Java基础
- 什么是字节码?
jvm可以理解的代码(.class文件)
Java代码从源代码到运行过程:
java代码 -> javac编译器->.class字节码文件 -> 解释器&JIT(运行时编译器)->机器码
JIT编译器会将热点代码的机器码保存下来 - 什么是AOT编译模式
直接将字节码编译成机器码,避免了JIT预热的时间,为什么不全部使用AOT,和Java语言的动态特性有关,有些技术需要修改.class文件 - Java执行过程
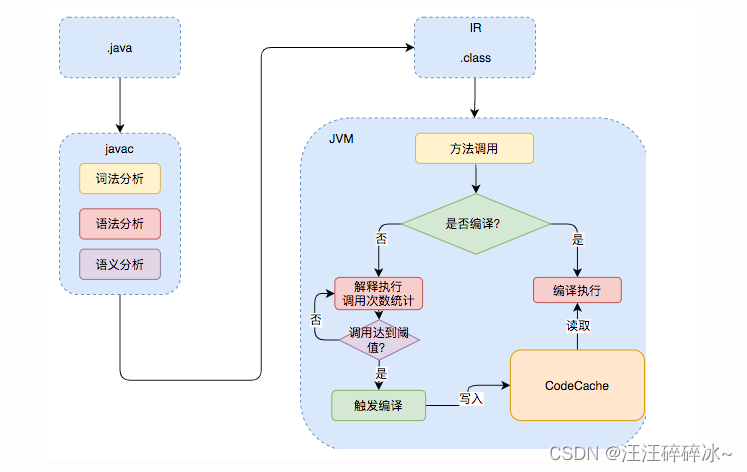
- 成员变量和局部变量
成员变量如果没有赋初始值会自动赋默认值,局部变量如果没有赋初始值则不会自动赋值 - 重载和重写的区别
- 重载同一个类(或者子类和父类之间),方法名相同,参数类型不同,个数不同,顺序不同,放回值和修饰符可以不同
- 重写发生在运行期,是子类对父类允许访问的方法的实现过程重写,方法名、参数列表必须相同。返回值比重写前的更小或相同,异常范围更小或相同,访问修饰符更大或相同
- private/final/static方法不能被重写
- 构造方法不能被重写
- 面向对象三大特征
封装、继承、多态
- 多态的具体表现为父类的引用指向子类的实例
- 接口和抽象类有什么共同点和区别?
共同点:
- 都不能被实例化
- 都可以包含抽象方法
区别:
接口主要是对类的行为进行约束,提供一种规范。抽象类主要用于代码复用,强调所属关系。
一个类只能继承一个抽象类,但可以实现多个接口
Java中只有值传递
- 如果参数是基本类型的话,传递基本类型字面量值的拷贝
- 如果参数是引用类型,传递的是实参引用对象在堆地址之中的拷贝
