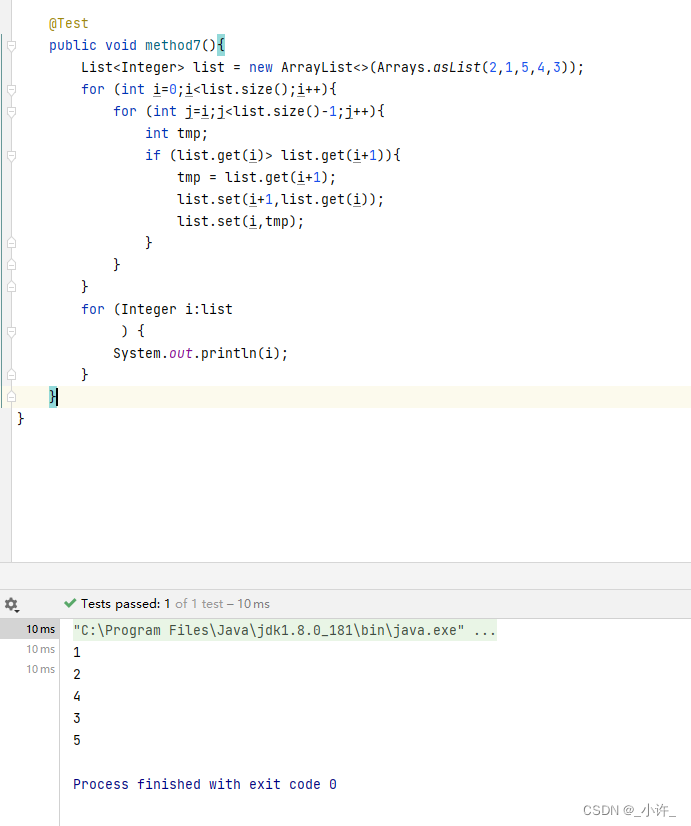
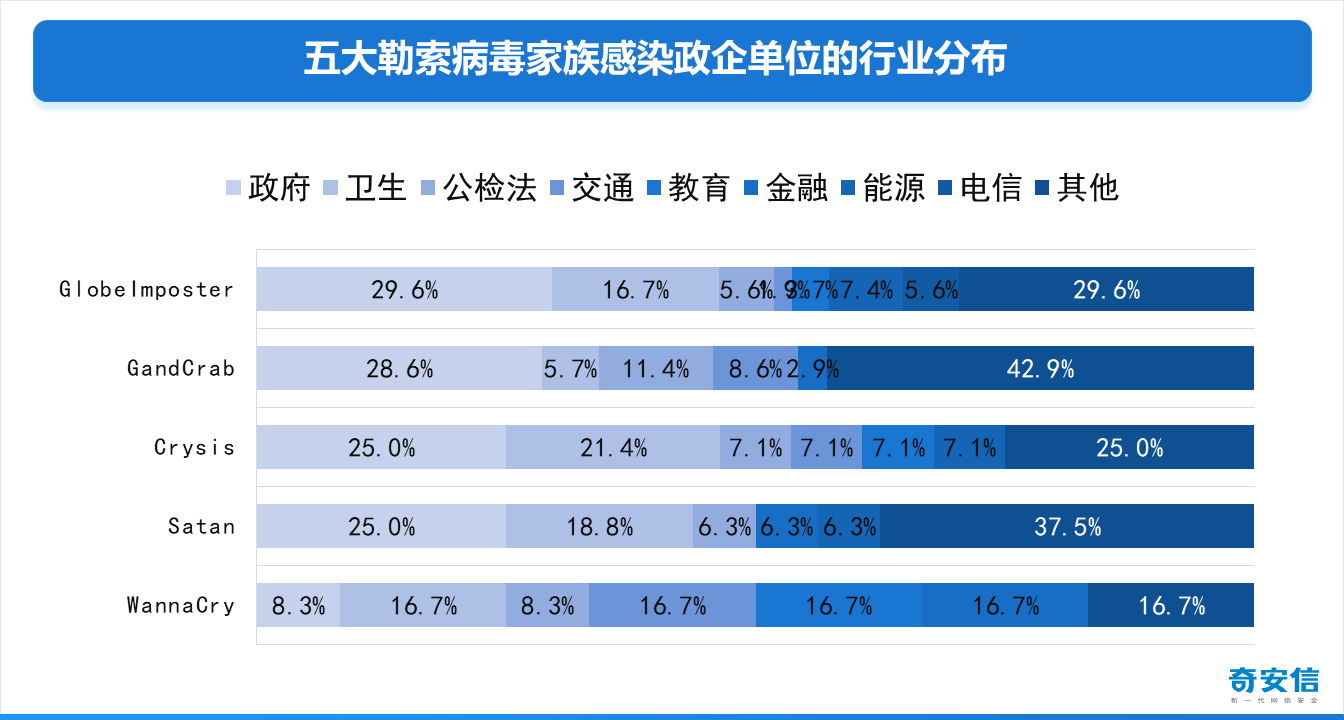
①引入pandas包,命名为pd。
- import pandas as pd
②读入HR.csv数据
- df=pd.read_csv(“./data/HR.csv”)
③查看是什么结构
- type(df)
④查看单个类别satisfaction_level的数据结构
- type(df[“satisfaction_level”])
⑤查看均值的数据结构
- type(df.mean())
⑥求satisfaction_level的均值
- df[“satisfaction_level”].mean()
⑦查看所有值的中位数
- df.median()
⑧查看satisfaction_level的中位数
- df[“satisfaction_level”].median()
⑨查看所有值的四分位数(四分位数q是0.25,)
- df.quantile(q=0.25)
⑩查看satisfaction_level的四分位数
- df[“satisfaction_level”].quantile(q=0.25)
11、求所有值的众数(会出现多个众数的情况,求单个类的众数和上面写的一样就是换一个函数。)
- df.mode()
