八大排序算法中的堆排序,就会使用到顺序存储二叉树。
1.线索化二叉树
1.1先看一个问题
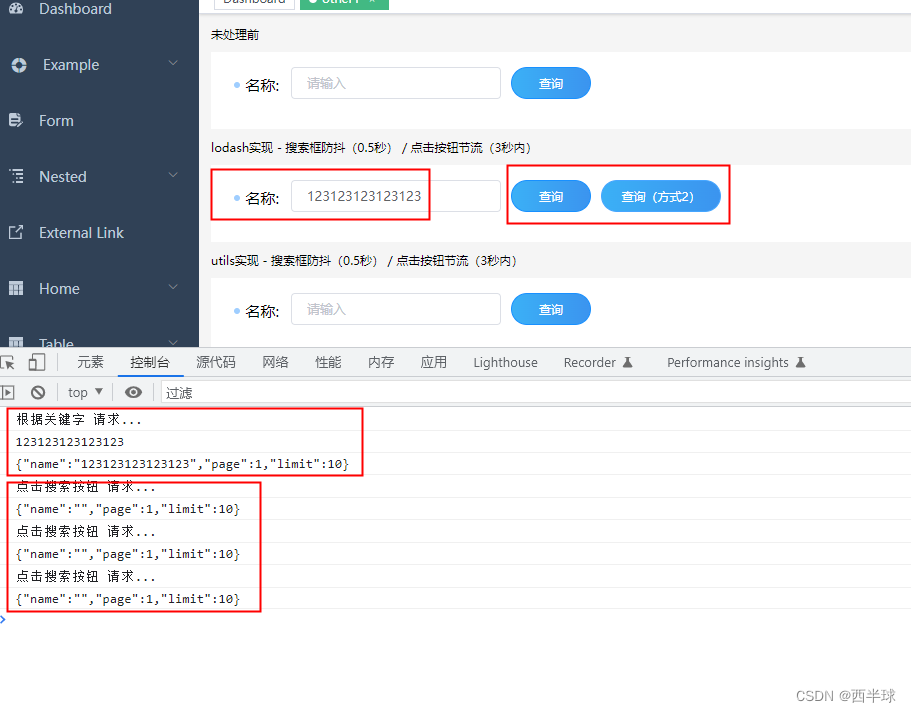
将数列 {1, 3, 6, 8, 10, 14 } 构建成一颗二叉树. n+1=7

问题分析:
-
当我们对上面的二叉树进行中序遍历时,数列为 {8, 3, 10, 1, 6, 14 }
-
但是 6, 8, 10, 14 这几个节点的 左右指针,并没有完全的利用上.
-
如果我们希望充分的利用 各个节点的左右指针, 让各个节点可以指向自己的前后节点,怎么办?
-
解决方案-线索二叉树
2.线索二叉树基本介绍
-
n 个结点的二叉链表中含有 n+1 【公式 2n-(n-1)=n+1】 个空指针域。利用二叉链表中的空指针域,存放指向
该结点在某种遍历次序下的前驱和后继结点的指针(这种附加的指针称为"线索") -
这种加上了线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树(Threaded BinaryTree)。根据线索性质
的不同,线索二叉树可分为前序线索二叉树、中序线索二叉树和后序线索二叉树三种 -
一个结点的前一个结点,称为前驱结点
-
一个结点的后一个结点,称为后继结点
3.线索二叉树应用案例
应用案例说明:将下面的二叉树,进行中序线索二叉树。中序遍历的数列为 {8, 3, 10, 1, 14, 6}
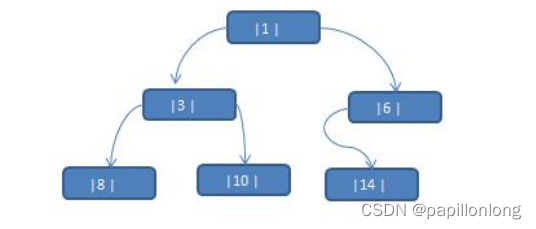
思路分析: 中序遍历的结果:{8, 3, 10, 1, 14, 6}
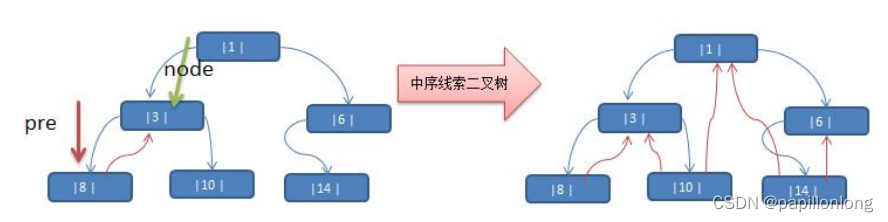
说明: 当线索化二叉树后,Node 节点的 属性 left 和 right ,有如下情况:
-
left 指向的是左子树,也可能是指向的前驱节点. 比如 ① 节点 left 指向的左子树, 而 ⑩ 节点的 left 指向的
就是前驱节点. -
right 指向的是右子树,也可能是指向后继节点,比如 ① 节点 right 指向的是右子树,而⑩ 节点的 right 指向
的是后继节点.
