导语|腾讯工程师许扬从 QQ 提醒实际业务场景出发,阐述一个订阅推送系统的技术要点和实现思路。如何通过推拉结合、异构存储、多重触发、可控调度、打散执行、可靠推送等技术,实现推送可靠性、推送可控性和推送高效性?本篇为你详细解答。
目录
1 业务背景与诉求
1.1 业务背景
1.2 技术诉求
2 实现方案
2.1 推拉结合
2.2 异构存储
2.3 多重触发
2.4 可控温度
2.5 打散执行
2.6 引入消息队列
2.7 At least once推送
2.8 容灾方案
3 总结
01
业务背景与诉求
1.1 业务背景
QQ服务了大量的移动互联网用户。作为一个超大流量的平台,其订阅提醒功能无论对于用户还是业务方而言,都发挥着至关重要的作用。QQ提醒的业务场景非常多样,举个例子,《使命与召唤》手游在某日早上 10 点发布, QQ则提醒预约用户下载并领取礼包;春节刷一刷领红包在小年当天晚上8点05分开始, QQ 则提醒订阅用户参与。
QQ提醒整体业务实现流程是:
-
业务方在管理端建立推送任务;
-
用户在终端订阅推送任务;
-
预设时间到时,通过消息服务给所有订阅的用户推送消息。
1.2 技术诉求
不难看出,这是一个通过预设时间触发的订阅推送系统, QQ 团队期望它能达到的技术要点涉及 3 个方面。
-
推送可靠性:任何业务方在系统上配置的任务,都应该得到触发;任何订阅了提醒任务的用户,都应该收到推送消息。
-
推送可控性:消息服务的容量是有上限的,系统的总体消息推送速率不能超过该上限。而业务投放的任务却有一定随机性,可能某一时刻没有任务,可能某一时刻多个任务同时触发。所以系统必须在总体上做速率把控,避免推送过快导致下游处理失败,影响业务体验。如果造成下游消息服务雪崩,后果不堪设想。
-
推送高效性:QQ 团队规划提高系统的推送速度,以满足业务的更高时效性的要求。实际上, QQ 团队的业务场景下做高并发是相对简单的,而做到高可靠和可控反而较复杂。话不多说,下面谈谈 QQ 团队如何实现这些技术要点。
02
实现方案
以下是整体架构图,供各位读者进行宏观了解。接下来讲8个重点实现思路。

2.1 推拉结合
首先给各位读者抛出一个疑问:提醒推送系统一定要通过推送来下发提醒吗?答案是否定的。既然推送的内容是固定的,那么 QQ 团队可以提前将任务数据下发到客户端,让客户端自行计时触发提醒。这类似于配置下发系统。
但如果采用类似于配置预下发的方式,就涉及到一个问题:提前多久下发呢?提前太久,如果下发后任务需要修改怎么办?对于 QQ 业务而言,这是很常见的问题。比如一个游戏原定时间发布不了(这也被称为跳票),需要修改到一个月后或者更久触发提醒。这个修改如果没有被客户端拉取到,那么客户端就会在原定时间触发提醒。尤其是 IOS 客户端本地,采用系统级别 localnotification 触发提醒,无法阻止。这最后必然导致用户投诉,业务方口碑受损。
消息推送模式主要分为拉取和推送两种,通过组合可以形成如下表呈现的几种模式。各种模式各有优劣,需要根据具体业务场景进行考量。