12、离中趋势
- 标准差 df.std()
- 方差 df.var()
- 求和sum()
- 偏态系数skaw()(负数说明平均值偏小,所以大部份值是大于它的平均值的)
- 风险系数kurt(正态分布0作为标准)
13、实现分布函数,pandas不能直接生说需要导入scipy统计包来帮助实现,命名为ss。 - import scipy.stats as ss
14、生成一个正态分布的对象 - ss.norm
15、查看正态分布,m均值,v方差,s偏态系数,k风态系数。
- ss.norm.stats(moments=“mvsk”)
16、标准的正太分布指定横坐标为0时的值
- ss.norm pdf(0.0)
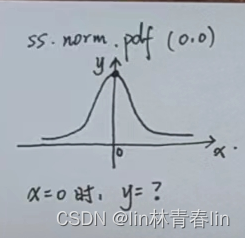
17、正太分布累计到0.9时候,横坐标的值是多少,我其实理解的是面积。x的值是多少,面积能达到0.9,面积的值在0-1之间。
- ss.norm.ppf(0.9)
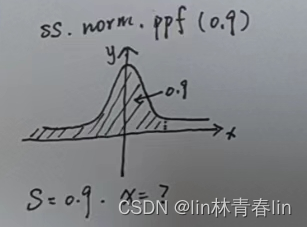
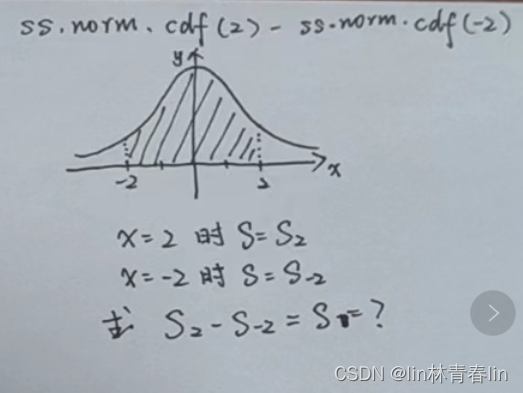
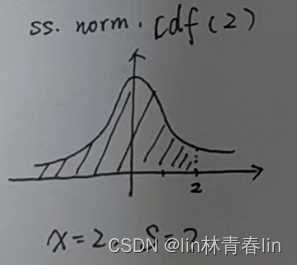
18、当x等于2的时候,面积达到了多少呢?
- ss.norm.cdf(2)
19、