「购物车升级」是今年双十一的重要体验提升项目,体现了大淘宝技术人“用技术突破消费者和商家体验天花板”的态度。这是一种敢于不断重新自我审视,然后做出更好选择的存在主义态度。
「体验提升」通常表现在以前需要降级的功能不降级,以前不够实时的数据逐渐实时,以前调用链路的长耗时逐步降低——这通常是庞大的系统工程,需要涉及到的每一个环节(客户端、应用、中间件、数据库、网络、容器、系统内核等组件)提供最强的产品能力来支撑。到数据库这个环节,挑战通常是访问量和连接数暴涨的前提下,仍要保持延时稳定和成本可控。
低延时是这些挑战里面的核心,是内存数据库 Tair 提供的服务本质。在高吞吐、大连接数、热点请求、异常流量、复杂计算逻辑、弹性伸缩这些真实场景下保持稳定的低延时,是 Tair 能够在低延时场景被选择的关键因素。 作为今年支撑购物车升级的核心产品,Tair 使用的内存/SCM 混合存储、水平扩展分区无锁和 SQL 引擎等技术是在支撑十四次双十一的过程中逐渐打磨完善的,在这些技术的基础上 Tair 使用 Fast Path 执行 SQL 、执行器模式及算子适配等技术持续进行服务端优化。本文将围绕 Tair 低延时这一本质特征在构建时所采用的系统手段,藉此提出更多问题来探讨,进一步打造更强大的内存数据库。
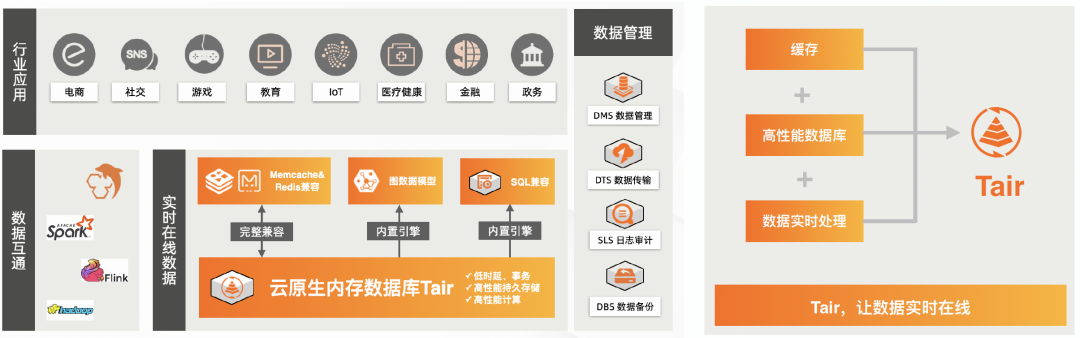
Tair 在低延时场景下的服务能力
低延时的基石
存储引擎的性能是数据库低延时的基石。从功能上看,我们会关心存储引擎提供的并发(线程安全、无锁)、事务处理(MVCC、冲突识别、死锁识别、操作原子性)、快照(标记数据集状态、降低延迟、减少容量膨胀)等能力。这里把并发放到后面论述,先看单次请求的延时,主要涉及到存储介质和数据索引。
存储介质
作为内存数据库,Tair 在绝大部分场景使用单次访问延时在 ns 级别的内存 / SCM 作为主要的存储介质。以 Table 存储为例,服务端的常驻数据大概可以分为 Tuple(可以认为是表里面的某一行)、String Pool、Index 三部分,这些数据都是存放在内存 / SCM 中,只有快照和日志会存放在磁盘上。
除了存储介质的延时,通常我们还需要关心的是介质的成本。成本一方面是从硬件上,Tair 是率先采用 SCM 的云产品,相对于 DRAM,SCM 的密度更高能支持持久化,且成本更低。上面提到的三部分数据结构中, Tuple 和 String Pool 是主要占用数据的空间,存放在空间更大的 SCM 上,Index 需要频繁访问且占用空间更低,存放在空间较小延时更低的 DRAM 上。