Java序列化和反序列化
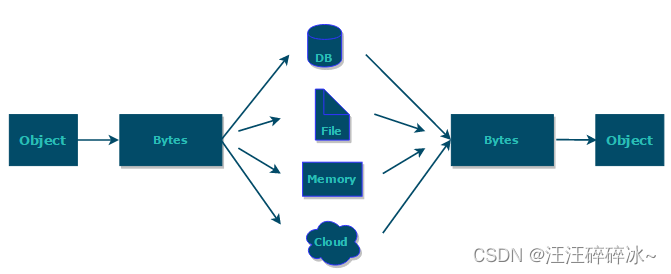
序列化协议对应于应用层
Java代理模式
使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。
动态代理机制
jdk动态代理机制:invocationHandler接口和proxy类是核心
invocationHandler接口定义jdk动态代理类,重写invoke调用原生方法,自定义处理逻辑
proxy获取代理对象的工厂类
缺点:只能代理实现了接口的类
CGLIB动态代理机制:MethodInterceptor 接口和 Enhancer 类是核心。
自定义 MethodInterceptor 并重写 intercept 方法,
通过 Enhancer 类的 create()创建代理类
java集合
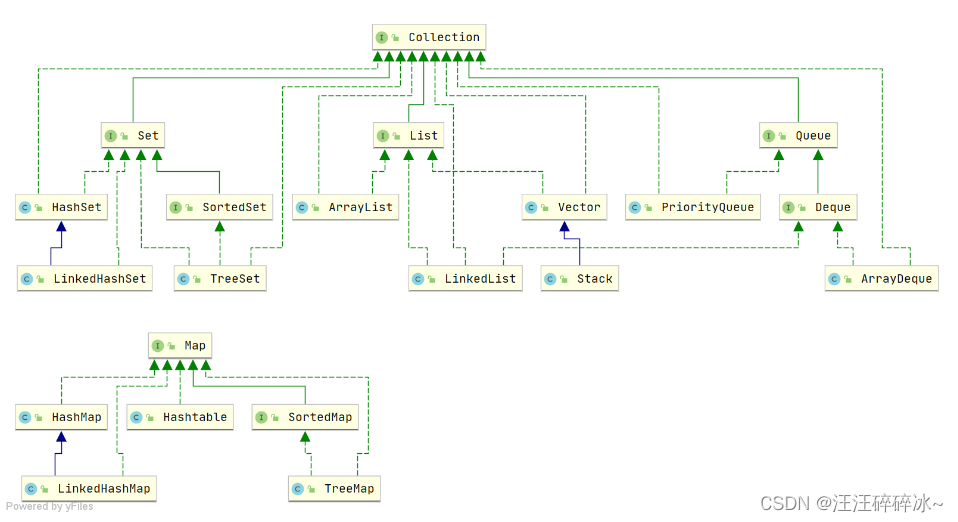
collection
list
ArrayList是list主要实现类,底层使用object[],线程不安全
Vector,底层使用object[],线程安全
LinkedList,底层使用双向链表,线程不安全
ArrayList扩容机制分析:默认构造函数,初始容量10
扩容关键代码:int newCapacity = oldCapacity + (oldCapacity >> 1),扩容后为原容积的1.5倍左右,位移运算符比普通运算符快很多
set
HashSet、LinkedHashSet 和 TreeSet 都是 Set 接口的实现类,都能保证元素唯一,并且都不是线程安全的。
