一、前言
上篇文章我们学习了ES的搜索辅助功能的一部分–分别是指定搜索返回的字段,搜索结果计数,分页,那么本次我们来学习一下ES的性能分析相关功能。
二、ES性能分析
在使用ES的过程中,有的搜索请求的响应比较慢,大部分原因的是DSL的执行逻辑有问题。ES提供了profile功能,该功能详细地列出例如了搜索时每一个步骤的耗时,可以帮助用户对DSL的性能进行剖析。以下将开启profilefile功能:
GET /hotel/_search
{
"profile":"true",
"query": {
"match": {
"amenities": "充电"
}
}
}
执行以上DSL后ES返回了一段比较冗长的信息,下面是省略一些信息的返回数据:
{
"took" : 11,
"timed_out" : false,
"_shards" : {...},
"hits" : {...},
"profile" : {
"shards" : [
{
"id" : "[ER773I31Sx-wJuJwJCh7Ng][hotel][0]",
"searches" : [
{
"query" : [
{ //在amenities搜索"充电",被ES拆分成两个子查询
"type" : "BooleanQuery",
"description" : "amenities:充 amenities:电",
"time_in_nanos" : 2365600, //match搜索的总耗时
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 4, //命中的文档个数
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 22200,
"match" : 4600,
"next_doc_count" : 8,
"score_count" : 4, //打分的文档个数
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 77800,
"advance_count" : 1,
"score" : 15600,
"build_scorer_count" : 2,
"create_weight" : 289900,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 1955500
},
"children" : [ //子查询
{ //子查询"amenities:充"
"type" : "TermQuery",
"description" : "amenities:充",
"time_in_nanos" : 125800, //耗时
"breakdown" : {...}
},
{ //子查询"amenities:电"
"type" : "TermQuery",
"description" : "amenities:电",
"time_in_nanos" : 29000,
"breakdown" : {...}
]
}
],
"rewrite_time" : 16500,
"collector" : [ //ES手机数据性能剖析
{
"name" : "SimpleTopScoreDocCollector",
"reason" : "search_top_hits",
"time_in_nanos" : 31900 //ES收集数据的耗时
}
]
}
],
"aggregations" : [ ] //聚合性能剖析,本次搜索无聚合,因此数据为空
}
]
}
}
如上所示,在带有profile的返回信息中,除了包含搜索结果外,还包含profile子句,在该子句中展示了搜索过程中各个环节的名称及耗时情况。需要注意的是,使用profile功能是有资源损耗的,建议用户只在前期调试的时候使用该功能,在生产中不要开启profile功能。
在java客户端中,我们可以通过SearchSourceBuilder.profile(true)开启profile性能分析。
因为一个搜索可能会跨越多个分片,所以使用shards数组放在profile子句中。每个shard子句中包含3个元素,分别是id、searches和aggregations。
- id表示分片的唯一标识,它的组成形式为[nodeID][indexName][shardID].
