目录
概念
特点
优点
缺点
文件的创建
1.字段规则
2.数据类型
3.字段名称
4.字段编号
文件的编译
protobuf 编译命令编译
protobuf cmake 方式编译
使用bazel 编译
在protobuf 文件夹下创建build 文件
代码解释:
样例
protobuf
使用文件
代码解释:
BUILD 文件
编译执行
执行
概念
protobuf 全称 Protocol buffers,是 Google 研发的一种跨语言、跨平台的序列化数据结构的方式,是一个灵活的、高效的用于序列化数据的协议。
protobuf 在游戏领域比较常见,因为压缩比例大,那么数据的传输速度相对比较快。
bazel 中已经集成了protobuf的编译器。
特点
在序列化数据时常用的数据格式还有 XML、JSON等,相比较而言,protobuf 更小、效率更高且使用更为便捷,protobuf内置编译器,可以将protobuf 文件编译成 C++、Python、Java、C#、Go 等多种语言对应的代码,然后可以直接被对应语言使用,轻松实现对数据流的读或写操作而不需要再做特殊解析。
优点
- 高效 —— 序列化后字节占用空间比XML少3-10倍,序列化的时间效率比XML快20-100倍;
- 便捷 —— 可以将结构化数据封装为类,使用方便;
- 跨语言 —— 支持多种编程语言;
- 高兼容性 —— 当数据交互的双方使用同一数据协议,如果一方修改了数据结构,不影响另一方的使用。
缺点
- 二进制格式易读性差;
- 缺乏自描述。
文件的创建
// 使用的 proto 版本, Cyber RT 中目前使用的是 proto2
syntax = "proto2";
//包
package apollo.cyber.demo_base_proto;
//消息 --- message 是关键字,Student 消息名称
message Student {
//字段
//字段格式: 字段规则 数据类型 字段名称 字段编号
required string name = 1;
optional uint64 age = 2;
optional double height = 3;
repeated string books = 4;
}
proto 中的字段语法,字段就格式而言主要有四部分组成:字段规则、数据类型、字段名称、字段编号,接下来分别介绍一下这四种格式。
1.字段规则
字段类型主要有如下三种:
- required —— 调用时,必须提供该字段的值,否则该消息将被视为“未初始化”,不建议使用,当需要把字段修改为其他规则时,会存在兼容性问题。
- optional —— 调用时该字段的值可以设置也可以不设置,不设置时,会根据数据类型生成默认值。
- repeated —— 该规则字段可以以动态数组的方式存储多个数据。
2.数据类型
protobuf 中的数据类型与不同的编程语言存在一定的映射关系,具体可参考官方资料,如下:
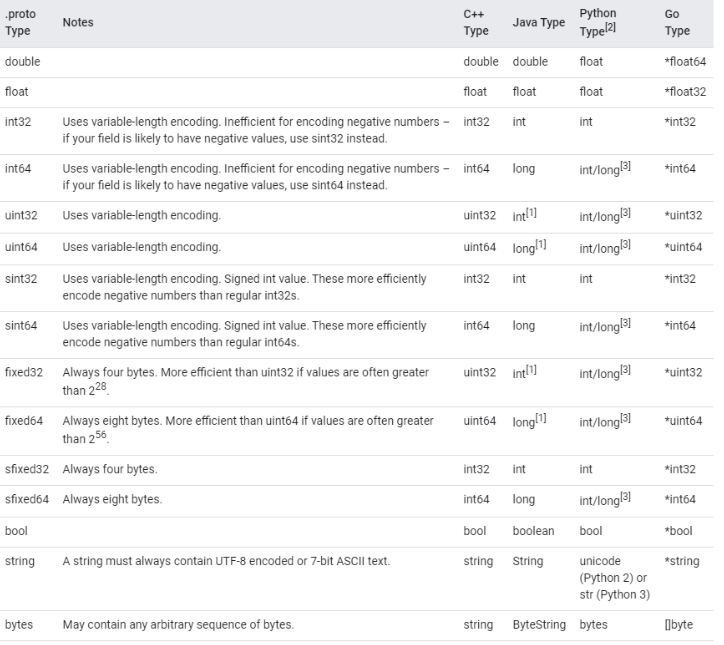
除了上述基本的类型之外也有枚举和字典。
枚举:protobuf中的枚举类型使用方法与C++中的枚举类型类似,在将proto文件编译成C++代码后,其对应的类型也是C++中的枚举类型。
package pkgName;
// 定义枚举类型
enum DayName {
Sun = 0;
Mon = 1;
Tues = 2;
Wed = 3;
Thur = 4;
Fri = 5;
Sat = 6;
}
message workDay {
// 消息类型使用枚举类型
optional DayName day = 1;
}
枚举常量的值必须在32位整数范围内,因为enum值是使用可编码方式存储的,对负数存储不够高效,因此不推荐在enum中使用负数。枚举类型可以定义在message内,也可以定义在message外,若定义在message内,其他message要使用则需要通过messageType.enumType来进行引用。默认情况下,枚举类型中的字段值不可重复,但是通过对enum添加**option allow_alias = true;**来达到对同一个枚举值起一个别名的目的,若不添加allow_alise并且有重复的枚举值编译的时候会报错。
package pkgName;
enum DayName {
// 若不添加该option,会报错:
// "pkgName.Test" uses the same enum value as "pkgName.Sat". If this is intended, set 'option allow_alias = true;' to the enum definition.
