自动驾驶面临的第一个问题:从哪里来,到哪里去?要解决这个问题,自动驾驶汽车首先需要准确的知道自己在地图上的位置。理所当然的我们可以想到通过GPS来进行定位,但获取GPS信号需要跟卫星进行通信,这就导致它的更新频率比较低,每次获取的位置是不连续的。换一个思路,我们高中都学过物理,当知道了一个小车的起点、速度和加速度之后,就可以通过直线运动公式预测接下来的位置,再结合小车偏向的角度、角速度和角加速度,完全可以通过运动学模型预测小车在二维道路上接下来的位置。此时我们有了两种定位的方式:直接通过GPS观测和间接通过运动模型预测,那该选择哪一种呢?小孩子才做选择,成年人表示我都要,这也是本节要介绍的——卡尔曼滤波。

介绍
卡尔曼滤波的应用非常广泛,尤其是在导航当中,而它的广泛应用主要是因为我们实际生活的世界中存在着大量的不确定性,当我们去描述一个系统的时候,不确定性主要体现在三个方面:① 不存在完美的数学模型,② 系统的扰动往往不可控也很难建模,③ 测量传感器本身存在误差。
最小例子
让我们先从一个简单的例子开始。假如有一辆小车从原点出发,原点处有一个光学测距仪器,每一时刻测量光从原点传播到小车所需的时间,可以据此计算出小车与原点之间的距离。小车上还装了加速度传感器,为了简化任务,该传感器只会输出 x x x方向上的加速度值,每隔 Δ t \Delta t Δt时间输出小车在 t t t时刻的瞬时加速度。我们的最终目标是希望能够尽可能准确的估计小车在每一时刻的速度 v t v_t vt和距离 d t d_t dt。
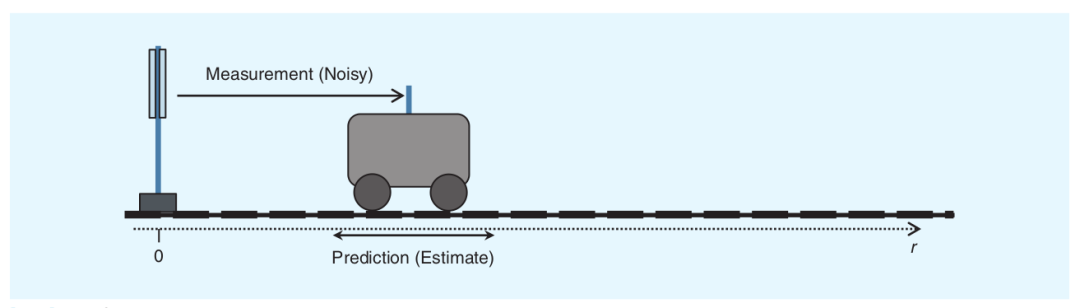
理想情况下,我们当让希望加速度计的测量是完美的,那么直接对加速度做积分就能得到速度,对速度再做一次积分就得到距离。但是在实际应用中,无论什么样的传感器,它的输出都是带有噪声的,直接使用带有噪声的数据做计算会导致累计误差越来越大。
简化一下任务,假如我们现在只想要小车与原点的距离,并且只考虑光学测距仪,再假如小车在某一个位置保持静止,那么为了得到更加准确的距离,我们可以多次测距取平均值,或者用不同的光学测距仪进行测距。我们用 z k z_k zk来表示测量的结果,下标 k k k就表示第 k k k次的测量结果。
如果我们采用同一仪器多次测量的方案,此时如果要估计真实结果,很自然的就可以想到取平均值,即 z ^ k = 1 k ( z 1 + z 2 + . . . + z k ) \hat{z}_k = \frac{1}{k}(z_1+z_2+...+z_k) z^k=k1(z1+z2+...+zk),这里的 ^ \hat{} ^表示这是 z k z_k zk的估计值,即期望。我们对 z ^ k \hat{z}_k z^k的公式做一下变形: z ^ k = k − 1 k 1 k − 1 ( z 1 + z 2 + . . . + z k − 1 ) + 1 k z k = k − 1 k z ^ k − 1 + 1 k z k = z ^ k − 1 + 1 k ( z k − z ^ k − 1 ) \hat{z}_k =\frac{k-1}{k}\frac{1}{k-1}(z_1+z_2+...+z_{k-1}) + \frac{1}{k}z_k =\frac{k-1}{k}\hat{z}_{k-1} + \frac{1}{k}z_k =\hat{z}_{k-1}+\frac{1}{k}(z_{k} - \hat{z}_{k-1}) z^k=kk−1k−11(z1+z2+...+zk−1)+k1zk=kk−1z^k−1+k1zk=z^k−1+k1(zk−z^k−1),即 k k k时刻的估计值 z ^ k \hat{z}_k z^k=上一次的估计值 z ^ k − 1 \hat{z}_{k-1} z^k−1+系数 1 k \frac{1}{k} k1×(当前测量值 z k z_k zk-上一次估计值 z ^ k − 1 \hat{z}_{k-1} z^k−1)。
分析这个公式可以得出以下结论:
- 当 k → + ∞ k \to +\infty k→+∞时, 1 k → 0 \frac{1}{k} \to 0 k1→0,此时 z ^ k → z ^ k − 1 \hat{z}_k \to \hat{z}_{k-1} z^k→z^k−1,也就是说,随着测量次数的增加的,新的测量结果就变得不再重要了,大量测试数据估计的结果就已经比较准确了,所以再增加测量值就没有太大意义了。
- 当 k k k还比较小的时候, 1 k \frac{1}{k} k1相对来说还比较大,此时测量的结果就非常有意义了,尤其是测量值和估计值差距比较大的时候。
- 第 k k k次的估计值 z ^ k \hat{z}_k z^k与第 k − 1 k-1 k−1次的估计值 z ^ k − 1 \hat{z}_{k-1} z^k−1有关,即为递归形式,因此不需要追溯很久以前的数据,只需要此次的测量值和上一次的测量值就可以。
我们将上面的公式提炼一下,令系数为 K \mathbf{K} K,则 z ^ k = z ^ k − 1 + K ( z k − z ^ k − 1 ) \hat{z}_k = \hat{z}_{k-1} + \mathbf{K}(z_{k} - \hat{z}_{k-1}) z^k=z^k−1+K(zk−z^k−1),这里的 K \mathbf{K} K就是后面要推导的卡尔曼增益。为了初步理解卡尔曼增益,我们引入两个参数:
- 估计误差 e e s t i m a t e e_{estimate} eestimate:估计值和真实值的差距,此处的真实值一般表示的是之前得出的估计值
- 测量误差 e m e a s u r e m e n t e_{measurement} emeasurement:测量值和真实值的差距,一般是由于传感器的误差造成的
此时卡尔曼增益定义为 K k = e e s t i m a t e k − 1 e e s t i m a t e k − 1 + e m e a s u r e m e n t k \mathbf{K}_k = \frac{e_{estimate_{k-1}}}{e_{estimate_{k-1}} + e_{measurement_{k}}} Kk=eestimatek−1+emeasurementkeestimatek−1(此公式后面给出推导过程)
讨论:
- 若 e e s t i m a t e k − 1 > > e m e a s u r e m e n t k e_{estimate_{k-1}} >> e_{measurement_{k}} eestimatek−1>>emeasurementk,则 K → 1 \mathbf{K} \to 1 K→1,此时 z ^ k = z ^ k − 1 + 1 × ( z k − z ^ k − 1 ) = z k \hat{z}_k = \hat{z}_{k-1} + 1 × (z_{k} - \hat{z}_{k-1}) = z_{k} z^k=z^k−1+1×(zk−z^k−1)=zk,这就说明当第 k − 1 k-1 k−1次的估计误差远大于第 k k k次的测量误差时,估计值就会更趋向于第 k k k次的测量值;
- 若 e e s t i m a t e k − 1 < < e m e a s u r e m e n t k e_{estimate_{k-1}} << e_{measurement_{k}} eestimatek−1<<emeasurementk,则 K → 0 \mathbf{K} \to 0 K→0,此时 z ^ k = z ^ k − 1 + 0 × ( z k − z ^ k − 1 ) = z ^ k − 1 \hat{z}_k = \hat{z}_{k-1} + 0 × (z_{k} - \hat{z}_{k-1}) = \hat{z}_{k-1} z^k=z^k−1+0×(zk−z^k−1)=z^k−1,这就说明当第 k k k次的测量误差远大于第 k − 1 k-1 k−1次的估计误差时,估计值就会更趋向于第 k − 1 k-1 k−1次的估计值。
接下来我们看一个实际的例子,给出如下表所示的测量数据。因为光学测距仪本身就有误差,所以每次测量的结果也会不尽相同。由于我们使用同一个光学测距仪,其测量误差固定为 e m e a s u r e m e n t = 2 m e_{measurement} = 2\text{m} emeasurement=2m,这个值一般由传感器厂商提供。
| 测量次数 | 测量值 |
|---|---|
| z 1 z_1 z1 | 101m |
| z 2 z_2 z2 | 105m |
| z 3 z_3 z3 | 98m |
一个非常简单的用卡尔曼滤波解决这个问题的步骤:
- 计算卡尔曼增益: K k = e e s t i m a t e k − 1 e e s t i m a t e k − 1 + e m e a s u r e m e n t k \mathbf{K}_k = \frac{e_{estimate_{k-1}}}{e_{estimate_{k-1}} + e_{measurement_{k}}} Kk=eestimatek−1+emeasurementkeestimatek−1
- 计算第k次的估计值: z ^ k = z ^ k − 1 + K k ( z k − z ^ k − 1 ) \hat{z}_k = \hat{z}_{k-1} + \mathbf{K}_k(z_{k} - \hat{z}_{k-1}) z^k=z^k−1+Kk(zk−z^k−1)
