Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙。
当我们真正进入到Lucene源代码之中的时候,我们会发现:
Lucene的索引过程,就是按照全文检索的基本过程,将倒排表写成此文件格式的过程。
Lucene的搜索过程,就是按照此文件格式将索引进去的信息读出来,然后计算每篇文档打分(score)的过程。
本文详细解读了Apache Lucene - Index File Formats(http://lucene.apache.org/java/2_9_0/fileformats.html) 这篇文章。
一、基本概念
下图就是Lucene生成的索引的一个实例:
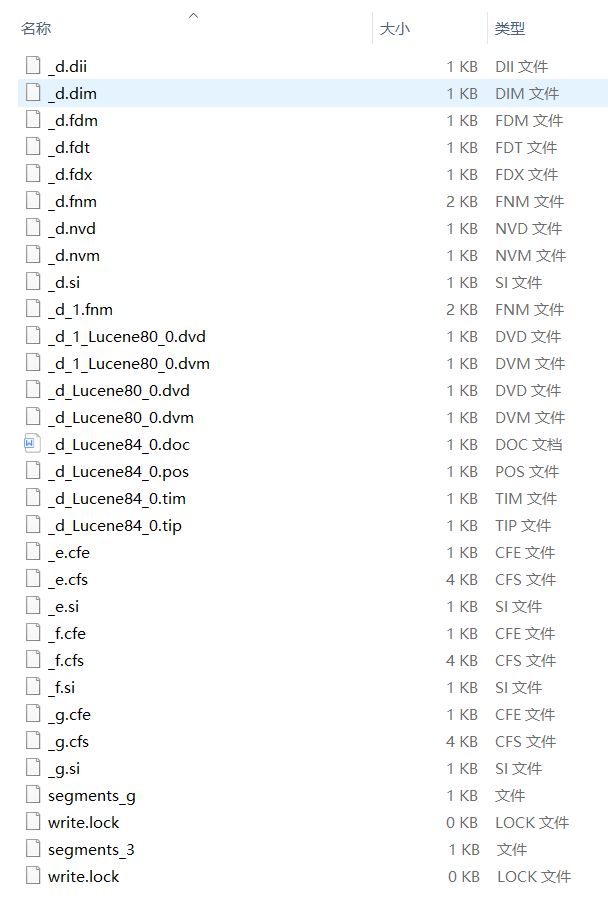
Lucene的索引结构是有层次结构的,主要分以下几个层次:
索引(Index):
在Lucene中一个索引是放在一个文件夹中的。
如上图,同一文件夹中的所有的文件构成一个Lucene索引。
段(Segment):
一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。
如上图,具有相同前缀文件的属同一个段,图中共四个段 "_d","_e","_f","_g"。
segments.gen和segments_3是段的元数据文件,也即它们保存了段的属性信息。
文档(Document):
文档是我们建索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档。
新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
域(Field):
一篇文档包含不同类型的信息,可以分开索引,比如标题,时间,正文,作者等,都可以保存在不同的域里。
不同域的索引方式可以不同,在真正解析域的存储的时候,我们会详细解读。
词(Term):
词是索引的最小单位,是经过词法分析和语言处理后的字符串。
Lucene的索引结构中,即保存了正向信息,也保存了反向信息。
所谓正向信息:
按层次保存了从索引,一直到词的包含关系:索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)。
也即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词。
既然是层次结构,则每个层次都保存了本层次的信息以及下一层次的元信息,也即属性信息,比如一本介绍中国地理的书,应该首先介绍中国地理的概况,以及中国包含多少个省,每个省介绍本省的基本概况及包含多少个市,每个市介绍本市的基本概况及包含多少个县,每个县具体介绍每个县的具体情况。
如上图,包含正向信息的文件有:
segments_N保存了此索引包含多少个段,每个段包含多少篇文档,当IndexWriter执行commit()操作后,会生成一个segments_N文件,仅仅通过flush()生成的段为无效的段信息文件。
XXX.fnm保存了此段包含了多少个域,每个域的名称及索引方式。
XXX.fdx,XXX.fdt保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
XXX.tvx,XXX.tvd,XXX.tvf保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息,将文档的词向量信息写到.tvx(vector_index)跟.tvd(vector_data)文件中。
所谓反向信息:
保存了词典到倒排表的映射:词(Term) –> 文档(Document)
如上图,包含反向信息的文件有:
XXX.tis,XXX.tii保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序。
XXX.frq保存了倒排表,也即包含每个词的文档ID列表。
XXX.prx保存了倒排表中每个词在包含此词的文档中的位置。
其他信息,暂时未知归属于上述哪一类:
XXX.nvd,XXX.nvm用来存储域的标准化值(normalization values),这两个索引文件记录了每一篇文档中每一种域的标准化值跟索引信息。
XXX.pos,XXX.pay:position在Lucene中描述的是一个term在一篇文档中的位置,并且存在一个或多个position。
