构建和设计软件解决方案时应考虑到可维护性。 本部分概述的原则可帮助指导你作出体系结构决策,生成简洁、可维护的应用程序。 一般而言,在这些原则的指导下构建的应用程序各部分间可通过显式接口或消息传送系统进行通信,并非松散耦合的离散组件。
通用设计原则
分离关注点
分离关注点是开发时的指导原则。 此原则主张应根据软件执行的工作类型将软件分离。 例如,假设应用程序中包含两个逻辑,其中一个逻辑标识要显示给用户的注意事项,另一个以特定方式设置这些注意事项的格式,使其更加显眼。 负责选择为哪些事项设置格式的行为应与负责设置格式的行为区分开,因为这两种行为只是碰巧彼此相关联的独立关注点。
从体系结构上来说,按此原则有逻辑地构建应用程序应将核心业务行为与基础结构及用户界面逻辑区分开。 理想情况下,业务规则和逻辑应单独位于一个项目中,且该项目不依赖于应用程序中的其他项目。 此区分操作可帮助确保该业务模型易于测试,且可在不与低级别实现详细信息紧密耦合的情况下逐步改进(如果基础结构问题取决于业务层中定义的抽象时,这也有帮助)。 在应用程序体系结构的使用层背后,关注点分离是核心设计思想。
封装
应用程序的不同部分应通过封装与应用程序中的其他部分隔离开。 只要不违反外部协定,应用程序组件和层应能在不中断其协作者的情况下调整其内部实现。 正确使用封装有助于在应用程序设计中实现松散耦合及模块化,因为只要维持相同的接口,就可以用替代实现来替代对象和包。
在类中实现封装的方式是限制对该类的内部状态的外部访问权限。 如果外部参与者想操作对象的状态,则应通过明确定义的函数(或属性 setter)来进行操作,而非直接访问该对象的私有状态。 同样,应用程序组件和应用程序本身应公开明确定义的接口供协作者使用,而非让协作者直接修改其状态。 通过此方法,只要公共协定得到维护,你就可以不断改进应用程序的内部设计,而无需担心会中断协作者。
可变全局状态与封装是对立的。 不能依赖从一个函数中的可变全局状态获取的值在另一个函数中(甚至在同一个函数中)具有相同的值。 理解可变全局状态问题是 C# 语言等编程语言支持不同范围规则的原因之一,从语句到方法再到类,这些规则被广泛使用。 值得注意的是,对于依赖中央数据库在应用程序内部和之间进行集成的数据驱动的体系结构,他们本身选择依赖由数据库表示的可变全局状态。 域驱动的设计和整洁的体系结构的一个重要考虑因素是如何封装对数据的访问,以及如何确保应用程序状态不会因直接访问其持久性格式而无效。
依赖关系反转