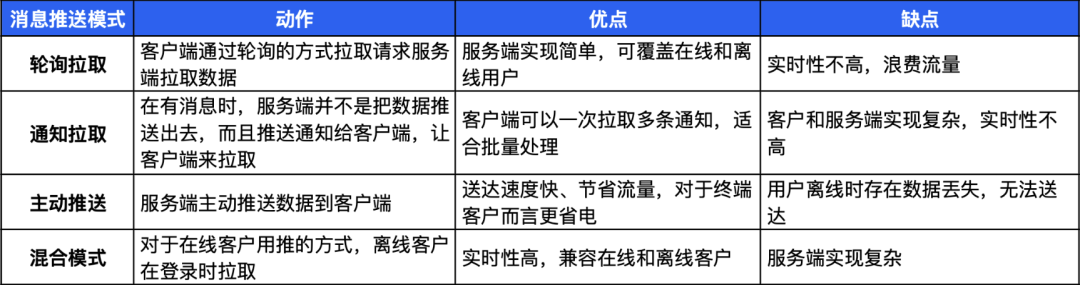
经过权衡, QQ 团队采取图示混合模式——推拉结合。即允许部分用户提前拉取到任务,未拉取的走推送。这个预下发的提前量是提醒当天 0 点开始。因此 QQ 团队也强制要求业务方不能在提醒当天再修改任务信息,包括提醒时间和提醒内容。因为当天0点之后用户就开始拉取,所以必须保证任务时间和内容不变。
2.2 异构存储
系统主要会有两部分数据:
-
业务方创建的任务数据。包含任务的提醒时间和提醒内容;
-
用户订阅生成的订阅数据。主要是订阅用户 uin 列表数据,这个列表元素级别可达到千万以上,并且必须要能够快速读取。
该项目存储选型主要从访问速度上考虑。任务数据可靠性要求高,不需要快速存取,使用MySQL即可。订阅列表数据需要频繁读写,且推送触发时对于存取效率要求较高,考虑使用内存型数据库。
最终QQ团队采用的是 Redis 的 set 类型来存储订阅列表,有以下好处:
-
Redis 单线程模型,有效避免读写冲突;
-
set 底层基于 intset 和 hash 表实现,存储整型 uin 在空间和时间上均高效;
-
原生支持去重;
-
原生支持高效的批量取接口(spop),适合于推送时使用。
2.3 多重触发
再问各位读者一个问题,计时服务一般是怎么做的?分布式计时任务有很多成熟的实现方案,一般是采用延迟队列来实现,比如 Redis sorted set 或者利用 RabbitMQ 死信队列。QQ 团队使用的移动端 QQ 通用计时器组件,即是基于Redis sorted set 实现。
为了保证任务能够被可靠触发, QQ 团队又增加了本地数据库轮询。假如外部组件通用计时器没有准时回调 QQ 团队,本地轮询会在延迟3秒后将还未触发的任务进行触发。这主要是为了防止外部组件可能的故障导致业务触发失败,增加一个本地的扫描查漏补缺。值得注意的是,引入这样的机制可能会带来任务多次触发的可能(例如本地扫描触发了,同一时间计时器也恢复),这就需要 QQ 团队保证任务触发的幂等性(即多次触发最终效果一致,不会重复推送)。触发流程如下:
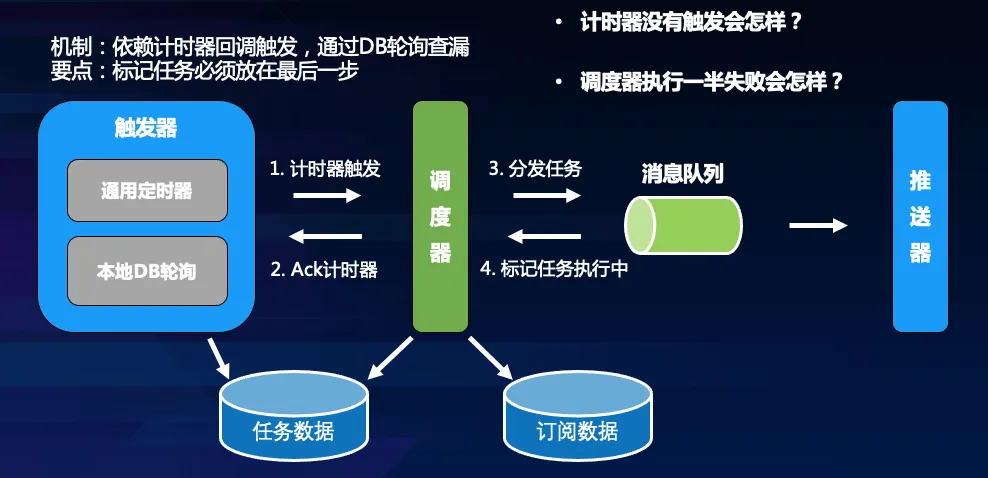
2.4 可控调度
如前所述,当多个千万级别的推送任务在同一时间触发时,推送量是很可观的,系统需要具备总体的任务间调度控制能力。因此需要引入调度器,由调度器来控制每一秒钟的推送量。调度器必须是分布式,以避免单点服务。因此这是一个分布式限频的问题。
这里 QQ 团队简单用 Redis INCR 命令计数。记录当前秒钟的请求量,所有调度器都尝试将当前任务需要下发的量累加到这个值上。如果累加的结果没有超过配置值,则继续累加。最后超过配置值时,每个调度器按照自己抢到的下发量进行下发。简单点说就是下发任务前先抢额度,抢到额度再下发。当额度用完或者没有抢到额度,则等待下一秒。伪代码如下:
CREATE TABLE table_xxx(
ds BIGINT COMMENT '数据日期',
label_name STRING COMMENT '标签名称',