- 更新估计误差: e e s t i m a t e k = ( 1 − K k ) e e s t i m a t e k − 1 e_{estimate_k} = (1 - \mathbf{K}_k)e_{estimate_{k-1}} eestimatek=(1−Kk)eestimatek−1(此公式后面给出推导过程)
由于卡尔曼滤波是通过递归的方式去估计一个非常接近真实值的估计值,因此开始的时候需要提供一个初始估计值 x ^ 0 = 95 \hat{x}_{0} = 95 x^0=95和初始估计值的误差 e e s t i m a t e 0 = 5 e_{estimate_0} = 5 eestimate0=5。
| k k k | z k z_k zk | e m e a s u r e m e n t k e_{measurement_k} emeasurementk | K k K_k Kk | z ^ k \hat{z}_k z^k | e e s t i m e a t e k e_{estimeate_k} eestimeatek |
|---|---|---|---|---|---|
| 0 | 100.00 | 5 | |||
| 1 | 103 | 2 | 0.71 | 102.13 | 1.45 |
| 2 | 101 | 2 | 0.42 | 101.65 | 0.84 |
| 3 | 98 | 2 | 0.3 | 100.56 | 0.59 |
- k = 1 时
a. K 1 = e e s t i m a t e 0 e e s t i m a t e 0 + e m e a s u r e m e n t 1 = 5 5 + 2 = 0.71 \mathbf{K}_1 = \frac{e_{estimate_{0}}}{e_{estimate_{0}} + e_{measurement_{1}}} = \frac{5}{5 + 2} = 0.71 K1=eestimate0+emeasurement1eestimate0=5+25=0.71
b. z ^ 1 = z ^ 0 + K k ( z 1 − z ^ 0 ) = 100 + 0.71 ∗ ( 103 − 100 ) = 102.13 \hat{z}_1 = \hat{z}_{0} + \mathbf{K}_k(z_{1} - \hat{z}_{0}) = 100 + 0.71 * (103 - 100) = 102.13 z^1=z^0+Kk(z1−z^0)=100+0.71∗(103−100)=102.13
c. e e s t i m a t e 1 = ( 1 − K 1 ) e e s t i m a t e 0 = ( 1 − 0.71 ) ∗ 5 = 1.45 e_{estimate_1} = (1 - \mathbf{K}_1)e_{estimate_{0}} = (1 - 0.71) * 5 = 1.45 eestimate1=(1−K1)eestimate0=(1−0.71)∗5=1.45 - k = 2 时
a. K 2 = e e s t i m a t e 1 e e s t i m a t e 1 + e m e a s u r e m e n t 2 = 1.45 1.45 + 2 = 0.42 \mathbf{K}_2 = \frac{e_{estimate_{1}}}{e_{estimate_{1}} + e_{measurement_{2}}} = \frac{1.45}{1.45 + 2} = 0.42 K2=eestimate1+emeasurement2eestimate1=1.45+21.45=0.42
b. z ^ 2 = z ^ 1 + K k ( z 2 − z ^ 1 ) = 102.13 + 0.42 ∗ ( 101 − 102.13 ) = 101.65 \hat{z}_2 = \hat{z}_{1} + \mathbf{K}_k(z_{2} - \hat{z}_{1}) = 102.13 + 0.42 * (101 - 102.13) = 101.65 z^2=z^1+Kk(z2−z^1)=102.13+0.42∗(101−102.13)=101.65
c. e e s t i m a t e 2 = ( 1 − K 2 ) e e s t i m a t e 1 = ( 1 − 0.42 ) ∗ 1.45 = 0.84 e_{estimate_2} = (1 - \mathbf{K}_2)e_{estimate_{1}} = (1 - 0.42) * 1.45 = 0.84 eestimate2=(1−K2)eestimate1=(1−0.42)∗1.45=0.84 - k = 3 时
a. K 3 = e e s t i m a t e 2 e e s t i m a t e 2 + e m e a s u r e m e n t 3 = 0.84 0.84 + 2 = 0.3 \mathbf{K}_3 = \frac{e_{estimate_{2}}}{e_{estimate_{2}} + e_{measurement_{3}}} = \frac{0.84}{0.84 + 2} = 0.3 K3=eestimate2+emeasurement3eestimate2=0.84+20.84=0.3
b. z ^ 3 = z ^ 2 + K k ( z 3 − z ^ 2 ) = 101.65 + 0.3 ∗ ( 98 − 101.65 ) = 100.56 \hat{z}_3 = \hat{z}_{2} + \mathbf{K}_k(z_{3} - \hat{z}_{2}) = 101.65 + 0.3 * (98 - 101.65) = 100.56 z^3=z^2+Kk(z3−z^2)=101.65+0.3∗(98−101.65)=100.56
c. e e s t i m a t e 3 = ( 1 − K 3 ) e e s t i m a t e 2 = ( 1 − 0.3 ) ∗ 0.84 = 0.59 e_{estimate_3} = (1 - \mathbf{K}_3)e_{estimate_{2}} = (1 - 0.3) * 0.84 = 0.59 eestimate3=(1−K3)eestimate2=(1−0.3)∗0.84=0.59
可以发现,虽然测量值 z k z_k zk是波动的,但是估计值 z ^ k \hat{z}_k z^k逐渐收敛,经过多步迭代之后,估计值会越来越趋向于某一个值,我们就认为这个收敛的估计值跟真实值是比较接近的。这就是卡尔曼滤波的递归思想,随着测量数据的越来越多,更新的估计值也越来越靠近真实值。
数学基础
卡尔曼滤波的公式推导需要一定的数学基础,本节主要讨论三个问题:数据融合、协方差矩阵和状态方程。
数据融合
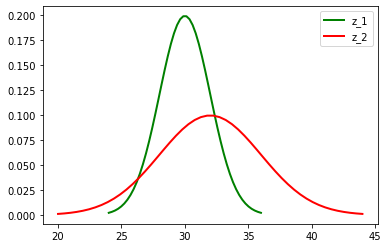
上面的最小例子中,我们通过光学测距仪多次测量取均值的方式得到了一个最优估计值,那么如果我们有多个光学测距仪,就可以将多个传感器的测量值融合起来。假如用两个光学测距仪进行测量,分别测出 z 1 = 30 m z_1 = 30 m z1=30m、 z 2 = 32 m z_2 = 32m z2=32m,两个传感器都有测量误差,并且误差服从正态分布,标准差 σ 1 2 = 2 m \sigma_1^2 = 2m σ12=2m、 σ 2 2 = 4 m \sigma_2^2 = 4m σ22=4m。
表现在图像上如下图所示:
import math
import numpy as np
import matplotlib.pyplot as plt
def normal_distribution(u, sig):
x = np.linspace(u - 3 * sig, u + 3 * sig, 50)
y = np.exp(-(x - u) ** 2 / (2 * sig ** 2)) / (math.sqrt(2 * math.pi) * sig)
return x, y
import math
import numpy as np
import matplotlib.pyplot as plt
def normal_distribution(u, sig):
x = np.linspace(u - 3 * sig, u + 3 * sig, 50)
y = np.exp(-(x - u) ** 2 / (2 * sig ** 2)) / (math.sqrt(2 * math.pi) * sig)
return x, y
u1, sig1 = 30, 2
u2, sig2 = 32, 4
x1, y1 = normal_distribution(u1, sig1)
x2, y2 = normal_distribution(u2, sig2)
plt.plot(x1, y1, "g", linewidth=2, label="z_1")
plt.plot(x2, y2, "r", linewidth=2, label="z_2")
plt.legend()
plt.show()
有了这两个结果之后,如果想要估计一个更加准确的值,自然而然的可以想到取平均,但是因为第一个传感器的误差更小一些,因此应该用加权平均,让结果更偏向第一个结果。