应用程序中的依赖关系方向应该是抽象的方向,而不是实现详细信息的方向。 大部分应用程序都是这样编写的:编译时依赖关系顺着运行时执行的方向流动,从而生成一个直接依赖项关系图。 也就是说,如果类 A 调用类 B 的方法,类 B 调用 C 类的方法,则在编译时,类 A 将取决于类 B,而 B 类又取决于类 C,如图 4-1 所示。
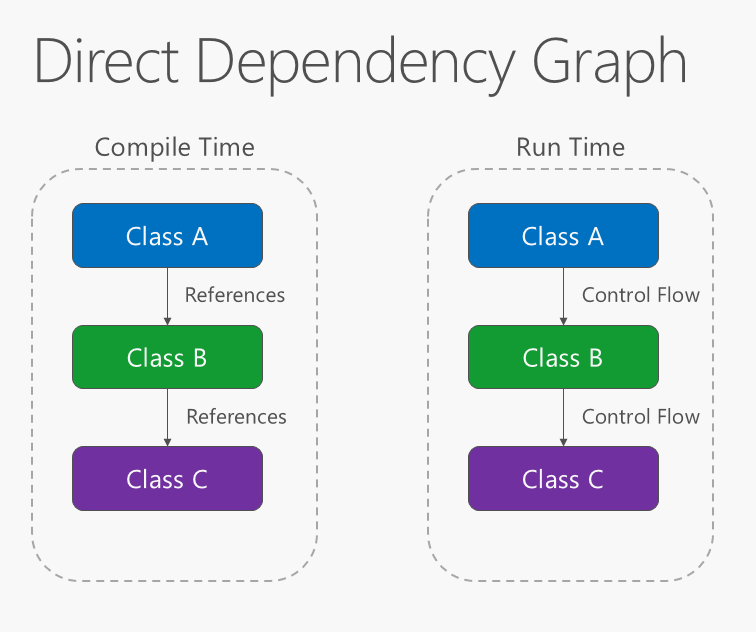
图 4-1。 直接依赖项关系图。
应用依赖关系反转原则后,A 可以调用 B 实现的抽象上的方法,让 A 可以在运行时调用 B,而 B 又在编译时依赖于 A 控制的接口(因此,典型的编译时依赖项发生反转)。 运行时,程序执行的流程保持不变,但接口引入意味着可以轻松插入这些接口的不同实现。
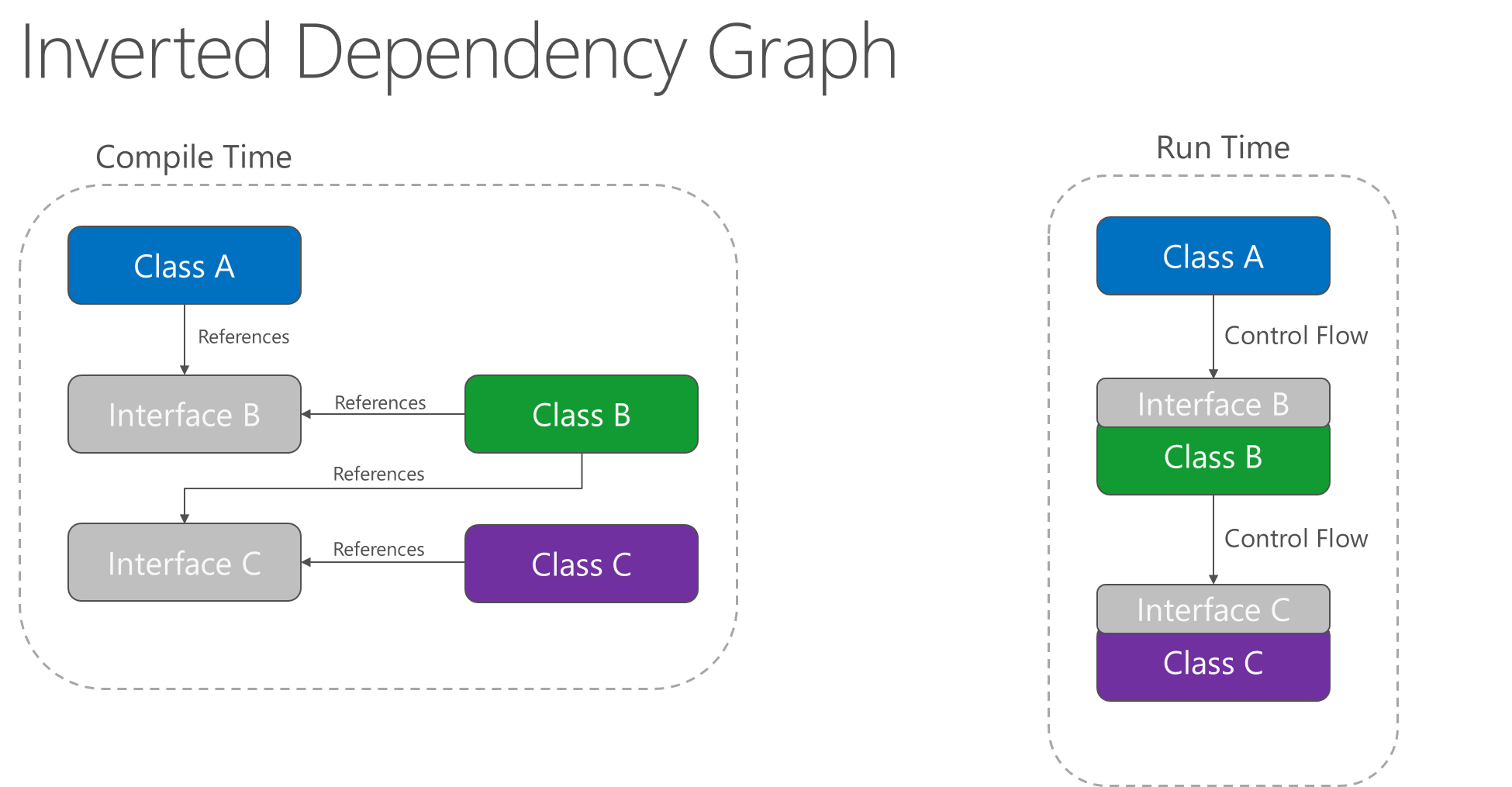
图 4-2。 反转依赖项关系图。
依赖项反转是生成松散耦合应用程序的关键一环,因为可以将实现详细信息编写为依赖并实现更高级别的抽象,而不是相反。 因此,生成的应用程序的可测试性、模块化程度以及可维护性更高。 遵循依赖关系反转原则可实现依赖关系注入。
显式依赖关系
方法和类应显式要求正常工作所需的任何协作对象。 我将此称为显式依赖关系原则。 通过类构造函数,类可以标识其实现有效状态和正常工作所需的内容。 如果定义的类可供构造和调用,但仅在具备特定全局组件或基础结构组件时正常工作,则这些类对其客户端而言就不诚实。 构造函数协定将告知客户端,它只需要指定的内容(如果类只使用无参数构造函数,则可能不需要任何内容),但随后在运行时,结果发现对象确实需要某些其他内容。
若遵循显式依赖关系原则,类和方法就会诚实地告知客户端其需要哪些内容才能工作。 遵循此原则可以让代码更好地自我记录,并让代码协定更有利于用户,因为用户相信只要他们以方法或构造函数参数的形式提供所需的内容,他们使用的对象在运行时就能正常工作。
单一责任
单一责任原则适用于面向对象的设计,但也可被视为类似于分离关注点的体系结构原则。 它指出对象只应有一个责任,并且只能因为一个原因更改对象。 具体而言,只在必须更新对象执行其唯一责任的方式时才应更改对象。 遵循这一原则有助于生成更松散耦合和模块化的系统,因为许多类型的新行为可以作为新类实现,而不是通过向现有类添加其他责任。 添加新类始终比更改现有类安全,因为还没有任何代码依赖于新类。
在整体应用程序中,可以在高级别将单一责任原则应用于应用程序中的层。 显示责任应位于 UI 项目中,而数据访问责任应位于基础结构项目中。 业务逻辑应位于应用程序核心项目中,该项目易于测试,并且可以独立于其他责任进行逐步改进。