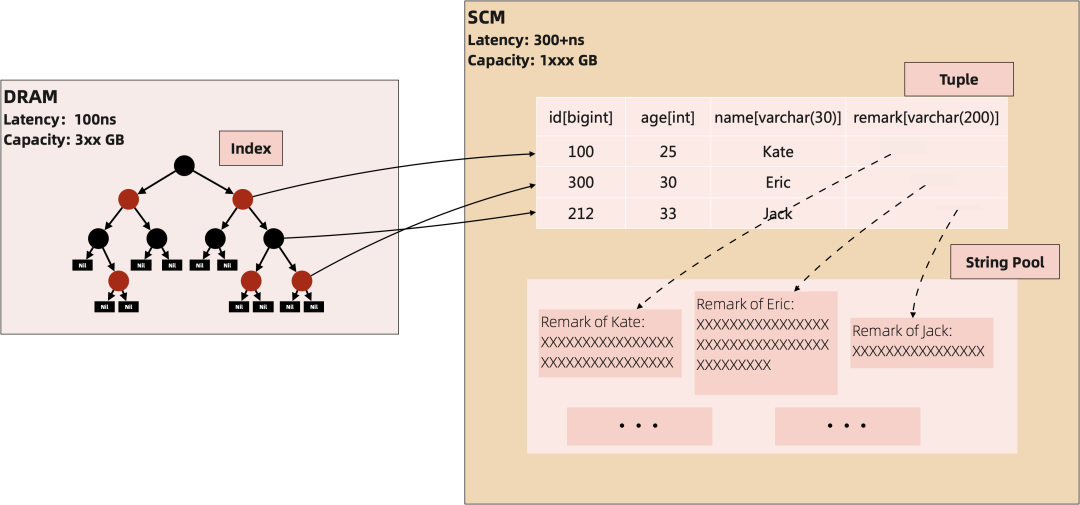
另外一方面是从数据结构上去降低成本,这里的技术手段包括,设计更友好的数据结构和碎片整理的机制、进行透明的数据压缩。Tair 中会以 Page 为单位来管理 Tuple,随着数据的删除,每个 Page 会有一些空闲的 Tuple,存储引擎会按照空闲率来对 Page 分组,当整体的空闲率高于一定阈值(默认是 10%)时,就会试图根据空闲率进行页的合并。
索引
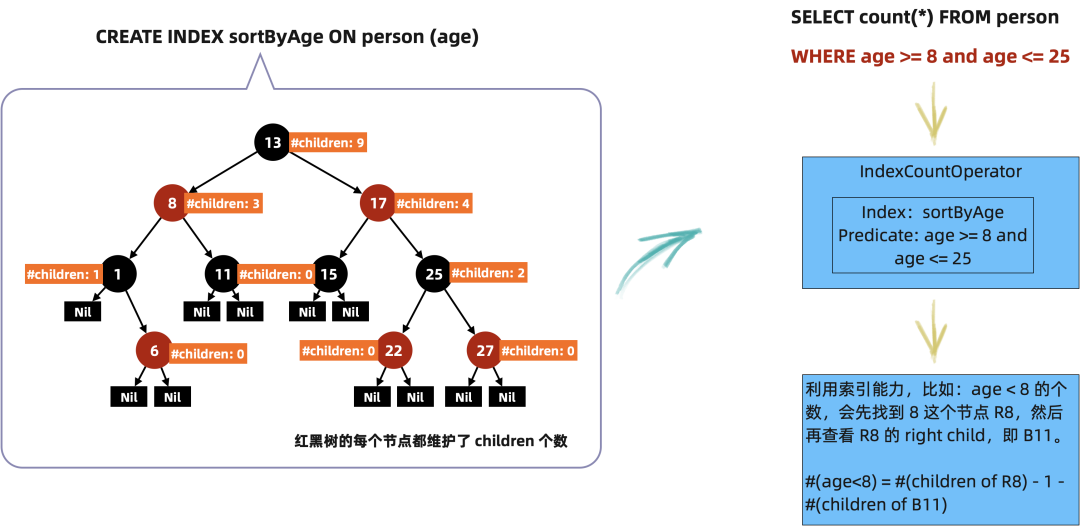
Tair 目前在使用的索引主要有 HashTable、SkipList、RBTree、RTree、Number Tree、Inverted index 等,分别应用于不同的场景。索引和需要服务的模型是相关联的,比如如果服务的主要模型是 Key-Value,那么主索引使用 HashTable 来达到 O(1)的时间复杂度,ZSet 涉及到数据排序和排名的获取,所以 Zset 使用了一个可以在查找时同时获取 Rank 的 Skiplist 作为索引。排序场景使用 SkipList 作为索引是内存数据库中比较常见的方案,相较于 BTree 来说,由于没有 Structure Modification,更易于实现并发和无锁,当然,也会增加一些 Footprint。在 Table 存储中,使用 RBTree 作为排序索引,在数据量达到 10k 的场景下,RBTree 能够提供更稳定的访问延时和更低的内存占用。
在数据库系统中,索引能力的增强还可以让执行器对外暴露更强的算子,比如 Tair 中的 RBTree 提供了快速计算两个值之间 Count 的能力,对外提供了 IndexCountOperator,这样类似于 Select count(*) from person where age >= 8 and age <= 25 的查询就可以直接使用 IndexCountOperator 来获取结果,无需朴素地调用 IndexScanOperator -> AggregateOperator对索引进行扫描才得出结果。
低延时的挑战