hashset底层数据结构是哈希表(基于hashmap)、linkedhashset底层结构是链表和哈希表,先进先出。TreeSet 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序
queue
Queue 扩展了 Collection 的接口,根据 因为容量问题而导致操作失败后处理方式的不同 可以分为两类方法: 一种在操作失败后会抛出异常,另一种则会返回特殊值。
Deque 扩展了 Queue 的接口, 增加了在队首和队尾进行插入和删除的方法,同样根据失败后处理方式的不同分为两类
ArrayDeque 和 LinkedList 都实现了 Deque 接口,两者都具有队列的功能,也可以用作栈
priorityQueue元素出列顺序与优先级相关
arrayDeque底层通过循环数组实现,是非线程安全的
MAP
hashmap 和hashtable hashmap线程不安全,table线程安全
基本不用hashtable
线程安全可以使用concurrenthashmap
hashmap默认大小16,扩容变为原来两倍,hashmap的扩容标准,阈值等于容量×加载因子,加载因子默认值是0.75
创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小
HashMap 总是使用 2 的幂作为哈希表的大小
HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)
treemap:拥有集合内元素搜索的能力以及根据键排序的能力
concurrenthashmap实现线程安全的方式:1.7的时候采用segment的方式,每把锁只锁一部分数据,segment继承了reentrantlock,可重入锁,segmengt的个数确定不可变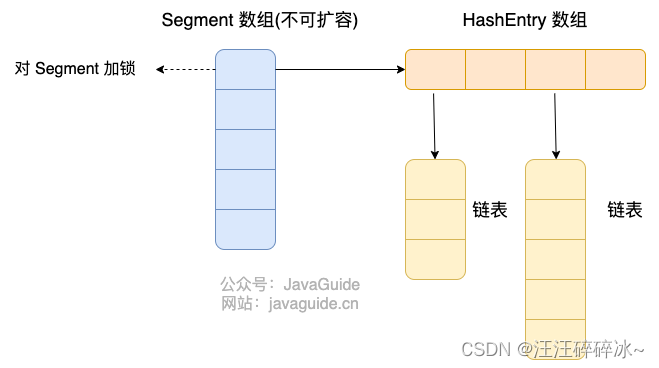
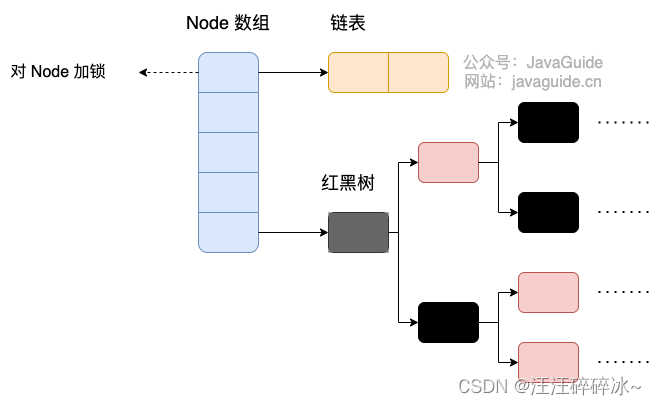
1.8的时候 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作
java IO
设计模式
装饰器模式:在不改变原有对象的情况下拓展其功能
装饰器模式很重要的一个特征,那就是可以对原始类嵌套使用多个装饰器。
适配器模式:主要用于接口互不兼容的类的协调工作
常见的IO模型
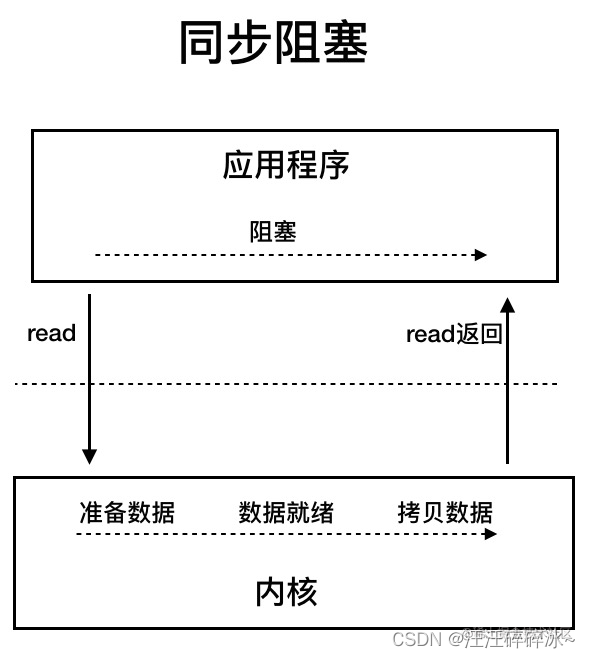
- BIO同步阻塞IO模型
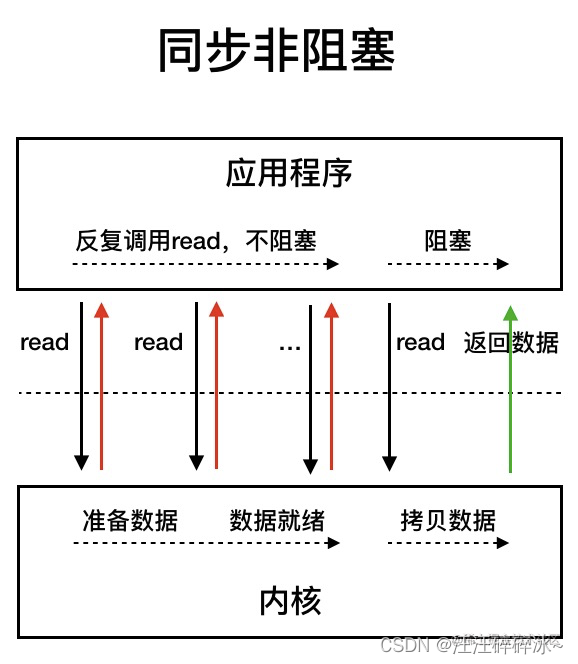
- NIO
同步非阻塞IO
在内核准备数据和数据就绪阶段中,应用程序会一直read调用,不过在数据拷贝阶段中,线程依然阻塞。不过应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。
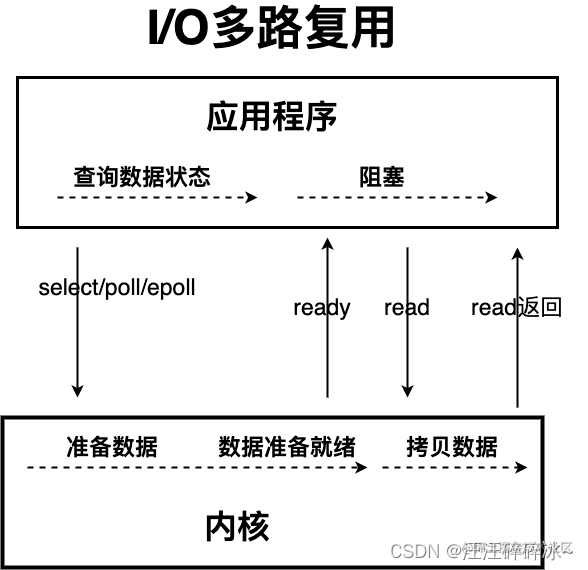
IO多路复用
线程发起select调用,等到内核数据准备好之后再发起read调用,read调用的过程依然阻塞,通过减少无效的系统调用,减少了对CPU资源的消耗
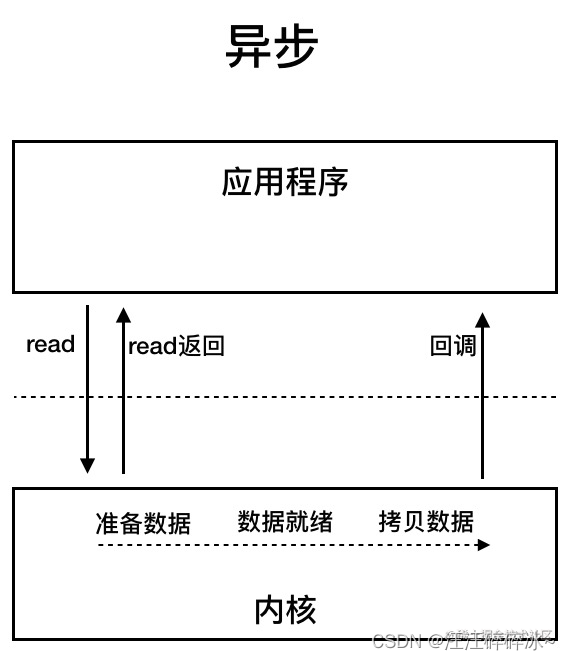
- AIO
异步IO基于事件和回调机制实现
并发编程
为什么程序计数器、虚拟机栈和本地方法栈是线程私有的?
