思路
先上一段代码
List<User> userList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
userList.add(new User(i, "wtq", "1234"));
}
userList.stream()
.filter(user -> user.getUserId() > 3)
.filter(user -> user.getUserId() > 4)
.forEach(System.out::println);
Java的stream流, 平时很常用的功能, 让代码变的更简洁, 可读性也更好, 但是完全没有了解过它内部的逻辑. 今天有时间自己尝试梳理了一下源码, 这也算是我第一次独立分析源码, 写的不好还请见谅.
整体逻辑
先在前面总结一下整套流程的大体逻辑.
在学习stream的使用方法时, 就了解到一些流操作分为中间操作和终止操作. 中间操作并不会触发逻辑执行, 真正触发操作执行是终止操作.
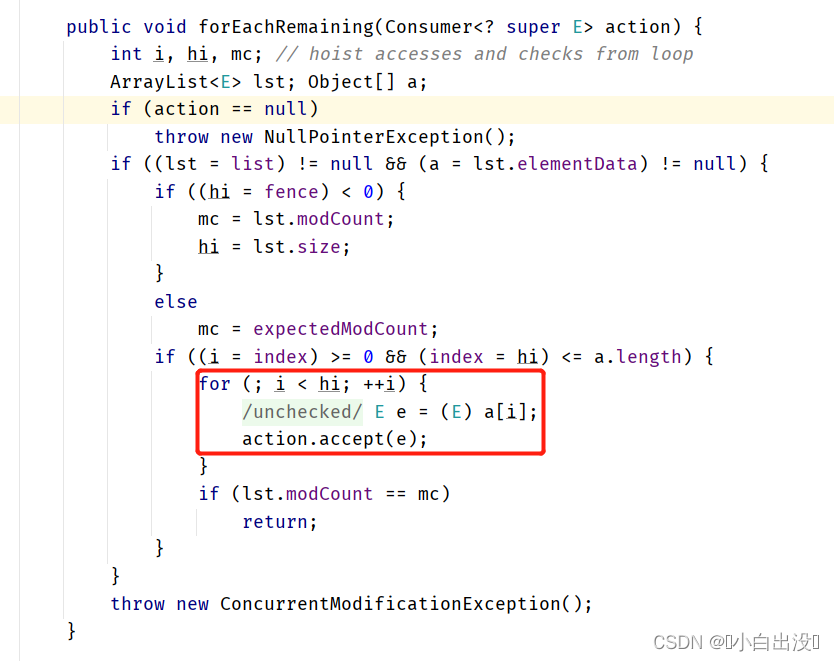
一段流操作中的中间操作在内部使用AbstractPipeline被连接成双向链表的结构, 并使用Sink保存具体的操作方式(如上面的过滤逻辑).
直到有一个中间操作对象调用了终止操作.终止操作需要实现TerminalOp和Sink . 由终止操作构造Sink调用单向链表. 最终将Sink执行链委托给Spliterator调用.
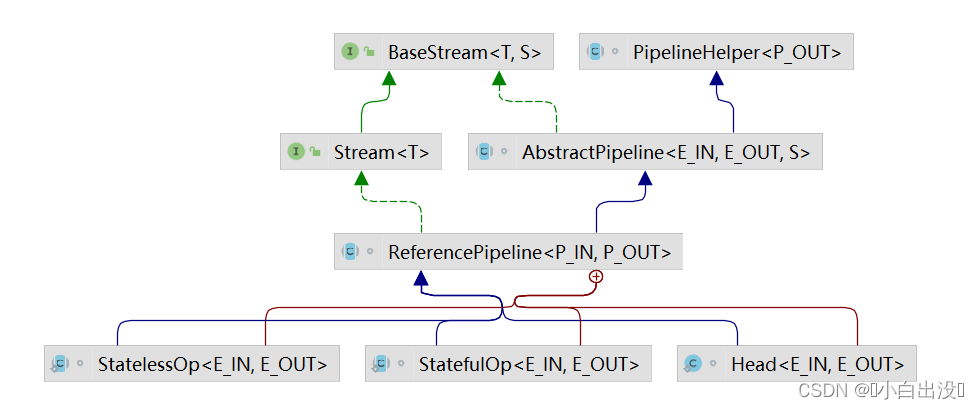
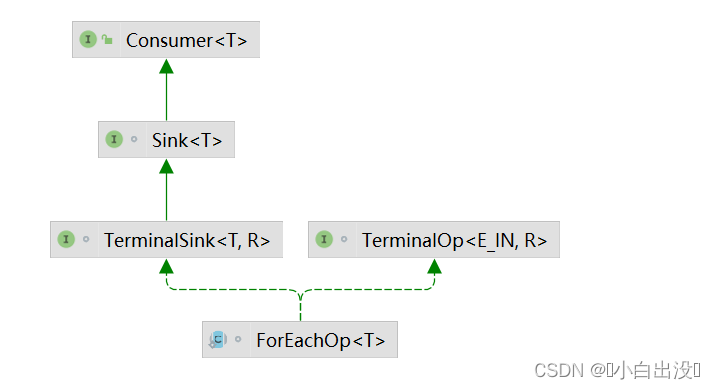
重要的类
AbstractPipeline : 双向链表元素类
Sink : 操作链, 串联整个流操作中的具体逻辑的类
Spliterator : 真正遍历调用操作链的类
这里暂时听不明白没关系, 下面正式进入代码
读代码
stream()
从第一个方法开始分析.