观察前面计算估计值的公式: z ^ k = z ^ k − 1 + K k ( z k − z ^ k − 1 ) \hat{z}_k = \hat{z}_{k-1} + \mathbf{K}_k(z_{k} - \hat{z}_{k-1}) z^k=z^k−1+Kk(zk−z^k−1),其实 z ^ k \hat{z}_k z^k和 z ^ k − 1 \hat{z}_{k-1} z^k−1不仅可以来自同一传感器不同时间的测量值,也可以来自不同传感器的测量值,即 z ^ = z 1 + k ( z 2 − z 1 ) \hat{z} = z_{1} + k(z_{2} - z_{1}) z^=z1+k(z2−z1)。此时我们的目标就变成了求解 k k k使得估计值 z ^ \hat{z} z^的标准差最小,也就是方差最小。
σ
z
2
=
V
a
r
(
z
1
+
k
(
z
2
−
z
1
)
)
=
V
a
r
(
z
1
−
k
z
1
+
k
z
2
)
=
V
a
r
(
(
1
−
k
)
z
1
+
k
z
2
)
=
V
a
r
(
(
1
−
k
)
z
1
)
+
V
a
r
(
k
z
2
)
=
(
1
−
k
)
2
V
a
r
(
z
1
)
+
k
2
V
a
r
(
z
2
)
=
(
1
−
k
)
2
σ
1
2
+
k
2
σ
2
2
\begin{aligned} \sigma_{z}^{2} &= \mathrm{Var}(z_{1}+k(z_{2}-z_{1})) = \mathrm{Var}(z_{1}-k z_{1}+k z_{2}) \\ & = \mathrm{Var}((1-k) z_{1}+k z_{2}) = \mathrm{Var}((1-k) z_{1}) + \mathrm{Var}(k z_{2}) \\ & = (1-k)^2\mathrm{Var}(z_{1}) + k^{2}\mathrm{Var}(z_{2}) = (1-k)^2\sigma_1^2 + k^{2}\sigma_2^2 \\ \end{aligned}
σz2=Var(z1+k(z2−z1))=Var(z1−kz1+kz2)=Var((1−k)z1+kz2)=Var((1−k)z1)+Var(kz2)=(1−k)2Var(z1)+k2Var(z2)=(1−k)2σ12+k2σ22
d
σ
z
2
d
k
=
−
2
(
1
−
k
)
σ
1
2
+
2
k
σ
2
2
=
0
⇒
k
=
σ
1
2
σ
1
2
+
σ
2
2
\frac{d \sigma_{z}^{2}}{d k} = -2(1 - k)\sigma_1^2 + 2k\sigma_2^2 = 0 \Rightarrow k = \frac{\sigma_1^2}{\sigma_1^2 + \sigma_2^2}
dkdσz2=−2(1−k)σ12+2kσ22=0⇒k=σ12+σ22σ12
然后我们把 σ 1 \sigma_1 σ1和 σ 2 \sigma_2 σ2带入进去即可计算出 k = 2 2 2 2 + 4 2 = 0.2 k = \frac{2^2}{2^2 + 4^2} = 0.2 k=22+4222=0.2,进而计算出 z ^ = z 1 + 0.2 ( z 2 − z 1 ) = 30 + 0.2 ∗ ( 32 − 30 ) = 30.4 \hat{z} = z_{1} + 0.2(z_{2} - z_{1}) = 30 + 0.2 * (32 - 30) = 30.4 z^=z1+0.2(z2−z1)=30+0.2∗(32−30)=30.4,也就是说,根据两个传感器的测量值和它们相应的误差,可以得出最优的估计值为30.4米,此时的方差为 σ z 2 = ( 1 − 0.2 ) 2 ∗ 2 2 + 0. 2 2 ∗ 4 2 = 3.2 \sigma_z^2 = (1 - 0.2)^2 * 2 ^2 + 0.2^2 * 4^2 = 3.2 σz2=(1−0.2)2∗22+0.22∗42=3.2。
将两个测量值和计算出的最优估计值表现在图像上如下图所示:
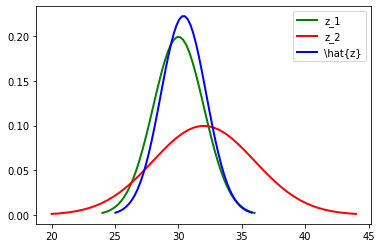
以上这个过程就是卡尔曼滤波的数据融合。
协方差矩阵
方差我们都知道,它是各个样本与样本均值的差的平方和的均值,用来度量一组数据的分散程度。那什么是协方差呢?可以通俗的理解为:两个变量在变化过程中是同方向变化还是反方向变化?同向或反向的程度如何?你变大,同时我也变大,说明两个变量是同向变化的,这时协方差就是正的,你变大,同时我变小,说明两个变量是反向变化的,这时协方差就是负的。从数值来看,协方差的数值越大,两个变量同向程度也就越大,反之亦然。协方差矩阵可以将方差和协方差在一个矩阵中表现出来,体现了变量间的联动关系。
那么怎么用数学语言来表述协方差呢?首先方差我们都比较熟悉,若样本 X : x 1 , x 2 , ⋯ , x m X: x_{1}, x_{2}, \cdots, x_{m} X:x1,x2,⋯,xm,期望为 μ \mu μ, 则方差为 V a r ( X ) = ∑ i = 1 m ∣ x i − μ ∣ 2 \mathrm{Var}(X) = \sum_{i=1}^{m} \left|x_{i} - \mu\right|^{2} Var(X)=∑i=1m∣xi−μ∣2。假设随机变量 x = [ x 1 x 2 ] \mathbf{x} = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} x=[x1x2]服从正态分布 x ∼ N ( 0 , σ 1 2 ) \mathbf{x} \sim N(0, \sigma_1^2) x∼N(0,σ12),根据方差公式 V a r ( x ) = E ( x 2 ) − [ E ( x ) ] 2 \mathrm{Var}(x) = \mathbb{E}(x^2) - [\mathbb{E}(x)]^2 Var(x)=E(x2)−[E(x)]2, σ 1 2 = E ( x 2 ) − [ E ( x ) ] 2 = t r [ x x T ] = x 1 2 + x 2 2 \sigma_1^2 = \mathbb{E}(\mathbf{x}^2) - [\mathbb{E}(\mathbf{x})]^2 = tr[\mathbf{x} \mathbf{x}^T] = x_1^2 + x_2^2 σ12=E(x2)−[E(x)]2=tr[xxT]=x12+x22。
类比一下,若样本 X : x 1 , x 2 , ⋯ , x m X: x_{1}, x_{2}, \cdots, x_{m} X:x1,x2,⋯,xm期望为 μ \mu μ,样本 Y : y 1 , y 2 , ⋯ , y m Y: y_{1}, y_{2}, \cdots, y_{m} Y:y1,y2,⋯,ym,期望为 ν \nu ν,那么 ( X , Y ) (X, Y) (X,Y)的取值可以为 ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x m , y m ) (x_{1}, y_{1}), (x_{2}, y_{2}), \cdots, (x_{m}, y_{m}) (x1,y1),(x2,y2),⋯,(xm,ym),则协方差为 C o v ( X , Y ) = ∑ i = 1 m ( x ‾ i − μ ) ( y ‾ i − ν ) \mathrm{Cov}(X, Y) = \sum\limits_{i=1}^{m}(\overline{x}_{i} - \mu)(\overline{y}_{i} - \nu) Cov(X,Y)=i=1∑m(xi−μ)(yi−ν)。假设有两个随机变量 x = [ x 1 x 2 ] , y = [ y 1 y 2 ] \mathbf{x} = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix}, \mathbf{y} = \begin{bmatrix} y_1 \\ y_2 \end{bmatrix} x=[x1x2],y=[y1y2],分别服从正态分布 x ∼ N ( 0 , σ 1 2 ) , y ∼ N ( 0 , σ 2 2 ) \mathbf{x} \sim N(0, \sigma_1^2), \mathbf{y} \sim N(0, \sigma_2^2) x∼N(0,σ12),y∼N(0,σ22),根据协方差公式 C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = E ( X Y ) − E ( X ) E ( Y ) \mathrm{Cov}(X, Y) = \mathbb{E}[(X - \mathbb{E}(X))(Y - \mathbb{E}(Y))] = \mathbb{E}(XY) - \mathbb{E}(X)\mathbb{E}(Y) Cov(X,Y)=E[(X−E(X))(Y−E(Y))]=E(XY)−E(X)E(Y),协方差矩阵为 C o v ( X , Y ) = E [ x y T ] = E [ x 1 y 1 x 1 y 2 x 2 y 1 x 2 y 2 ] \mathrm{Cov}(X, Y) = \mathbb{E}[\mathbf{xy^\mathbf{T}}] = \mathbb{E}\begin{bmatrix} x_1y_1 & x_1y_2\\ x_2y_1 & x_2y_2 \end{bmatrix} Cov(X,Y)=E[xyT]=E[x1y1x2y1x1y2x2y2]。
