今天和大家聊一聊伪共享
1.什么是伪共享?
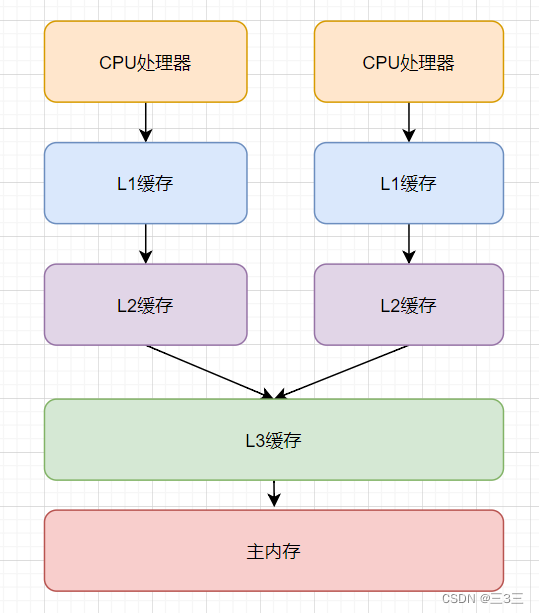
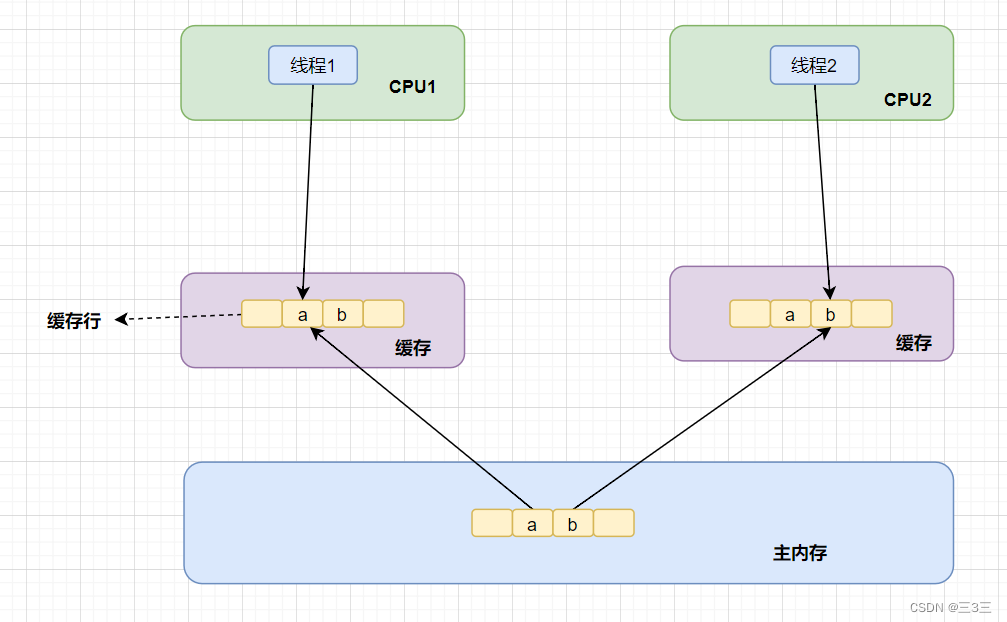
缓存一致性协议在计算机中针对的最小单元:缓存行,每个缓存行的大小是64字节,一串连续的64字节数据都会存储到缓存行中。
- 假设数据A和数据B在同一缓存行中,CPU1修改了数据A,根据缓存一致性协议,CPU1会通知其他CPU这一行的缓存数据已经失效。此时CPU2想要修改数据B,但是缓存行已经失效了,所以需要重新从主内存中读取数据,然后重新写会缓存行中。这样缓存的优势就完全没有了。
- 上述问题就是伪共享的场景,如果同时有多个CPU同时修改同一缓存行的数据,频繁回写主内存,会大大降低性能。
如下图所示:
2.如何解决伪共享问题?
- 伪共享的根源就是不同的数据缓存到了同一缓存行中,如果我们能把独立的数据都单独存储到不同的缓存行,那么伪共享的问题也就不存在了。
- 缓存行填充:
当我们存储的数据不足64字节的时候,我们可以手动将余下的字节空间填充,以空间换时间的方式,解决伪共享。
举个例子:
public class FalseShareTest {
public static void main(String[] args) throws InterruptedException {
Rectangle rectangle = new Rectangle();
long beginTime = System.currentTimeMillis();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
rectangle.a = rectangle.a + 1;
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
rectangle.b = rectangle.b + 1;
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("执行时间" + (System.currentTimeMillis() - beginTime));
}
}
class Rectangle {
volatile long a;
volatile long b;
}
//运行结果:
执行时间2815
一个long类型是8字节,我们在变量a和b之间不上7个long类型变量呢,输出结果是啥呢?如下:
class Rectangle {
volatile long a;
long a1,a2,a3,a4,a5,a6,a7;
volatile long b;
}
//运行结果
执行时间1113
我们可以发现,利用填充数据的方式,可以让读写的变量分割到不同缓存行中,性能可以大大提高!
3.消除伪共享的框架应用
Disruptor是一个性能极强的开源的无锁并发框架,基于Disruptor的LMAX架构交易平台,号称单线程内每秒可处理600万笔订单。简直是一个不折不扣的性能小钢炮。
Disruptor框架的核心是它的Ringbuffer环形缓冲。这里不做框架的具体分析,有兴趣可在github下载源码。推荐大家阅读Disruptor框架。
在Disruptor中,也是应用了大量的缓存行填充,消除了伪共享的问题。