pandas——DataFrame基本操作(二)
文章目录
- pandas——DataFrame基本操作(二)
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 1.修改数据
- 2.缺失值
- 3.合并
- 1.concat合并
- 2.使用append方法合并
- 3.使用merge进行合并
- 4.使用join进行连接
一、实验目的
熟练掌握pandas中DataFrame的修改元素值、缺失值处理、合并操作的方法
二、实验原理
concat合并:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
objs: series,dataframe或者是panel构成的序列lsit。
axis: 需要合并链接的轴,0是行,1是列,默认为axis=0。
join:连接的方式 inner,或者outer,默认为join=‘outer’
keys:合并的同时增加分区。
ignore_index:忽略索引,默认为False,当为True时,合并的两表就按列字段对齐。
merge合并:
pandas的merge方法提供了一种类似于SQL的内存链接操作,官网文档提到它的性能会比其他开源语言的数据操作(例如R)要高效。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,validate=None)
merge的参数:
left/right:两个不同的DataFrame
on:指的是用于连接的列索引名称。必须存在左右两个DataFrame对象中,如果没有指定且其他参数也未指定则以两个DataFrame的列名交集做为连接键
left_on:左则DataFrame中用作连接键的列名;这个参数中左右列名不相同,但代表的含义相同时非常有用。right_on:右则DataFrame中用作 连接键的列名。
left_index:使用左则DataFrame中的行索引做为连接键。
right_index:使用右则DataFrame中的行索引做为连接键。
how:指的是合并(连接)的方式有inner(内连接),left(左外连接),right(右外连接),outer(全外连接);默认为inner。
sort:根据DataFrame合并的keys按字典顺序排序,默认是True,如果置false可以提高表现。
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(‘_x’,‘_y’)
copy:默认为True,总是将数据复制到数据结构中;大多数情况下设置为False可以提高性能
indicator:在 0.17.0中还增加了一个显示合并数据中来源情况;如只来自于左边(left_only)、两者(both)。
merge的默认合并方法:merge用于表内部基于 index-on-index 和 index-on-column(s) 的合并,但默认是基于index来合并。
join连接:
主要用于索引上的合并
join(self, other, on=None, how='left', lsuffix='', rsuffix='',sort=False)
其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how=left
1.默认按索引合并,可以合并相同或相似的索引,不管他们有没有重叠列。
2.可以连接多个DataFrame
3.可以连接除索引外的其他列
4.连接方式用参数how控制
5.通过lsuffix=‘’, rsuffix=‘’ 区分相同列名的列
三、实验环境
Python 3.6.1以上
jupyter notebook
四、实验内容
练习pandas中DataFrame的修改元素值、缺失值处理、合并操作。
五、实验步骤
1.修改数据
1.通过字典对象创建一个DataFrame。
import numpy as np
import pandas as pd
dates = pd.date_range('20130101', periods=6)
