一、目标网址
http://img.itlun.cn/uploads/allimg/180703/1-1PF3160531-lp.jpg二、右击图片获取图片地址
http://img.itlun.cn/uploads/allimg/180703/1-1PF3160531-lp.jpg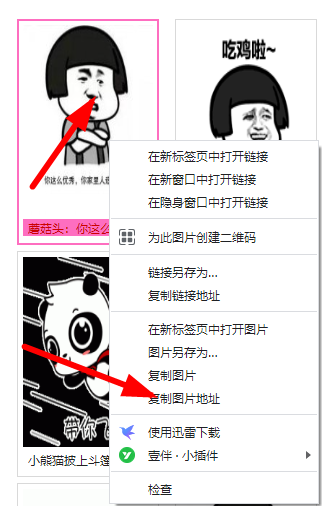
三、以二进制形式返回响应数据
响应=requests.get(网页,headers=头)
响应内容=响应.content四、存储二进制数据
withopen("图片.jpg","wb") as 图片数据:
图片数据.write(响应内容)五、获取单张图片的源码
import requests
头={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
网页="http://img.itlun.cn/uploads/allimg/180703/1-1PF3160531-lp.jpg"
响应=requests.get(网页,headers=头)
响应内容=响应.content
with open("图片.jpg","wb") as 图片数据:
图片数据.write(响应内容)六、通过urllib库获取图片
1、导入库文件
import urllib2、指定要保存的图片地址
图片地址="http://img.itlun.cn/uploads/allimg/180703/1-1PF3160531-lp.jpg"3、通过命令获取该图片
urllib.request.urlretrieve(图片地址,"456.jpg")七、批量获取图片
1、通过网页源码,批量获取图片地址
import requests
目标地址="http://md.itlun.cn/a/new/"头={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
响应=requests.get(url=目标地址,headers=头)
响应内容=响应.textprint(响应内容)2、响应内容有乱码,charset是gbk,所以我们指定一下代码
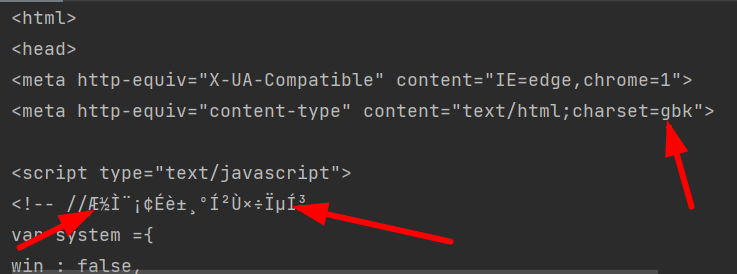
3、指定编码格式
响应.encoding="gbk"4、分析源码,找到了图片的所有地址

5、通过正则表达式获取图片地址
正则='target="_blank"><IMG border="0" src="(.*?)"'
print(re.findall(正则,响应内容))6、返回的数据是一个列表,将列表里面的值重新组和,并保存
正则='target="_blank"><IMG border="0" src="(.*?)"'
列表内容=re.findall(正则,响应内容)for i in 列表内容:
i="http:"+i
图片名字=i.split("/")[-1]
urllib.request.urlretrieve(i,图片名字)