合适的存储介质和索引只是提供低延时的一个前提,要在真实环境提供低延时的内存数据库服务,至少需要经历高吞吐的磨练。刚才我们关注了单个请求的延时,介质的延时和索引操作的时间复杂度会影响单个请求的延时。如果一个数据库节点需要承担每秒数十万的请求,这些是不够的,数据库节点需要拥有良好的并发能力。如果吞吐近一步增长,带来的 CPU、网络消耗已经超过了单机的极限的时候,比如大促峰值时 Tair 某集群每秒提供了数千万的读,这些读会带来数万兆的网络流量消耗,这时候就需要产品能够支持水平扩展,“凡治众如寡,分数是也”,把请求散落到不同的 Sharding,提供稳定的低延迟。
高并发
并发是低延时场景一个关键挑战。解法通常分为两种,一种是在存储引擎内部支持更细粒度的锁或者无锁的并发请求;还有一种是在存储引擎外部来进行线程模型的优化,保证某一部分数据(一般来说是一个分区)只被一个线程处理,这样就能够在单线程引擎之上构建出高吞吐的能力。
早期的版本中,Tair 的锁粒度是实例级别的,锁开销损耗较大。为了提升单机的处理能力,Tair 引入了 RCU 无锁引擎,实现内存 KV 引擎的无锁化访问,成倍提升了内存引擎的性能,相关工作发表在 FAST20 上:《HotRing: A Hotspot-Aware In-Memory Key-Value Store》

在提升单机引擎的并发上,SQL 场景使用了另外一种解法,让每一个 Partition 的数据由一个单独的线程来进行处理,这样能在引擎内部通过增加分区达到线性的扩展,而且无需使用前面提到的无锁实现中常会使用的重试步骤。相对于上面的方案,这种方案的工程难度更低,且能够天然地支持 Serializable 的事务隔离级别,某一特定时刻只有一个事务能够运行在特定的分区上,增加 undo buffer 即可以保证事务的原子性。
但是使用这种方式需要满足一些假设:对每个 Partition 的访问是均衡的;跨 Partition 的访问比较少。如果某个 Partition 存在热点访问,也就是明显高出其它的 Partition,由于只有一个线程能处理这个 Partition 的数据,很容易造成这个 Parition 的请求堆积;如果出现跨 Partition 的访问,就需要在各个 Partition 之间做同步,这样也会造成等待并影响并发性能。目前支持的优惠、购物车场景都是用户维度的,表中的 partition column 都是 buyer_id,所以单个请求基本是针对某一个特定分区的,数据链路不存在跨分区请求。