哈希表
一般哈希表都是用来快速判断一个元素是否出现在集合里。
哈希函数
哈希碰撞--解决方法:拉链法和线性探测法。
拉链法:冲突的元素都被存储在链表中
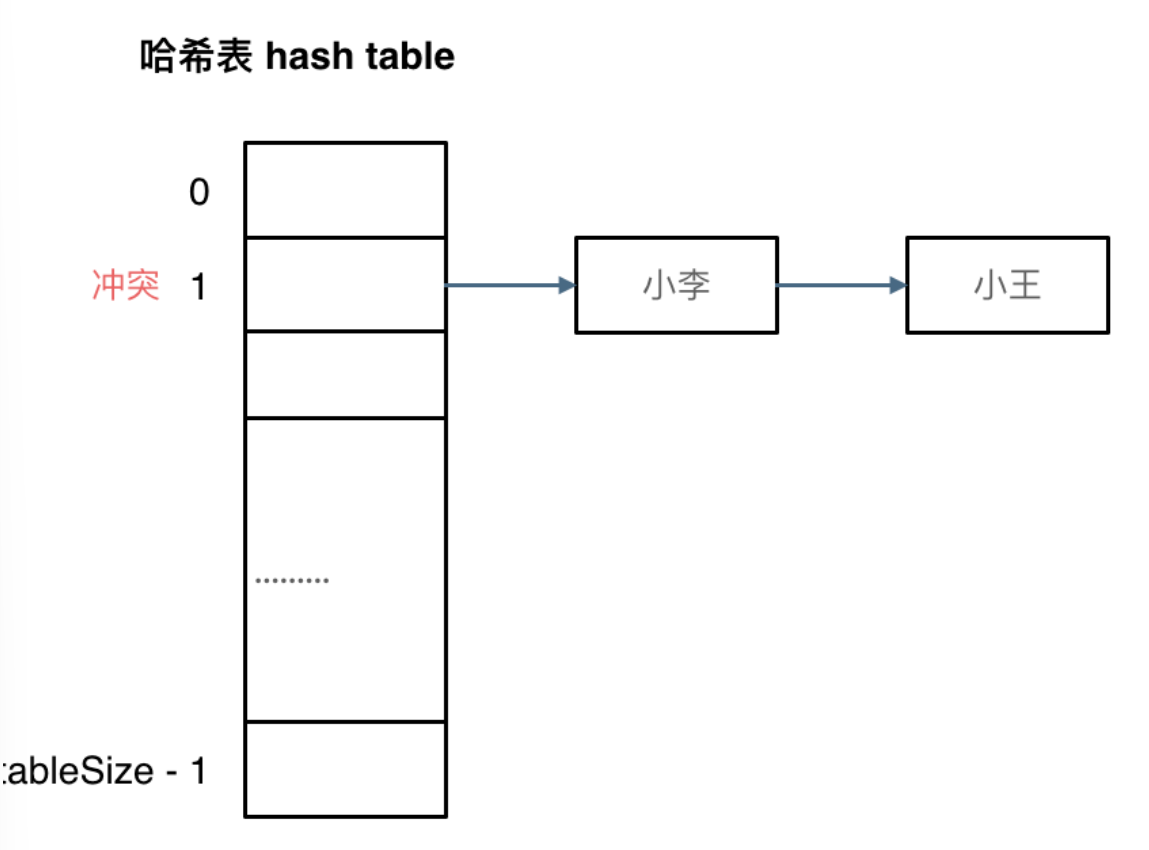
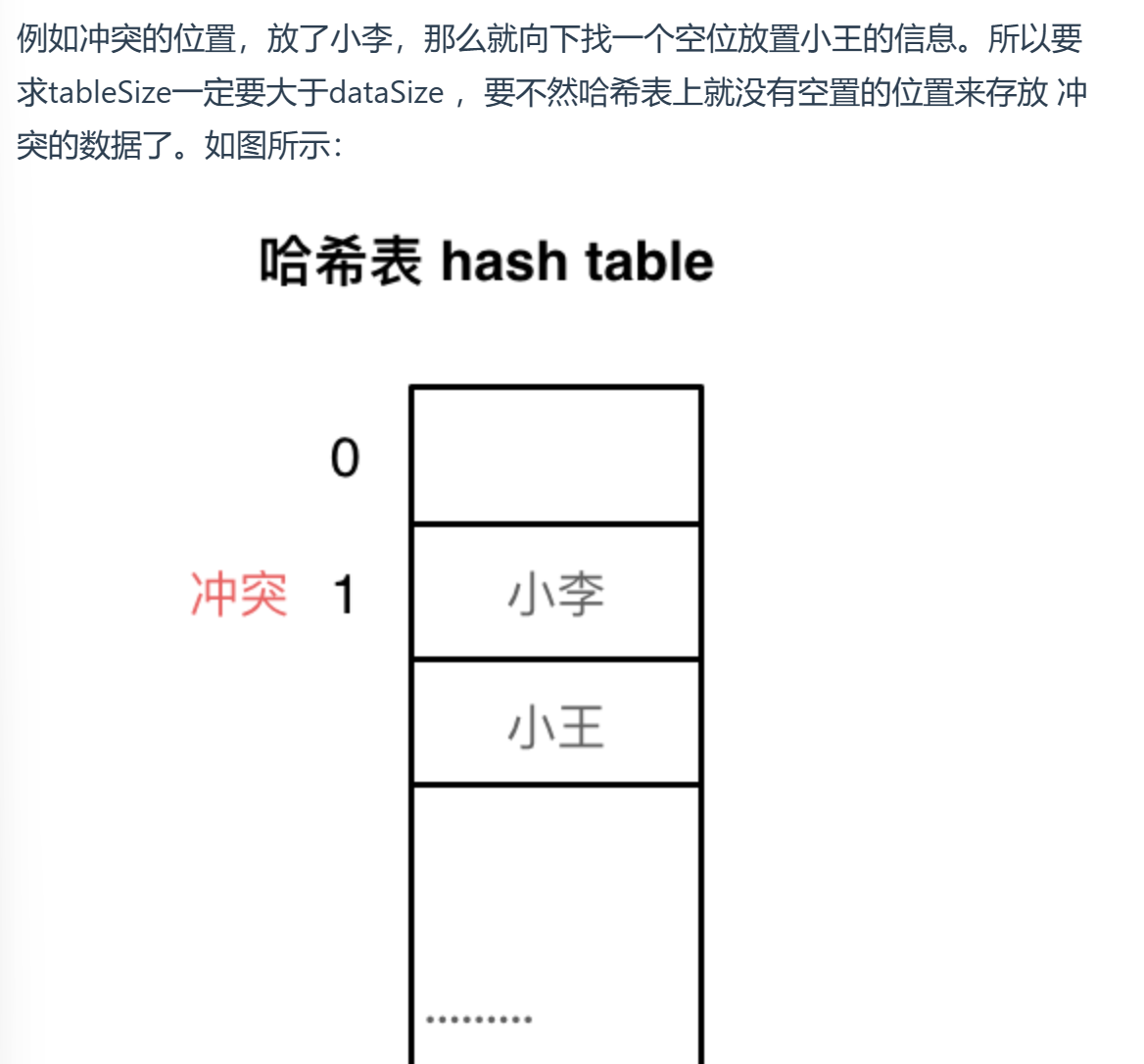
线性探测法:一定要保证tableSize大于dataSize,利用哈希表中的空位解决碰撞问题。
三种哈希结构
数组、set(集合)、map(映射)
set与map的共同点:
set、map都是C++的关联容器,只是通过它提供的接口对里面的元素进行访问,底层都是采用红黑树实现。
set与map的不同点:
set:用来判断一个元素是否在一个组里。
map:映射,相当于字典,把一个值映射成另一个值,可以创建字典。
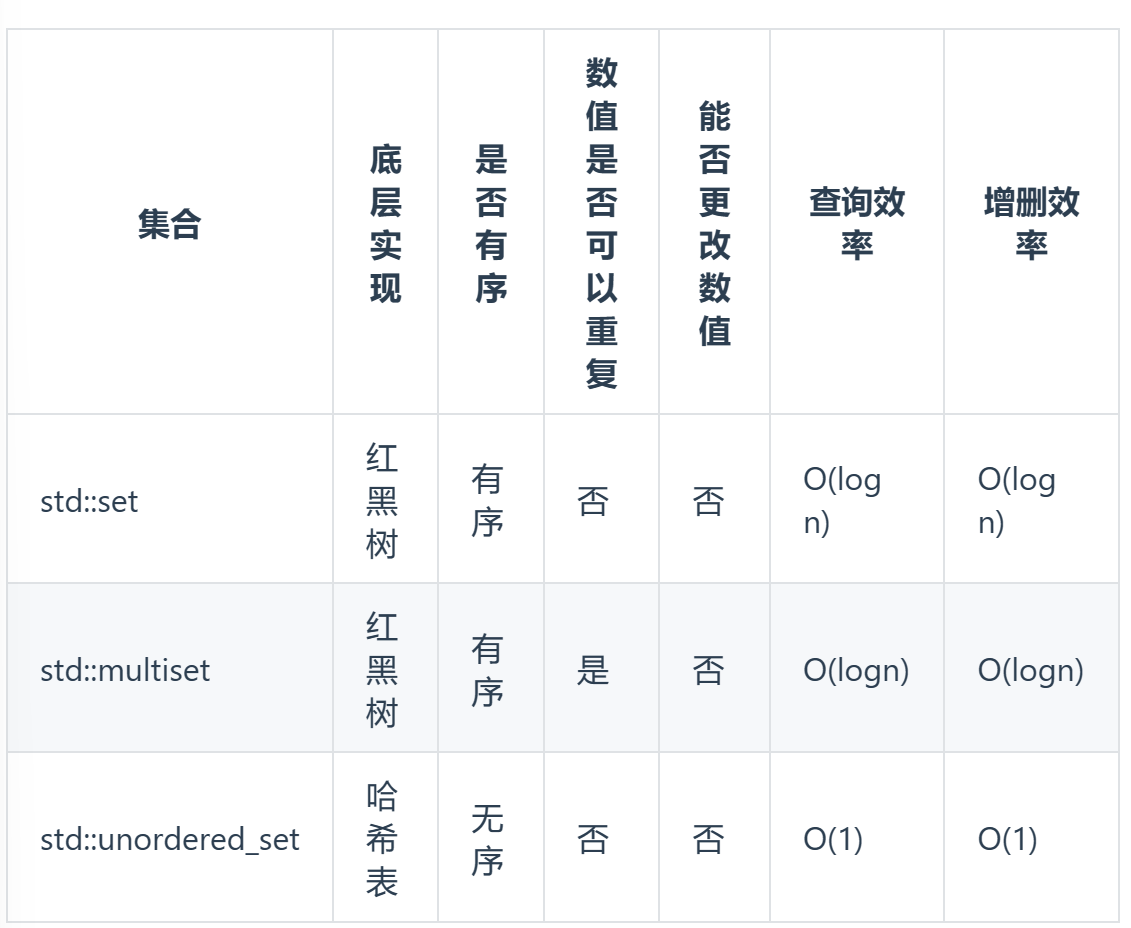
set
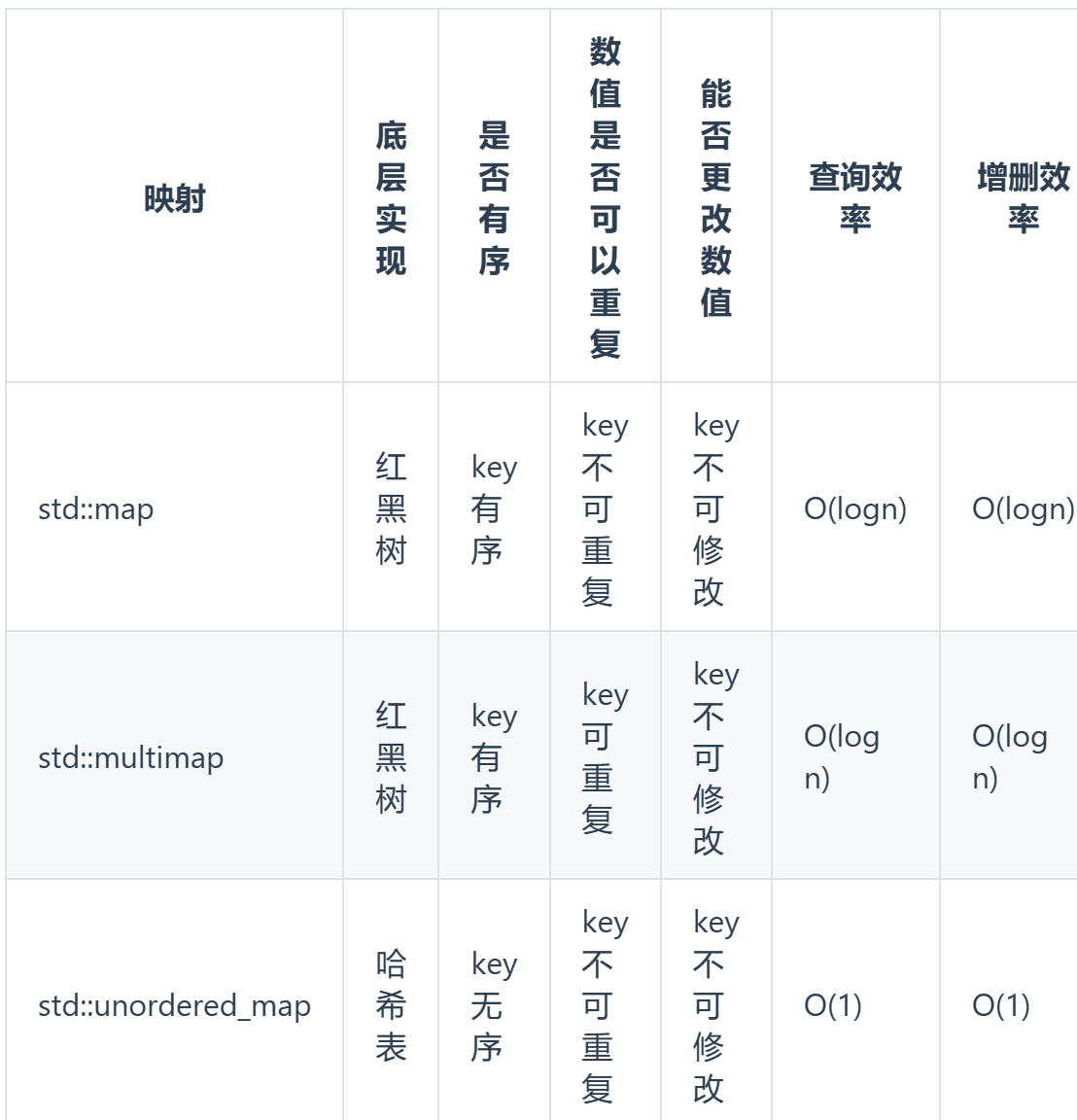
map
小结
当要用集合来解决哈希问题时,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合有序,就用set,要有重复数据,就用multiset。
1.为什么要成倍的扩容,而不是一次增加一个固定大小的容量?
保证常数的时间复杂度。
2.为什么以两倍方式扩容?
考虑可能产生的堆空间浪费,所以增长倍数不能太大。
