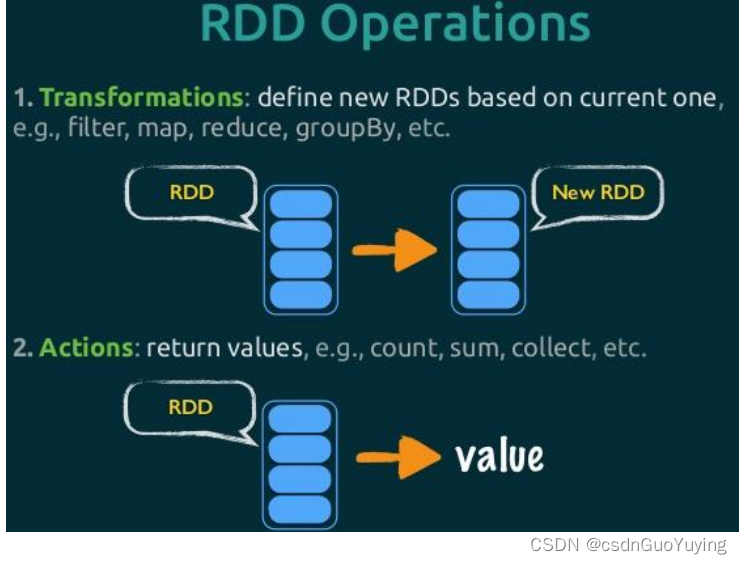
3.2 Transformation函数
在Spark中Transformation操作表示将一个RDD通过一系列操作变为另一个RDD的过程,这个操作可能是简单的加减操作,也可能是某个函数或某一系列函数。值得注意的是Transformation操作并不会触发真正的计算,只会建立RDD间的关系图。
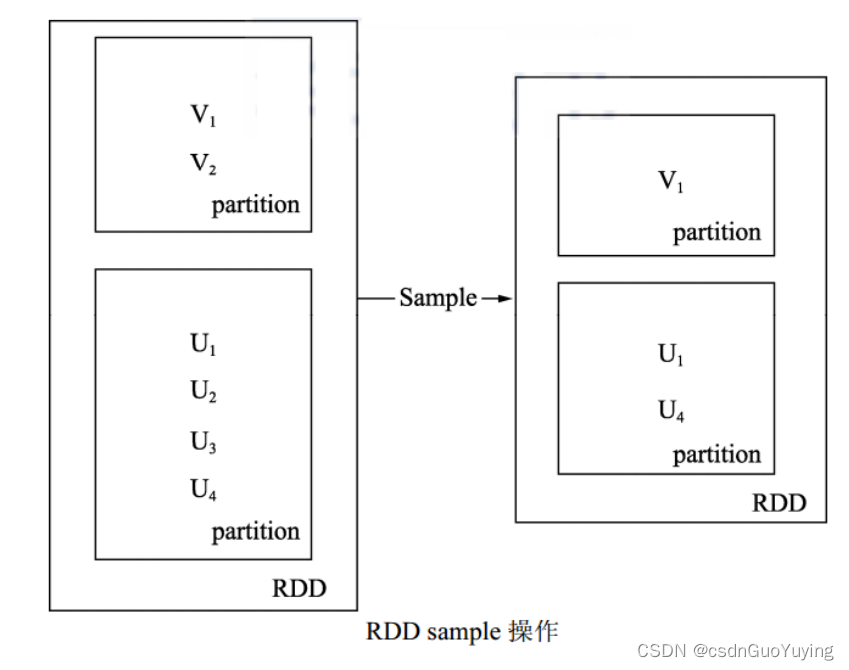
如下图所示,RDD内部每个方框是一个分区。假设需要采样50%的数据,通过sample函数,从 V1、V2、U1、U2、U3、U4 采样出数据 V1、U1 和 U4,形成新的RDD。
常用Transformation转换函数,加上底色为重要函数,重点讲解常使用函数:

3.3 Action函数
不同于Transformation操作,Action操作代表一次计算的结束,不再产生新的 RDD,将结果返回到Driver程序或者输出到外部。所以Transformation操作只是建立计算关系,而Action 操作才是实际的执行者。每个Action操作都会调用SparkContext的runJob 方法向集群正式提交请求,所以每个Action操作对应一个Job。
常用Action执行函数,加上底色为重要函数,后续重点讲解。