数据统计调用的类似于 Select count(*) from table这种请求,由于存储引擎的支持,单分区内可以 O(1) 的时间返回,所以也不存在问题。当然,对于 delete * from table 这种跨分区的写操作,目前会对请求造成秒级抖动,未来会加入 Lazy Free 的处理逻辑,降低对正常请求的影响。
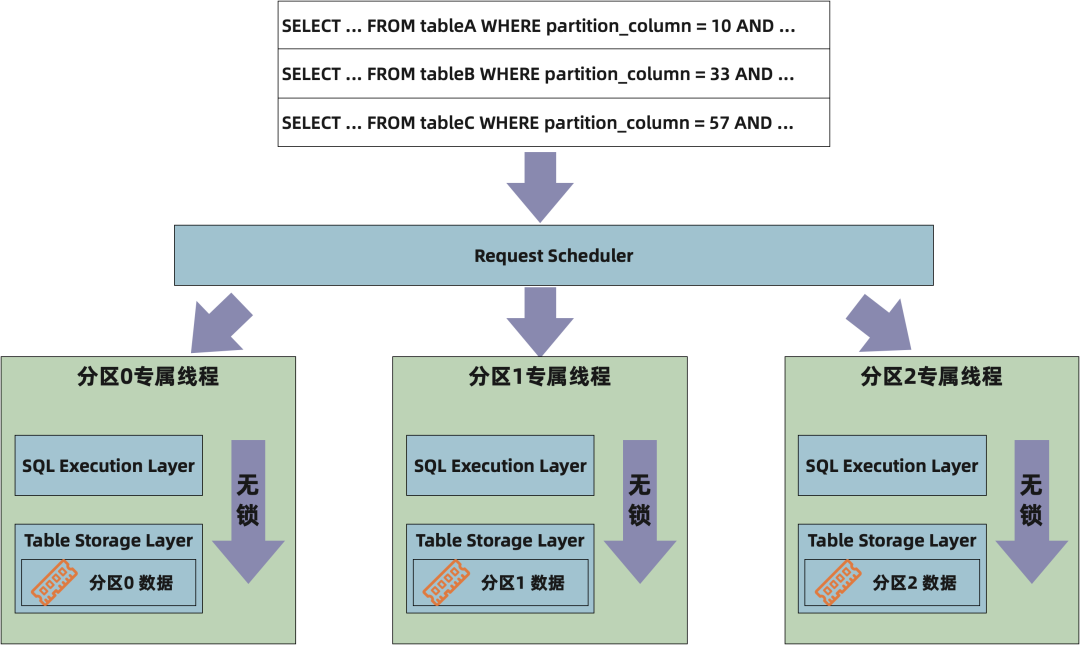
水平扩展
水平扩展是应对高吞吐的有效手段之一。水平扩展为分布式系统带来了应对高吞吐的能力,但同时相对于单节点的系统而言,也会带来很多挑战,比如:跨节点的请求如何保证事务性;如何弹性地进行节点增减;如何应对节点的失效等。在 Tair 的大部分场景而言,并不存在需要保证跨分区请求的原子性。Tair 的 SQL 引擎也支持跨节点的分布式事务,但是这些分布式事务一般不是常规的业务访问,而是运维类的操作。
对于很多系统而言,分区和节点是 N 对1 的关系(常见于 Hash 分区),采用固定的分区数,和动态的节点数是一种常见的解决方案,比如说 Redis Cluster,在这类系统中,弹性地进行节点增减的问题就转换为如何在节点前进行分区迁移的问题。也有一些系统的分区和节点是 1对1 的(常见于 Range 分区),比如 HBase,在这类系统中,弹性伸缩的问题就转换为分区分裂的问题了。
对于节点失效,涉及到判活和后续的数据处理两类的问题。对于很多系统而言,冗余和分片是分开的,比如 Redis Cluster、MongoDB、AnalyticDB Worker,即有一个 HA Group 的概念,HA Group 中的每一个节点,数据是完全一致的。不同系统处理的时候依然会有些区别,一些系统 HA Group 中的某一个节点所有分区都是 Leader,我们称为 Leader 节点,提供读写服务,其它节点只有冗余数据的同步流量,称为 Follower 节点,比如 Redis Cluster,这类系统在调度系统不够成熟的时期,有一个明显的短板就是 Follower 节点所在的机器资源是有空余的,通常是通过朴素的混布来提供资源的利用率,但也带来了部署上的复杂度,所以在系统设计的时候就会有这样的考量:能不能在 HA Group内分散这些分区的 Leader 呢,于是就有了下面这些系统。