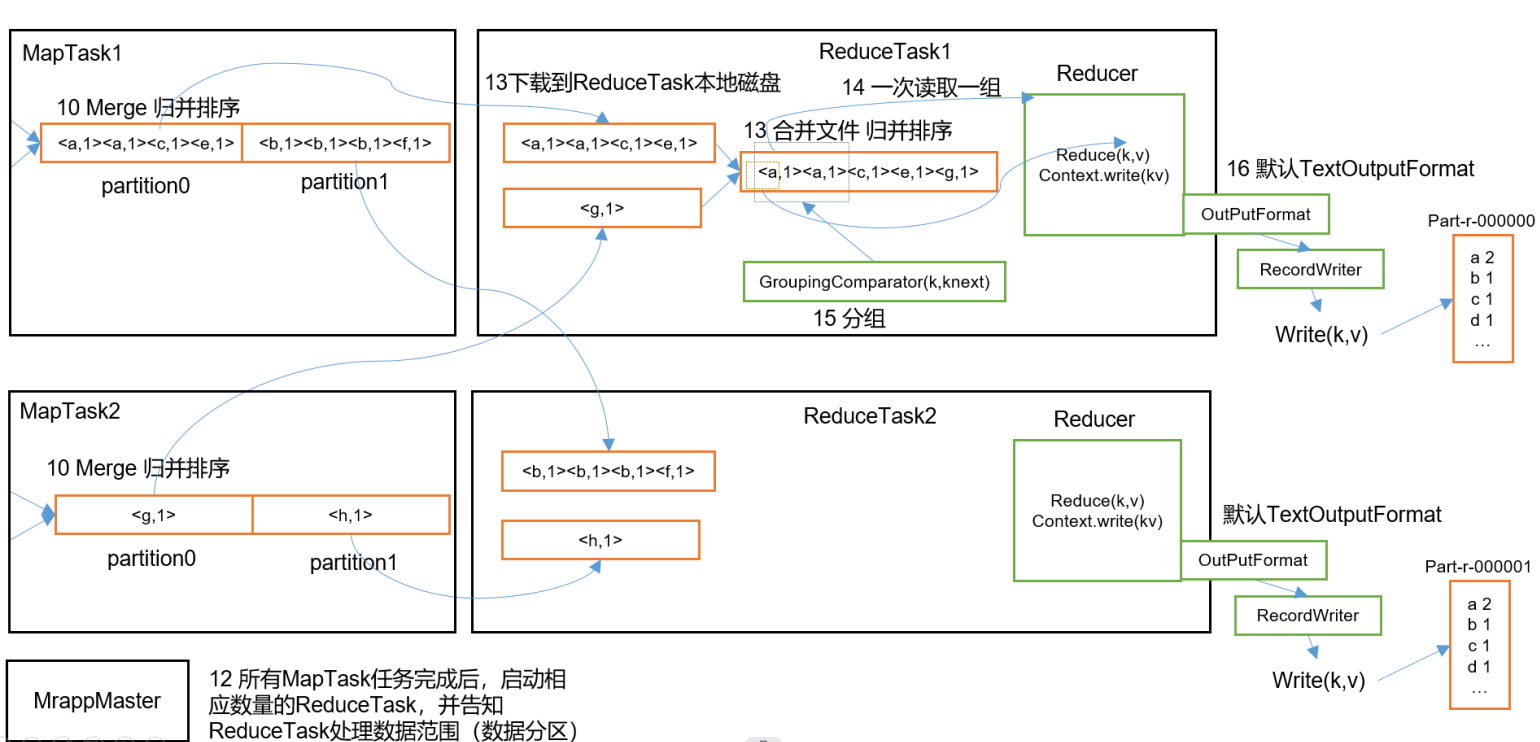
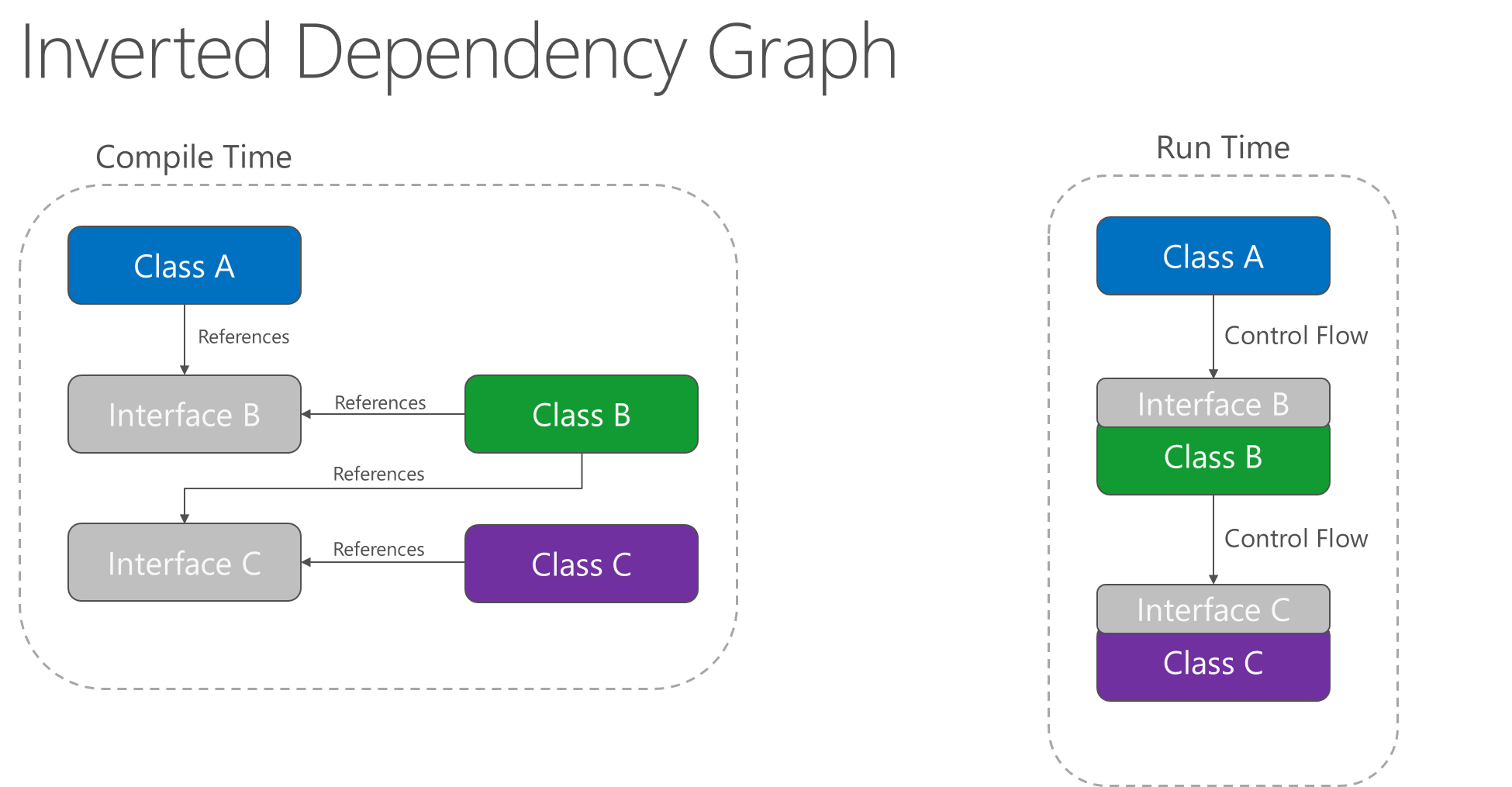
一.MapReduce工作流程图
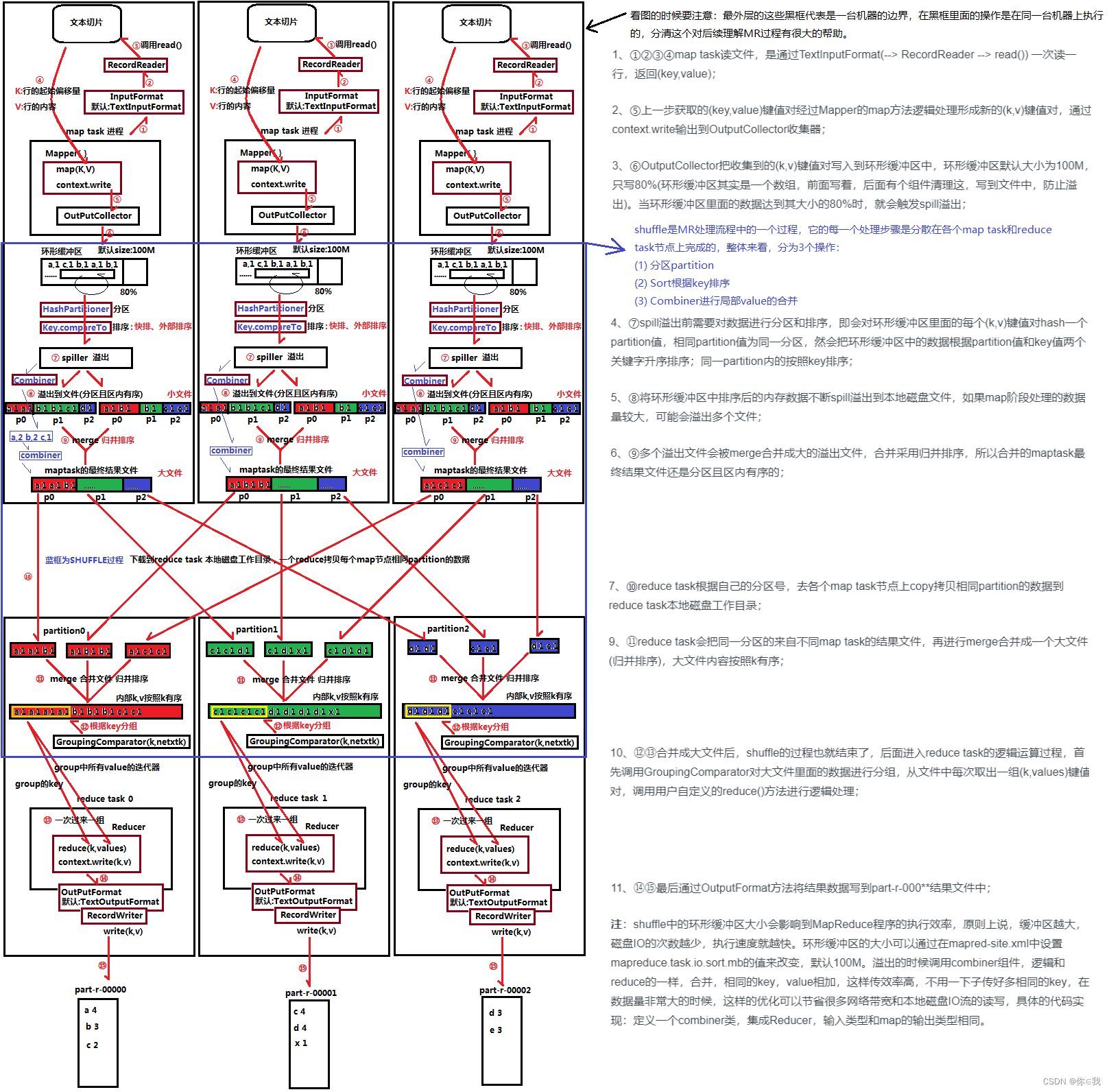
1、分片操作:FileInputstream,首先要计算切片大小,FileInputstream是一个抽象类,继承InputFormat接口,真正完成工作的是它的实现类,默认为是TextInputFormat,TextInputFormat是读取文件的,默认为一行一行读取,将输入文件切分为逻辑上的多个input split,input split是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念,在进行Map计算之前,MapReduce会根据输入文件计算的切片数开启map任务,一个输入切片对应一个maptask,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据位置的集合,每个input spilt中存储着该分片的数据信息如:文件块信息、起始位置、数据长度、所在节点列表等,并不是对文件实际分割成多个小文件,输入切片大小往往与hdfs的block关系密切,默认一个切片对应一个block