程序计数器私有主要是为了线程切换后能恢复到正确的执行位置。为了保证线程中的局部变量不被别的线程访问到,虚拟机栈和本地方法栈是线程私有的
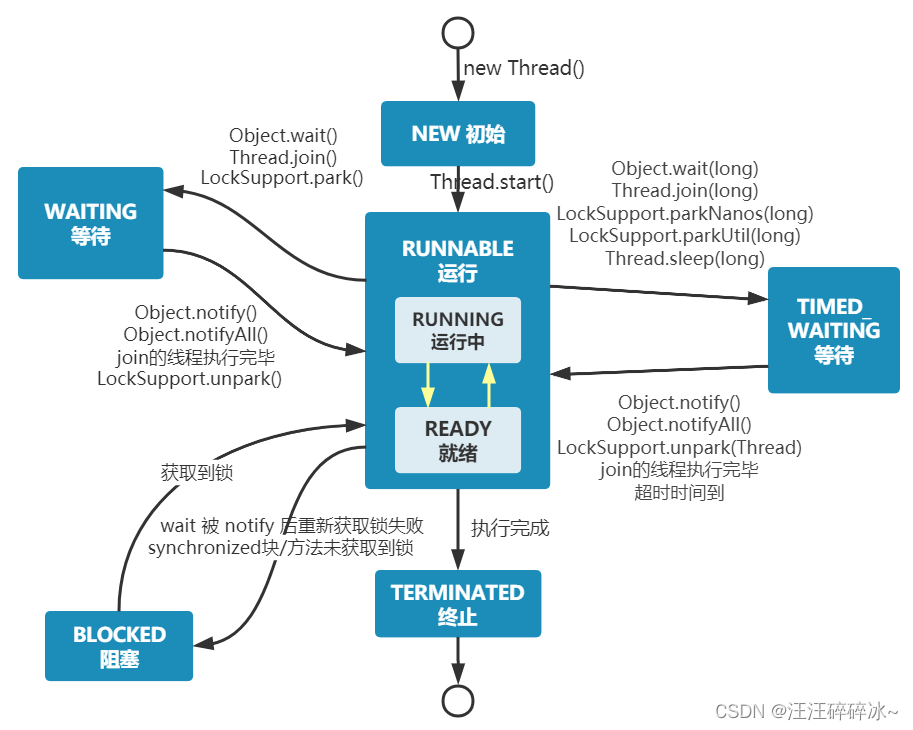
线程的生命周期和状态
sleep 和wait 方法对比
sleep()方法没有释放锁,wait释放锁
sleep是thread类的静态方法,wait是object类的本地方法,因为wait方法操作的的是对象实例
反复调用一个线程的start()方法是否可行
不行,threadStatus的变量。如果它不等于0,调用start()是会直接抛出异常的。,在调用一次start()之后,threadStatus的值会改变(threadStatus !=0),此时再次调用start()方法会抛出IllegalThreadStateException异常。
可以直接调用 Thread 类的 run 方法吗?
如果直接调用run方法的话并不是以多线程的方式执行:
new 一个 Thread,线程进入了新建状态。调用 start()方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 但是,直接执行 run() 方法,会把 run() 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
线程组和线程优先级
每个Thread必然存在于一个ThreadGroup中,Thread不能独立于ThreadGroup存在
threadGroup是标准的向下引用的树状结构,设计的原因是防止上级线程被下级线程引用而无法被垃圾回收
线程安全问题
活跃性问题
- 死锁
- 活锁
- 饥饿问题
性能问题
线程创建和上下文切换
