一、数组的引用
int main()
{
int a = 10, b = 20;
int ar[10] = { 1,2,3,4,6,7 };
int& x = ar[0];
int& p[5] = ar;//error
int(&p)[10] = ar;//引用整个数组的大小sizeof(ar)
int(*p)[10] = &ar;//type+size=表示整个数组
//只有在这三种情况下代表整个数组,其他情况下退化成为数组首元素的地址
}二、指针的引用
int main()
{
int a = 10, b = 20;
int* ip = &a;
int* s = ip;
int*& rs = ip;
rs = &b;//ip=&b;
*rs = 100;//*ip=100;
//int&* rb; //error
}三、引用作为形参代替指针
void swap(int& ap, int& bp)
{
int temp = ap;//不需要判空,能够使用引用,就不需要使用指针
ap = bp;
bp = temp;
}
int main()
{
int a = 10, b = 20;
swap(a, b);
}
四、指针和引用的区别
从语法规则上来看
指针变量存储某个实例(变量或对象)的地址,引用是某个实例的别名。
程序为指针分配内存区域,而不为引用分配内存区域。
解引用是指针使用时要在前面加*,引用可以直接使用。
指针变量的值可以发生改变,存储不同实例的地址,引用在定义的时候就被初始化,之后无法改变(不能是其他实例的引用)。
指针变量的值可以为空,没有空引用。
指针变量作为形参需要测试它的合法性(判空NULL),引用不需要判空。
对指针变量使用“sizeof”得到的是指针变量的大小,对引用变量使用“sizeof”得到的是变量的大小。
理论上指针的级别没有限制,但引用只有一级。既不存在引用的引用,但可以有指针的指针。
++引用和++指针的效果不同。
对指针变量的操作,会使指针变量指向下一个实体(变量或对象)的地址,而不是改变所指实体(变量或对象)的内容。对引用的操作直接反应所引用的实体(变量或对象)。
不可以对函数中的局部变量以引用或指针的方式返回。
从汇编规则上来看(int& b <=> int* const x)
在编译的角度来说,引用其实是自身为常性的指针。
五、inline内联函数
当函数执行调用时,系统要建立栈空间,保护现场,传递参数以及控制程序执行的转移等等,这些工作主要系统时间和空间的开销。
inline的设置
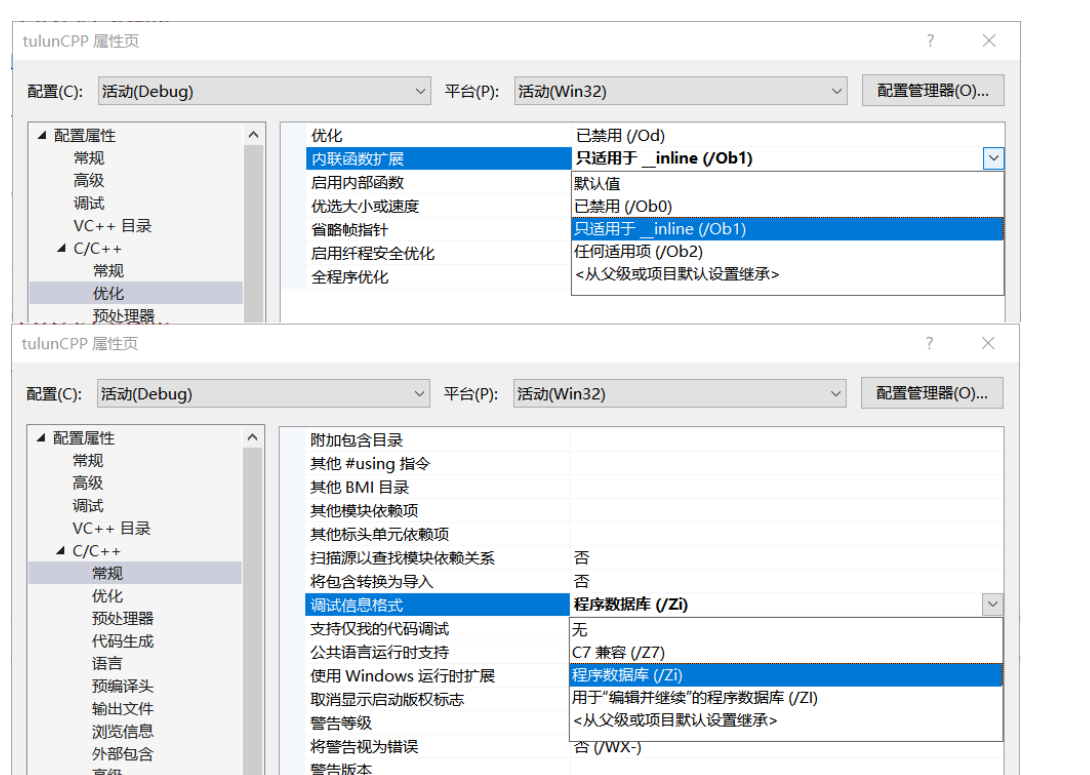
inline举例
inline bool ISNumber(char c)
{
return (c >= '0' && c <= '9') ? true : false;
}
int main()
{
char ch;
while (cin.get(ch), ch != '\n')
{
if (ISNumber(ch))
{
cout << "是数字型字符" << endl;
}
else
{
cout << "不是数字型字符" << endl;
}
}
}要点:
inline是一种以空间换时间的做法,省去调用函数的开销。但当函数体的代码过长或者递归函数即便加上inine关键字,也不会在调用点以内联展开该函数。
inline对于编译器而言只是一个建议,编译器会自动优化。
inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
哪种情况下采用inline处理适合,什么情况下以普通函数形式处理合适呢?
如果函数的执行开销小于开栈清栈开销(函数体较小),使用inline处理效率高。如果函数的执行开销大于开栈清栈开销,使用普通函数处理。
内联函数与宏定义区别:
内联函数在编译时展开,带参的宏在预编译时展开。
内联函数直接嵌入到目标代码中,带参的宏是简单的文本替换。
内联函数有类型检测、语法判断等功能,宏只是替换。