这个方法构造了最初的Stream对象, 第一个参数是通过调用内部方法获取的.先不管这个参数.

点进StreamSupport提供的方法, 可以发现这里的Stream对象的实际类型是ReferencePipeline的内部类Head构造了双向链表的头.
filter() 中间操作
注意, 这里filter()其实是由Head对象调用的, 注意搞清楚this的值.
这里创建了一个StatelessOp.

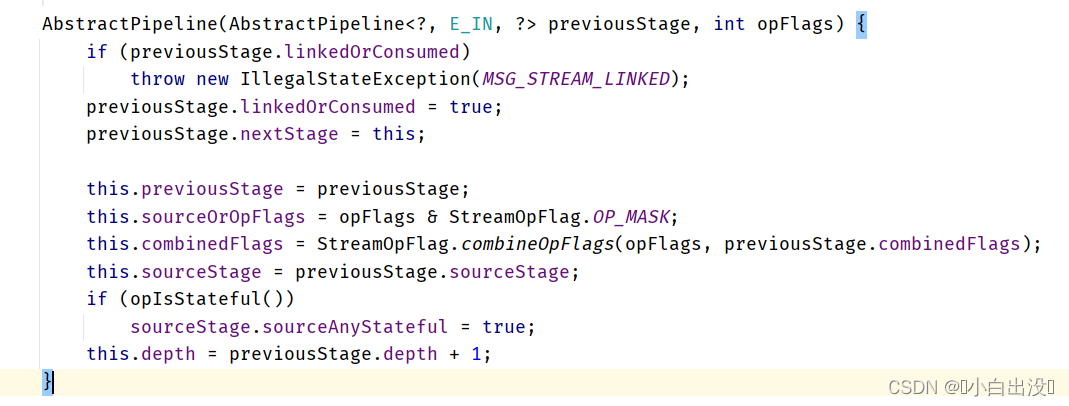
继续追溯构造方法, 实际是调用了AbstractPipeline的构造方法, 此时构造对象的previousStage就是Head. 同时为previousStage的nextStage赋值. 这时候, 双向链表已经有了两个元素.
这里想象一下第二个filter运行时, 会将上一个filter的StatelessOp对象作为previousStage, 执行相同的操作. 做完这些操作, 双向链表里加入了第三个元素.
foreach() 终止操作
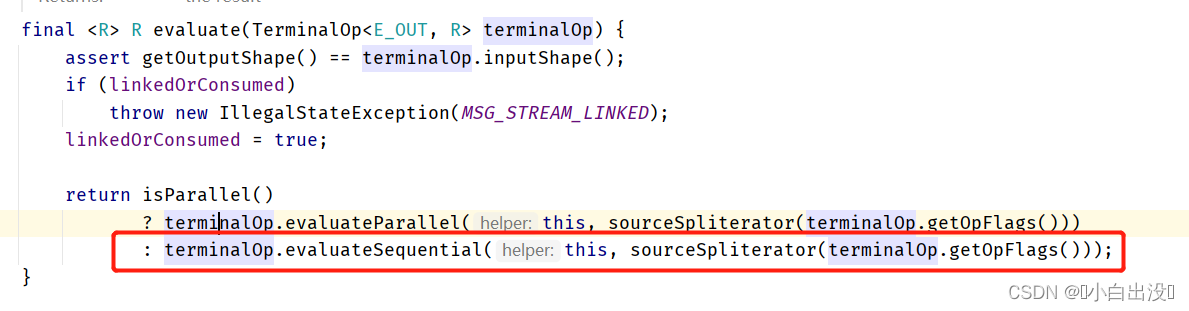
此时终止操作是由最后一个中间操作调用
这里将终止操作的逻辑保存在ForEachOps对象中


由终止操作调用最终评估方法, 将全部中间操作构成的链表传入方法
继续传递

 构造
构造Sink单向链表

将Sink链表传递给Spliterator
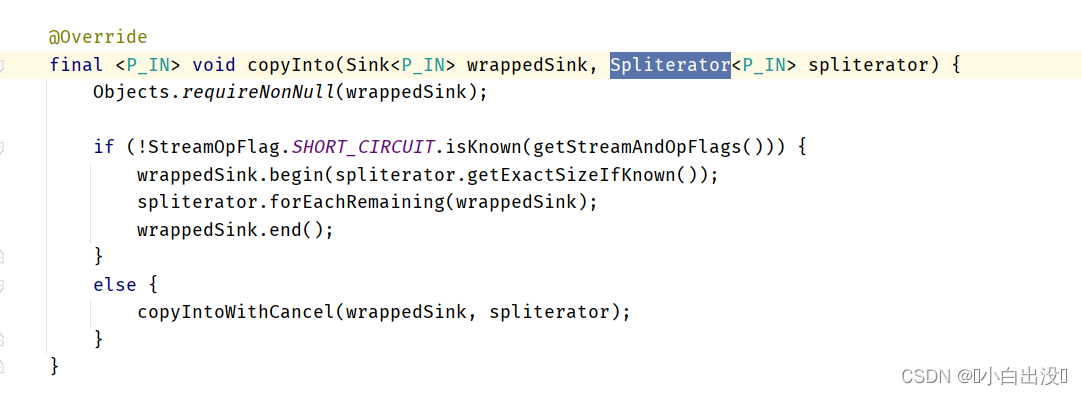
为每个元素调用Sink操作链