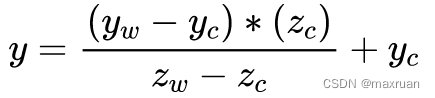文章目录
- SparkSQL 核心编程
- 1、新的起点
- 2、SQL 语法
- 1) 读取 json 文件创建 DataFrame
- 2) 对 DataFrame 创建一个临时表
- 3) 通过SQL语句实现查询全表
- 3、DSL 语法
- 1) 创建一个DataFrame
- 2) 查看DataFrame的Schema信息
- 3) 只查看"username"列数据
- 4) 查看"username"列以及"age"+1数据
- 5) 查看"age"大于"20"的数据
- 6) 按照"age"分组,查看数据条数
- 4、RDD 转换为 DataFrame
- 5、DataSet
- 1) 创建 DataSet
- 2) DataFrame 转换为 DataSet
- 3)RDD 直接转换为 DataSet
SparkSQL 核心编程
学习如何使用 Spark SQL 提供的 DataFrame 和 DataSet 模型进行编程,以及了解他们之间的关系和转换,关于具体的SQL书写不是我们的重点。
1、新的起点
Spark Core 中,如果想要执行应用程序,需要首先构建上下文环境对象,SparkContext,Spark SQL 其实可以理解为对 Spark Core的一种封装,不仅仅在模型上进行了封装,上下文环境对象也进行了封装。
在老的版本中,SparkSQL提供两种 SQL 查询起始点,一个叫 SQLContext,用于 Spark 自己提供的 SQL 查询,一个叫 HiveContext,用于连接 Hive 查询。
SparkSession 是 Spark 最新的 SQL 查询起点,实质是上 SQLContext 和 HiveContext 的组合,所以在 SQLContext 和 HiveContext 上可用的API在 SparkSession 上同样是可以使用的。SparkSession 内部封装了 SparkContext,所以实际上是由sparkContext 完成的。当我们使用 spark-shell 的时候,spark 框架会自动创建一个名称叫做spark的SparkSession对象,就像我们以前可以自动获取到一个sc来表示SparkContext对象一样。