代码实现:
public class TreadedBinaryTreeDemo {
public static void main(String[] args) {
// 测试一把中序线索二叉树的功能
HeroNode root = new HeroNode(1, "tom");
HeroNode node2 = new HeroNode(3, "jack");
HeroNode node3 = new HeroNode(6, "smith");
HeroNode node4 = new HeroNode(8, "mary");
HeroNode node5 = new HeroNode(10, "king");
HeroNode node6 = new HeroNode(14, "dim");
// 说明,我们先手动创建该二叉树,后面我们学习递归的方式创建二叉树
root.setLeft(node2);
root.setRight(node3);
node2.setLeft(node4);
node2.setRight(node5);
node3.setLeft(node6);
// 测试线索化
ThreadedBinaryTree threadedBinaryTree = new ThreadedBinaryTree();
threadedBinaryTree.setRoot(root);
threadedBinaryTree.threadedNodes();
// 测试 以10结点测试
HeroNode leftNode = node5.getLeft();
HeroNode rightNode = node5.getRight();
System.out.println("10号结点的前驱结点是=" + leftNode);
System.out.println("10号结点的后继结点是=" + rightNode);
// 当线索化二叉树后,能在使用原来的遍历方法
// threadedBinaryTree.infixOrder();
System.out.println("使用线索化的方式遍历 线索化二叉树");
threadedBinaryTree.threadedList();
}
}
//定义ThreadedBinaryTree实现了线索化功能的二叉树
class ThreadedBinaryTree {
private HeroNode root;
// 为了实现线索化,需要创建要给当前结点的前驱点的指针
// 在递归进行线索化时,pre总保留前一个结点
private HeroNode pre = null;
public void setRoot(HeroNode root) {
this.root = root;
}
// 重载一把threadedNodes方法
public void threadedNodes() {
this.threadedNodes(root);
}
// 遍历线索化二叉树的方法
public void threadedList() {
// 定义一个变量,存储当前遍历的结点,从root开始
HeroNode node = root;
while (node != null) {
// 循环的找到leftType == 1的结点,第一个找到就是8结点
// 后面随着遍历而变化,因为当leftType==1时,说明该节点是按照线索化
// 处理后的有效结点
while (node.getLeftType() == 0) {
node = node.getLeft();
}
// d打印当前这个结点
System.out.println(node);
// 如果当前节点的左指针指向的是后继结点,就一直输出
while (node.getRightType() == 1) {
// 获取到当前节点的后继结点
node = node.getRight();
System.out.println(node);
}
// 替换这个遍历的结点
node = node.getRight();
}
}
// 编写对二叉树进行中序线索化的方法
/**
*
* @param node 就是当前需要线索化的结点
*/
public void threadedNodes(HeroNode node) {
// 如果node == null ,不能线索化
if (node == null) {
return;
}
// (一)先线索化左子树
threadedNodes(node.getLeft());
// (二)线索化当前节点
// 处理当前节点的前驱结点
// 以8结点来解释
// 8结点.left = null,8结点的.leftType = 1;
if (node.getLeft() == null) {
// 让当前节点的左指针指向前驱节点
node.setLeft(pre);
// 修改当前节点的左指针的类型,指向前驱结点
node.setLeftType(1);
}
// 处理后继节点
if (pre != null && pre.getRight() == null) {
// 让前驱节点的右指针指向当前节点
pre.setRight(node);
// 修改前驱节点的右指针类型
pre.setRightType(1);
}
// 处理每一个节点后让当前节点是指向下一个结点的前驱结点
pre = node;
// (三)在线索化右子树
threadedNodes(node.getRight());
}
// 删除结点
public void delNode(int no) {
if (root != null) {