label_id BIGINT COMMENT '标签id',
appid STRING COMMENT '小程序appid',
useruin BIGINT COMMENT 'useruin',
tag_name STRING COMMENT 'tag名称',
tag_id BIGINT COMMENT 'tag id',
tag_value BIGINT COMMENT 'tag权重值'
)
PARTITION BY LIST( ds )
SUBPARTITION BY LIST( label_name )(
SUBPARTITION sp_xxx VALUES IN ( 'xxx' ),
SUBPARTITION sp_xxxx VALUES IN ( 'xxxx' )
)调度流程如下:

值得关注的是,幂等性如何保证呢?讲完了调度的实现,再来论证下幂等性是否成立。
假设第一种情况,调度器执行一半挂了,后面又再次对同一个任务进行调度。由于调度器每次对一个任务进行调度时,都会先查看任务当前剩余推送量(即任务还剩多少块),根据任务的剩余块数来继续调度。所以,当任务再次触发时,调度器可以接着前面的任务继续完成。
假设第二种情况,一个任务被同时触发两次,由两个调度器同时进行调度,那么两个调度器会互相抢额度,抢到后用在同一个任务。从执行效果来看,和一个调度器没有差别。因此,任务可以被重复触发。
2.5 打散执行
任务分块执行的必要性在于:将任务打散分成小任务了,才能实现细粒度的调度。否则,几个 1000w 级别的任务,各位开发者如何调度?假如将所有任务都拆分成 5000 量级的小任务块,那么速率控制就转化成分发小任务块的块数控制。假设配置的总体速率是3w uin/s,那么调度器每一秒最多可以下发 6 个任务块。这 6 个任务块可以是多个任务的。如下图所示:
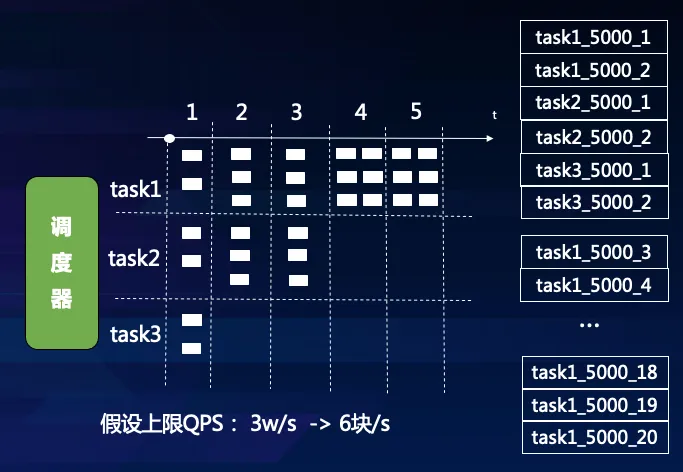
任务分块执行还有其他好处。将任务分成多块均衡分配给后端的worker去执行,可以提高推送的并发量,同时减少后端worker异常的影响粒度。
那么有开发者会问到:如何分块呢?具体实现时调度器负责按配置值下发指令,指令类似到某个任务的列表上取一个任务块,任务块大小 5000 个uin,并执行下发。后端的推送器worker收到指令后,便到指定的任务订阅列表上(redis set实现),通过 spop 获取到 5000 个 uin ,执行推送。
2.6 引入消息队列
一般来说,消息队列的意义主要是削峰填谷、异步解耦。对本项目而言,引入消息队列有以下好处:
-
将任务调度和任务执行解耦(调度服务并不需要关心任务执行结果);
-
异步化,保证调度服务的高效执行,调度服务的执行是以 ms 为单位;
-
借助消息队列实现任务的可靠消费( At least once );
-
将瞬时高并发的任务量打散执行,达到削峰的作用。
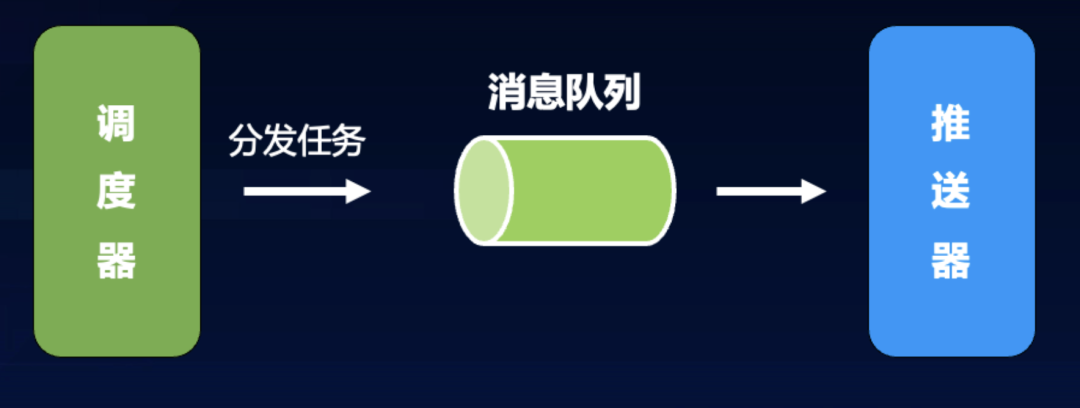
具体的实现方式上,采用队列模型,调度器在进行上文所述的任务分块后,将每一块子任务写入到消息队列中,由推送器节点进行竞争消费。
