第一章 MapReduce核心理论
1.1 什么是MapReduce
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据应用” 的核心框架 。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并行运行在一个 Hadoop 集群上。
回顾一下Hadoop 的四大组件:
HDFS:分布式存储系统
MapReduce:分布式计算系统
YARN:资源调度系统
Common:以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等
1.2 为什么需要 MapReduce
为什么需要 MapReduce?
1、海量数据在单机上处理因为硬件资源限制,无法胜任
2、而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
3、引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
设想一个海量数据场景下的数据计算需求:
单机版:磁盘受限,内存受限,计算能力受限
分布式版:思考,图片讲解。
程序由单机版扩成分布式版时,会引入大量的复杂工作。
为了提高开发效率,可以将分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。
Hadoop 当中的 MapReduce 就是这样的一个分布式程序运算框架,它把大量分布式程序都会涉及的到的内容都封装进了,让用户只用专注自己的业务逻辑代码的开发。
1.3 MapReduce的优缺点
优点:
(1)适合大批量(PB级以上)数据的离线处理
上千台服务器集群并发工作能力,提供数据运算。
(2)高容错性
首先要知道MapReduce设计的初衷:就是使程序能够部署在廉价的PC机器上,那么这就需要MapReduce框架具有很高的容错性。比如在运行的过程中有节点宕机,它可以把上面的计算任务转移到其他节点上来运行,不至于让这个任务运行失败,且这个过程不需要人工去参与,由Hadoop内部完成的。
(3)高扩展性
计算资源不够的时候,通过简单的增加机器来扩展它的计算能力。横向扩展。
(4)易于编程(中规中矩)
完成一个分布式程序的运行,简单的实现一些接口就可以。这个分布式程序可以分布到廉价的机器上运行。
写一个分布式程序,和写一个普通的串行程序是一样的。
缺点:
(1)实时计算不擅长
MapReduce基本上做不到毫秒或者秒级内返回结果。
(2)流式计算也不擅长
MapReduce输入数据源是静态的,不能动态变化;流式计算输入数据是动态的。这是由MapReduce自身设计特点决定数据源必须是静态的。
Spark Streaming、 Flink 擅长实时。
(3)多级依赖任务不擅长
N个应用程序存在依赖关系,前一个的输出为后一个应用程序的输入。这种情况下,MapReduce处理效率很低,因为这个时候使用MapReduce后,每个MapReduce job的输出结果都会写入到磁盘,会造成大量的磁盘IO,所以性能低下。
Spark擅长这种多级依赖。
1.4 MapReduce的核心思路
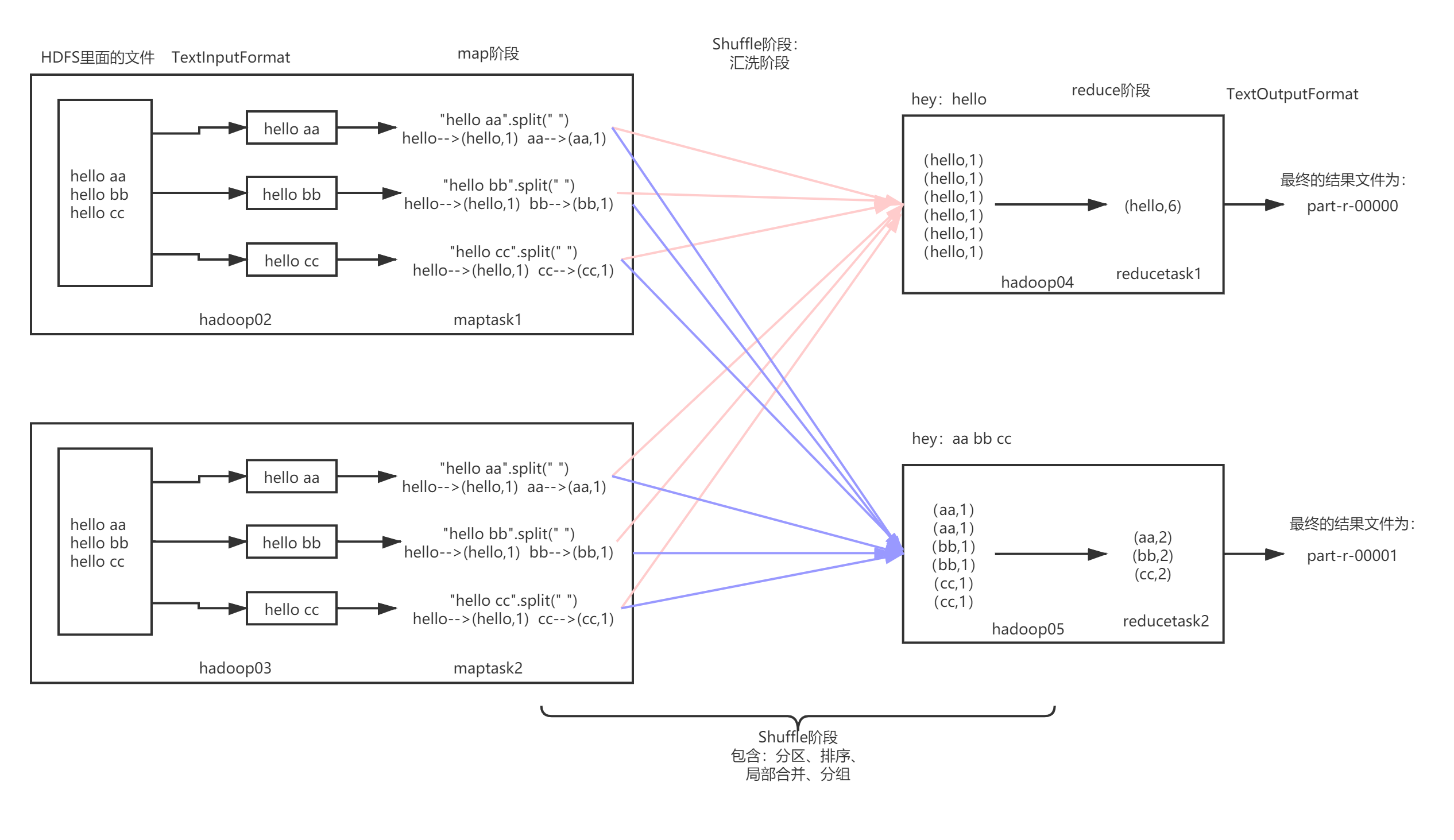
思路
1、MapReduce运算程序需要分成2个阶段执行。
2、第一个阶段的MapTask任务并发执行,完全并行运行,互不影响。
3、第二个阶段的ReduceTask任务并发执行,但是此时的数据依赖于上一个阶段的所有MapTask并发任务的输出。
4、MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果业务逻辑复杂,那只能多个MapReduce程序,串行运行。