java内存区域和内存模型
Java使用共享内存并发模型
1.内存可见性
针对共享变量,堆,为什么会有内存不可见问题,因为会在缓存区缓存共享变量
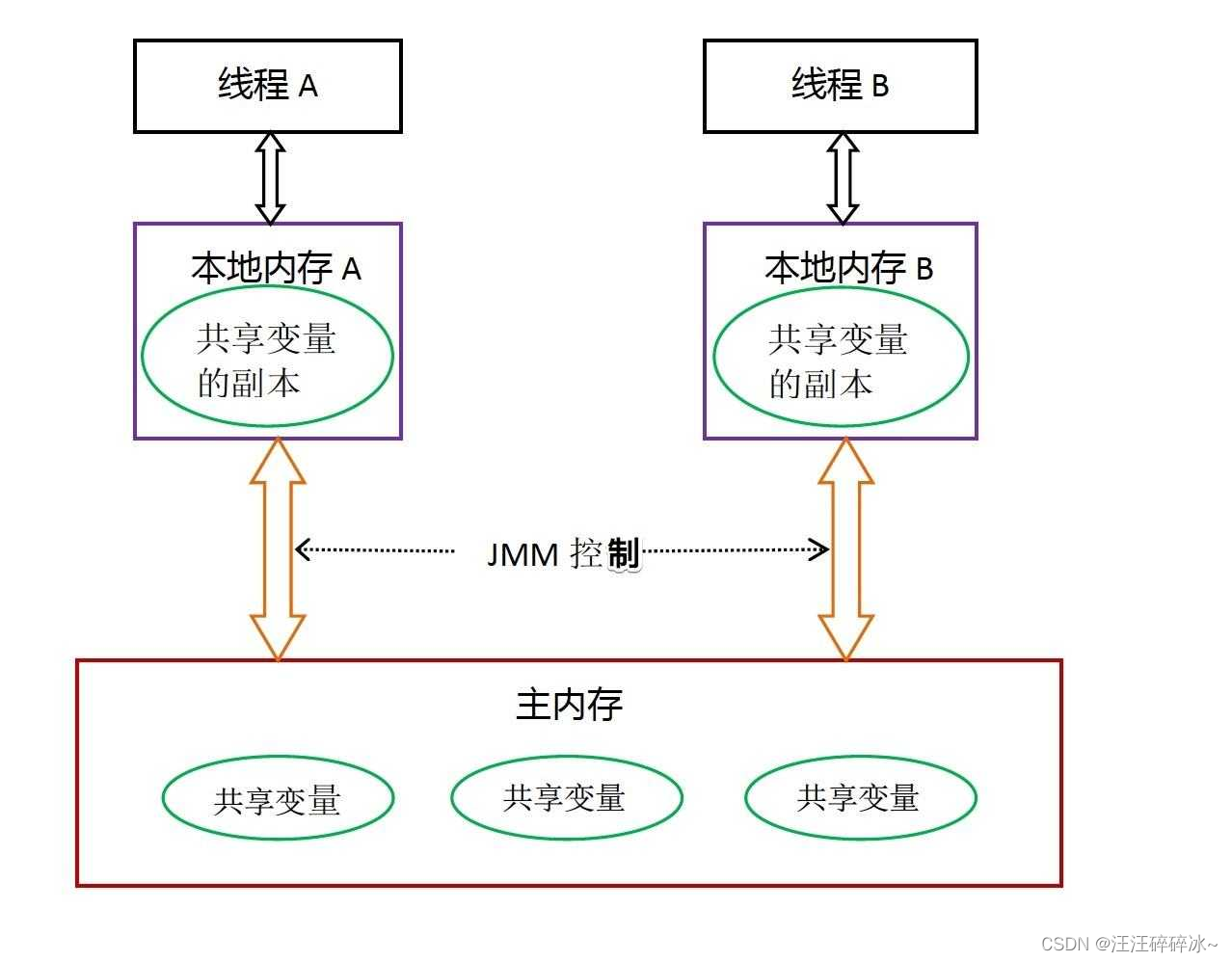
JMM通过控制主内存与每个线程的本地内存之间的交互,来提供内存可见性的保证。
指令重排:
编译器优化重排
指令并行重排
内存系统重排
线程池
通过threadPoolExecutor的方式创建线程池,不建议使用executors创建。
核心参数:
corePoolSize:线程池的核心线程数量
maximumPoolSize:最大线程数量
keepAliveTime:线程数大于核心线程数时的空闲线程最长存活时间
workQueue:等待队列
线程池饱和策略:
AbortPolicy:抛出异常RejectedExecutionException来拒绝新任务的处理
CallerRunsPolicy:调用执行线程运行任务
discardPolicy:不处理新任务,直接丢掉
discardOldestpolicy:丢弃最早的未处理任务
线程池提交一个任务的流程原理

几个对比
- runnable和callable:runnable不会返回结果或抛出异常,callable可以
- execute和submit:execute用于提交不需要返回值的任务,无法判断任务是否被线程池执行成功与否。submit会返回一个future类型对象,通过这个对象可以判断任务是否执行成功,通过future的get方法获取返回值
AQS
抽象队列同步器
主要就是为构建锁和同步器提供了一些通用功能的实现
核心思想:
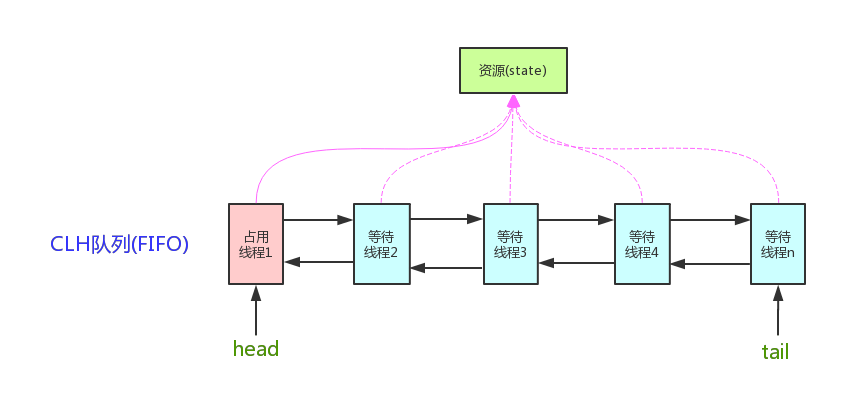