将此原则应用到应用程序体系结构及其逻辑终结点时,你将获得微服务。 给定的微服务应具有单一责任。 一般而言,如果需要扩展系统的行为,最好通过添加其他微服务来实现,而不要向现有微服务添加责任。
不要自我重复 (DRY)
应用程序应避免在多个位置指定与特定概念相关的行为,因为这种做法经常会导致出错。 有时,如果要求发生变化,将要求更改此行为。 至少有一个行为实例可能无法更新,系统行为可能不一致。
请将逻辑封装在编程构造中,而不要重复该逻辑。 让此构造成为针对此行为的单一权限,并让应用程序中需要此行为的任何其他部分都使用新的构造。
备注
避免将恰巧重复的行为绑定在一起。 例如,只因为两个不同的常数具有相同的值,如果从概念上讲两个常数是指不同的内容,这并不意味着只应使用一个常数。 复制总是比耦合到错误的抽象更可取。
持久性无感知
持久性无感知 (PI) 是指需要保持不变的类型,但其代码不受所选择的持久性技术的影响。 .NET 中的这种类型有时被称为普通旧 CLR 对象 (POCO),因为这种类型无需继承特定的基类或实现特定的接口。 持久性无感知非常有用,因为它可以让相同的业务模型以多种方式保持不变,让应用程序更加灵活。 持久性选择可能会随着时间的推移而发生变化,从一种数据库技术变为另一种数据库技术,或除应用程序一开始具备的持久性形式之外还需要其他形式的持久性(例如,除相关数据库之外还需使用 Redis 缓存或 Azure Cosmos DB)。
违反此原则的一些示例包括:
-
必需的基类。
-
必需的接口实现。
-
负责保存其自身的类(例如活动记录模式)。
-
所需的无参数构造函数。
-
需要 virtual 关键字的属性。
-
特定于持久性的必需特性。
要求类具有上述任何特性或行为会增加要保持不变的类型和持久性技术的选择之间的耦合,从而增加将来采用新的数据访问策略的难度。
有界上下文
有界上下文是领域驱动设计中的中心模式。 它们可以将大型应用程序或组织分解为独立的概念模块,通过这种方式来解决复杂性问题。 每个概念模块表示各自独立的上下文(因此有界),并且可以独立改进。 理想情况下,每个有界上下文都应该能够为其中的概念自由选择它自己的名称,并对其自己的持久性存储具有独占访问权限。
至少,各 Web 应用程序应努力成为自己的有界上下文,为其业务模型提供自己的持久性存储,而不是与其他应用程序共享数据库。 有界上下文之间的通信通过编程接口进行,而不是通过共享数据库进行,这样可以引发业务逻辑和事件来响应发生的更改。 有界上下文会紧密映射到微服务,后者在理想情况下也作为其自己的单独有界上下文实现。