MapReduce中的进程:一个完整的MapReduce计算程序在分布式运行的时候有三类实例进程:
1、MapTask:负责Map阶段的数据处理流程。
2、ReduceTask:负责Reduce阶段的数据处理流程。
3、MrAppMaster:负责整个程序的流程调度和状态协调。
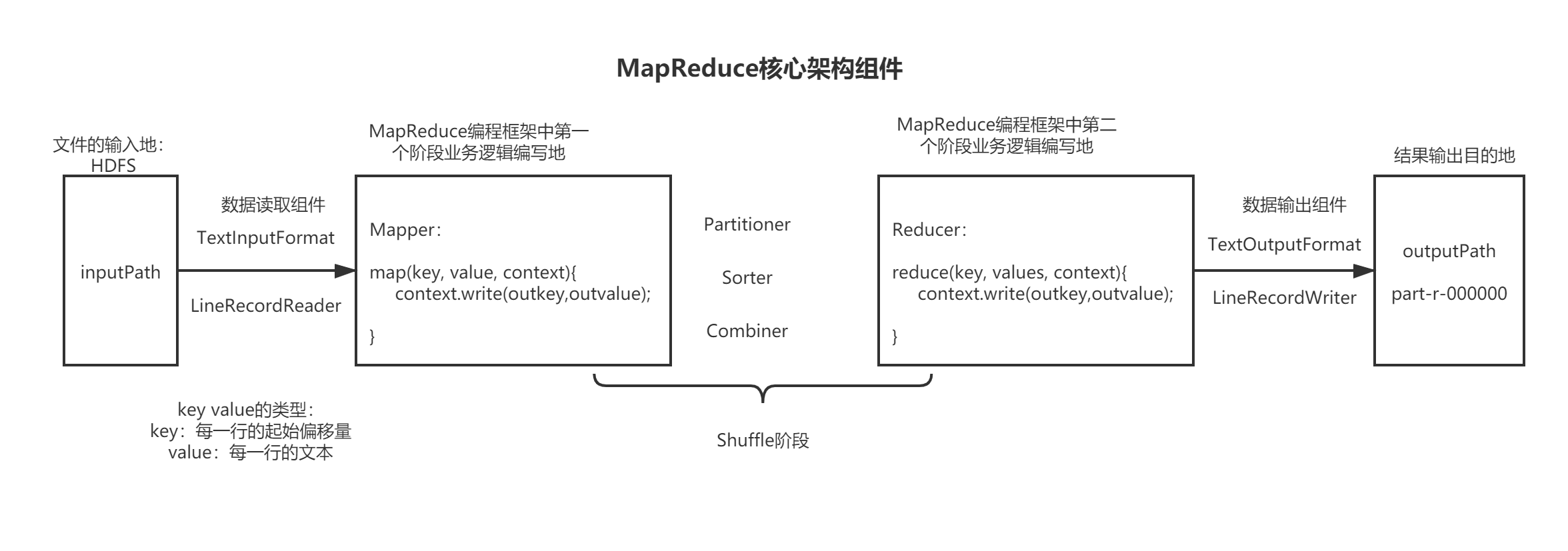
1.5 MapReduce核心组件
1.6 MapReduce编程流程和规范
MapReduce编程流程
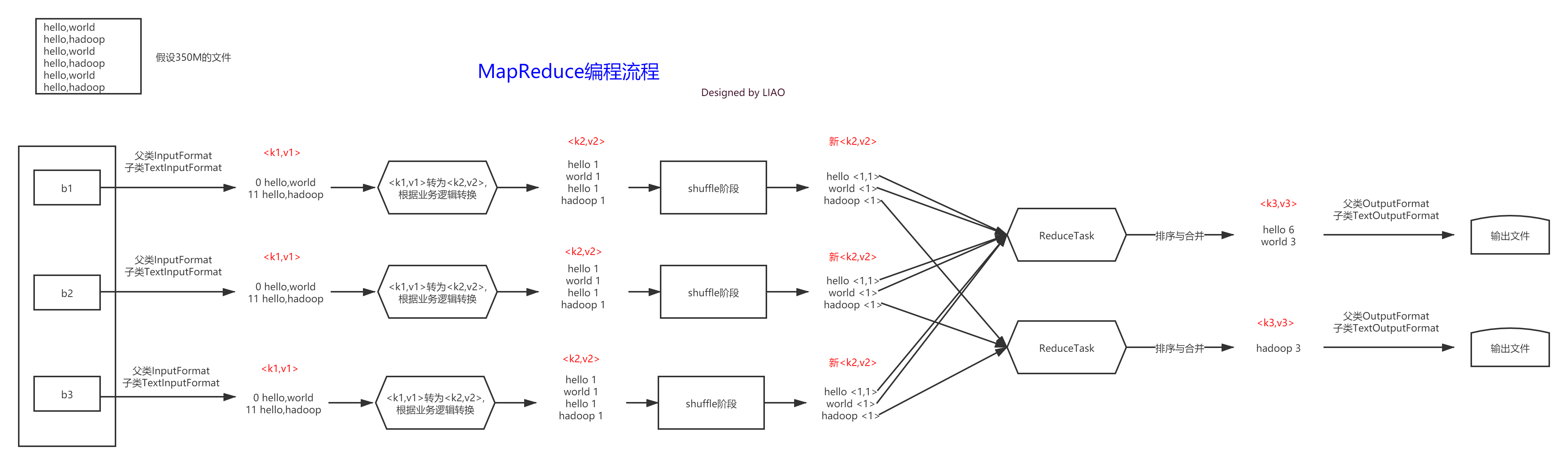
MapReduce编程规范
1、MapReduce 程序的业务编码分为两个大部分:
一部分配置程序的运行信息,
一部分编写该 MapReduce 程序的业务逻辑,并且业务逻辑的 map 阶段和 reduce 阶段的代码分别继 承 Mapper 类和 Reducer 类
2、MapReduce 程序具体编写规范
1、用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行 MR 程序的客户端)
2、Mapper 的输入数据是 KV 对的形式(KV 的类型可自定义)
3、Mapper 的输出数据是 KV 对的形式(KV 的类型可自定义)
4、Mapper 中的业务逻辑写在 map()方法中
5、map()方法(maptask 进程)对每一个<K,V>调用一次
6、Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV 对的形式
7、Reducer 的业务逻辑写在 reduce()方法中
8、Reducetask 进程对每一组相同 k 的<K,V>组调用一次 reduce()方法
9、用户自定义的 Mapper 和 Reducer 都要继承各自的父类
10、整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信息的 job 对象
1.7 MapReduce程序运行演示
在 MapReduce 组件里,官方给我们提供了一些样例程序,其中非常有名的就是 wordcount 和 pi 程序。这些 MapReduce 程序的代码都在hadoop-mapreduce-examples-2.7.4.jar 包里,这 个 jar 包在 hadoop 安装目录下的/share/hadoop/mapreduce/目录里
下面我们使用 hadoop 命令来试跑例子程序,看看运行效果
先看 MapReduce 程序求WordCount的程序:
1、创建一个wcinput文件夹,注意是在hdfs上面创建,不是在本地创建
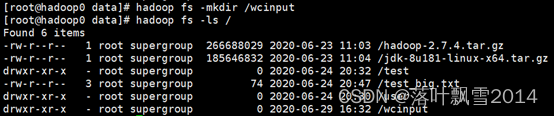
2、在本地任意文件夹下面创建文件并上传到hdfs上面,我这里是在本地的/home/data目录下面创建的wordcount.txt

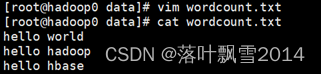

3、任意目录下运行官方wordcount程序
官方案例的路径为:
/software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar
编写的时候注意路径不要写错了!!!注意是HDFS上面的路径。
hadoop jar /software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /wcinput /wcoutput
4、去hdfs上面查看
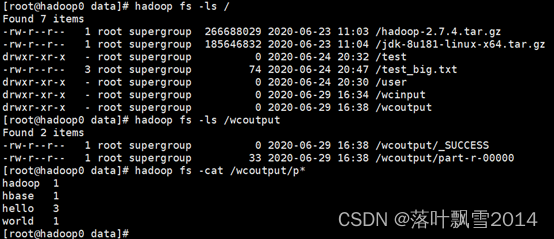