因此,方差其实是一种特殊的协方差,当 x = y x=y x=y时, C o v ( x , y ) = V a r ( x ) = V a r ( y ) \mathrm{Cov}(x,y) = \mathrm{Var}(x) = \mathrm{Var}(y) Cov(x,y)=Var(x)=Var(y),方差的值就是协方差矩阵的迹。数据集中两两变量的协方差就组成了协方差矩阵,其中的每个元素就是各个向量元素之间的协方差,其对角线上的值就是方差。
状态方程
我们将小车 t t t时刻的速度和距离表示为一个状态向量 x t = [ d t v t ] \mathbf{x}_t = \begin{bmatrix} d_t \\ v_t \end{bmatrix} xt=[dtvt],设 t t t时刻加速度传感器的输出为 a t a_t at。根据直线运动公式,小车在 t t t时刻的速度为 v t = v t − 1 + a t Δ t v_{t}=v_{t-1}+a_{t} \Delta t vt=vt−1+atΔt,距离为 d t = d t − 1 + v t − 1 Δ t + 1 2 a t Δ t 2 d_{t}=d_{t-1}+v_{t-1} \Delta t+\frac{1}{2} a_{t} \Delta t^{2} dt=dt−1+vt−1Δt+21atΔt2,将其整理为矩阵相乘的形式: x ^ t = [ d t v t ] = [ 1 Δ t 0 1 ] [ d t − 1 v t − 1 ] + [ Δ t 2 2 Δ t ] a t \mathbf{\hat{x}}_{t}=\left[\begin{array}{l} d_{t} \\ v_{t} \end{array}\right]=\left[\begin{array}{rr} 1 & \Delta t \\ 0 & 1 \end{array}\right]\left[\begin{array}{l} d_{t-1} \\ v_{t-1} \end{array}\right]+\left[\begin{array}{c} \frac{\Delta t^{2}}{2} \\ \Delta t \end{array}\right] a_{t} x^t=[dtvt]=[10Δt1][dt−1vt−1]+[2Δt2Δt]at。当然,这是在理想状态下的期望值,实际的状态向量应该再加上一项随机噪声向量 w t − 1 \mathbf{w}_{t-1} wt−1,即 x t = [ 1 Δ t 0 1 ] [ d t − 1 v t − 1 ] + [ Δ t 2 2 Δ t ] a t + w t − 1 \mathbf{x}_{t}=\left[\begin{array}{rr}1 & \Delta t \\0 & 1\end{array}\right]\left[\begin{array}{l}d_{t-1} \\v_{t-1}\end{array}\right]+\left[\begin{array}{c}\frac{\Delta t^{2}}{2} \\\Delta t\end{array}\right] a_{t}+ \mathbf{w}_{t - 1} xt=[10Δt1][dt−1vt−1]+[2Δt2Δt]at+wt−1,此时我们得到的方程即为卡尔曼滤波算法中状态方程的特殊形式。
卡尔曼滤波算法假定系统在某一时刻的状态可以由上一时刻的状态根据一个线性方程变化而来,即状态方程:
x
t
=
A
x
t
−
1
+
B
u
t
+
w
t
−
1
\mathbf{x}_{t} =\mathbf{A} \mathbf{x}_{t-1}+\mathbf{B} \mathbf{u}_{t}+\mathbf{w}_{t-1}
xt=Axt−1+But+wt−1
其中:
- x t \mathbf{x}_t xt: t t t时刻系统的状态向量,维度为 (n, 1)
- A \mathbf{A} A:状态转移矩阵,维度为 (n, n)
- B \mathbf{B} B:状态控制矩阵,维度为 (n, m)
- u t \mathbf{u}_t ut: t t t时刻系统的输入向量,维度为 (m, 1)
- w t − 1 \mathbf{w}_{t-1} wt−1: t − 1 t - 1 t−1时刻系统的过程噪声(Process Noise)向量,维度为 (n, 1) ,一般服从正态分布,均值为0,协方差矩阵为 Q t − 1 \mathbf{Q}_{t - 1} Qt−1,维度为 (n, n)
由于噪声是均值为0的正态噪声,那么上述状态方程的期望(最大概率对应的值)是
x
^
t
−
=
A
x
^
t
−
1
+
+
B
u
t
\hat{\mathbf{x}}_{t}^{-}=\mathbf{A} \hat{\mathbf{x}}_{t-1}^{+}+\mathbf{B} \mathbf{u}_{t}
x^t−=Ax^t−1++But
其中:
- 上标^表示该值为期望值
- 角标-表示更新前的状态
- 角标+表示更新后的状态
上式表示,当前时刻对状态向量的预测可以从上一时刻输出的系统状态向量乘以状态转换矩阵加上此时的控制输入向量乘以控制矩阵得出。
光学测距仪得到的测量值是光从原点移动到小车的时间,设光速为 c c c,那么测量值 z t = d t c z_t = \frac{d_t}{c} zt=cdt,将其写为与系统状态向量矩阵相乘的形式 z ^ t = [ 1 c , 0 ] [ d t v t ] \mathbf{\hat{z}}_t = \begin{bmatrix} \frac{1}{c},& 0 \end{bmatrix} \begin{bmatrix} d_t \\ v_t \end{bmatrix} z^t=[c1,0][dtvt]。当然,这也是在理想状态下的期望值,实际的测量向量应该再加上一项测量噪声向量 v t \mathbf{v}_{t} vt,即 z t = [ 1 c , 0 ] [ d t v t ] + v t \mathbf{z_t} = \begin{bmatrix} \frac{1}{c},& 0 \end{bmatrix} \begin{bmatrix} d_t \\ v_t \end{bmatrix} + \mathbf{v}_{t} zt=[c1,0][dtvt]+vt。
接下来我们对测量向量状态方程进行抽象: z t = H x t + v t \mathbf{z}_{t}=\mathbf{H} \mathbf{x}_{t}+\mathbf{v}_{t} zt=Hxt+vt,其中:
- z t \mathbf{z}_{t} zt:测量向量,维度为 (l, 1)
- H \mathbf{H} H:测量转移矩阵,维度为 (l, n),作用就是将系统状态向量映射到测试向量
- v t \mathbf{v}_t vt:测量噪声向量,维度为 (l, 1),其协方差矩阵为 R t \mathbf{R}_t Rt
我们最终的目标其实是 x t \mathbf{x}_t xt,因此也可以将测量向量状态方程转换一下: x ^ t = H − 1 z ^ t \hat{\mathbf{x}}_t = \mathbf{H}^{-1}\hat{\mathbf{z}}_t x^t=H−1z^t,后面也会用到这种形式。
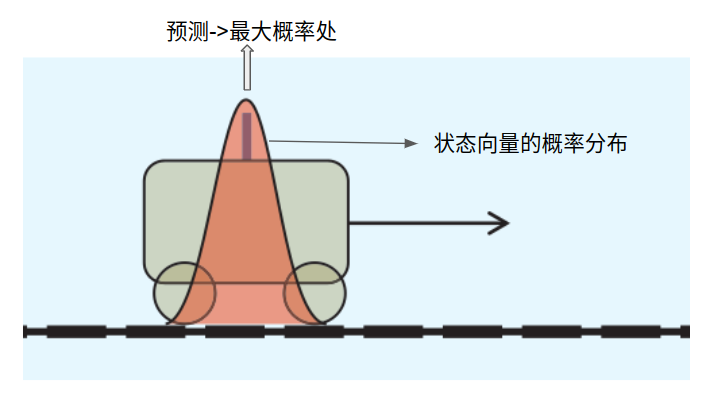
由于我们假设噪声服从正态分布,正态分布的均值为0,也就是值为0对应的概率最大。换句话说,状态向量和测量向量实际上是一个随机向量,等于什么值是一个概率问题。如下图,小车在时刻
t
t
t的位置是一个满足图示的概率分布。
最后,我们就得出了卡尔曼滤波算法中重要的两个状态方程:
x
t
=
A
x
t
−
1
+
B
u
t
−
1
+
w
t
−
1
z
t
=
H
x
t
+
v
t
\begin{array}{l} \mathbf{x}_{t}=\mathbf{A} \mathbf{x}_{t-1}+\mathbf{B} \mathbf{u}_{t-1}+\mathbf{w}_{t-1} \\ \mathbf{z}_{t}=\mathbf{H} \mathbf{x}_{t}+\mathbf{v}_{t} \end{array}
xt=Axt−1+But−1+wt−1zt=Hxt+vt。
公式推导
在开始正式推导卡尔曼滤波的公式之前,先做一个符号说明,不需要完全记住,只需在后面推导的过程中如果发生混淆随时查阅即可。
x t \mathbf{x}_t xt:t 时刻的状态向量
x ^ t − \mathbf{\hat{x}}_t^- x^t−:t 时刻预测的状态向量的先验估计(未优化)
x ^ t + \mathbf{\hat{x}}_t^+ x^t+:t 时刻预测的状态向量的后验估计(优化后)
z t \mathbf{z}_t zt:t 时刻的测量向量
z ^ t − \mathbf{\hat{z}}_t^- z^t−:t 时刻预测的测量向量的先验估计(未优化)
z ^ t + \mathbf{\hat{z}}_t^+ z^t+:t 时刻预测的测量向量的后验估计(优化后)
w t \mathbf{w}_t wt:t 时刻的过程噪声,服从正态分布
v t \mathbf{v}_t vt:t 时刻的测量噪声,服从正态分布
u t \mathbf{u}_t ut:t 时刻外界对系统的输入
A \mathbf{A} A:状态转移矩阵
B \mathbf{B} B:输入控制矩阵
H \mathbf{H} H:测量矩阵
Q \mathbf{Q} Q:过程噪声的协方差矩阵
R \mathbf{R} R:测量噪声的协方差矩阵