一些系统 HA Group 的每一个节点都承担部分分区的 Leader,这就是每个节点都会提供读写服务,比如 AnalyticDB Worker。这类有 HA Group 的系统,判活和后续数据处理一般只在 HA Group 内,即某个节点失效后,会把访问流量转移到 HA Group 内的其它节点,然后通过上层的调度在 HA Group 内补充新的节点。还是老问题,在调度系统还不够成熟的时期,补充新的节点也会带来运维的复杂度,那就会有新的考量:能不能跨越 HA Group 的限制,把冗余的个数和系统内节点的个数解耦呢?于是就有了 Kudu 这类系统的架构,冗余和分片是交织起来的,某一个节点失效之后,它上面的分区会由中心节点来调度到其它节点。在调度能力非常成熟的今天,数据库系统自身的能力怎么和数据库相关的调度能力想结合,也会给系统架构带来新的启发。

超大连接数
连接数的限制是一个比较容易被忽略的约束。但在一个真实的系统中,连接数过多会给系统带来巨大的压力。比如说 Redis,即使在 6.0 支持了多 io 之后,能够支持的连接数也是有限的。而目前直接访问 Tair 的应用动辄有 100k 规模的容器数目,所以支持超多连接数是一个必选项。其中涉及到的技术主要是几方面:a. 提高多线程 io 的能力,目前成熟的网络框架基本都有这个能力;b. 把 io 线程和 worker 线程解耦,这样可以独立增强 worker 的处理能力,避免对 io 产生阻塞,当然这个策略取决于 worker 的工作负载,对于单次处理延时稳定较小的场景,支持无锁并发后,整个链路使用 io 线程处理避免线程切换是更优的方案;c. 轻量化连接,把关联到连接上的业务逻辑和 io 功能剥离开,可以更加灵活地做针对性的优化,一些系统中连接对资源的消耗较大,一个连接需要消耗 ~10M 的内存资源,这样连接数就比较难以扩展了。
稳定的低延时
现在有了高效的存储引擎和水平扩展,已经具备了提供低延时和高吞吐服务的能力,但是成为一个健壮地提供低延时的数据库系统还需要能够应对一些异常的场景,比如说某一个分区有热点访问,比如说某个租户的流量异常对其它租户产生干扰,比如说某些慢请求消耗了大量的服务资源。本章节将介绍 Tair 是如何处理这些“异常”场景来提供稳定的低延时的。
热点策略