这下面是在终端命令行简单的演示,是怎么用spark 执行sql语句执行的。
读取json文件创建DataFrame:
val df = spark.read.json("input/user.json")

注意:
从内存中获取数据,spark 可以知道数据具体是什么。如果是数字,默认作为 Int 处理,但是从文件中读取的数字,不能确定是什么类型,所以用 bigint(大整形) 接收,可以和 Long 类型转换,但是和 Int 不能进行转换。
2、SQL 语法
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助。
1) 读取 json 文件创建 DataFrame

2) 对 DataFrame 创建一个临时表
要想用sql语句,那肯定首先就要有个表,所以将DataFrame转换为一个临时表,就可以用sql语句了。创建临时表使用 createReplaceTempView("pepole"),创建临时视图使用 createTempView("pepole")

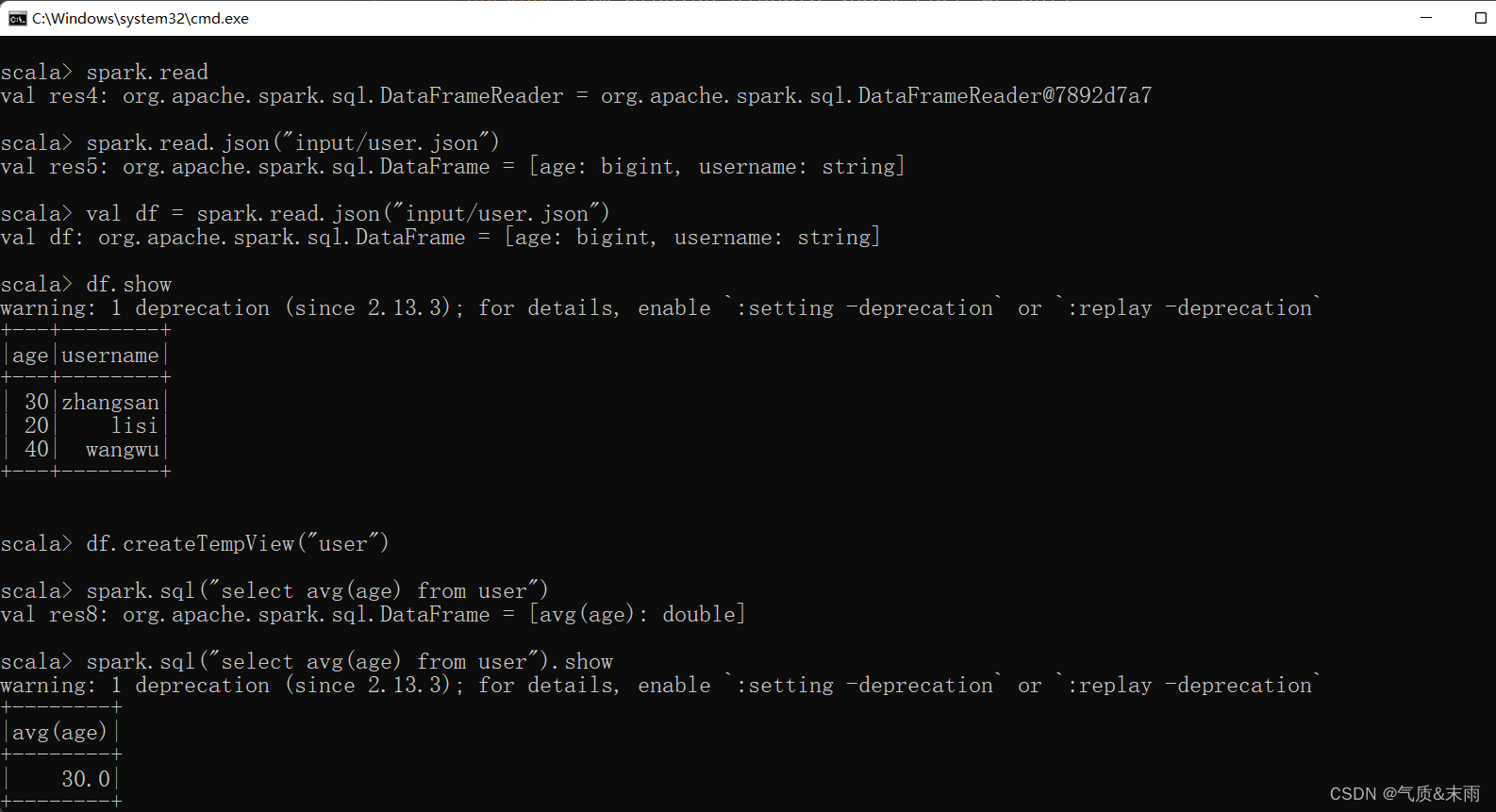
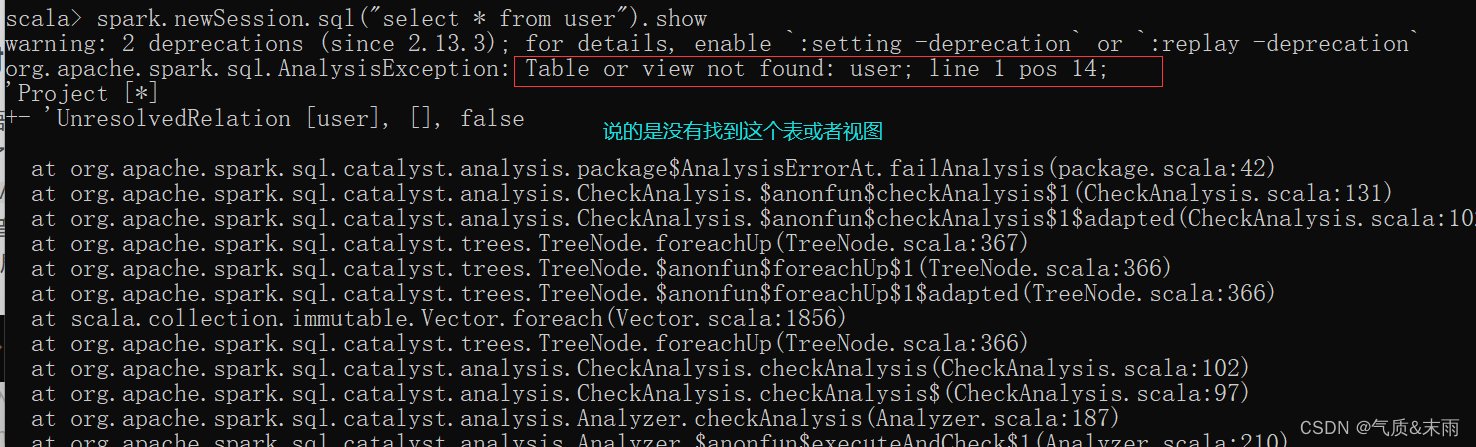
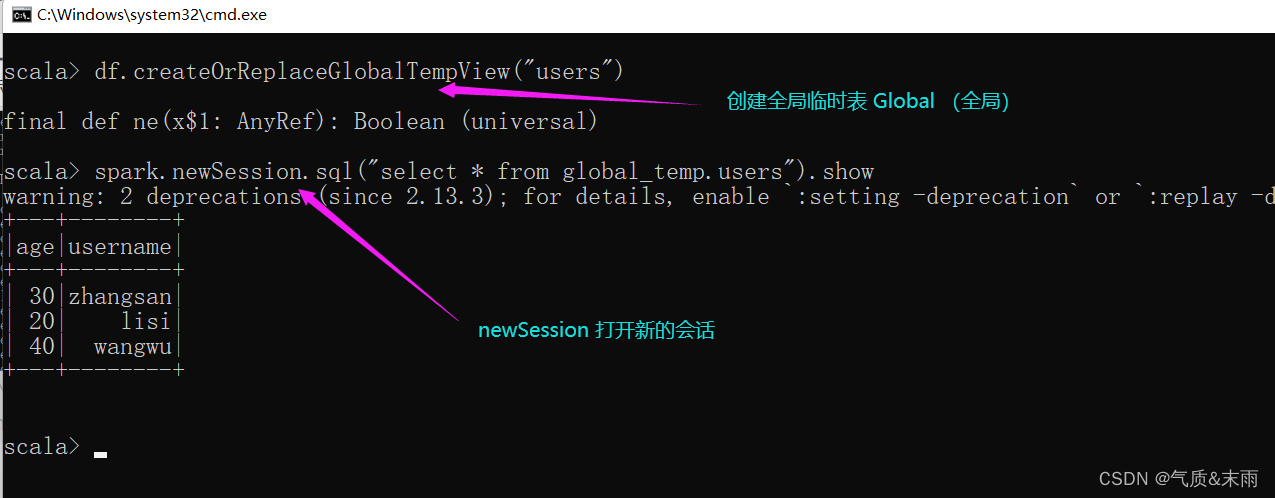
注意:普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问。
比如下面这里就是newSession 开启了一个新的会话,之前那个临时表就用不了了,找不到。
3) 通过SQL语句实现查询全表
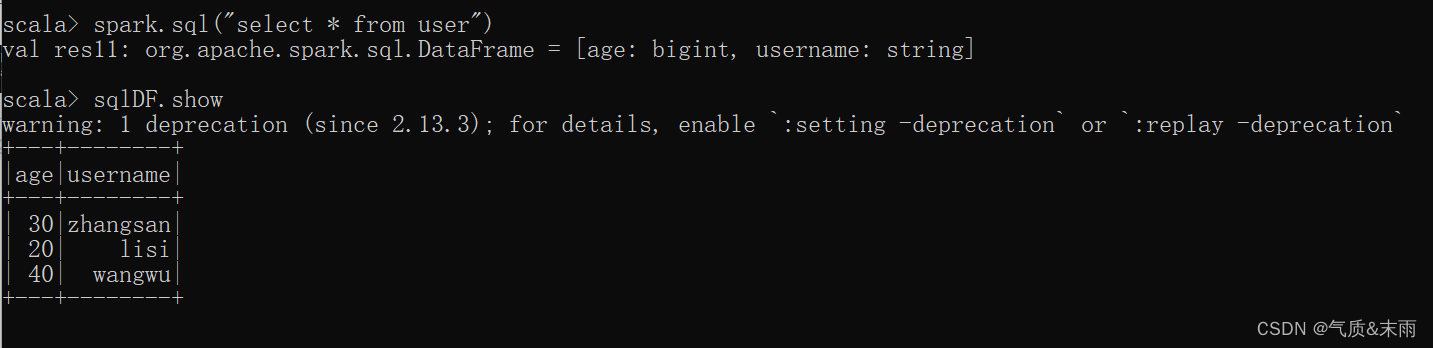
spark 查询语句:spark.sql("select * from user") 这个user就是上面创建的临时视图,必须要创建个这样的对象,才能进行sql 语句查询。

这个就是查询的结果
3、DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language,DSL)去管理结构化数据。可以在 Scala,Java,Python,和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了。