P \mathbf{P} P:误差的协方差矩阵
K \mathbf{K} K:卡尔曼增益
根据卡尔曼滤波的两个状态方程可以得到两个状态向量的期望表达式: x ^ t − = A x ^ t − 1 + + B u t x ^ t = H − 1 z ^ t \begin{array}{l} \hat{\mathbf{x}}_{t}^{-}=\mathbf{A} \hat{\mathbf{x}}_{t-1}^{+}+\mathbf{B} \mathbf{u}_{t} \\ \hat{\mathbf{x}}_t = \mathbf{H}^{-1}\hat{\mathbf{z}}_t \end{array} x^t−=Ax^t−1++Butx^t=H−1z^t,然后根据前面得到的数据融合的公式: z ^ k = z ^ k − 1 + K ( z k − z ^ k − 1 ) \hat{z}_k = \hat{z}_{k-1} + \mathbf{K}(z_{k} - \hat{z}_{k-1}) z^k=z^k−1+K(zk−z^k−1),扩展为将两个状态向量进行融合 x ^ t + = x ^ t − + G ( H − 1 z t − x ^ t − ) \hat{\mathbf{x}}_{t}^{+} = \hat{\mathbf{x}}_{t}^{-} + \mathbf{G}(\mathbf{H}^{-1}\mathbf{z}_t - \hat{\mathbf{x}}_{t}^{-}) x^t+=x^t−+G(H−1zt−x^t−),然后令 G = K t H \mathbf{G} = \mathbf{K}_t\mathbf{H} G=KtH,则 x ^ t + = x ^ t − + K t ( z t − H x ^ t − ) \hat{\mathbf{x}}_{t}^{+} = \hat{\mathbf{x}}_{t}^{-} + \mathbf{K}_t(\mathbf{z}_t - \mathbf{H}\hat{\mathbf{x}}_{t}^{-}) x^t+=x^t−+Kt(zt−Hx^t−),这个就是卡尔曼滤波的核心公式。我们的目标就是找到一个合适的 K t \mathbf{K}_t Kt使得估计值 x ^ t + \hat{\mathbf{x}}_{t}^{+} x^t+的误差最小。
状态预测对系统的状态向量进行建模,由于传感器的输出是带噪声的,反映到对状态向量的估计就是状态预测方程中的 w t \mathbf{w}_t wt噪声项,我们假设噪声服从正态分布,即 P ( w t ) ∼ N ( 0 , Q t ) P(\mathbf{w}_t) \sim N(0, \mathbf{Q}_t) P(wt)∼N(0,Qt),其中 Q t = E [ w t w t T ] \mathbf{Q}_t = \mathbb{E}[\mathbf{w}_t\mathbf{w}_t^T] Qt=E[wtwtT]。
在实际建模的过程中,并不能直接获取到噪声,但是我们希望通过滤波让噪声造成的误差越小越好。可以用 t t t时刻实际的状态向量 x t \mathbf{x}_t xt减去 t t t时刻预测的状态向量 x ^ t − \hat{\mathbf{x}}_{t}^{-} x^t−,即误差 e t = x t − x ^ t e_{t} = \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} et=xt−x^t。由于噪声服从正态分布,因此误差也服从正态分布,即 P ( e t ) ∼ N ( 0 , P t ) P(e_t) \sim N(0, \mathbf{P}_t) P(et)∼N(0,Pt),其中 P t \mathbf{P}_t Pt为误差的协方差矩阵。
P t = E [ e t e t T ] = E [ ( x t − x ^ t ) ( x t − x ^ t ) T ] \mathbf{P}_{t} = \mathbb{E}[e_{t}e_{t}^{T}] = \mathbb{E}\left[(\mathbf{x}_t - \mathbf{\hat{x}}_{t})(\mathbf{x}_t - \mathbf{\hat{x}}_{t})^{T}\right] Pt=E[etetT]=E[(xt−x^t)(xt−x^t)T]
其中 x t − x ^ t = x t − ( x ^ t − + K t ( z t − H x ^ t − ) ) = x t − x ^ t − − K t z t + K t H x ^ t − \begin{aligned} \mathbf{x}_t - \mathbf{\hat{x}}_{t} & = \mathbf{x}_t - \left(\hat{\mathbf{x}}_{t}^{-} + \mathbf{K}_t(\mathbf{z}_t - \mathbf{H}\hat{\mathbf{x}}_{t}^{-})\right) \\ & = \mathbf{x}_t - \hat{\mathbf{x}}_{t}^{-} - \mathbf{K}_t\mathbf{z}_t + \mathbf{K}_t\mathbf{H}\hat{\mathbf{x}}_{t}^{-} \end{aligned} xt−x^t=xt−(x^t−+Kt(zt−Hx^t−))=xt−x^t−−Ktzt+KtHx^t−
又 z t = H x t + v t \mathbf{z}_{t}=\mathbf{H} \mathbf{x}_{t}+\mathbf{v}_{t} zt=Hxt+vt
所以 x t − x ^ t = x t − x ^ t − − K t ( H x t + v t ) + K t H x ^ t − = ( x t − x ^ t − ) − K t H x t + K t H x ^ t − − K t v t = ( E − K t H ) ( x t − x ^ t − ) − K t v t \begin{aligned} \mathbf{x}_{t} - \mathbf{\hat{x}}_{t} & = \mathbf{x}_{t} - \hat{\mathbf{x}}_{t}^{-} - \mathbf{K}_{t}(\mathbf{H}\mathbf{x}_{t} + \mathbf{v}_{t}) + \mathbf{K}_t\mathbf{H}\hat{\mathbf{x}}_{t}^{-} \\ & = (\mathbf{x}_t - \hat{\mathbf{x}}_{t}^{-}) - \mathbf{K}_t\mathbf{H}\mathbf{x}_{t} + \mathbf{K}_t\mathbf{H}\hat{\mathbf{x}}_{t}^{-} - \mathbf{K}_t\mathbf{v}_{t} \\ & = (\mathbf{E} - \mathbf{K}_t\mathbf{H})(\mathbf{x}_t - \hat{\mathbf{x}}_{t}^{-}) - \mathbf{K}_t\mathbf{v}_{t} \end{aligned} xt−x^t=xt−x^t−−Kt(Hxt+vt)+KtHx^t−=(xt−x^t−)−KtHxt+KtHx^t−−Ktvt=(E−KtH)(xt−x^t−)−Ktvt
误差
e
t
=
x
t
−
x
^
t
e_{t} = \mathbf{x}_{t}-\hat{\mathbf{x}}_{t}
et=xt−x^t,所以先验误差即为
e
t
−
=
x
t
−
x
^
t
−
e_t^- = \mathbf{x}_{t}-\hat{\mathbf{x}}_{t}^-
et−=xt−x^t−,那么误差的方差:
P
t
=
E
[
(
x
t
−
x
^
t
)
(
x
t
−
x
^
t
)
T
]
=
E
[
(
(
E
−
K
t
H
)
e
t
−
−
K
t
v
t
)
(
(
E
−
K
t
H
)
e
t
−
−
K
t
v
t
)
T
]
=
E
[
(
(
E
−
K
t
H
)
e
t
−
−
K
t
v
t
)
(
e
t
−
T
(
E
−
K
t
H
)
T
−
v
t
T
K
t
T
)
]
=
E
[
(
E
−
K
t
H
)
e
t
−
e
t
−
T
(
E
−
K
t
H
)
T
−
(
E
−
K
t
H
)
e
t
−
v
t
T
K
t
T
−
K
t
v
t
e
t
−
T
(
E
−
K
t
H
)
T
+
K
t
v
t
v
t
T
K
t
T
]
