1 生产者
生产逻辑
- 配置生产者客户端参数及创建相应的生产者实例。
- 构建待发送的消息。
- 发送消息
- 关闭实列
参数说明
- bootstrap.servers :用来指定生产者客户端链接Kafka集群搜需要的broker地址清单,具体格式 host1:port1,host2:port2,可以设置一个或多个地址中间,号分割,参数默认 空串。这里要注意并不需要配置所有的broker地址,应为生产者会在broker中找到其他的broker地址,但是建议配置两个以上,当其中一个broker宕机时还可以通过另外一个工作。
- key.serializer和value.serializer:broker端接受的消息必须以字节数组的形式存在。
- client.id : 默认 “” 用来设置KafkaProducer对应的客户端id
- max.block.ms:默认值 60000 用来控制KafkaProducer 中send()方法和partitionsFor()方法的阻塞时间
- partitioner.class:用来指定分区器
- enable.idempotence:默认值 false 是否开启幂等性
- interceptor.classes 用来设置生产者拦截器
- max.in.flight.requests.per.connection:5 限制每个连接最多缓存的请求数
- metadata.max.age.ms: 300000 5分钟 如果在这个时间内元数据没有更新的话就强制更新。
- transactional.id:null 设置事务id 必须唯一
- batch.size 16384(16KB): 生产者客户端中用于缓存消息的缓冲区大小。
序列化器(Serializer)
生产者发送消息到kafka是需要将对象序列化城流才能访问到kafka,消费者需要把流反序列化 才能进行 消费。
分区器
消息在通过send()方法发送到broker的过程中,有可能需要经过拦截器、序列化器和分区器(partitioner)的一系列作用之后才能被真正的发往broker。拦截器一般不是必须的,而序列化器时必须的必须的。消息经过序列化之后就需要确定它发送的分区,如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区。
分区器时通过kay来计算partition的值,分区器的作用就是为消息分配分区。
kafka的默认分区器是 org.apache.kafka.clients.producer.internals.DefaultPartitioner
生产者拦截器(Interceptor)
生产者拦截器主要用来在消息发送前做一些准备工作,如按照规则过滤不符合条件的消息,修改消息等,也可以用来做一些定制化的需求,kafkaProducer在将消息序列化和计算分区之前会调用拦截器的onSend()方法来对消息进行相应的定制化
原理分析
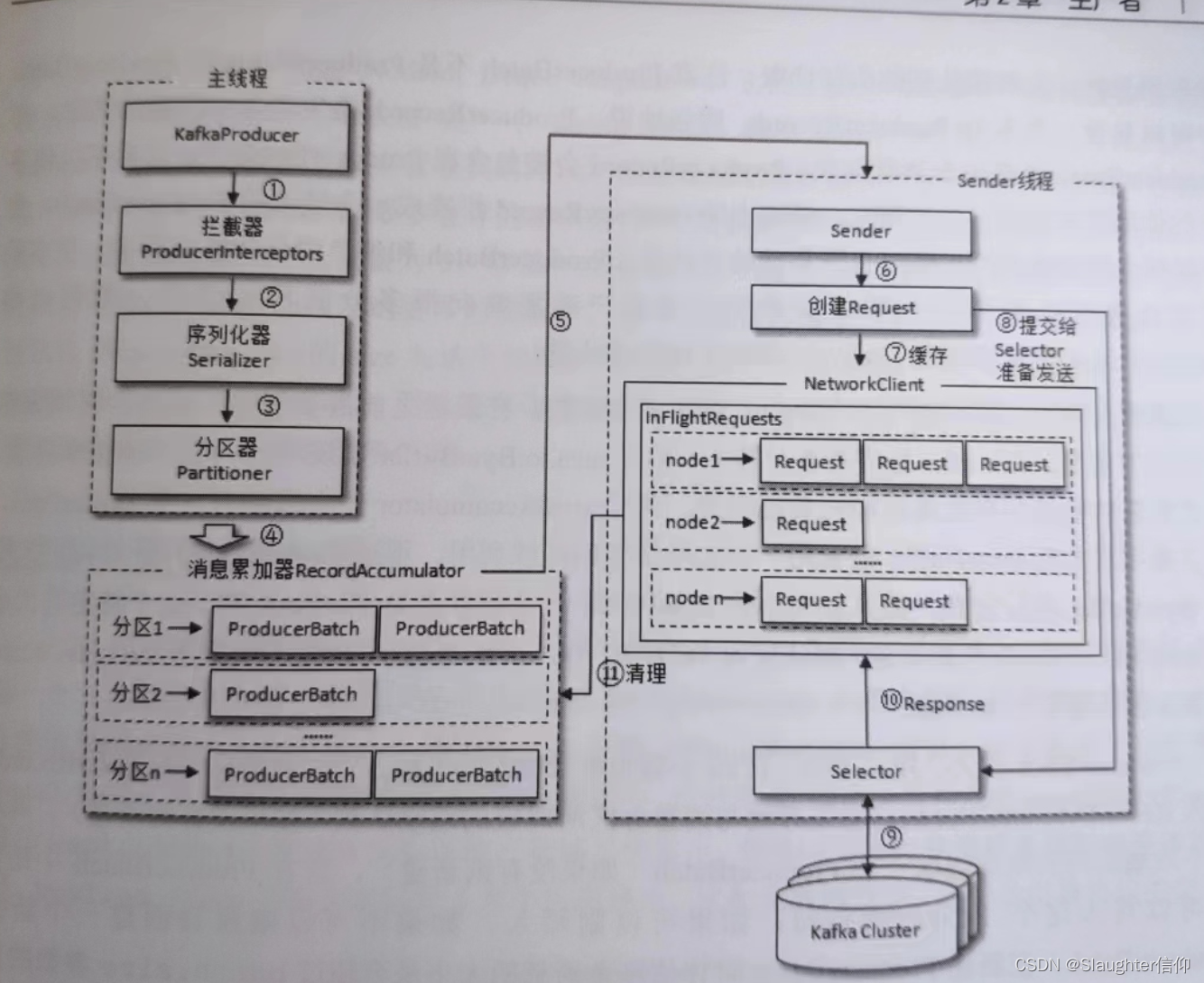
- 主线程中由KafkaPartition创建消息
- 通过拦截器
- 通过序列化器
- 通过分区器
- 到达消息累加器(RecordAccumulator)主要是用来收集消息方便 Sender可以批量发送