再来看求PI的案例
1、任意目录直接运行即可
hadoop jar /software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar pi 5 5 //pi + map数量 + reduce数量

2、查看结果
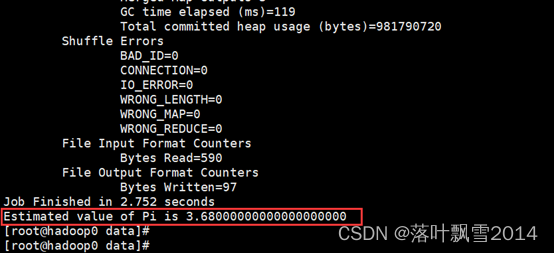
1.8 运行模式
集群运行模式:
1、 将 MapReduce 程序提交给 Yarn 集群, 分发到很多的节点上并发执行
2、 处理的数据和输出结果应该位于 HDFS 文件系统
3、 提交集群的实现步骤: 将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
hadoop jar mr-day01-1.0-SNAPSHOT.jar com.nx.JobMain
[root@hadoop10 data]# hadoop jar mapreduce-1.0-SNAPSHOT.jar com.aa.mapreduce.wordcount.JobMain
[root@hadoop10 home]# hadoop jar mapreduce-1.0-SNAPSHOT.jar com.aa.mr.JobMain
1.9 可能会遇到的错误
[root@hadoop10 home]# hadoop jar mapreduce-1.0-SNAPSHOT.jar com.aa.mr.JobMain
2021-11-12 22:40:52,213 INFO client.RMProxy: Connecting to ResourceManager at hadoop10/192.168.22.136:8032
2021-11-12 22:40:53,180 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2021-11-12 22:40:53,223 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1636727840916_0001
2021-11-12 22:40:53,247 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2021-11-12 22:40:53,299 INFO input.FileInputFormat: Total input files to process : 1
2021-11-12 22:40:54,649 INFO mapreduce.JobSubmitter: number of splits:1
2021-11-12 22:40:54,889 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1636727840916_0001
2021-11-12 22:40:54,890 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-11-12 22:40:55,132 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
2021-11-12 22:40:55,203 INFO conf.Configuration: resource-types.xml not found
2021-11-12 22:40:55,204 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-11-12 22:40:55,669 INFO impl.YarnClientImpl: Submitted application application_1636727840916_0001