,大小为128M;注意:尽管我们可以使用默认块大小或自定义的方式来定义分片的大小,但一个文件的大小,如果是在切片大小的1.1倍以内,仍作为一个片存储,而不会将那多出来的0.1单独分片。
2、数据格式化操作:TextInputFormat 会创建RecordReader去读取数据,通过getCurrentkey,getCurrentvalue,nextkey,value等方法来读取,读取结果会形成key,value形式返回给maptask,key为偏移量,value为每一行的内容,此操作的作用为在分片中每读取一条记录就调用一次map方法,反复这一过程直到将整个分片读取完毕。
3、map阶段操作:此阶段就是程序员通过需求偏写了map函数,将数据格式化的<K,V>键值对通过Mapper的map()方法逻辑处理,形成新的<k,v>键值对,通过Context.write输出到OutPutCollector收集器
map端的shuffle(数据混洗)过程:溢写(分区,排序,合并,归并)
reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件。
1) Copy过程,拉取数据。
2)Merge阶段,合并拉取来的小文件
3)Reducer计算
4)Output输出计算结果
溢写:由map处理的结果并不会直接写入磁盘,而是会在内存中开启一个环形内存缓冲区,先将map结果写入缓冲区,这个缓冲区默认大小为100M,并且在配置文件里为这个缓冲区设了一个阀值,默认为0.8,同时map还会为输出操作启动一个守护线程,如果缓冲区内存达到了阀值0.8,这个线程会将内容写入到磁盘上,这个过程叫作spill(溢写)。
分区Partition:当数据写入内存时,决定数据由哪个Reduce处理,从而需要分区,默认分区方式采用hash函数对key进行哈布后再用Reduce任务数量进行取模,表示为hash(key)modR,这样就可以把map输出结果均匀分配给Reduce任务处理,Partition与Reduce是一一对应关系,类似于一个分片对应一个map task,最终形成的形式为(分区号,key,value)
排序Sort:在溢出的数据写入磁盘前,会对数据按照key进行排序,默认采用快速排序,第一关键字为分区号,第二关键字为key。
合并combiner:程序员可选是否合并,数据合并,在Reduce计算前对相同的key数据、value值合并,减少输出量,如(“a”,1)(“a”,1)合并之后(“a”,2)
归并menge:每块溢写会成一个溢写文件,这些溢写文件最终需要被归并为一个大文件,生成key对应的value-list,会进行归并排序<"a",1><"a",1>归并后<"a",<1,1>>。
Reduce 端的shffle:
reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件。
1) Copy过程,拉取数据。
2)Merge阶段,合并拉取来的小文件
3)Reducer计算
4)Output输出计算结果
数据copy:map端的shffle结束后,所有map的输出结果都会保存在map节点的本地磁盘上,文件都经过分区,不同的分区会被copy到不同的Recuce任务并进行并行处理,每个Reduce任务会不断通过RPC向JobTracker询问map任务是否完成,JobTracker检测到map位务完成后,就会通过相关Reduce任务去aopy拉取数据,Recluce收到通知就会从Map任务节点Copy自己分区的数据此过程一般是Reduce任务采用写个线程从不同map节点拉取
归并数据:Map端接取的数据会被存放到 Reduce端的缓存中,如果缓存被占满,就会溢写到磁盘上,缓存数据来自不同的Map节点,会存在很多合并的键值对,当溢写启动时,相同的keg会被归并,最终各个溢写文件会被归并为一个大类件归并时会进行排序,磁盘中多个溢写文许归并为一个大文许可能需要多次归并,一次归并溢写文件默认为10个
Reduce阶段:Reduce任务会执行Reduce函数中定义的各种映射,输出结果存在分布式文件系统中。
MapReduce工作流程图2