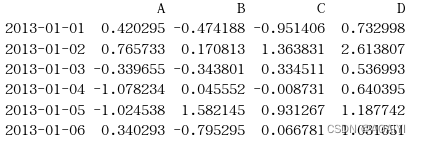
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df)
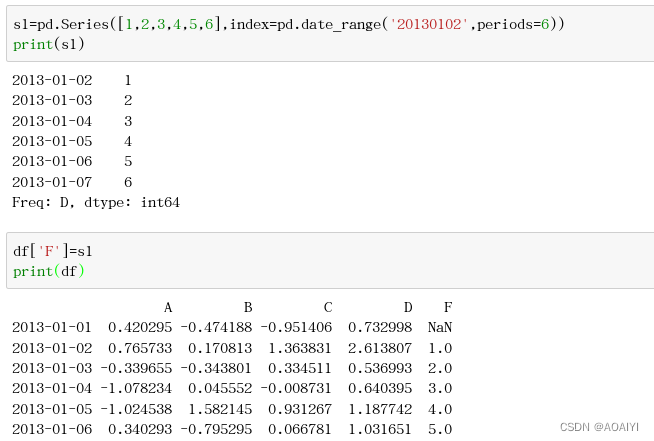
2.新建一个值为[1,2,3,4,5,6],索引index为2013-01-02到2013-01-07的Series,并将series赋值给df作为df新增的F列。
s1=pd.Series([1,2,3,4,5,6],index=pd.date_range('20130102',periods=6))
print(s1)
df['F']=s1
print(df)
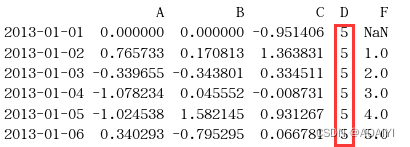
3.使用loc方法把df的D列值修改为5*len(df)。
df.loc[:,'D']=np.array([5]*len(df))
print(df)
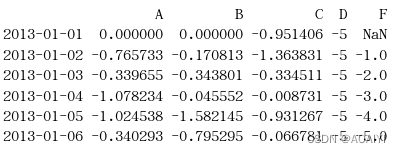
4.使用copy方法将df赋值给df2,使用where语句将df2中满足df2>0条件的值修改为-df2。
df2=df.copy()
df2[df2>0]=-df2
print(df2)
2.缺失值
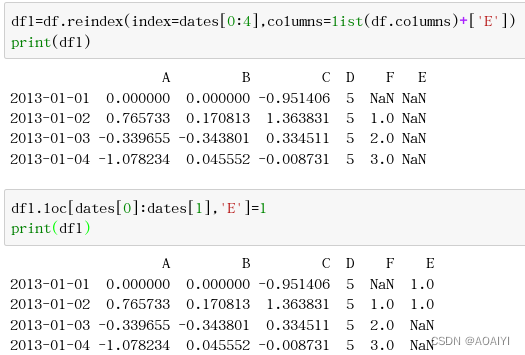
1.使用reindex方法将df的行列索引同时重新索引,使行index=date[0:4],列索引culumns=list(df.columns+[‘E’]),并返回一个新的数据帧df1,然后使用loc方法将df1中行索引为dates[0]和dates[1],列为“E"的值修改为1。
df1=df.reindex(index=dates[0:4],columns=list(df.columns)+['E'])
print(df1)
df1.loc[dates[0]:dates[1],'E']=1
print(df1)
2.使用dropna方法删除df1中任何包含缺失值的行。
df1.dropna(how='any')

3.使用fillna方法,将df1中所有的缺失值用5填充。
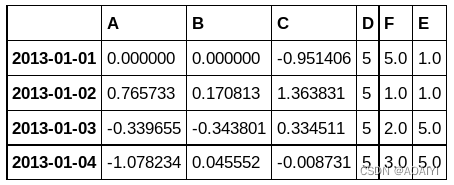
print(df1)
df1.fillna(value=5)
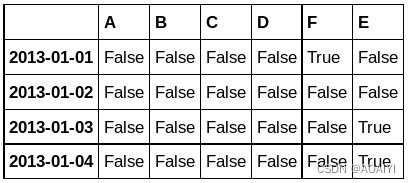
4.使用isnull方法判断df1中的值是否为缺失值,是缺失值返回True,否则返回False,返回一个由布尔值组成的数据帧。
pd.isnull(df1)
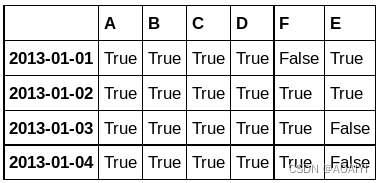
5.使用notnull判断df1中的值是否为缺失值,返回一个由布尔值组成的数据帧。
pd.notnull(df1)
3.合并
1.concat合并
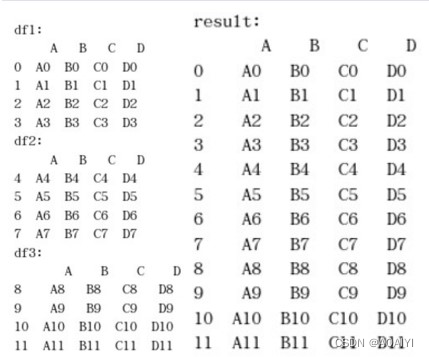
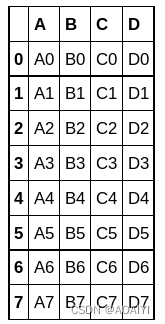
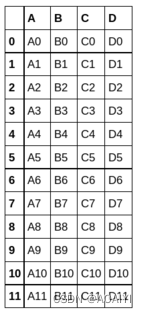
1.创建数据帧df1、df2、df3,使用concat函数将df1\df2\df3进行合并。
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']},index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],'B': ['B4', 'B5', 'B6', 'B7'],'C': ['C4', 'C5', 'C6', 'C7'],'D': ['D4', 'D5', 'D6', 'D7']},index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],'B': ['B8', 'B9', 'B10', 'B11'],'C': ['C8', 'C9', 'C10', 'C11'],'D': ['D8', 'D9', 'D10', 'D11']},index=[8, 9, 10, 11])