1) 创建一个DataFrame
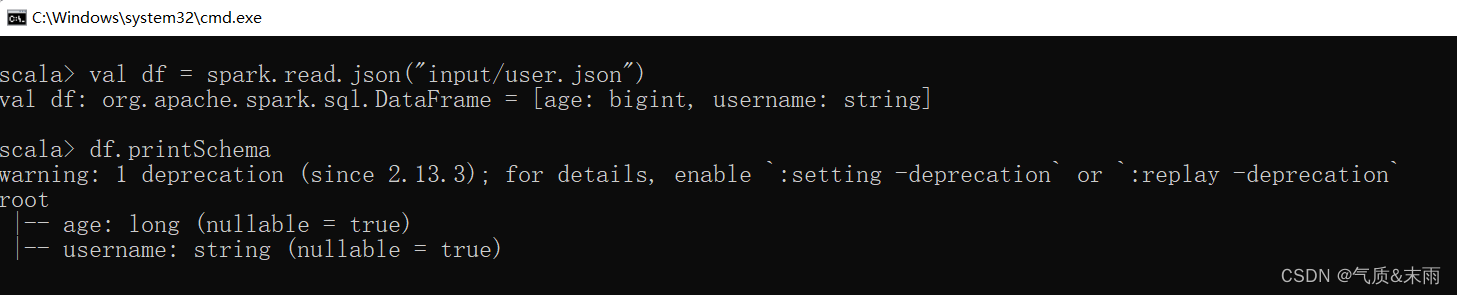
val df = spark.read.json("input/user.json")

2) 查看DataFrame的Schema信息
df.printSchema 用这个看到看信息,说明spark的那些方法都是可以用的。
这里可以看到,这种DSL 不需要创建什么表,这个是可以直接用 DataFrame对象直接进行select的查询
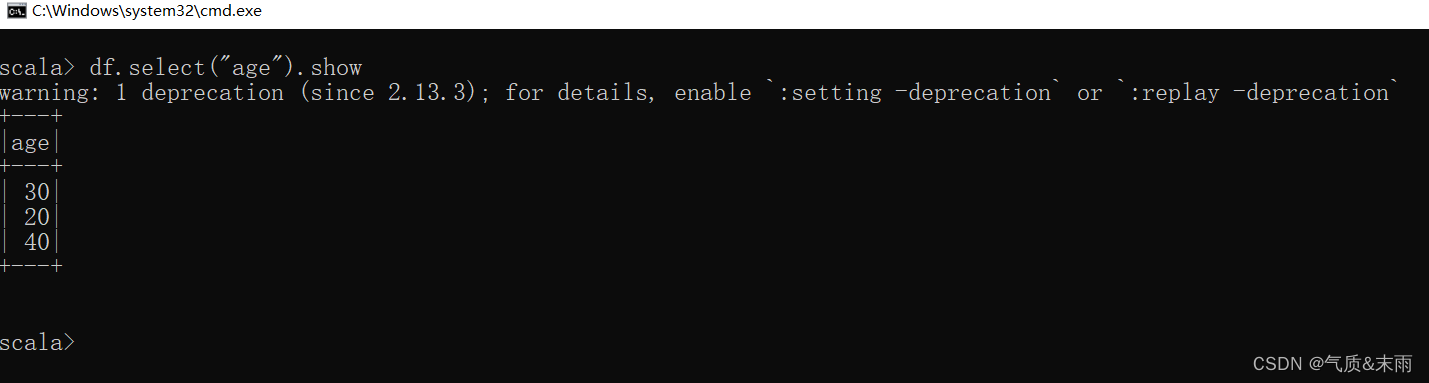
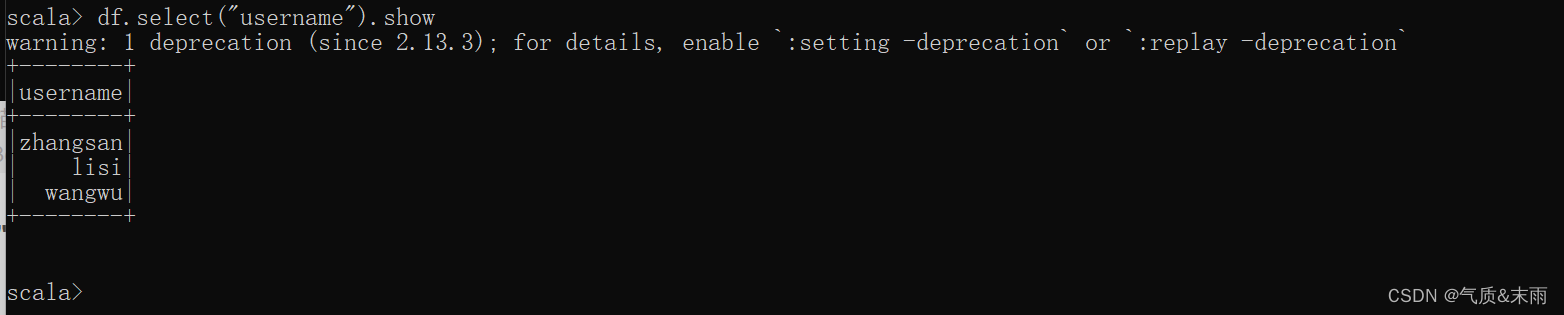
3) 只查看"username"列数据
df.select("username").show
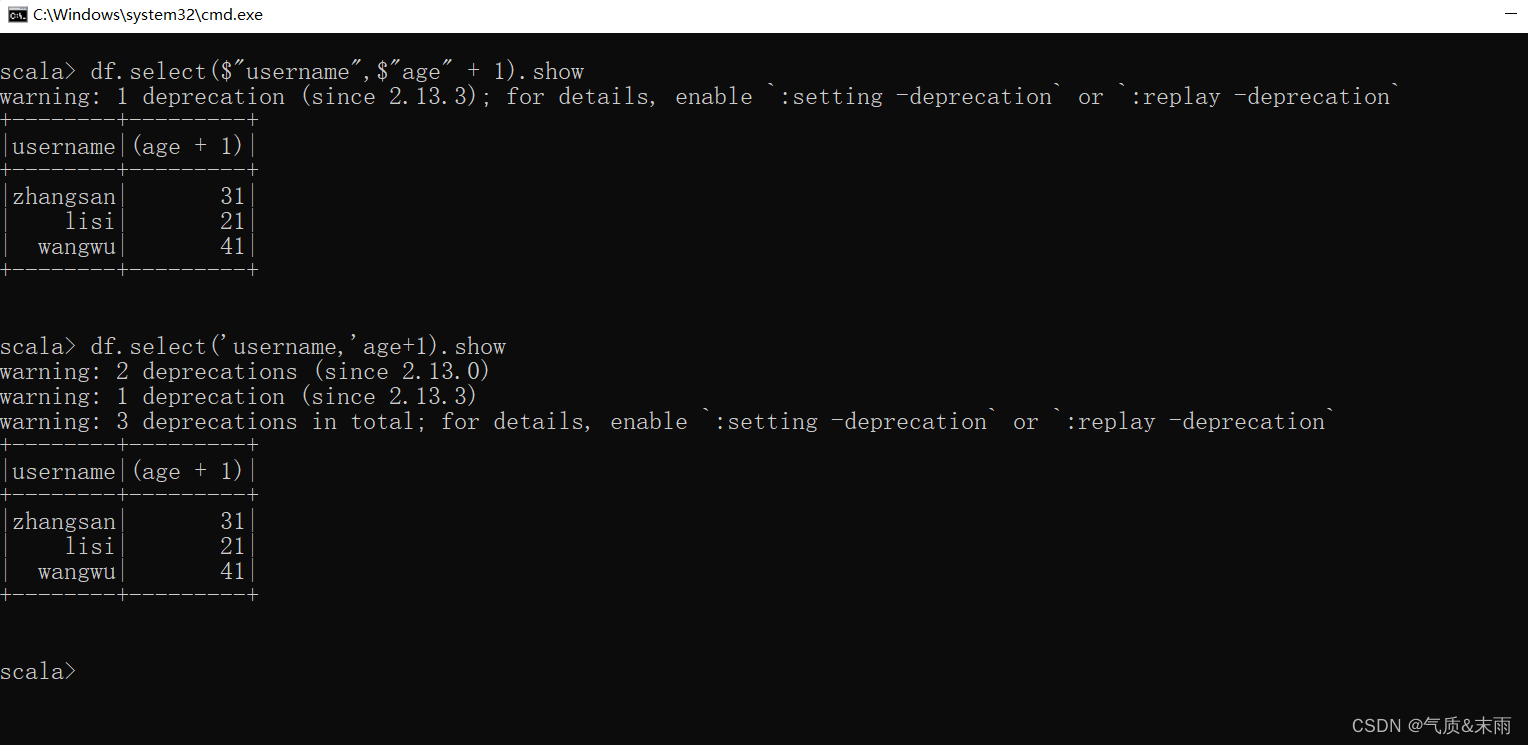
4) 查看"username"列以及"age"+1数据