索引文件.doc中按块(block)的方式存放了每一个term的文档号、词频,并且保存skip data来实现块之间的快速跳转。payload是一个自定义的元数据(mete data)来描述term的某个属性,term在一篇文章中的多个位置可以一一对应多个payload,也可以只有部分位置带有payload。offset是一对整数值(a pair of integers),即startOffset跟endOffset,它们分别描述了term的第一个字符跟最后一个在文档中的位置。每一个term在所有文档中的position、payload、offset信息在IndexWriter.addDocument()的过程中计算出来,在内存中生成一张倒排表,最终持久化到磁盘时,通过读取倒排表,将position信息写入到.pos文件中,将payload、offset信息写入到.pay文件中。
XXX.tim(TermDictionary)文件中存放了每一个term的TermStats,TermStats记录了包含该term的文档数量,term在这些文档中的词频总和;另外还存放了term的TermMetadata;TermMetadata记录了该term在.doc、.pos、.pay文件中的信息,这些信息即term在这些文件中的起始位置,即保存了指向这些文档的索引;还存放了term的Suffix,对于有部分相同前缀值的term,只需存放这些term不相同的后缀值,即Suffix。
XXX.tip文件中存放了指向tim文件的索引来实现随机访问tim文件中的信息,并且.tip文件还能用来快速判断某个term是否存在。
XXX.dim,XXX.dii:从Lucene6.0开始出现点数据(Point Value)的概念,通过将多维度的点数据生成KD-tree结构,来实现快速的单维度的范围查询(比如 IntPoint.newRangeQuery)以及N dimesional shape intersection filtering。
索引文件.liv只有在一个segment中包含被删除的文档时才会生成,它记录了当前段中没有被删除的文档号。
当生成一个新的segment时(执行flush、commit、merge、addIndexes(facet)),会生成一个描述段文件信息(segmentInfo)的.si索引文件。
索引文件XXX.cfs,XXX.cfe被称为复合(compound)索引文件,在IndexWriterConfig可以配置是否生成复合索引文件,默认开启。
在了解Lucene索引的详细结构之前,先看看Lucene索引中的基本数据类型。
二、基本类型
Lucene索引文件中,用一下基本类型来保存信息:
Byte:是最基本的类型,长8位(bit)。
UInt32:由4个Byte组成。
UInt64:由8个Byte组成。
VInt:
变长的整数类型,它可能包含多个Byte,对于每个Byte的8位,其中后7位表示数值,最高1位表示是否还有另一个Byte,0表示没有,1表示有。
越前面的Byte表示数值的低位,越后面的Byte表示数值的高位。
例如130化为二进制为 1000, 0010,总共需要8位,一个Byte表示不了,因而需要两个Byte来表示,第一个Byte表示后7位,并且在最高位置1来表示后面还有一个Byte,所以为(1) 0000010,第二个Byte表示第8位,并且最高位置0来表示后面没有其他的Byte了,所以为(0) 0000001。

Chars:是UTF-8编码的一系列Byte。
String:一个字符串首先是一个VInt来表示此字符串包含的字符的个数,接着便是UTF-8编码的字符序列Chars。
三、基本规则
Lucene为了使的信息的存储占用的空间更小,访问速度更快,采取了一些特殊的技巧,然而在看Lucene文件格式的时候,这些技巧却容易使我们感到困惑,所以有必要把这些特殊的技巧规则提取出来介绍一下。
在下不才,胡乱给这些规则起了一些名字,是为了方便后面应用这些规则的时候能够简单,不妥之处请大家谅解。
1. 前缀后缀规则(Prefix+Suffix)
Lucene在反向索引中,要保存词典(Term Dictionary)的信息,所有的词(Term)在词典中是按照字典顺序进行排列的,然而词典中包含了文档中的几乎所有的词,并且有的词还是非常的长的,这样索引文件会非常的大,所谓前缀后缀规则,即当某个词和前一个词有共同的前缀的时候,后面的词仅仅保存前缀在词中的偏移(offset),以及除前缀以外的字符串(称为后缀)。

比如要存储如下词:term,termagancy,termagant,terminal,
如果按照正常方式来存储,需要的空间如下:
[VInt = 4] [t][e][r][m],[VInt = 10][t][e][r][m][a][g][a][n][c][y],[VInt = 9][t][e][r][m][a][g][a][n][t],[VInt = 8][t][e][r][m][i][n][a][l]
共需要35个Byte.