热点访问是商品维度、卖家维度的数据常常会遇到的一个挑战,热点方案也是 Tair 能够服务于低延时场景的关键能力。前面讲了水平扩展之后,用户的某个请求就会根据一定的规则(Hash、Range、List 等)路由到某一个分区上,如果存在热点访问,就会造成这一个分区的访问拥塞。处理热点有很多方案,比如二级散列,这种方案对于热点的读写可以做进一步拆分的场景是有用的,比如现在我们有一个卖家订单表,然后卖家 id 是分区列,则我们可以再以订单 id 做一次二级散列,解决一个大卖家导致的热点问题;目前淘宝大规模使用的 Tair 的 KV 引擎不满足使用二级散列的前提,一般来说商品的信息映射到 Tair 内就是某一个 Value,更新和读取都是原子的。所以 Tair 目前使用的方案是在一层进行散列,借助于和客户端的交互,将热点数据分散到集群当中的其它节点,共同来处理这个热点请求,当然这种方案需要应用接受热点在一定时间内的延迟更新。另外这种方案需要客户端和服务端协同,需要应用升级到对应的客户端才能使用。所以最新的 Tair 热点策略在兼容社区 Redis 的服务时使用了不同的方案,应用能够直接使用任一流行的开源客户端进行访问,因此需要在服务端提供独立的热点处理能力。目前的 Tair 热点能力是由 Proxy 来提供的,相对于 Tair 之前的方案,这种方案拥有更强大的弹性和更好的通用性。
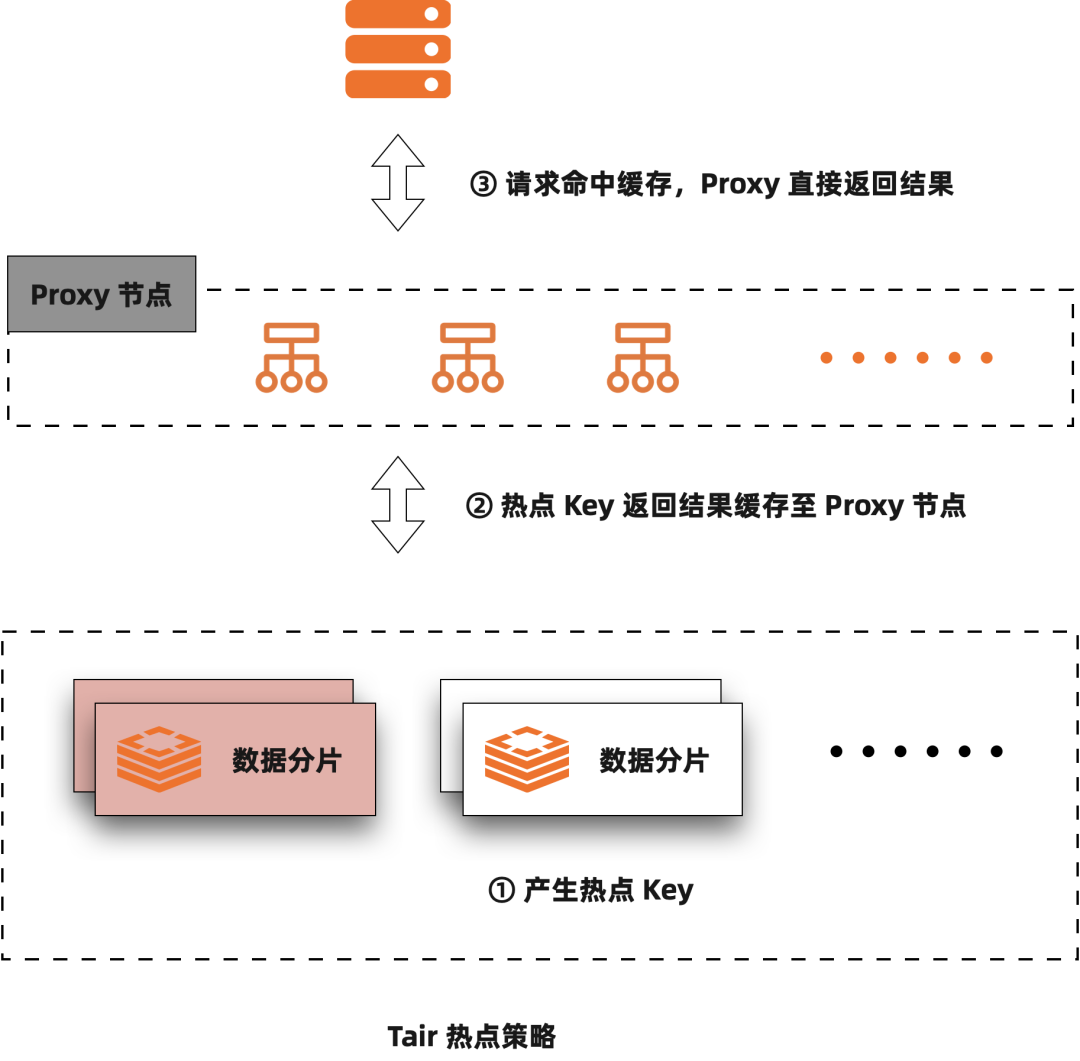
流控
服务于多租户的数据库系统,解决资源隔离的问题通常需要对进行容量或者访问量的配额管理来保证 QoS。即使服务于单租户的系统,也需要在用户有突发异常流量时,保证系统的稳定性,识别出异常流量进行限制,保证正常流量不受影响,比如 Tair 中对于 慢 SQL 识别和阻断。再退一步,即使面对无法识别的异常流量,如果判断请求流量已经超过了服务的极限,按照正常的行为进行响应会对服务端造成风险,需要进行 Fast Fail,并保证服务端的可用性,达到可用性防御的目的,比如 Tair 在判断有客户端的 Output Buffer 超过一定内存阈值之后,就会强制 Kill 掉客户端连接;在判断目前排队的请求个数或者回包占用的内存超过一定阈值之后,就会构造一个流控的回包并回复给客户端。
流控一般包含以下几部分内容:请求资源消耗的统计,这部分是为流控策略和行为提供数据支撑;流控的触发,一般是给资源消耗设定一个阈值,如果超过阈值就触发;流控的行为,这部分各个系统根据服务的场景会有较大的不同;最后的流控的恢复,也是就是资源消耗到达什么情况下解除流控。