\begin{aligned} \mathbf{P}_{t} & = \mathbb{E}\left[(\mathbf{x}_t - \mathbf{\hat{x}}_t)(\mathbf{x}_t - \mathbf{\hat{x}}_t)^{\mathbf{T}}\right] \\ & = \mathbb{E}\left[ \left( (\mathbf{E} - \mathbf{K}_t\mathbf{H})e_t^- - \mathbf{K}_t\mathbf{v}_{t} \right)\left( (\mathbf{E} - \mathbf{K}_t\mathbf{H})e_t^- - \mathbf{K}_t\mathbf{v}_{t} \right)^{\mathbf{T}} \right] \\ & = \mathbb{E}\left[ \left( (\mathbf{E} - \mathbf{K}_t\mathbf{H})e_t^- - \mathbf{K}_t\mathbf{v}_{t} \right)\left( {e_t^-}^{\mathbf{T}}(\mathbf{E} - \mathbf{K}_t\mathbf{H})^{\mathbf{T}} - \mathbf{v}_{t}^{\mathbf{T}}\mathbf{K}_t^{\mathbf{T}} \right) \right] \\ & = \mathbb{E}\left[ (\mathbf{E} - \mathbf{K}_t\mathbf{H})e_t^- {e_t^-}^{\mathbf{T}}(\mathbf{E} - \mathbf{K}_t\mathbf{H})^{\mathbf{T}} - (\mathbf{E} - \mathbf{K}_t\mathbf{H})e_t^-\mathbf{v}_{t}^{\mathbf{T}}\mathbf{K}_t^{\mathbf{T}} - \mathbf{K}_t\mathbf{v}_{t}{e_t^-}^{\mathbf{T}}(\mathbf{E} - \mathbf{K}_t\mathbf{H})^{\mathbf{T}} + \mathbf{K}_t\mathbf{v}_{t}\mathbf{v}_{t}^{\mathbf{T}}\mathbf{K}_t^{\mathbf{T}} \right] \end{aligned}
Pt=E[(xt−x^t)(xt−x^t)T]=E[((E−KtH)et−−Ktvt)((E−KtH)et−−Ktvt)T]=E[((E−KtH)et−−Ktvt)(et−T(E−KtH)T−vtTKtT)]=E[(E−KtH)et−et−T(E−KtH)T−(E−KtH)et−vtTKtT−Ktvtet−T(E−KtH)T+KtvtvtTKtT]
由于先验误差 e t − e_t^- et−和测量噪声 v t \mathbf{v}_t vt是相互独立的,两个相互独立的随机变量的乘积的期望等于两个随机变量期望的乘积,即 E ( x 1 ⋅ x 2 ) = E ( x 1 ) ⋅ E ( x 2 ) \mathbb{E}\left(\mathrm{x}_{1} \cdot \mathrm{x}_{2}\right)=\mathbb{E}\left(\mathrm{x}_{1}\right) \cdot \mathbb{E}\left(\mathrm{x}_{2}\right) E(x1⋅x2)=E(x1)⋅E(x2),而测量噪声向量的期望为0,所以 E [ ( E − K t H ) e t − v t T K t T ] = E [ K t v t e t − T ( E − K t H ) T ] = 0 \mathbb{E} \left[ (\mathbf{E} - \mathbf{K}_t\mathbf{H})e_t^-\mathbf{v}_{t}^{\mathrm{T}}\mathbf{K_t}^{\mathrm{T}} \right] = \mathbb{E} \left[ \mathbf{K}_t\mathbf{v}_{t}{e_t^-}^{\mathrm{T}}(\mathbf{E} - \mathbf{K}_t\mathbf{H})^{\mathrm{T}} \right] = 0 E[(E−KtH)et−vtTKtT]=E[Ktvtet−T(E−KtH)T]=0。
误差的协方差矩阵简化为: P t = E [ ( E − K t H ) e t − e t − T ( E − K t H ) T + K t v t v t T K t T ] = ( E − K t H ) E [ e t − e t − T ] ( E − K t H ) T + K t E [ v t v t T ] K t T = ( E − K t H ) P t − ( E − H T K t T ) + K t R K t T \begin{aligned} \mathbf{P}_{t} & = \mathbb{E}\left[ (\mathbf{E} - \mathbf{K}_t\mathbf{H})e_t^- {e_t^-}^{\mathbf{T}}(\mathbf{E} - \mathbf{K}_t\mathbf{H})^{\mathbf{T}} + \mathbf{K}_t\mathbf{v}_{t}\mathbf{v}_{t}^{\mathrm{T}}\mathbf{K}_t^{\mathrm{T}} \right] \\ & = (\mathbf{E} - \mathbf{K}_t\mathbf{H}) \ \mathbb{E} \left[ e_t^- {e_t^-}^{\mathbf{T}} \right](\mathbf{E} - \mathbf{K}_t\mathbf{H})^{\mathrm{T}} + \mathbf{K}_t \ \mathbb{E} \left[ \mathbf{v}_{t}\mathbf{v}_{t}^{\mathrm{T}} \right] \mathbf{K}_t^{\mathrm{T}} \\ & = (\mathbf{E} - \mathbf{K}_t\mathbf{H}) \ \mathbf{P}_{t}^{-} (\mathbf{E} - \mathbf{H}^{\mathrm{T}}\mathbf{K}_t^{\mathrm{T}}) + \mathbf{K}_t \ \mathbf{R} \mathbf{K}_t^{\mathrm{T}} \\ \end{aligned} Pt=E[(E−KtH)et−et−T(E−KtH)T+KtvtvtTKtT]=(E−KtH) E[et−et−T](E−KtH)T+Kt E[vtvtT]KtT=(E−KtH) Pt−(E−HTKtT)+Kt RKtT,回过头看,我们的目标是希望找到 K t \mathbf{K}_{t} Kt使误差 e t e_{t} et的方差越小越好,而方差其实就是协方差矩阵的迹,因此可以用 t r ( P t ) tr(\mathbf{P}_{t}) tr(Pt)对 K t \mathbf{K}_{t} Kt求导,令导数值等于零,就可以找到 t r ( P t ) tr(\mathbf{P}_{t}) tr(Pt)的极值点了,即方差最小的点。
为了方便计算,将 P t \mathbf{P}_{t} Pt的表达式展开然后求迹: t r ( P t ) = t r ( P t − ) − 2 t r ( K t H P t − ) + t r ( K t H P t − H T K t T ) + t r ( K t R K t T ) tr(\mathbf{P}_{t}) = tr(\mathbf{P}_{t}^{-}) - 2tr(\mathbf{K}_t\mathbf{H}\mathbf{P}_{t}^{-}) + tr(\mathbf{K}_t\mathbf{H}\mathbf{P}_{t}^{-}\mathbf{H}^{\mathbf{T}}\mathbf{K}_t^{\mathbf{T}}) + tr(\mathbf{K}_t \mathbf{R} \mathbf{K}_t^{\mathbf{T}}) tr(Pt)=tr(Pt−)−2tr(KtHPt−)+tr(KtHPt−HTKtT)+tr(KtRKtT),然后每一项分别对 K t \mathbf{K}_{t} Kt求导:
- d t r ( P t − ) d ( K t ) = 0 \frac{\mathrm{d} \ tr(\mathbf{P}_{t}^{-})}{\mathrm{d} (\mathbf{K}_{t})} = 0 d(Kt)d tr(Pt−)=0
- 根据矩阵求导公式 t r ( A B ) A = B T \frac{\mathrm{tr}(\mathbf{A} \mathbf{B})}{\mathbf{A}} = \mathbf{B}^{\mathrm{T}} Atr(AB)=BT, d t r ( K t H P t − ) d ( K t ) = ( H P t − ) T \frac{\mathrm{d} \ tr(\mathbf{K}_t\mathbf{H}\mathbf{P}_{t}^{-})}{\mathrm{d} (\mathbf{K}_{t})} = (\mathbf{H}\mathbf{P}_{t}^{-})^\mathrm{T} d(Kt)d tr(KtHPt−)=(HPt−)T
- 根据矩阵求导公式 t r ( A B A T ) A = 2 A B \frac{\mathrm{tr}(\mathbf{A} \mathbf{B} \mathbf{A}^{\mathrm{T}})}{\mathbf{A}} = 2\mathbf{A} \mathbf{B} Atr(ABAT)=2AB, d t r ( K t H P t − H T K t T ) d ( K t ) = 2 K t H P t − H T \frac{\mathrm{d} \ tr(\mathbf{K}_t\mathbf{H}\mathbf{P}_{t}^{-}\mathbf{H}^{\mathbf{T}}\mathbf{K}_t^{\mathbf{T}})}{\mathrm{d} (\mathbf{K}_{t})} = 2\mathbf{K}_t\mathbf{H}\mathbf{P}_{t}^{-}\mathbf{H}^{\mathbf{T}} d(Kt)d tr(KtHPt−HTKtT)=2KtHPt−HT
