文章目录
- 一、索引是什么?
- 索引的作用
- 二、索引的使用
- 查看索引
- 创建索引
- 删除索引
- 三、索引的底层
一、索引是什么?
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
索引的作用
1.数据库中的表,数据,索引之间的关系,类似于书架上的图书,图书内容,图书目录的关系。
2.顾名思义,索引类似于图书目录,可以快速的定位我们想要看的位置。
3.索引可以大大提高数据库的性能。
索引我们可以例比着书的目录去理解,当我们有了目录的时候,我们就可以很快的找到对应内容的位置。
索引的效果:
加快了查找的速度,进行数据库操作时,常用的操作是增删查改,但是查询是日常业务中最最频繁的操作
同时,索引提高查询速度的同时,也增加了增删改的开销,因为当我们修改操作时,索引也会跟着改变。空间的开销也会增大,需要额外的空间来保存索引。
二、索引的使用
查看索引
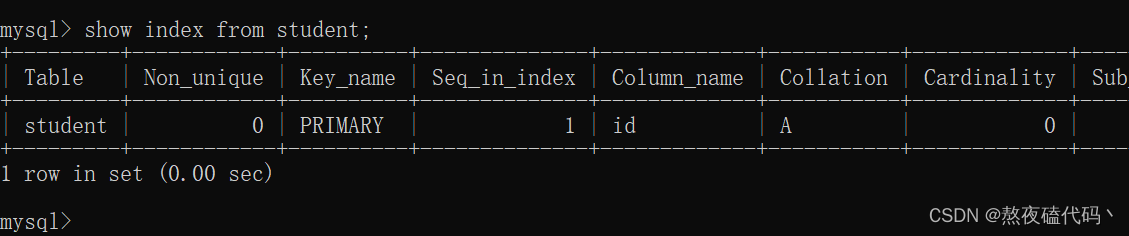
show index from 表名;
-- 创建一个学生表
create table student(id int primary key,name varchar(50));

我们可以发现在学生表中,我们未手动添加索引,但是它会自带一个索引。
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。其实也很好理解,上面这几种情况,在进行相关操作时,都会先对表中相应的列去查询,如果不去添加索引,就会去一条一条去遍历表中的数据,那么效率将大大的低下.
创建索引
create index 索引名 on 表名(字段名);
-- 给学生表名字创建一个索引
create index idx_stu_name on student(name);

我们可以发现成功给name加入了一个索引。
注意事项;
索引虽然是一个很便捷的东西,但是我们使用它的时候一定得小心,我们如果需要加索引的话尽量在创表的时候就搞好,否则将是一个十分危险的操作,如果我们这个时候去创建一个索引的话,就会占据大量的资源(磁盘IO等),就跟我们在写一本书,在写好书之后再去编写目录,索引是同理,是一件很麻烦的事情,会花费大量时间,时间取决于数据量的大小
加上索引后查询一定快吗?
不一定,当数据量特别少,一行行查询可能会更快。
如果你是给大量重复的数据加索引(如性别),也是无法提高查询速度的。
删除索引
drop index 索引名 on 表名;
-- 删除学生表name索引
drop index idx_stu_name on student;
同样的删除索引也是会耗费大量的资源,是一项危险的操作
三、索引的底层
那么索引在MySQL中的数据结构是什么呢?