执行流程优化
经典的 NoSQL 系统,提供的 API 都是和服务端的处理流程非常耦合的,比如说 Redis 提供了很多 API,光是 List 就有 20 多个接口。在服务端其实很多接口的执行过程中的步骤是比较类似的,比如说有一些 GenericXXX 的函数定义。我们再看看一般的 RDBMS 中的处理 SQL 的流程,一般是 解析(从 SQL 文本到 AST),然后是优化器编译 (把 AST 编译成算子,TableScan、Filter、Aggregate),然后是执行器来执行。类比到 Redis 中,用户传进来的就是 AST,且服务端已经预定了执行计划,直接执行就行了。如果我想使用 SQL,不想学习这么多 API,同时由于我的访问场景是比较固定的,比如进行模板化之后,只有十多种 SQL 语句,且访问的数据比较均衡,某一条特定的语句所有的参数用一条特定的索引就足够了,有没有办法在执行过程中省去解析、编译的开销来提高运行的效率?有很多同学可能已经想到了存储过程。是的,存储过程很多场景是在扩充表达能力,比如多条语句组成的存储过程,需要进行比较复杂的逻辑判断,单条语句存储过程本质上是在灵活性和性能上进行折衷。Tair 所有线上运行的 SQL 都是预先创建存储过程的,这样进行访问就类似于调用 Redis 的一个 API 了,这是在复杂计算逻辑的场景下保证低延时的一种方案。

很多熟悉数据库实现的同学对火山执行模型都不陌生,tuple-at-a-time 的执行方式会消耗比较多的 cpu cycle,对 cache locality 也不太友好。在分析场景,通常会引入 code-gen 技术来进行优化,比如 Snowflake、GreenPlum。Tair 中使用 Pipeline 执行模型,使用 Bulk Processing 更适合目前应用的 TP 场景。使用 Pipeline 执行模型对于算子的设计和执行计划的生成更有挑战,以 Scan 算子为例,Scan 算子中内联了 Filter、Aggregate 和 Projection,Scan 算子本身逻辑比较多,且在执行计划编译过程需要在逻辑优化阶段进行算子内联的转换。
更多场景的低延时