如果应用前缀后缀规则,需要的空间如下:
[VInt = 4] [t][e][r][m],[VInt = 4 (offset)][VInt = 6][a][g][a][n][c][y],[VInt = 8 (offset)][VInt = 1][t],[VInt = 4(offset)][VInt = 4][i][n][a][l]
共需要22个Byte。
大大缩小了存储空间,尤其是在按字典顺序排序的情况下,前缀的重合率大大提高。
2. 差值规则(Delta)
在Lucene的反向索引中,需要保存很多整型数字的信息,比如文档ID号,比如词(Term)在文档中的位置等等。
由上面介绍,我们知道,整型数字是以VInt的格式存储的。随着数值的增大,每个数字占用的Byte的个数也逐渐的增多。所谓差值规则(Delta)就是先后保存两个整数的时候,后面的整数仅仅保存和前面整数的差即可。

比如要存储如下整数:16386,16387,16388,16389
如果按照正常方式来存储,需要的空间如下:
[(1) 000, 0010][(1) 000, 0000][(0) 000, 0001],[(1) 000, 0011][(1) 000, 0000][(0) 000, 0001],[(1) 000, 0100][(1) 000, 0000][(0) 000, 0001],[(1) 000, 0101][(1) 000, 0000][(0) 000, 0001]
供需12个Byte。
如果应用差值规则来存储,需要的空间如下:
[(1) 000, 0010][(1) 000, 0000][(0) 000, 0001],[(0) 000, 0001],[(0) 000, 0001],[(0) 000, 0001]
共需6个Byte。
大大缩小了存储空间,而且无论是文档ID,还是词在文档中的位置,都是按从小到大的顺序,逐渐增大的。
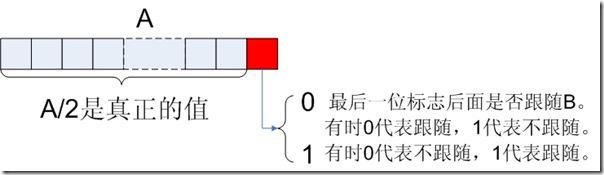
3. 或然跟随规则(A, B?)
Lucene的索引结构中存在这样的情况,某个值A后面可能存在某个值B,也可能不存在,需要一个标志来表示后面是否跟随着B。
一般的情况下,在A后面放置一个Byte,为0则后面不存在B,为1则后面存在B,或者0则后面存在B,1则后面不存在B。
但这样要浪费一个Byte的空间,其实一个Bit就可以了。
在Lucene中,采取以下的方式:A的值左移一位,空出最后一位,作为标志位,来表示后面是否跟随B,所以在这种情况下,A/2是真正的A原来的值。
如果去读Apache Lucene - Index File Formats这篇文章,会发现很多符合这种规则的:
.frq文件中的DocDelta[, Freq?],DocSkip,PayloadLength?