// 如果只有一个root结点,这里立刻判断root是不是就是要删除结点
if (root.getNo() == no) {
root = null;
} else {
// 递归删除
root.delNode(no);
}
} else {
System.out.println("空树,不能删除");
}
}
// 前序遍历
public void preOrder() {
if (this.root != null) {
this.root.preOrder();
} else {
System.out.println("二叉树为空,无法遍历");
}
}
// 中序遍历
public void infixOrder() {
if (this.root != null) {
this.root.infixOrder();
} else {
System.out.println("二叉树为空,无法遍历");
}
}
// 后续遍历
public void postOrder() {
if (this.root != null) {
this.root.postOrder();
} else {
System.out.println("二叉树为空,无法遍历");
}
}
// 前序遍历
public HeroNode preOrderSearch(int no) {
if (root != null) {
return root.preOrderSearch(no);
} else {
return null;
}
}
// 中序遍历
public HeroNode infixOrderSearch(int no) {
if (root != null) {
return root.infixOrderSearch(no);
} else {
return null;
}
}
// 后序遍历
public HeroNode postOrderSearch(int no) {
if (root != null) {
return root.postOrderSearch(no);
} else {
return null;
}
}
}
//先创建HeroNode结点
class HeroNode {
private int no;
private String name;
private HeroNode left;// 默认null
private HeroNode right;// 默认null
// 说明
// 1.如果leftType == 0 表示指向的是左子树,如果1则表示指向前驱结点
// 2.如果rightType == 0 表示指向的是右子树,如果1表示指向后继结点
private int leftType;
private int rightType;
public int getLeftType() {
return leftType;
}
public void setLeftType(int leftType) {
this.leftType = leftType;
}
public int getRightType() {
return rightType;
}
public void setRightType(int rightType) {
this.rightType = rightType;
}
public HeroNode(int no, String name) {
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode [no=" + no + ", name=" + name + "]";
}
// 递归删除结点
// 1.如果删除的节点是叶子节点,则删除该节点
// 2.如果删除的节点是非叶子节点,则删除该子树
public void delNode(int no) {
// 思路
/*
* 1. 因为我们的二叉树是单向的,所以我们是判断当前结点的子结点是否需要删除结点,而不能去判断当前这个结点是不是需要删除结点. 2.
* 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将 this.left = null; 并且就返回(结束递归删除) 3.
* 如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将 this.right= null ;并且就返回(结束递归删除) 4. 如果第 2 和第
* 3 步没有删除结点,那么我们就需要向左子树进行递归删除 5. 如果第 4 步也没有删除结点,则应当向右子树进行递归删除.
*
*/
// 2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将 this.left = null; 并且就返回(结束递归删除)
if (this.left != null && this.left.no == no) {
this.left = null;
return;
}
// 3. 如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将 this.right= null ;并且就返回(结束递归删除)
if (this.right != null && this.right.no == no) {
this.right = null;
return;
}
// 4. 我们就需要向左子树进行递归删除
if (this.left != null) {
this.left.delNode(no);
}
// 5. 则应当向右子树进行递归删除.