- 同上, d t r ( K t R K t T ) d ( K t ) = 2 K t R \frac{\mathrm{d} \ tr(\mathbf{K}_t \mathbf{R} \mathbf{K}_t^{\mathbf{T}})}{\mathrm{d} (\mathbf{K}_{t})} = 2\mathbf{K}_t \mathbf{R} d(Kt)d tr(KtRKtT)=2KtR
所以 d t r ( P t ) d ( K t ) = − 2 P t − H T + 2 K t H P t − H T + 2 K t R \frac{\mathrm{d} \ tr(\mathbf{P}_{t})}{\mathrm{d} (\mathbf{K}_{t})} = -2\mathbf{P}_{t}^{-}\mathbf{H}^\mathrm{T} + 2\mathbf{K}_t\mathbf{H}\mathbf{P}_{t}^{-}\mathbf{H}^{\mathbf{T}} + 2\mathbf{K}_t \mathbf{R} d(Kt)d tr(Pt)=−2Pt−HT+2KtHPt−HT+2KtR,令其等于零,可解出 K t = P t − H t T H t P t − H t T + R t \mathbf{K}_{t} = \frac{\mathbf{P}_{t}^{-} \mathbf{H}_{t}^{\mathrm{T}}}{\mathbf{H}_{t} \mathbf{P}_{t}^{-} \mathbf{H}_{t}^{\mathrm{T}} + \mathbf{R}_{t}} Kt=HtPt−HtT+RtPt−HtT,这也就是我们想求的卡尔曼增益,它可以让误差的方差取极小值。
H
\mathbf{H}
H是已知的测量矩阵,
R
\mathbf{R}
R是测量噪声向量的协方差矩阵,因此
K
\mathbf{K}
K的表达式中只有
P
−
\mathbf{P}^{-}
P−是未知的,根据定义
P
t
−
=
E
[
e
t
−
e
t
−
T
]
\mathbf{P}_{t}^{-} = \mathbb{E}[e_{t}^{-}{e_{t}^{-}}^{\mathrm{T}}]
Pt−=E[et−et−T],而
e
t
−
=
x
t
−
x
^
t
−
e_t^- = \mathbf{x}_{t}-\hat{\mathbf{x}}_{t}^-
et−=xt−x^t−,根据
x
t
=
A
x
t
−
1
+
B
u
t
−
1
+
w
t
−
1
x
^
t
−
=
A
x
^
t
−
1
+
+
B
u
t
−
1
\begin{matrix} \mathbf{x}_{t}=\mathbf{A} \mathbf{x}_{t-1}+\mathbf{B} \mathbf{u}_{t-1}+\mathbf{w}_{t-1} \\ \hat{\mathbf{x}}_{t}^{-}=\mathbf{A} \hat{\mathbf{x}}_{t-1}^{+}+\mathbf{B} \mathbf{u}_{t-1} \end{matrix}
xt=Axt−1+But−1+wt−1x^t−=Ax^t−1++But−1,得
e
t
−
=
A
(
x
t
−
1
−
x
^
t
−
1
+
)
+
w
t
−
1
e_t^- = \mathbf{A} (\mathbf{x}_{t-1} - \hat{\mathbf{x}}_{t-1}^{+}) + \mathbf{w}_{t-1}
et−=A(xt−1−x^t−1+)+wt−1,因此
P
t
−
=
E
[
e
t
−
e
t
−
T
]
=
E
[
(
A
e
t
−
1
+
w
t
−
1
)
(
e
t
−
1
T
A
T
+
w
t
−
1
T
)
]
=
E
[
A
e
t
−
1
e
t
−
1
T
A
T
+
A
e
t
−
1
w
t
−
1
T
+
w
t
−
1
e
t
−
1
T
A
T
+
w
t
−
1
w
t
−
1
T
]
=
E
[
A
e
t
−
1
e
t
−
1
T
A
T
]
+
E
[
A
e
t
−
1
w
t
−
1
T
]
+
E
[
w
t
−
1
e
t
−
1
T
A
T
]
+
E
[
w
t
−
1
w
t
−
1
T
]
\begin{aligned} \mathbf{P}_{t}^{-} & = \mathbb{E}[e_{t}^{-}{e_{t}^{-}}^{\mathrm{T}}] \\ & = \mathbb{E}\left[ \left( \mathbf{A} e_{t-1} + \mathbf{w}_{t-1} \right)\left(e_{t-1}^{\mathrm{T}}\mathbf{A}^{\mathrm{T}} + \mathbf{w}_{t-1}^{\mathrm{T}} \right)\right] \\ & = \mathbb{E}\left[ \mathbf{A} e_{t-1}e_{t-1}^{\mathrm{T}}\mathbf{A}^{\mathrm{T}} + \mathbf{A}e_{t-1}\mathbf{w}_{t-1}^{\mathrm{T}} + \mathbf{w}_{t-1} e_{t-1}^{\mathrm{T}}\mathbf{A}^{\mathrm{T}} + \mathbf{w}_{t-1}\mathbf{w}_{t-1}^{\mathrm{T}} \right] \\ & = \mathbb{E}\left[ \mathbf{A} e_{t-1}e_{t-1}^{\mathrm{T}}\mathbf{A}^{\mathrm{T}} \right ] + \mathbb{E}\left[\mathbf{A}e_{t-1}\mathbf{w}_{t-1}^{\mathrm{T}}\right] + \mathbb{E}\left[\mathbf{w}_{t-1} e_{t-1}^{\mathrm{T}}\mathbf{A}^{\mathrm{T}}\right] + \mathbb{E}\left[\mathbf{w}_{t-1}\mathbf{w}_{t-1}^{\mathrm{T}} \right] \end{aligned}
Pt−=E[et−et−T]=E[(Aet−1+wt−1)(et−1TAT+wt−1T)]=E[Aet−1et−1TAT+Aet−1wt−1T+wt−1et−1TAT+wt−1wt−1T]=E[Aet−1et−1TAT]+E[Aet−1wt−1T]+E[wt−1et−1TAT]+E[wt−1wt−1T]
注意 e t − = x t − x ^ t − x t = A x t − 1 + B u t − 1 + w t − 1 \begin{aligned} & e_t^- = \mathbf{x}_{t}-\hat{\mathbf{x}}_{t}^- \\ & \mathbf{x}_{t}=\mathbf{A} \mathbf{x}_{t-1}+\mathbf{B} \mathbf{u}_{t-1}+\mathbf{w}_{t-1} \end{aligned} et−=xt−x^t−xt=Axt−1+But−1+wt−1, w t − 1 \mathbf{w}_{t-1} wt−1作用与第 t t t次 x t \mathbf{x}_{t} xt,而 e t − 1 e_{t-1} et−1是第 t − 1 t-1 t−1次的误差,因此两个向量相互独立, E [ A e t − 1 w t − 1 T ] = E [ w t − 1 e t − 1 T A T ] = 0 \mathbb{E}\left[\mathbf{A}e_{t-1}\mathbf{w}_{t-1}^{\mathrm{T}}\right] = \mathbb{E}\left[\mathbf{w}_{t-1} e_{t-1}^{\mathrm{T}}\mathbf{A}^{\mathrm{T}}\right] = 0 E[Aet−1wt−1T]=E[wt−1et−1TAT]=0,最终简化为 P t − = A E [ e t − 1 e t − 1 T ] A T + E [ w t − 1 w t − 1 T ] = A t P t − 1 + A t T + Q t \mathbf{P}_{t}^{-} = \mathbf{A}\mathbb{E}\left[e_{t-1}e_{t-1}^{\mathrm{T}}\right]\mathbf{A}^{\mathrm{T}} + \mathbb{E}\left[\mathbf{w}_{t-1}\mathbf{w}_{t-1}^{\mathrm{T}} \right] = \mathbf{A}_{t} \mathbf{P}_{t-1}^{+} \mathbf{A}_{t}^{T} + \mathbf{Q}_{t} Pt−=AE[et−1et−1T]AT+E[wt−1wt−1T]=AtPt−1+AtT+Qt。
求出了先验估计
P
t
−
\mathbf{P}_{t}^{-}
Pt−,根据前面推导出的后验估计公式
P
t
=
(
E
−
K
t
H
)
P
t
−
(
E
−
H
T
K
t
T
)
+
K
t
R
K
t
T
\mathbf{P}_{t} = (\mathbf{E} - \mathbf{K}_t\mathbf{H}) \ \mathbf{P}_{t}^{-} (\mathbf{E} - \mathbf{H}^{\mathrm{T}}\mathbf{K}_t^{\mathrm{T}}) + \mathbf{K}_t \ \mathbf{R} \mathbf{K}_t^{\mathrm{T}}
