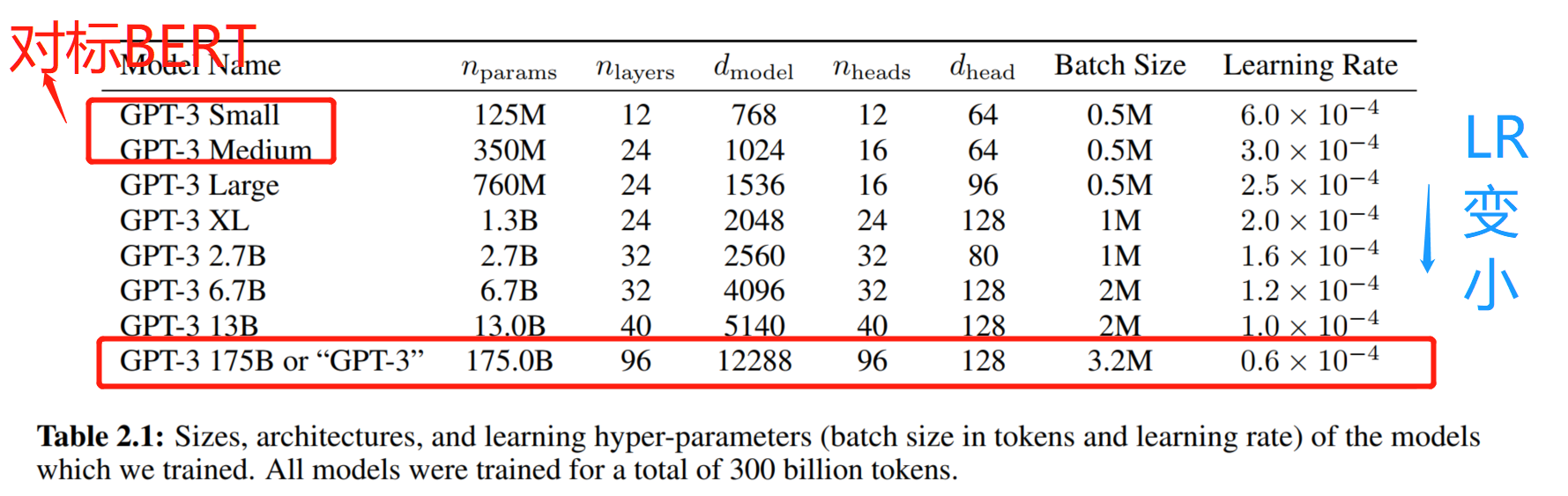
然后再就是一大堆实验,这里也不再复述。然后有意思的是在文中也提到了对这种生成式大模型的一些可能的影响的讨论。包括:
- 模型可能会误导人啊
- 模型可能会造假啊
- 模型可能会有威胁的行为啊
- 模型会有性别歧视和宗教偏见啊
- …
总之这些讨论我觉得还是挺有意义的,展现了一个负责任团队的社会责任感。
Instruct GPT与ChatGPT
Instruct GPT论文
ChatGPT 的论文还没有发,但是官网的论文基本就说明了是基于GPT3.5而来,其实也就是基于上面的Instruct GPT而来。我们可以简单来看一下他的原理。当然我也更加推荐张俊林大佬对于它的解读,或者沐神的论文精读视频。但最好的还是我们自己去读一读原论文,印象更加深刻。
我让ChatGPT翻译了一下论文的摘要:
这篇论文表明,让语言模型变得更大并不能让它们更好地遵循用户意图。例如,大型语言模型可能生成不真实、有毒或对用户无益的输出。换句话说,这些模型与用户不一致。本文通过使用人类反馈进行微调,展示了一种将语言模型与用户意图对齐的方法,可以在多种任务上使用。首先,我们使用标签写的提示和通过OpenAI API提交的提示,收集一组标签示例,以表示所需的模型行为,然后使用监督学习对GPT-3进行微调。然后,我们收集了一组模型输出的排名数据,使用人类反馈的强化学习对这个监督模型进一步微调。我们称结果模型为InstructGPT。在我们的提示分布中的人类评估中,1.3B参数InstructGPT模型的输出被认为比175B GPT-3更好,尽管参数数量少100倍。