result = pd.concat([df1,df2,df3])
print('df1:\n',df1,'\ndf2:\n',df2,'\ndf3:\n','\nresult:\n',result)
2.将df1,df2,df3进行合并,并将合并后的数据帧进行分区为keys=[‘x’,‘y’,‘z’]。
result1 = pd.concat([df1,df2,df3], keys=['x', 'y', 'z'])
print(result1)

3.新建一个数据帧df4,将df1与df4进行列项合并,axis=1。
df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],'D': ['D2', 'D3', 'D6', 'D7'],'F': ['F2', 'F3', 'F6', 'F7']},index=[2, 3, 6, 7])
result2=pd.concat([df1,df4],axis=1)
print(result2)
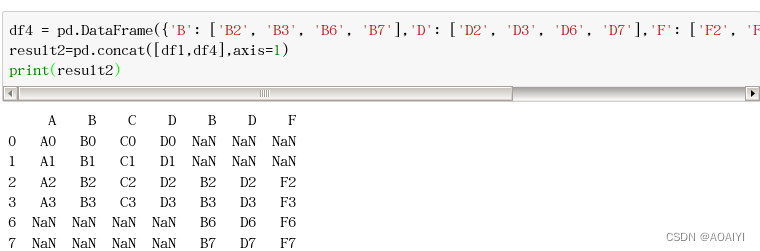
4.df1与df4进行列项合并axis=1,合并方式为内部合并join=‘inner’。
result3=pd.concat([df1,df4],axis=1,join='inner')
print(result3)

2.使用append方法合并
1.使用append方法将df1与df2合并。
df1.append(df2)
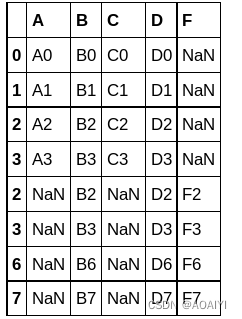
2.使用append方法将df1与df4合并。
df1.append(df4)
3…使用append方法将df1与df2、df3合并。
df1.append([df2,df3])
3.使用merge进行合并
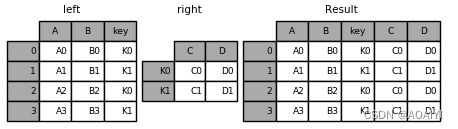
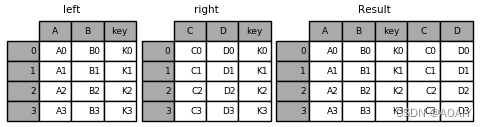
1.创建两个数据帧left、right,使用merge函数按key列将left与right进行连接。
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on='key')
print( left,right,result)
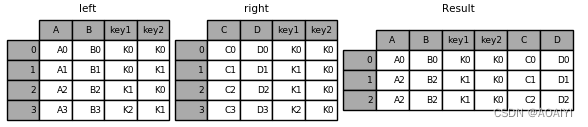
2.复合key的合并方法,使用merge的时候可以选择多个key作为复合可以来对齐合并。
创建两个数据帧left、right,使用merge函数按[key1,key2]列将left与right进行连接。
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],'key2': ['K0', 'K0', 'K0', 'K0'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on=['key1', 'key2'])
print( left,right,result)
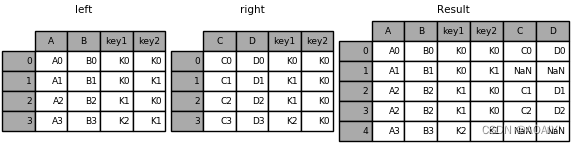
3.使用merge函数按[key1,key2]列将left与right进行左表连接。
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],'key2': ['K0', 'K0', 'K0', 'K0'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
print( left,right,result)
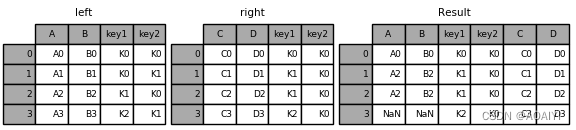
4.使用merge函数按[key1,key2]列将left与right进行右表连接。
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
print(result)