1.哈希表
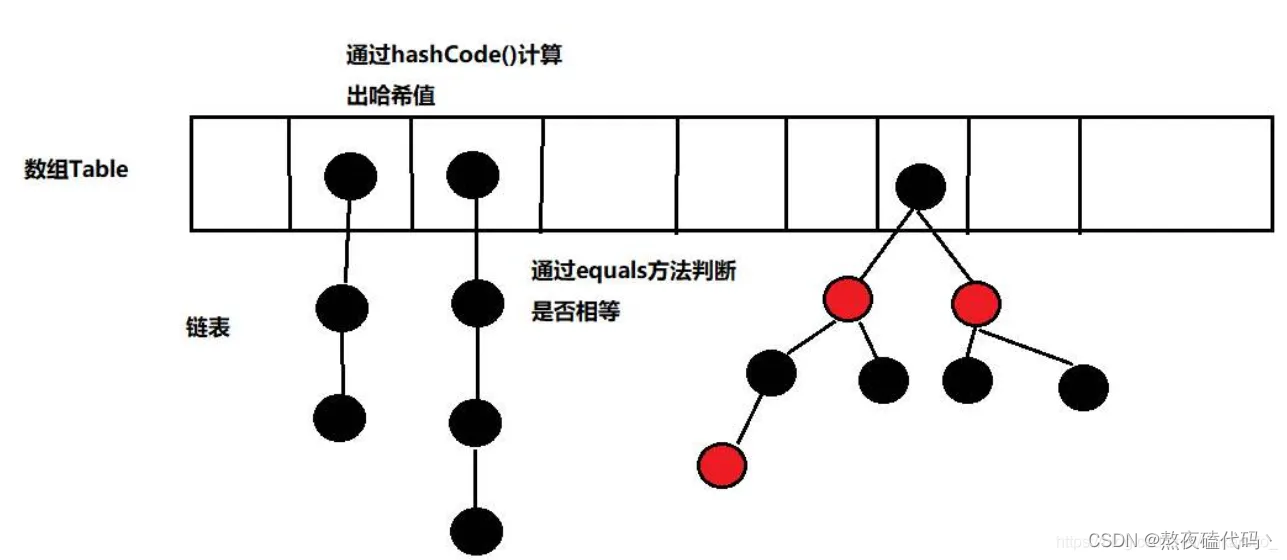
哈希表是一项查询为常数项的数据结构,但是哈希表不适合去当做数据库的索引。因为哈希表虽然查找速度很快,但无法进行between and这样的范围查询。
2.二叉搜索树
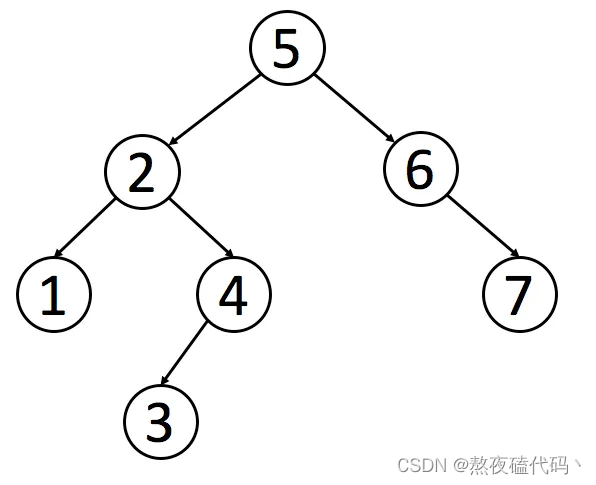
这里我们在查询元素的时候,时间复杂度是多少?
long(N),当这个二叉搜索树是单分支最差情况下,二叉树因为前序遍历是有序的,因次可以满足between and 的范围查询,但是当元素个数增多时,树的高度高时,元素的比较的次数也会增多,硬盘的操作也会增多,因此也不太适合。
3.N叉搜索树
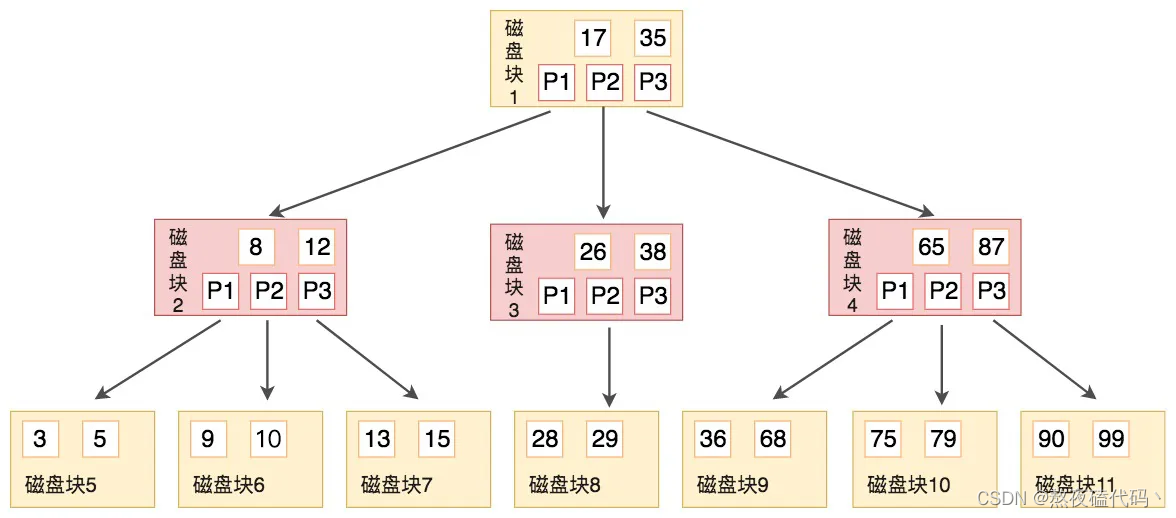
我们可以发现N叉搜索树(B树),在二叉搜索树的基础上,每个节点有多个值,同时有多个分叉,树的高度降低了,比较次数虽然没有减少,但是在硬盘上读的次数减少了许多(因为每次读的操作都是在硬盘上).我们发现B树已经能够做数据库的索引,但是在实际开发中对性能要求远不止此,B+树就是为了索引量身定做。
4.B+树
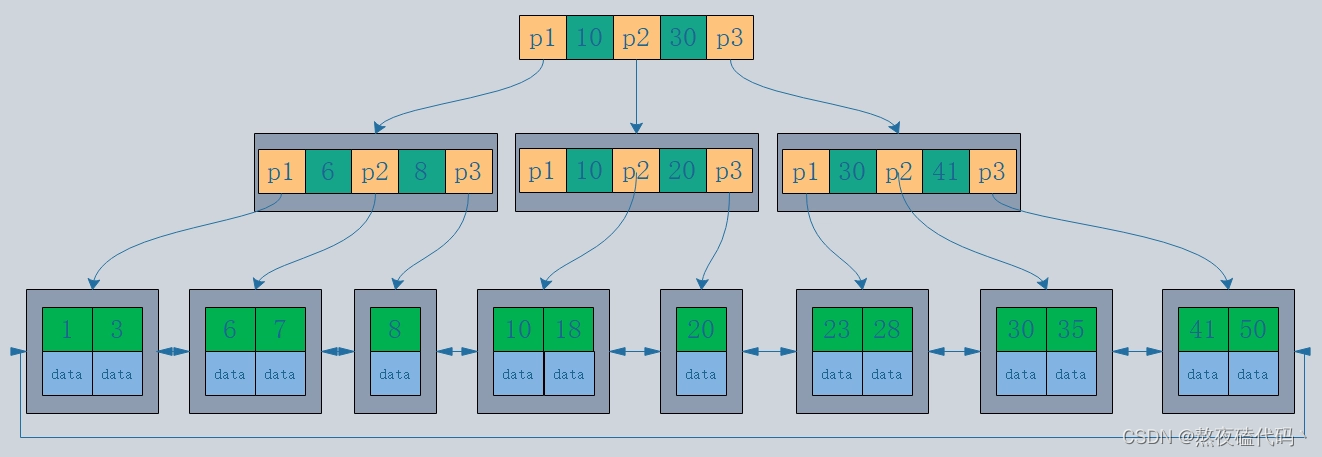
1.B+树是N叉搜索树的一个升级版,每个节点的最后一个值就是局部最大值了。
2.叶子节点会用一个双链表首尾相连,当我们需要进行between and的操作时,只需要root tail 指针指向相应节点,然后遍历即可。