此外,InstructGPT模型在真实性和减少有毒输出生成方面表现得更好,同时在公共NLP数据集上的性能影响最小。尽管InstructGPT仍然会犯一些简单的错误,但我们的研究结果表明,使用人类反馈进行微调是将语言模型与人类意图对齐的有前途的方向。
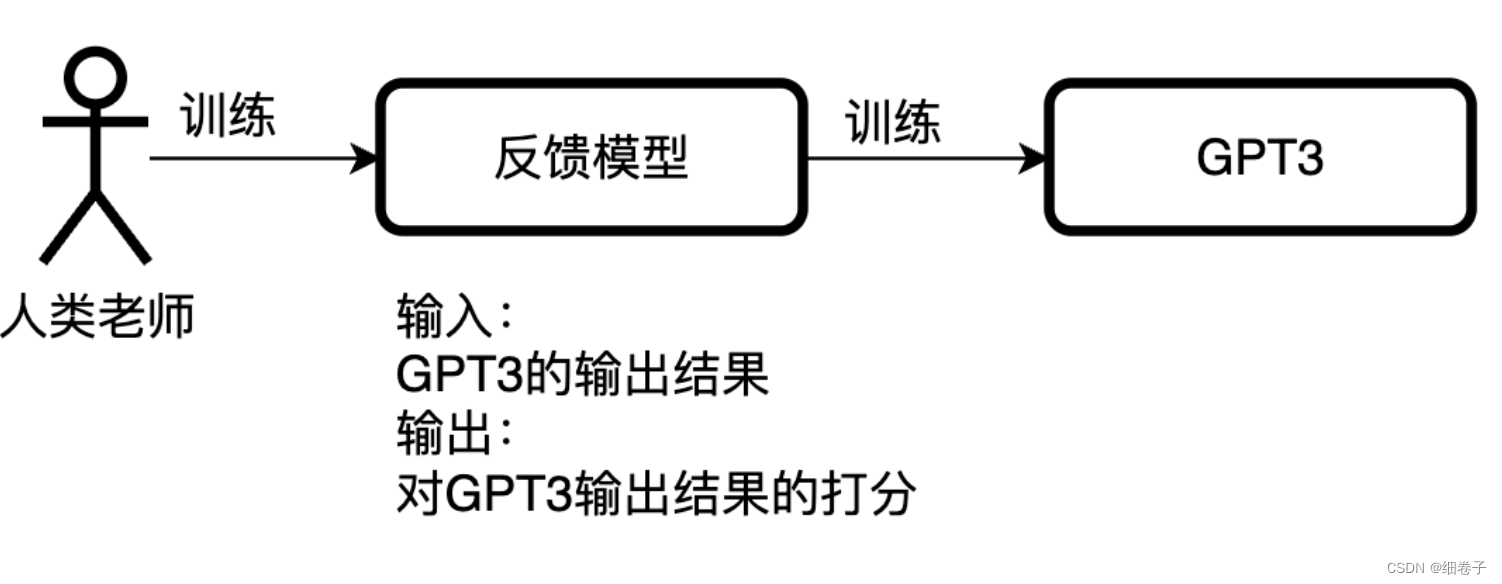
整个模型的基本原理如下图,我在上面做了一些标注。

可以看出来,模型主要有SFT+RM+RL构成,也就是官方说的GPT3.5+RLHF,SFT部分需要标注数据,也就<prompt,answer>对,然后RLHF部分则需要人类对机器生成的answers打分排序,以训练RM模型。具体还有一些关于损失函数的细节大家可以去看原文。(结合了PPO、LLM等多个部分的loss)
当然在原文中作者对安全性、有效性、精细度的讨论也有,比如在完全安全、不产生有毒数据、不睁眼说瞎话方面做的还是不够,这也的确是现阶段ChatGPT存在的问题。但总体来说,我们在这条茫茫求索之路上又向前走了一步了,巨人的肩膀又高了一节。
写在最后
本文并没有对GPT的原理进行庖丁解牛式的解读,只是将一些比较重要的点拼凑了一下,体系感还是不够强,逻辑完整性也有待重新梳理补充。大家如果需要详细深入了解,建议精度文中所提到的四篇论文,以获取更多信息。
回到文章标题的问题:我们离那个理想的AI时代到底还有多远?每个人心中或许都有不一样的答案,我的答案是:革命尚未成功,同志仍需努力!
附:ChatGPT睁眼说瞎话的样子。。。