df.select($"username",$"age" + 1)
df.select('username,'age + 1)
注意:涉及到运算的时候,每列都必须使用$,或者采用引号表达式:单引号+字段名

或者不要双引号,在每个字段的前面加上一个单引号也是可以的。
5) 查看"age"大于"20"的数据
就不是select了,使用filter进行筛选过滤。
df.filter($"age">20).show
注意:这里这个大于20,上面那个20+1那个是不算的。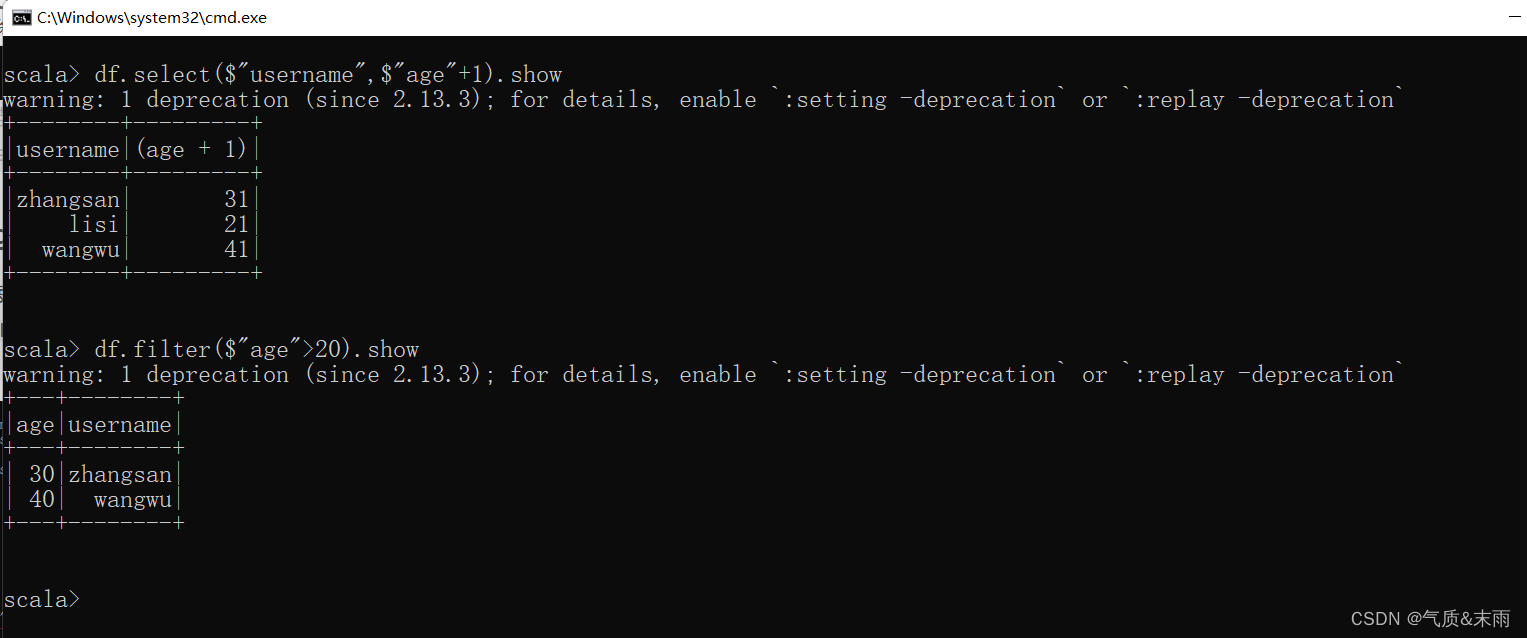
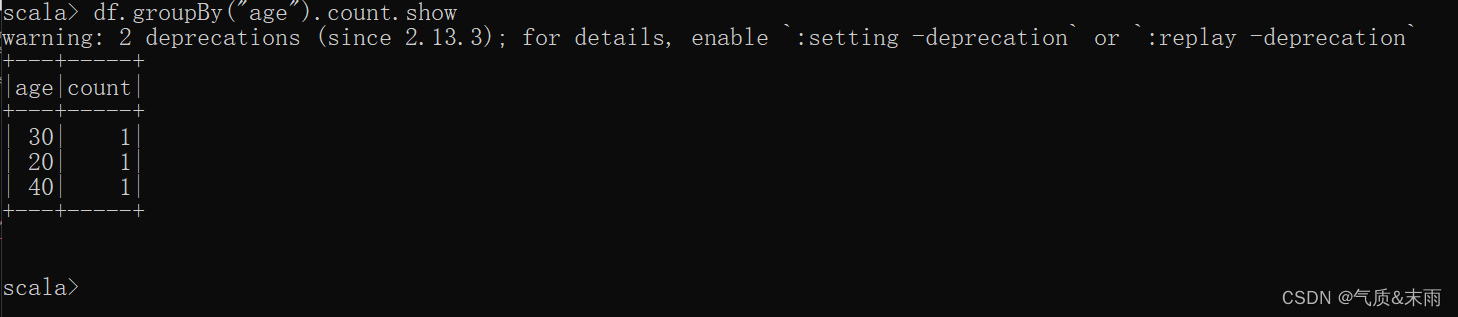
6) 按照"age"分组,查看数据条数
使用groupBy,分组完还必要要用count统计
df.groupBy("age").count.show
4、RDD 转换为 DataFrame
在 IDEA 开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入import spark.implicits._