- searches以数组的形式存在,因为有的搜索请求会跨多个索引进行搜索。每一个search子元素即为在同一个索引中的子查询,此处不仅返回了该search子元素耗时为2365600ns的信息,而且还返回了搜索"充电"的详细策略,即被拆分成"amenities:充"和"amenities:电"两个子查询。同理,children子元素给出了"amenities:充"和"amenities:电"的耗时和详细搜索步骤的耗时,此处不再赘述。
- aggregations只有在进行聚合运算时才有内容,这个之后学习聚合的时候会再次提及
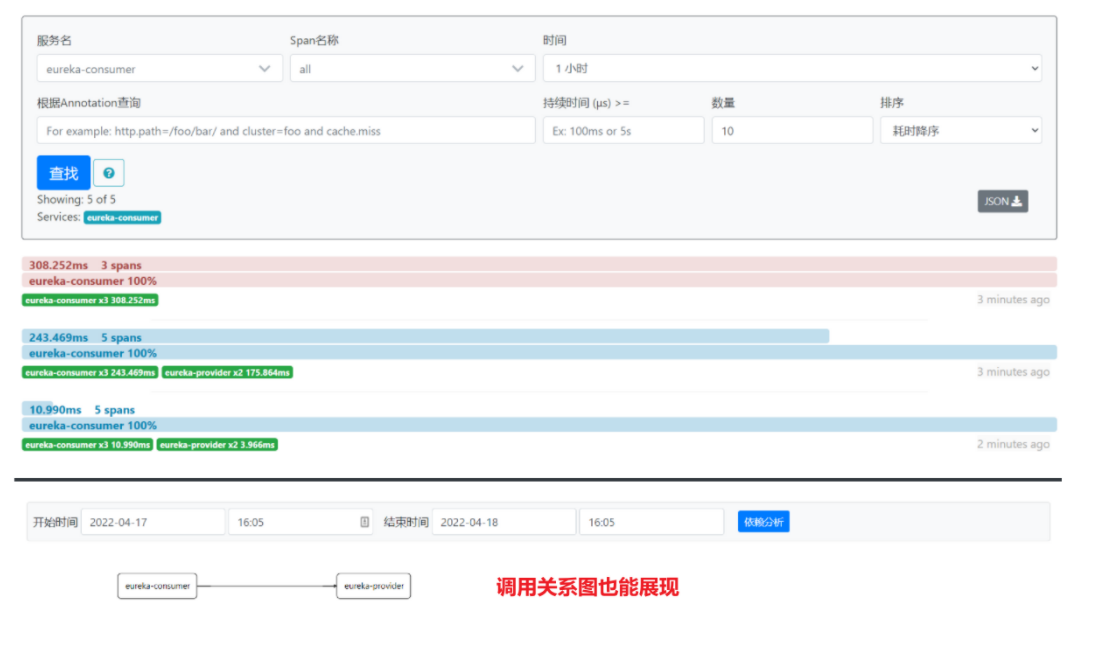
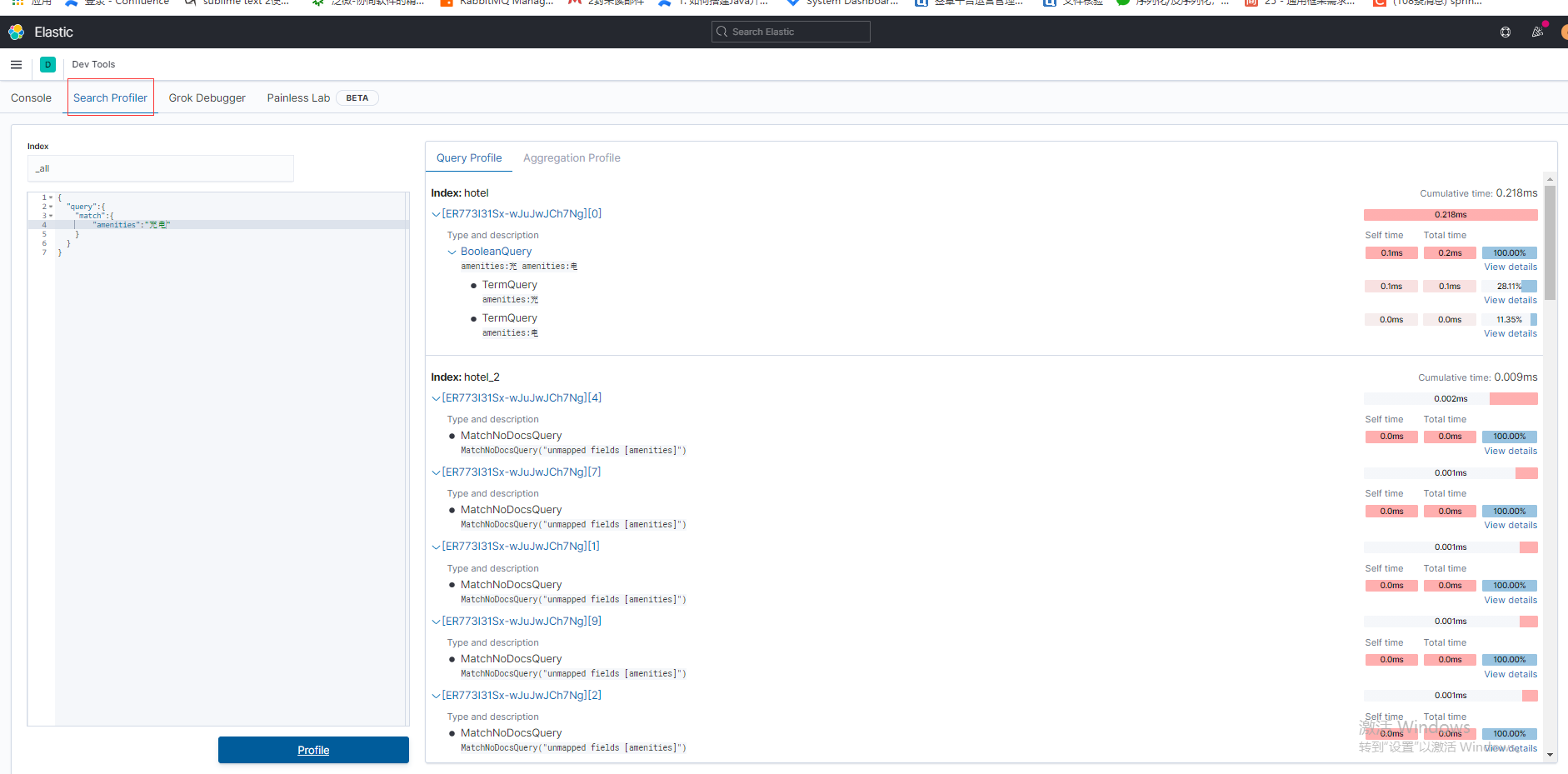
上面只是一个很简单的例子,如果查询比较复杂或者命中的分片比较多,profile返回的信息将特别冗长。在这种情况下,用户进行性能剖析的效率将非常低。为此,Kibana提供了可视化的profile功能,该功能建立在ES的profile功能基础上。在Kibana的DEV Tools界面中单击Search Profiler链接,就可以使用可视化的profile了,输入刚才在控制台输入的DSL,其区域布局如下图:
三、ES评分分析
在使用搜索引擎时,一般都会涉及排序功能,如果用户不指定按照某个字段进行升序或者降序排列,那么ES会使用自己的打分算法对文档进行排序。有时我们需要知道某个文档的具体的打分详情,以便于对搜索DSL问题进行排查。ES提供了explain功能来帮助使用者查看搜索时的匹配详情。explain的使用形式如下:
GET /${index_name}/_explain/${doc_id}
{
"query": {
...
}
}
以下示例为按照标题进行搜索的explain查询请求:
GET /hotel/_explain/002
{
"query": {
"match": {
"amenities": "充电"
}
}
}
执行上述explain查询请求后,ES返回信息如下:
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"matched" : true,
"explanation" : { //"amenities": "充电"被拆分成两个子查询
"value" : 0.56802404,
"description" : "sum of:",
"details" : [
{ //子查询"amenities": "充"的具体匹配过程
"value" : 0.28401202,
"description" : "weight(amenities:充 in 6) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.28401202, //子查询"amenities": "充"的匹配得分
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
...,
...,
...
]
}
]
},
{ //子查询"amenities": "电"的具体匹配过程
"value" : 0.28401202,
"description" : "weight(amenities:电 in 6) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.28401202, //子查询"amenities": "电"的匹配得分
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
...,
...,
...
]
}
]
}
]
}
]
}
}
上面的内容将返回结果省略了,可以看到,explain返回的信息比较全面,关于每一项内容在之后的篇章中会进行讲解。
另外,如果一个文档和查询不匹配,explain也会直接将返回信息告知用户,具体如下:
{
"_index" : "hotel", //搜索的索引
"_type" : "_doc",
"_id" : "002",
"matched" : false, //没有命中的文档
"explanation" : {
"value" : 0.0,
"description" : "no matching term",
"details" : [ ] //命中的文档集合为空
}
}