论文阅读 RL^2 Fast Reinforcement Learning Via Slow Reinforcement Learning
- 1. 摘要
- 2.introduction
- 3. 实现
- 4.小结
1. 摘要
强化学习可以对于单个任务有较好的效果,但需要大量的尝试。动物往往可以通过少量的尝试就获得很好的效果。原因在于动物可以更好地使用先验知识。这篇文章主要通过使用RNN来进行元学习,学习任务的MDP先验知识并保存,进一步将先验知识进行应用,以解决快速学习的问题。
2.introduction
在增加先验知识方面,贝叶斯强化学习为将先验知识纳入学习过程提供了坚实的框架,但贝叶斯更新的精确计算在除最简单的情况外的所有情况下都是困难的。因此,实际的强化学习算法通常结合贝叶斯和特定领域的思想,以降低样本复杂性和计算负担。
本文方法:1. 将代理本身的学习过程视为一个目标,使用标准的强化学习方法来优化。2. 根据特定分布,在所有可能的MDP中对目标进行平均,这反映了我们希望提取到的先验。3. 将代理构造为一个递归神经网络,除了通常接收的观察之外,还接收过去的奖励、动作和终止标志作为输入。4. 它的内部状态在不同时期都保持着,因此它有能力在自己的隐藏激活中进行学习。
3. 实现
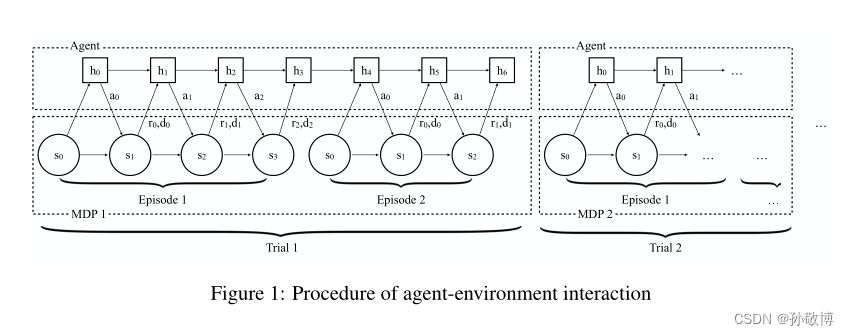
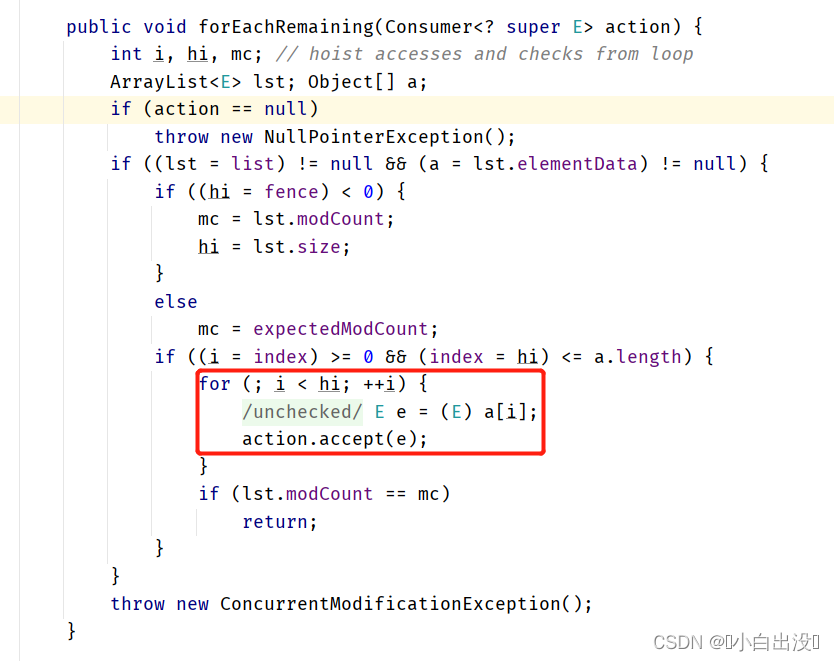
- 核心思想是使用RNN(实现中使用的LSTM,文中说GRU)作为决策网络,利用其记忆能力进行元学习,保留对于旧任务的先验知识。
- 训练的样本定义为Trial,一个Trial是一种任务的几个episode(文中设定2个),文中认为一种任务代表一种MDP。
- 一个Trial中包含两个episode,第一个episode用于智能体进行探索,episode结束后不重置RNN的隐藏层,继续使用其隐藏层进行第二个episode的学习。第二个episode的学习用于使用先验知识进行快速应用。
- 每个任务采样于分布 M ∈ p M M \in p_{M} M∈pM,不同的Trial间的RNN隐藏层是不同的。
- 学习的目标是每个trial的累计奖励,即一个trial中多个episode的累计奖励。
- RNN的输入包括状态、奖励、动作以及结束标志位。同时通过使用标准的RL算法进行训练,本文使用的是TRPO训练RNN。
4.小结
- 这篇文章的主要创新是使用RNN作为策略网络,可以很好的保留同一个Trial中不同episode的隐藏信息,即学习任务或MDP的先验知识。
- 使用Trial的方式设置多种任务,作为训练框架,加速对于不同任务的先验知识学习。
- 引用知乎一位老哥按照inner loop和out loop思路的理解:
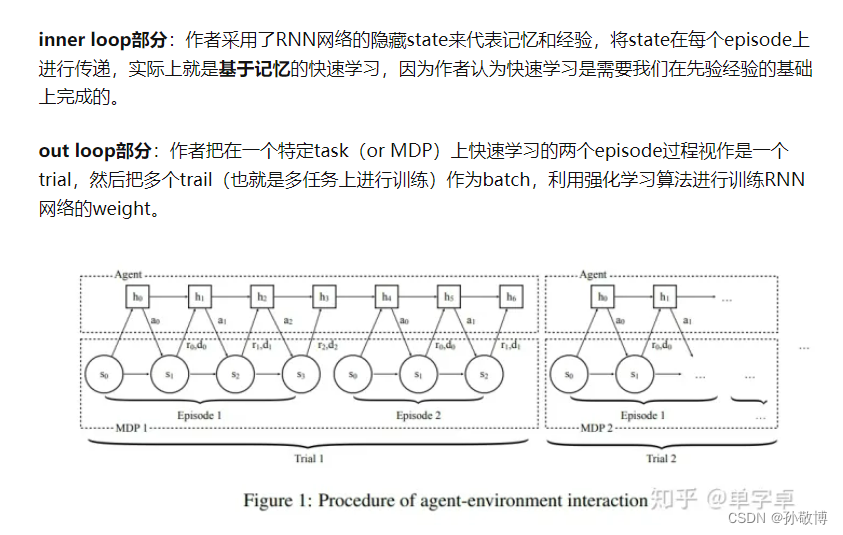
图片来自:https://zhuanlan.zhihu.com/p/252427115