2021-11-12 22:40:55,780 INFO mapreduce.Job: The url to track the job: http://hadoop10:8088/proxy/application_1636727840916_0001/
2021-11-12 22:40:55,781 INFO mapreduce.Job: Running job: job_1636727840916_0001
2021-11-12 22:41:08,979 INFO mapreduce.Job: Job job_1636727840916_0001 running in uber mode : false
2021-11-12 22:41:08,979 INFO mapreduce.Job: map 0% reduce 0%
2021-11-12 22:41:15,038 INFO mapreduce.Job: Task Id : attempt_1636727840916_0001_m_000000_0, Status : FAILED
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.aa.mr.WordMapper not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2638)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:187)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:759)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:347)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1762)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
Caused by: java.lang.ClassNotFoundException: Class com.aa.mr.WordMapper not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2542)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2636)
... 8 more
2021-11-12 22:41:21,141 INFO mapreduce.Job: Task Id : attempt_1636727840916_0001_m_000000_1, Status : FAILED
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.aa.mr.WordMapper not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2638)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:187)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:759)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:347)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1762)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
Caused by: java.lang.ClassNotFoundException: Class com.aa.mr.WordMapper not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2542)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2636)
... 8 more
cccc2021-11-12 22:41:26,207 INFO mapreduce.Job: Task Id : attempt_1636727840916_0001_m_000000_2, Status : FAILED
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.aa.mr.WordMapper not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2638)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:187)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:759)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:347)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1762)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
Caused by: java.lang.ClassNotFoundException: Class com.aa.mr.WordMapper not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2542)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2636)
... 8 more
2021-11-12 22:41:33,311 INFO mapreduce.Job: map 100% reduce 100%
上面的报错是说找不到类,但是本质上是主调度入口在集群上运行的时候没有配置好。
解决方案:加上下面的一行代码即可
job.setJarByClass(JobMain.class);
声明:
文章中代码为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接
![[短的文章] Spring Boot 日志创建使用、日志级别、@Slf4j、日志持久化——Spring Boot 系列](https://img-blog.csdnimg.cn/img_convert/13588e5daa7a7d802f61e1a700aaad3d.png)








![[附源码]java毕业设计疫情防控期间网上教学管理](https://img-blog.csdnimg.cn/d902728649074f0db00dee6d44fdda84.png)



![[附源码]java毕业设计疫苗接种管理系统](https://img-blog.csdnimg.cn/9fb81c64f43a42dba18b38e183bb9488.png)