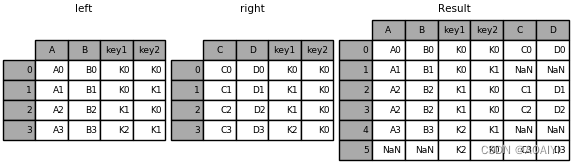
5.使用merge函数按[key1,key2]列将left与right进行外表连接。
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
print(result)
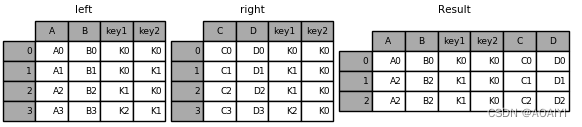
6.使用merge函数按key1,key2列将left与right进行内表连接。
result = pd.merge(left, right, how='inner', on=['key1', 'key2'])
print(result)
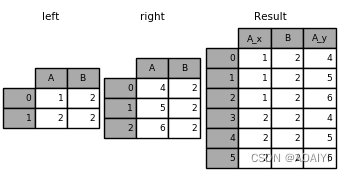
7.创建两个都只有A、B两列的数据帧left,right,使用merge函数按B列将left与right进行外表连接,可以看到除连接列B以外的列名相同时,会在列名后加上区分的后缀。
left = pd.DataFrame({'A' : [1,2], 'B' : [2, 2]})
right = pd.DataFrame({'A' : [4,5,6], 'B': [2,2,2]})
result = pd.merge(left, right, on='B', how='outer')
print(result)
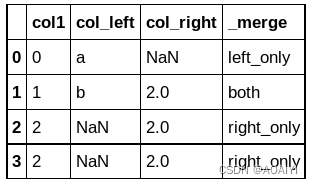
8.创建两个数据帧df1、df2,使用merge函数按col1列将df1与df2进行外表连接,并使用参数indicator显示出每列值在合并列中是否出现。
df1 = pd.DataFrame({'col1': [0, 1], 'col_left':['a', 'b']})
df2 = pd.DataFrame({'col1': [1, 2, 2],'col_right':[2, 2, 2]})
pd.merge(df1, df2, on='col1', how='outer', indicator=True)
4.使用join进行连接
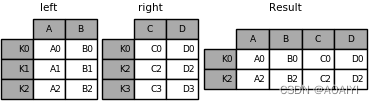
1.创建两个数据帧left、right,使用join方法将left与right连接。
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']},index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],'D': ['D0', 'D2', 'D3']},index=['K0', 'K2', 'K3'])
result = left.join(right)
print(left,'\n',right,'\n',result)
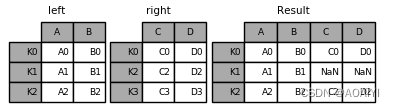
2.使用join方法将left与right进行外表连接
result = left.join(right, how='outer')
print(left,'\n',right,'\n',result)
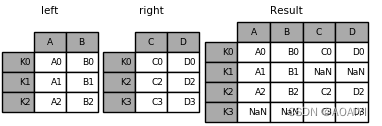
3.使用join方法将left与right进行内表连接.
result = left.join(right, how='inner')
print(left,'\n',right,'\n',result)
4.创建两个数据帧left、right,使用join方法按key列将left与right连接。
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'], 'key': ['K0', 'K1', 'K0', 'K1']})
right = pd.DataFrame({'C': ['C0', 'C1'],'D': ['D0', 'D1']},index=['K0', 'K1'])
result = left.join(right, on='key')
print(left,'\n',right,'\n',result)