.prx文件中的PositionDelta,Payload? (但不完全是,如下表分析)
当然还有一些带?的但不属于此规则的:
.frq文件中的SkipChildLevelPointer?,是多层跳跃表中,指向下一层表的指针,当然如果是最后一层,此值就不存在,也不需要标志。
.tvf文件中的Positions?, Offsets?。
在此类情况下,带?的值是否存在,并不取决于前面的值的最后一位。
而是取决于Lucene的某项配置,当然这些配置也是保存在Lucene索引文件中的。
如Position和Offset是否存储,取决于.fnm文件中对于每个域的配置(TermVector.WITH_POSITIONS和TermVector.WITH_OFFSETS)
为什么会存在以上两种情况,其实是可以理解的:
对于符合或然跟随规则的,是因为对于每一个A,B是否存在都不相同,当这种情况大量存在的时候,从一个Byte到一个Bit如此8倍的空间节约还是很值得的。
对于不符合或然跟随规则的,是因为某个值的是否存在的配置对于整个域(Field)甚至整个索引都是有效的,而非每次的情况都不相同,因而可以统一存放一个标志。
文章中对如下格式的描述令人困惑: Positions --> <PositionDelta,Payload?> Freq Payload --> <PayloadLength?,PayloadData> PositionDelta和Payload是否适用或然跟随规则呢?如何标识PayloadLength是否存在呢? 其实PositionDelta和Payload并不符合或然跟随规则,Payload是否存在,是由.fnm文件中对于每个域的配置中有关Payload的配置决定的(FieldOption.STORES_PAYLOADS) 。 当Payload不存在时,PayloadDelta本身不遵从或然跟随原则。 当Payload存在时,格式应该变成如下:Positions --> <PositionDelta,PayloadLength?,PayloadData> Freq 从而PositionDelta和PayloadLength一起适用或然跟随规则。 |
4. 跳跃表规则(Skip list)
为了提高查找的性能,Lucene在很多地方采取的跳跃表的数据结构。
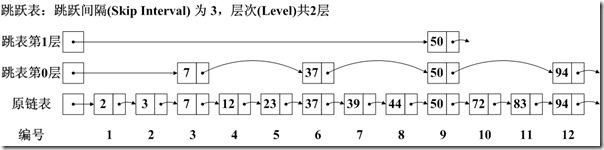
跳跃表(Skip List)是如图的一种数据结构,有以下几个基本特征:
元素是按顺序排列的,在Lucene中,或是按字典顺序排列,或是按从小到大顺序排列。
跳跃是有间隔的(Interval),也即每次跳跃的元素数,间隔是事先配置好的,如图跳跃表的间隔为3。
跳跃表是由层次的(level),每一层的每隔指定间隔的元素构成上一层,如图跳跃表共有2层。
需要注意一点的是,在很多数据结构或算法书中都会有跳跃表的描述,原理都是大致相同的,但是定义稍有差别:
对间隔(Interval)的定义: 如图中,有的认为间隔为2,即两个上层元素之间的元素数,不包括两个上层元素;有的认为是3,即两个上层元素之间的差,包括后面上层元素,不包括前面的上层元素;有的认为是4,即除两个上层元素之间的元素外,既包括前面,也包括后面的上层元素。Lucene是采取的第二种定义。
对层次(Level)的定义:如图中,有的认为应该包括原链表层,并从1开始计数,则总层次为3,为1,2,3层;有的认为应该包括原链表层,并从0计数,为0,1,2层;有的认为不应该包括原链表层,且从1开始计数,则为1,2层;有的认为不应该包括链表层,且从0开始计数,则为0,1层。Lucene采取的是最后一种定义。
跳跃表比顺序查找,大大提高了查找速度,如查找元素72,原来要访问2,3,7,12,23,37,39,44,50,72总共10个元素,应用跳跃表后,只要首先访问第1层的50,发现72大于50,而第1层无下一个节点,然后访问第2层的94,发现94大于72,然后访问原链表的72,找到元素,共需要访问3个元素即可。
然而Lucene在具体实现上,与理论又有所不同,在具体的格式中,会详细说明。