option allow_alias = true;
Sun = 0;
Mon = 1;
Tues = 2;
Wed = 3;
Thur = 4;
Fri = 5;
Sat = 6;
Test = 6; // Test与Sat字段值重名
}
map 数据类型:
需要注意:
(1) protobuf中的map实质上是unordered_map
(2) proto中map类型不能用optional/required/repeated任何类型修饰。
package pkgName;
message Tdata {
map<int32,string> data = 1;
}
3.字段名称
字段名称就是变量名,其命名规则参考C++中的变量名命名规则即可。
4.字段编号
每个字段都有一个唯一编号,用于在消息的二进制格式中标识字段。
文件的编译
protobuf 编译命令编译
protoc ./xxxx.proto --cpp_out=.
上面是C++ 相关文件的编译方式,也有java和python的
protobuf cmake 方式编译
# 查找 protobuf
find_package(Protobuf REQUIRED)
if (PROTOBUF_FOUND)
message("protobuf found")
else ()
message(FATAL_ERROR "Cannot find Protobuf")
endif ()
# 编译 proto 为 .cpp 和 .h
set(PROTO_FILES proto/xxxx.proto) # 这里要写实际的proto 文件名称
PROTOBUF_GENERATE_CPP(PROTO_SRCS PROTO_HDRS ${PROTO_FILES})
message("PROTO_SRCS = ${PROTO_SRCS}")
message("PROTO_HDRS = ${PROTO_HDRS}")
# 关联 protobuf 到最后的二进制文件
add_executable(cmake_protobuf
src/users.cpp
src/main.cpp
${PROTO_SRCS}
${PROTO_HDRS})
target_include_directories(${PROJECT_NAME}
PUBLIC ${CMAKE_CURRENT_BINARY_DIR}
PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}
PUBLIC ${PROTOBUF_INCLUDE_DIRS})
target_link_libraries(${PROJECT_NAME} ${PROTOBUF_LIBRARIES})
使用bazel 编译
在protobuf 文件夹下创建build 文件
load("//tools:python_rules.bzl", "py_proto_library")
package(default_visibility = ["//visibility:public"])
proto_library(
name = "student_proto",
srcs = ["student.proto"]
)
cc_proto_library(
name = "student_cc",
deps = [":student_proto"]
)
py_proto_library(
name = "student_py",
deps = [":student_proto"]
)
代码解释:
1.proto_library 函数
该函数用于生成 proto 文件对应的库,该库被其他编程语言创建依赖库时所依赖。
参数:
- name 目标名称
- srcs proto文件
2.cc_proto_library 函数
该函数用于生成C++相关的proto依赖库。
参数:
- name 目标名称
- deps 依赖的proto 库名称
3.py_proto_library 函数
该函数用于生成Python相关的proto依赖库。
参数:
- name 目标名称
- deps 依赖的proto 库名称
注意:
- 使用py_proto_library 必须声明 load("//tools:python_rules.bzl", "py_proto_library")。
- proto_library 函数的参数 name 值必须后缀 _proto 否则,python调用时会抛出异常。
- 为了方便后期使用,建议先添加语句:package(default_visibility = ["//visibility:public"])。
编译方式就是bazel build xxx/xxx/... ,然后就会在这个目录下生成对应的可以调用的中间文件。
样例
protobuf
// 使用的 proto 版本, Cyber RT 中目前使用的是 proto2
syntax = "proto2";
//包
package apollo.cyber.demo_base_proto;
//消息 --- message 是关键字,Student 消息名称
message Student {
//字段
//字段格式: 字段规则 数据类型 字段名称 字段编号
required string name = 1;
optional uint64 age = 2;
optional double height = 3;
repeated string books = 4;
}
使用文件
/*
演示 C++中 protobuf 的基本读写使用
*/
#include "cyber/demo_base_proto/student.pb.h"
int main(int argc, char const *argv[])
{
//创建对象
apollo::cyber::demo_base_proto::Student stu;
//数据写
stu.set_name("zhangsan");
stu.set_age(18);
stu.set_height(1.75);
stu.add_books("yuwen");
stu.add_books("c++");
stu.add_books("Python");
//数据读
std::string name = stu.name();
uint64_t age = stu.age();
double height = stu.height();
std::cout << name << " == " << age << " == " << height << " == ";
for (int i = 0; i < stu.books_size(); i++)
{
std::cout << stu.books(i) << "-";
}
std::cout << std::endl;
return 0;
}
代码解释:
proto 文件生成的对应的 C++ 源码中,字段的设置与获取有其默认规则:
- 如果是非 repeated 规则的字段:那么字段值的设置函数对应的格式为:set_xxx(value),获取函数对应的格式为xxx()。
- 如果是 repeated 规则的字段:那么字段值的设置函数对应的格式为:add_xxx(),获取函数对应的格式为xxx(索引),另外还可以通过函数 xxx_size() 获取数组中元素的个数。
其中 xxx 为字段名称。
BUILD 文件
cc_binary(
name = "test_student",
srcs = ["test_student.cc"],
deps = [":student_cc"],
)
编译执行
bazel build cyber/<user dir>/...
执行
./bazel-bin/cyber/<user dir>/test_student