if (this.right != null) {
this.right.delNode(no);
}
}
// 编写前序遍历方法
public void preOrder() {
System.out.println(this);// 先输出父节点
// 递归向左子树前序遍历
if (this.left != null) {
this.left.preOrder();
}
// 递归向右子树前序遍历
if (this.right != null) {
this.right.preOrder();
}
}
// 中序遍历
public void infixOrder() {
// 递归向左子树前序遍历
if (this.left != null) {
this.left.infixOrder();
}
System.out.println(this);// 输出父节点
// 递归向右子树前序遍历
if (this.right != null) {
this.right.infixOrder();
}
}
// 后序遍历
public void postOrder() {
// 递归向左子树前序遍历
if (this.left != null) {
this.left.postOrder();
}
// 递归向右子树前序遍历
if (this.right != null) {
this.right.postOrder();
}
System.out.println(this);// 输出父节点
}
// 前序遍历查找
/**
*
* @param no 查找no
* @return 如果找到就返回该Node,如果没有找到返回null
*/
public HeroNode preOrderSearch(int no) {
System.out.println("进入前序遍历");
// 比较当前节点是不是
if (this.no == no) {
return this;
}
// 则判断当前结点的左子结点是否为空,如果不为空,则递归前序查找
// 2.如果左递归前序查找,找到结点,则返回
HeroNode resNode = null;
if (this.left != null) {
resNode = this.left.preOrderSearch(no);
}
if (resNode != null) {// 说明我们左子树找到
return resNode;
}
// 1.左递归前序查找,找到结点,则返回,否则继续判断,
// 2.当前结点的右子结点是否为空,如果不为空,则递归前序查找
if (this.right != null) {
resNode = this.right.preOrderSearch(no);
}
return resNode;
}
// 中序遍历查找
public HeroNode infixOrderSearch(int no) {
// 判断当前结点的左子结点是否为空,如果不为空,则递归中序查找
HeroNode resNode = null;
if (this.left != null) {
resNode = this.left.infixOrderSearch(no);
}
if (resNode != null) {
return resNode;
}
System.out.println("进入中序遍历");
// 如果找到则返回,如果没有找到,就和当前结点比较,如果是则返回当前结点
if (this.no == no) {
return this;
}
// 否则继续左递归的中序查找
if (this.right != null) {
resNode = this.right.infixOrderSearch(no);
}
return resNode;
}
// 后序遍历查找
public HeroNode postOrderSearch(int no) {
// 判断当前结点的左子节点是否为空,如果不为空则递归后序查找
HeroNode resNode = null;
if (this.left != null) {
resNode = this.left.postOrderSearch(no);
}
if (resNode != null) {// 说明在左子树找到
return resNode;
}
// 如果左子树没有找到,则向右子树递归进行后序遍历查找
if (this.right != null) {
resNode = this.right.postOrderSearch(no);
}
if (resNode != null) {
return resNode;
}
System.out.println("进入后序查找");
// 如果左右子树都没有找到,就比较当前节点是不是
if (this.no == no) {
return this;
}
return resNode;
}
}
遍历线索化二叉树
-
说明:对前面的中序线索化的二叉树, 进行遍历
-
分析:因为线索化后,各个结点指向有变化,因此原来的遍历方式不能使用,这时需要使用新的方式遍历
线索化二叉树,各个节点可以通过线型方式遍历,因此无需使用递归方式,这样也提高了遍历的效率。 遍历的次
序应当和中序遍历保持一致。 -
代码
// 遍历线索化二叉树的方法
public void threadedList() {
// 定义一个变量,存储当前遍历的结点,从root开始
HeroNode node = root;
while (node != null) {
// 循环的找到leftType == 1的结点,第一个找到就是8结点
// 后面随着遍历而变化,因为当leftType==1时,说明该节点是按照线索化
// 处理后的有效结点
while (node.getLeftType() == 0) {
node = node.getLeft();
}
// d打印当前这个结点
System.out.println(node);
// 如果当前节点的左指针指向的是后继结点,就一直输出
while (node.getRightType() == 1) {
// 获取到当前节点的后继结点
node = node.getRight();
System.out.println(node);
}
// 替换这个遍历的结点
node = node.getRight();
}
}