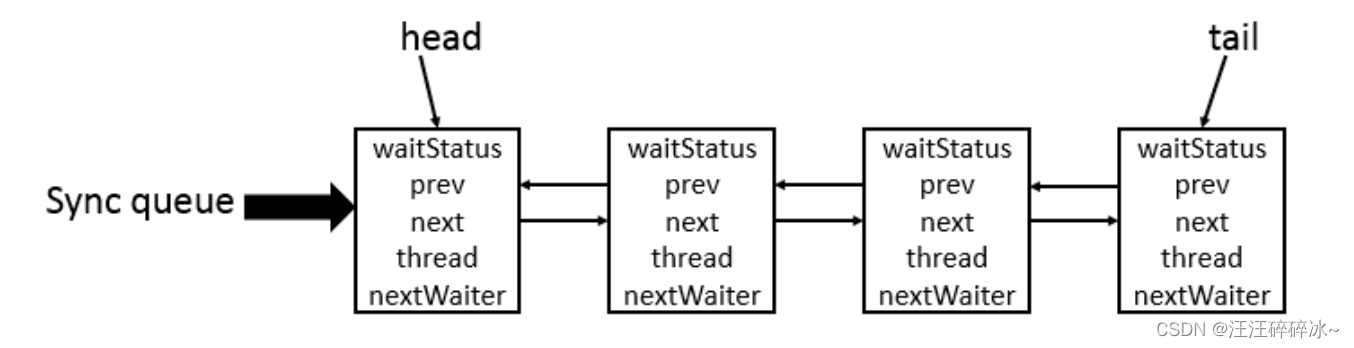
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁 实现的,即将暂时获取不到锁的线程加入到队列中。在 CLH 同步队列中,一个节点表示一个线程,它保存着线程的引用(thread)、 当前节点在队列中的状态(waitStatus)、前驱节点(prev)、后继节点(next)。
核心原理图:
AQS使用state变量表示同步状态
semaphore
可以用来控制同时访问特定资源的线程数量
具有公平模式和非公平模式
semaphore会默认构造state为许可的数量,然后state>=0的时候可以获取,小于0的时候不行,加入阻塞队列
一般用来限流
countdownlatch
CountDownLatch 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。CountDownLatch 是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当 CountDownLatch 使用完毕后,它不能再次被使用
实现原理也是初始化state为count,不同的是到state为0的时候才会执行
可以用来多线程读取多个文件的任务,对多个文件的结果需要汇总处理,这样countdown结束后才会执行后面逻辑
CLH队列锁
CLH是一个虚拟的双向队列,AQS将每个请求共享资源的线程封装成CLH锁队列的节点实现锁分配。
乐观锁的实现
版本号机制或CAS算法
常见并发容器
ConcurrentHashMap
copyonwriteArrayList
只对写加锁,内部copy数组
ConcurrentLinkedQueue
非阻塞队列,使用CAS