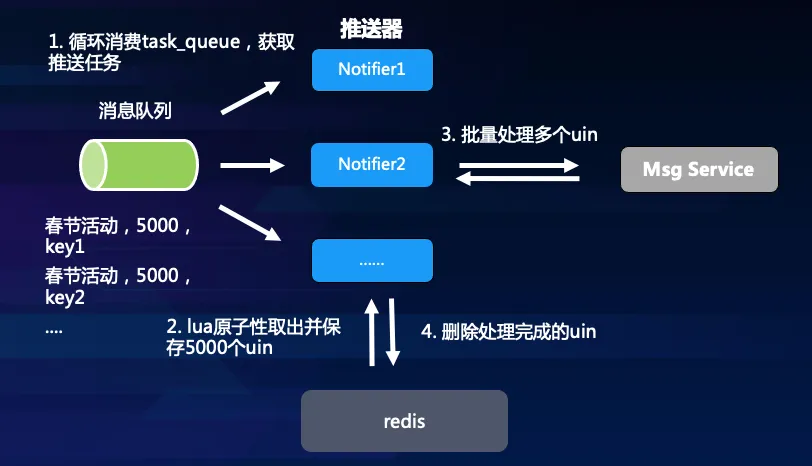
2.7 At least once推送
实现用户级别的可靠性,即要保证所有订阅用户都被至少推送一次(At least once)。如何做到这一点呢?前提是当把用户 uin 从订阅列表中取出进行推送后,在推送结果返回之前,必须保证用户 uin 被妥善保存,以防止推送失败后没有机会再推送。由于 Redis 没有提供从一个 set 中批量 move 数据到另一个set中,这里采取的做法是通过 redis lua 脚本来保证这个操作的原子性,具体 lua 代码如下(近似):
redis.replicate_commands()
local set_key, task_key = KEYS [1], KEYS [2]
local num = tonumber(ARGV [1])
local array
array = redis.call('SPOP', set_key, num)
if #array > 0 then
redis.call("SADD", task_key, unpack(array))
end
return redis.call('scard', task_key)推送流程整体如下:
2.8 容灾方案
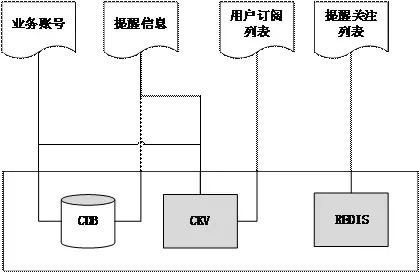
订阅推送系统最重要的是保证推送的可靠性。用户的订阅数据对于系统来说是重中之重。因此,业务团队采用了异构的存储来保证数据的可靠性。每一个用户订阅事件,都会在 CKV (腾讯自主研发的 KV 型数据库)中记录,并将用户 uin 添加到 Redis 中的订阅集合。在任一系统发生故障时,可以从任意一份数据中恢复出另一份数据,形成互备。同时, Redis 存储也使用了腾讯云的Redis集群架构。采用了 2 副本、3 分片的模型,以进一步提高可靠性。

03
总结
上文论述了如何在高并发的基础上实现可控和可靠的任务推送。这个方案可以总结为 Dispatcher+Worker 模型,其核心思想是分治思想,类似于在一条快递流水线上先将大包裹化整为零,分割成标准的小件,再分发给流水线上的众多快递员,执行标准化的配送服务。高性能大流量推送机制是腾讯QQ在真实业务高并发场景下沉淀的高效运营能力,在有效提升用户活跃度与粘性方面效果显著。
腾讯QQ团队在服务内部各个业务条线的同时,也将这部分核心能力进行了抽象、解耦和沉淀,可以作为通用能力服务于各个行业及B端业务。相关技术服务信息,在腾讯移动开发平台(TMF)可以获取。以上便是整个QQ提醒订阅推送系统的实现思路和方案。欢迎各位读者在评论区分享交流。
-End-
原创作者|许扬
技术责编|许扬
你可能感兴趣的腾讯工程师作品
| 算法工程师深度解构ChatGPT技术
| 腾讯云开发者2022年度热文盘点
| 3小时!开发ChatGPT微信小程序
| 7天DAU超亿级,《羊了个羊》技术架构升级实战
技术盲盒:前端|后端|AI与算法|运维|工程师文化
![]()