这里的 spark 不是 Scala 中的包名,而是创建的sparkSession 对象的变量名称,所以必须先创建 SparkSession 对象再导入。这里的 spark 对象那个不能那个使用 var 声明,因为Scala 只支持 val 修饰的对象的引入。
spark-shell 中无需导入,自动完成此操作。
首先创建一个rdd
val rdd = sc.makeRDD(List(1,2,3,4)) 然后可以看到下面有很多的方法,其中有一个toDF方法,就是 RDD 转换为 DataFrame的。
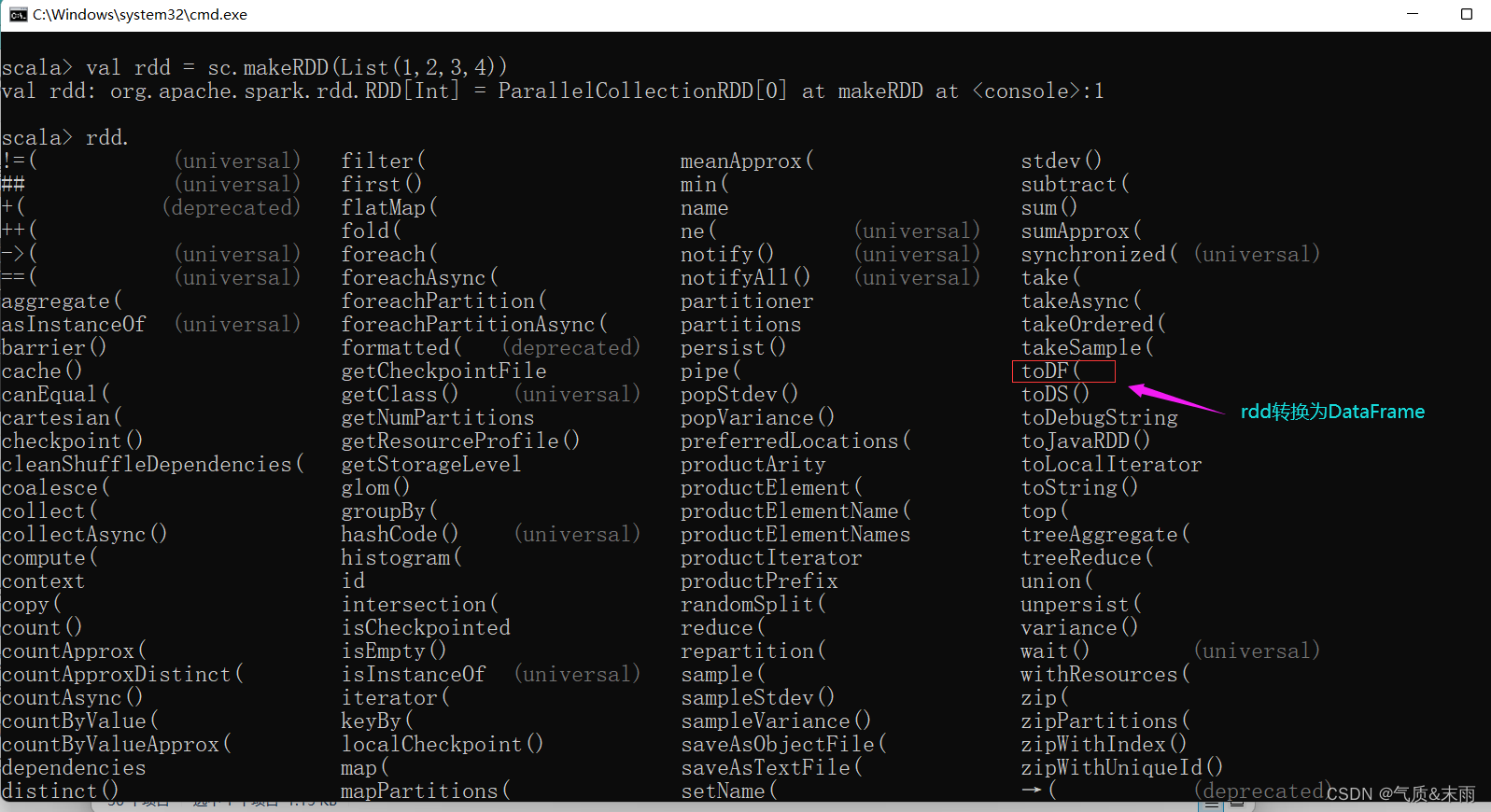
val df = rdd.toDF("id") 我们将数据转换为DataFrame 那我们得让他知道我们的数据是什么意思,所以给他一个列字段名,“id”。
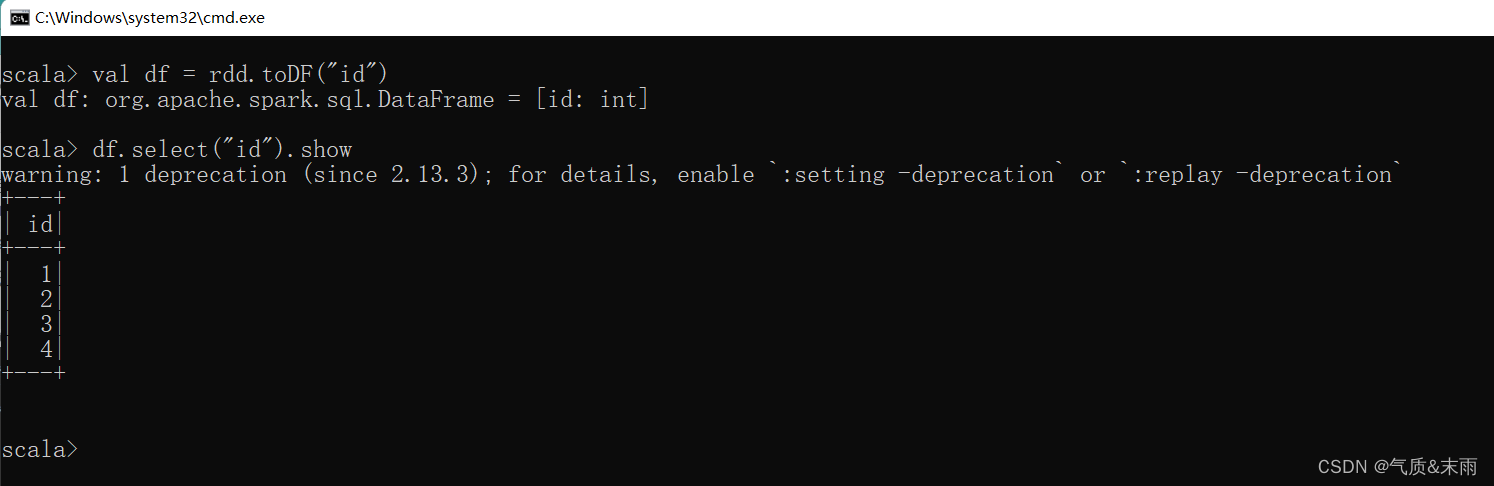
要是想从DataFrame转换回RDD的话,那么直接 df.rdd 就转换回去了。
5、DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