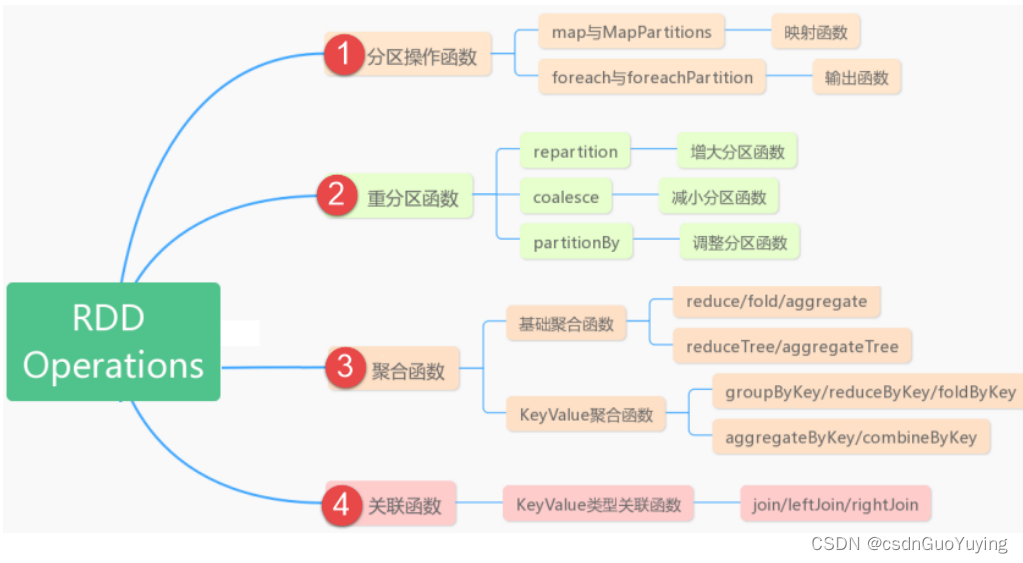
3.4 重要函数
RDD中包含很多函数,主要可以分为两类:Transformation转换函数和Action函数。
主要常见使用函数如下,一一通过演示范例讲解
基本函数
RDD中map、filter、flatMap及foreach等函数为最基本函数,都是都RDD中每个元素进行操作,将元素传递到函数中进行转换。
- map 函数:
map(f:T=>U) : RDD[T]=>RDD[U],表示将 RDD 经由某一函数 f 后,转变为另一个RDD。 - flatMap 函数:
flatMap(f:T=>Seq[U]) : RDD[T]=>RDD[U]),表示将 RDD 经由某一函数 f 后,转变为一个新的 RDD,但是与 map 不同,RDD 中的每一个元素会被映射成新的 0 到多个元素(f 函数返回的是一个序列 Seq)。 - filter 函数:
filter(f:T=>Bool) : RDD[T]=>RDD[T],表示将 RDD 经由某一函数 f 后,只保留 f 返回为 true 的数据,组成新的 RDD。 - foreach 函数:
foreach(func),将函数 func 应用在数据集的每一个元素上,通常用于更新一个累加器,或者和外部存储系统进行交互,例如 Redis。关于 foreach,在后续章节中还会使用,到时会详细介绍它的使用方法及注意事项。 - saveAsTextFile 函数:
saveAsTextFile(path:String),数据集内部的元素会调用其 toString 方法,转换为字符串形式,然后根据传入的路径保存成文本文件,既可以是本地文件系统,也可以是HDFS 等。
上述函数基本上都使用过,在后续的案例中继续使用,此处不再单独演示案例。
分区操作函数
每个RDD由多分区组成的,实际开发建议对每个分区数据的进行操作,map函数使用mapPartitions代替、foreache函数使用foreachPartition代替。

针对词频统计WordCount代码进行修改,针对分区数据操作,范例代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext, TaskContext}
/**
* 分区操作函数:mapPartitions和foreachPartition
*/
object SparkIterTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// TODO: 1、从文件系统加载数据,创建RDD数据集
val inputRDD: RDD[String] = sc.textFile("datas/wordcount/wordcount.data", minPartitions = 2)
// TODO: 2、处理数据,调用RDD集合中函数(类比于Scala集合类中列表List)
/*
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false
): RDD[U]
*/
val wordcountsRDD: RDD[(String, Int)] = inputRDD
// 将每行数据按照分隔符进行分割,将数据扁平化
.flatMap(line => line.trim.split("\\s+"))
// TODO: 针对每个分区数据操作
.mapPartitions{ iter =>
// iter 表示RDD中每个分区中的数据,存储在迭代器中,相当于列表List
iter.map(word => (word, 1))
}
// 按照Key聚合统计, 先按照Key分组,再聚合统计(此函数局部聚合,再进行全局聚合)
.reduceByKey((a, b) => a + b )
// TODO: 3、输出结果RDD到本地文件系统
wordcountsRDD.foreachPartition{ datas =>
// 获取各个分区ID
val partitionId: Int = TaskContext.getPartitionId()
// val xx: Iterator[(String, Int)] = datas
datas.foreach{ case (word, count) =>
println(s"p-${partitionId}: word = $word, count = $count")
}
}
// 应用程序运行结束,关闭资源
sc.stop()
}
}
为什么要对分区操作,而不是对每个数据操作,好处在哪里呢???
- 应用场景:处理网站日志数据,数据量为10GB,统计各个省份PV和UV。
- 假设10GB日志数据,从HDFS上读取的,此时RDD的分区数目:80 分区;
- 但是分析PV和UV有多少条数据:34,存储在80个分区中,实际项目中降低分区数目,比如设置为2个分区。