Pt=(E−KtH) Pt−(E−HTKtT)+Kt RKtT,带入
K
t
\mathbf{K}_t
Kt,即可将后验估计公式简化为:
P
t
+
=
(
E
−
K
t
H
t
)
P
t
−
\mathbf{P}_{t}^{+}=(\mathbf{E} - \mathbf{K}_{t} \mathbf{H}_{t}) \mathbf{P}_{t}^{-}
Pt+=(E−KtHt)Pt−。
到此为止,卡尔曼滤波中所有的公式就已经推导完毕。
总结与练习
卡尔曼滤波给出了一种数据融合的方案,将以加速度传感器的输出建立的数学模型和光学测距仪的输出融合起来,取长补短,这样得出的结果才更加准确。那么具体怎么融合,卡尔曼滤波给出了步骤:首先通过数学模型预测,然后通过测量模型更新。所谓状态预测,就是前面提到的用数学模型根据加速度传感器的输出直接推导出小车此时的速度和距离,将其称为预测结果。所谓更新,就是先获取小车以外的传感器的测量结果,比如光学测距仪的结果,然后结合该测量结果对预测结果进行修正,因此也叫测量更新。
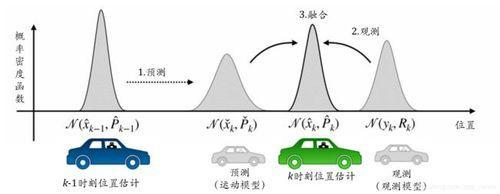
在自动驾驶中,我们并不知道自己的精确位置。卡尔曼滤波从
k
−
1
k - 1
k−1时刻的概率估计开始,通过里程计或IMU的输出建立数学模型预测
k
k
k时刻的状态,但由于传感器的精度、空气阻力和摩擦系数等不确定性因素,导致预测并不是很完美。然后通过GPS等传感器建立的测量模型更新
k
k
k时刻的车辆位置,虽然GPS的精度不够准确,但是卡尔曼滤波可以将所有可用的信息都结合起来,根据其本身的噪声分配一定的权重,就能得到一个比任何单个方案更好的结果,这就是卡尔曼滤波的作用。
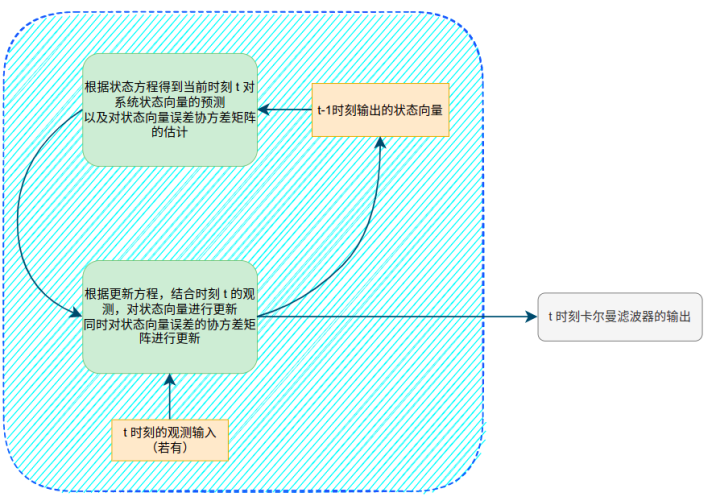
卡尔曼滤波的步骤
卡尔曼滤波包括下面5个步骤:
- (预测)根据 t − 1 t - 1 t−1时刻后验估计预测值 x ^ t − 1 + \mathbf{\hat{x}}_{t-1}^+ x^t−1+计算 t t t时刻先验估计预测值 x t − \mathbf{x}_t^- xt−,即 x ^ t − = A x ^ t − 1 + + B u t \hat{\mathbf{x}}_{t}^{-}=\mathbf{A} \mathbf{\hat{x}}_{t-1}^{+} + \mathbf{B}\mathbf{u}_{t} x^t−=Ax^t−1++But。
- (预测)根据 t − 1 t - 1 t−1时刻后验估计预测值的误差 P t − 1 + \mathbf{P}_{t-1}^{+} Pt−1+计算 t t t时刻先验估计预测值的误差 P t − \mathbf{P}_{t}^{-} Pt−,即 P t − = A P t − 1 + A T + Q \mathbf{P}_{t}^{-} = \mathbf{A} \mathbf{P}_{t-1}^{+} \mathbf{A}^{T} + \mathbf{Q} Pt−=APt−1+AT+Q。
- (更新)根据 t t t时刻先验估计预测值的误差 P t − \mathbf{P}_{t}^{-} Pt−和测量值的协方差矩阵 R t \mathbf{R}_t Rt计算卡尔曼增益,即 K t = P t − H T H P t − H T + R \mathbf{K}_{t} = \frac{\mathbf{P}_{t}^{-} \mathbf{H}^{\mathrm{T}}}{\mathbf{H} \mathbf{P}_{t}^{-} \mathbf{H}^{\mathrm{T}} + \mathbf{R}} Kt=HPt−HT+RPt−HT。
- (更新)根据 t t t时刻先验估计预测值 x t − \mathbf{x_t}^- xt−、测量值 z t \mathbf{z}_{t} zt和卡尔曼增益 K t \mathbf{K}_{t} Kt计算后验估计预测值 x ^ t + \mathbf{\hat{x}_{t}}^+ x^t+,即 x ^ t + = x ^ t − + K t ( z t − H x ^ t − ) \hat{\mathbf{x}}_{t}^{+}=\hat{\mathbf{x}}_{t}^{-} + \mathbf{K}_{t}\left(\mathbf{z}_{t}-\mathbf{H} \hat{\mathbf{x}}_{t}^{-}\right) x^t+=x^t−+Kt(zt−Hx^t−)。
- (更新)根据 t t t时刻先验估计预测值的误差协方差矩阵 P t − \mathbf{P}_{t}^{-} Pt−和卡尔曼增益 K t \mathbf{K}_{t} Kt计算后验估计预测值的误差协方差矩阵 P t + \mathbf{P}_{t}^{+} Pt+,即 P t + = ( E − K t H ) P t − \mathbf{P}_{t}^{+}=(\mathbf{E} - \mathbf{K}_{t} \mathbf{H}) \mathbf{P}_{t}^{-} Pt+=(E−KtH)Pt−。
我们可以将卡尔曼滤波看作是融合不同传感器信息进行不确定性估计的技术,它的每一个组成部分,初始估计、预测状态和更新状态都是通过均值和方差确定的随机变量。由于它是一个递推的公式,要计算 t = 1 t = 1 t=1时刻误差的协方差矩阵 P 1 − \mathbf{P}_{1}^{-} P1−,需要给出 t = 0 t = 0 t=0时刻的协方差矩阵 P 0 + \mathbf{P}_{0}^{+} P0+,以及初始化一个 Q 0 \mathbf{Q}_{0} Q0。
卡尔曼滤波对初始值并不是很敏感,在实际使用中,如果可以得到在一段初始时间内状态向量的简单计算结果,那么也就可以从这一段时间内计算出均值和方差。比如在上面这个例子中,起始阶段小车静止,速度和距离都是0,但是如果直接用加速度传感器的输出做一次积分得到速度,做二次积分得到距离,得到的速度和距离不是0的话,那么就可以据此简单估计出噪声的均值和方差。对于无法估计的系统,噪声的方差可以设为传感器的观测方差,一般可以通过测量实验或从传感器厂商那里直接获得。
练习
接下来我们通过Python实现一个简单的卡尔曼滤波:
import numpy as np
import matplotlib.pyplot as plt
delta_t = 0.1 # 每秒钟采一次样
end_t = 7 # 时间长度
time_t = end_t * 10 # 采样次数
t = np.arange(0, end_t, delta_t) # 设置时间数组
u = 1 # 定义外界对系统的作用 加速度
x = 1 / 2 * u * t ** 2 # 实际真实位置
v_var = 1 # 测量噪声的方差
# 创建高斯噪声,精确到小数点后两位
v_noise = np.round(np.random.normal(0, v_var, time_t), 2)
X = np.mat([[0], [0]]) # 定义预测优化值的初始状态
v = np.mat(v_noise) # 定义测量噪声
z = x + v # 定义测量值 = 实际状态值 + 噪声
A = np.mat([[1, delta_t], [0, 1]]) # 定义状态转移矩阵
B = [[delta_t ** 2 / 2], [delta_t]] # 定义输入控制矩阵
P = np.mat([[1, 0], [0, 1]]) # 定义初始状态协方差矩阵
Q = np.mat([[0.001, 0], [0, 0.001]]) # 定义预测噪声协方差矩阵
H = np.mat([1, 0]) # 定义观测矩阵
R = np.mat([1]) # 定义观测噪声协方差
X_mat = np.zeros(time_t) # 初始化记录系统预测优化值的列表
for i in range(time_t):
# 预测
X_predict = A * X + np.dot(B, u) # 估算状态变量
P_predict = A * P * A.T + Q # 估算状态误差协方差
# 校正
K = P_predict * H.T / (H * P_predict * H.T + R) # 更新卡尔曼增益
X = X_predict + K * (z[0, i] - H * X_predict) # 更新预测优化值
P = (np.eye(2) - K * H) * P_predict # 更新状态误差协方差
# 记录系统的预测优化值
X_mat[i] = X[0, 0]
plt.plot(x, "b", label="ground truth") # 设置曲线数值
plt.plot(X_mat, "g", label="predict value")
plt.plot(z.T, "r--", label="measure value")
plt.xlabel("time") # 设置X轴的名字
plt.ylabel("distance") # 设置Y轴的名字
plt.title("Kalman Filter") # 设置标题
plt.legend() # 设置图例
plt.show() # 显示图表
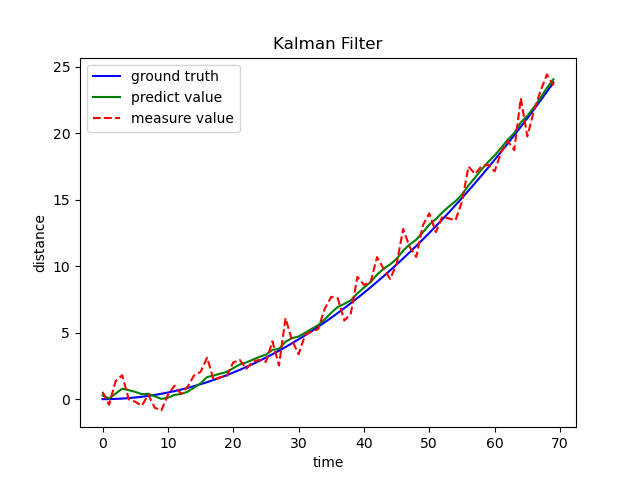
可以看出,尽管测量值波动很大,但最终的预测优化值与实际状态值相差不大。