3.为什么insert后,以前保存的iterator不会失效?
因为map和set储存的是节点,不需要内存拷贝和内存移动。但是vector在插入数据时如果内存不够,会重新开辟一块内存。map和set的iterator指向的是节点的指针,vector指向的是内存的某个位置。
4.为什么map和set的插入删除效率比其他序列容器高?
因为map和set底层实现为红黑树,插入和删除的时间复杂度为O(logn)。
例题:
有效的字母异位词(小写字母,用数组!)
赎金信(与有效的字母异位词类似)
两个数组的交集(输出结果是去重的,无序的,用unordered_set)
两个数组的交集II(哈希映射,有重复元素)
字母异位词分组(字符串排序的效果、通过设计哈希表中的键值进行归类)
快乐数(各个位上数的提取、判断是否有重复的数字出现,是否出现了死循环或者出现了1)
两数之和(经典,利用哈希查询效率高)
四数相加II(四个数组,两两分组)
//9、10使用双指针
三数之和(双指针法,对三个元素的去重)
四数之和(与三数之和类似,在一级剪枝时,判断条件要注意,nums[i]>0且target>0,对各个元素进行去重)
![[js基础]ECMAScript2015(ES6)精要知识点(下)](https://img-blog.csdnimg.cn/img_convert/7eca13bc94c7d514ba0e2b2705cd5229.png)