3.父元素会在子节点重复出现,并且是最大值。
B+树的优势:
1.除了叶子节点都是简单的存储了id,最终都会落到叶子结点,所以无论查询那个元素,比较次数大差不差,查询操作不会出现大差异。
2.因为叶子结点存储了所有的key,所以我们只需把真正的数据只存储在叶子结点即可。
3.更适合范围查询,双链表连接。
4.N叉搜索树高度降低了,硬盘上的IO操作大幅度减少。
如果是多索引怎么办?
比如主键索引是id,非主键索引的姓名。
那么姓名索引的B+树的叶子节点存储的都是主键id,找到id后,再去主键索引idB+树去遍历,主键idB+树的叶子节点存储的是完整数据行,此操作成为回表
我们在此处所谈的B+树只是在MySQL的InnDB这个数据库引擎所使用的典型数据结够。不同的数据库有不同的引擎,索引的数据结构也会有所差异。
![[附源码]java毕业设计医疗预约系统](https://img-blog.csdnimg.cn/eb6d2c0baa4249049b763bc872188fef.png)



![[附源码]java毕业设计疫情防控期间人员档案追寻系统设计与实现论文](https://img-blog.csdnimg.cn/d87e22bcb2104277adecdb7ae3df6f7e.png)



![[附源码]SSM计算机毕业设计江苏策腾智能科技公司人事管理系统JAVA](https://img-blog.csdnimg.cn/1fde4f81b3fd451e81bf7cb440197553.png)