1) 创建 DataSet
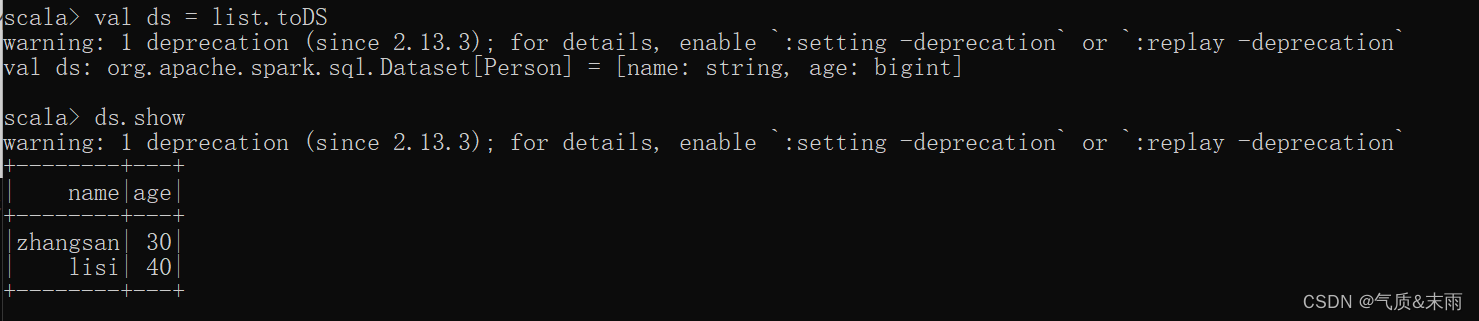
使用样例类序列创建DataSet

上面创建了一个样例类的列表的数据 ,然后直接使用toDS 方法之间转换为DataSet

转换好之后,数据就可以直接看了。
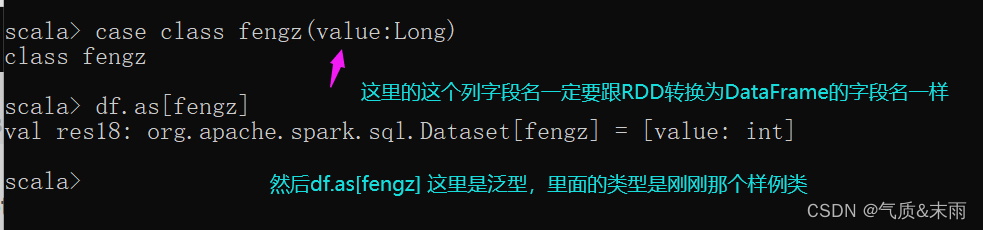
2) DataFrame 转换为 DataSet
首先从RDD转换为DataFrame使用rdd.toDF,然后我们要创建一个样例类,注意样例类里面这个列字段名要和那个DataFrame里面的那个字段名是一样的,比如这里这个是value,然后用df.as[fengz] 有了类型他就变成DataSet了。

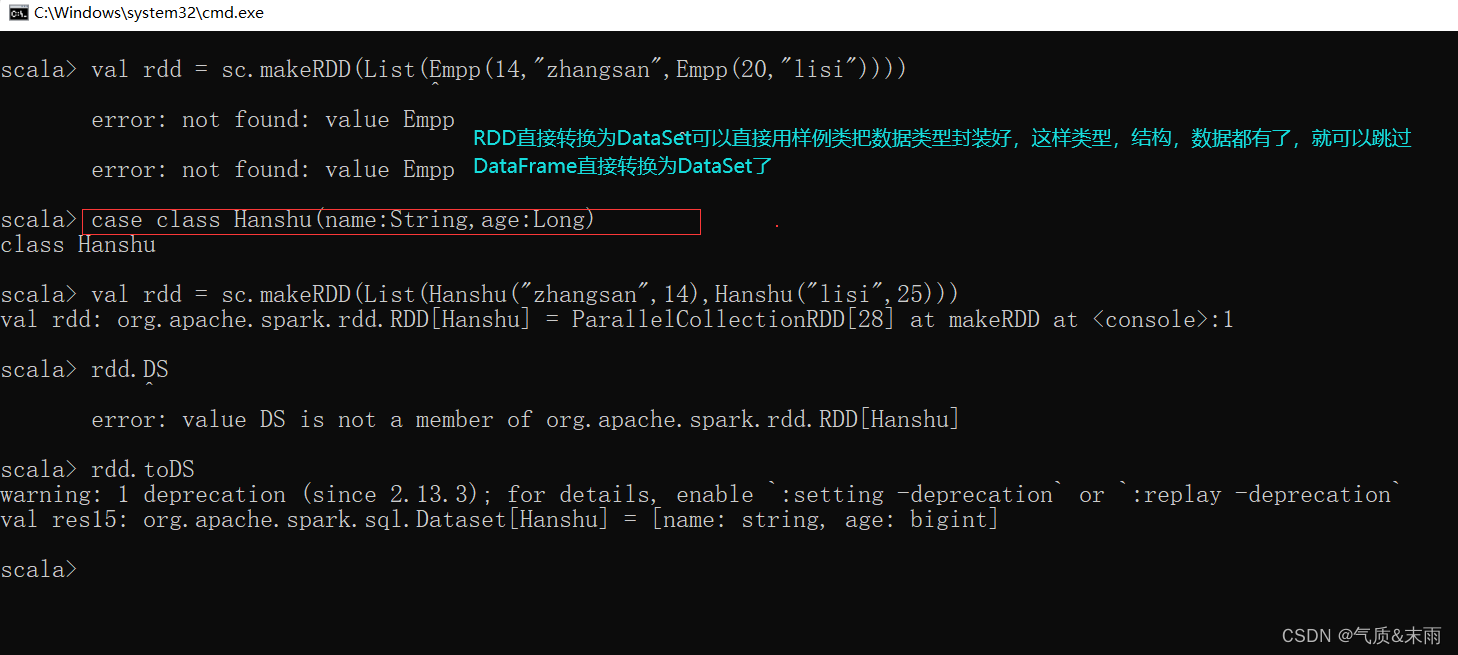
3)RDD 直接转换为 DataSet
直接先创建一个样例类,把他的类型先确定好,然后创建一个RDD,RDD里面的数据直接使用这个样例类创建,然后直接使用rdd.toDS直接就从RDD转换为DataSet了。