从最早的 KV 到扩展的 Pkey-Skey-Value,再到 List、Zset,再到支持地理位置的 GIS,再到支持全文索引的 Search 和 Table 结构 的 SQL,Tair 早已不再是一个单纯用来存储热数据的缓存,而是能够把更多存储上构建的计算能力方便地提供给业务使用的内存数据库。这一章节介绍内存数据库 Tair 在双十一场景的应用。
购物车使用 Tair 支撑容量升级
提到 MySQL,开发者很容易想到 Table 模型,想到 SQL 查询来进行过滤、排序、聚合等操作;想到 Redis,很容易想到高吞吐、低延时。使用 Redis 来进行读加速的场景,都需要把 MySQL 中数据查询出来之后,序列化到某一个 Value,加速场景直接获取 Value 即可,无需再进行过滤、排序等操作。如果一个读加速的场景不仅需要高吞吐低延时,也需要进行过滤等操作,Redis 还能够满足需求么?更进一步,如果引入读加速的过程中不希望改变数据模型,依然希望使用表模型,省去模型转换的心智负担,同时拥有高吞吐低延时,支撑 10w 级别的连接数,需要使用什么产品呢?目前优惠查询和购物车的场景的需求抽象出来就是这样,这种需要关系型数据库超级只读的场景就需要引入 Tair 的 SQL引擎,兼有 MySQL 和 Redis 优势的产品。

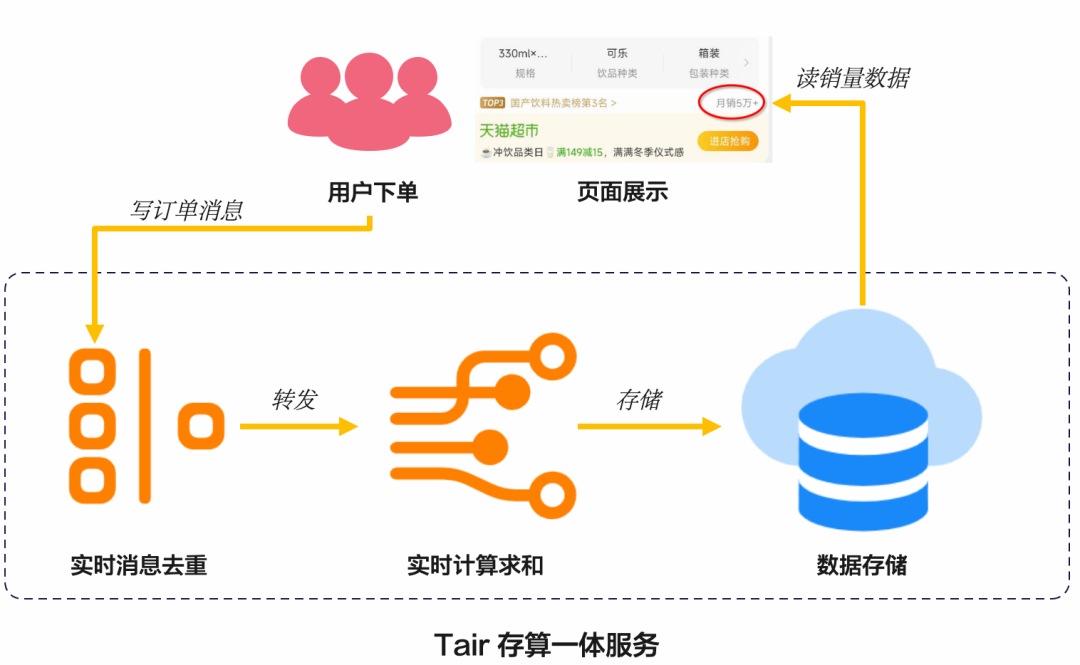
销量统计使用 Tair 提升实时计算
历史上双十一因无法解决销量的实时计算问题对商家产生过很多困扰。为应对2022年双十一,Tair 销量计数项目应运而生:利用已有的 Tair 非精确“去重计数”算子开发新的“去重求和”算子,解决用户商品销量计数慢而无法实时获得销量数据的痛点问题。通过对用户的商品订单消息进行原子地“去重和销量的实时求和”能力,双十一首次做到了“买家订单数不降级”、“商品月销量不降级”两项大促核心体验。同时,利用 Tair-PMem 底座进一步帮助用户降低使用成本,提升数据持久化能力。相比于传统的 AP 类数据库,通过开发的独特非精确计算算子,有效降低了单 QPS 的计算成本。
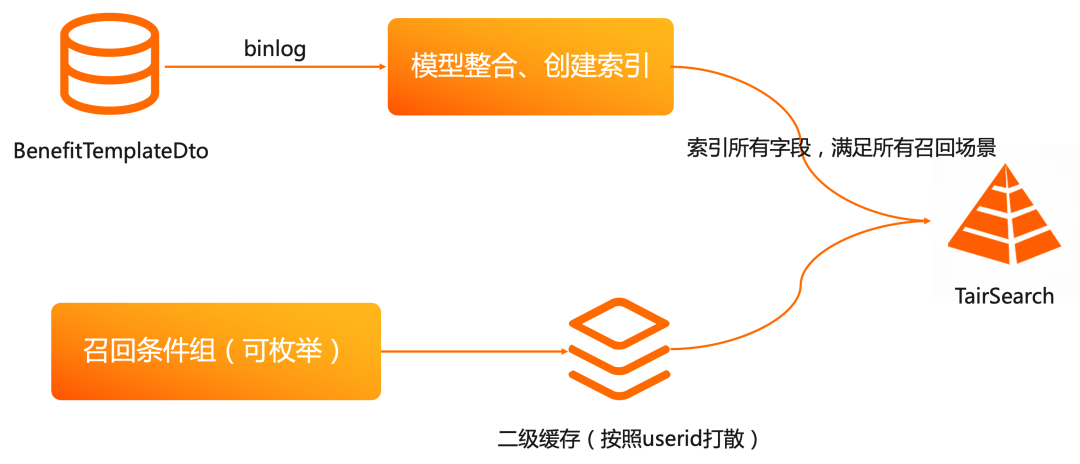
淘菜菜使用 Tair 进行卖家优惠券召回
淘菜菜是阿里社区电商对外的统一品牌,卖家维度的优惠券召回作为一个重要的功能模块,需要搜索系统满足低成本、实时索引和低延迟的搜索能力。鉴于之前使用的搜索系统无法满足需求,淘菜菜今年双十一首次使用 TairSearch 能力实现卖家维度优惠券召回功能,Tair 以其高效实时的内存索引技术为商家提供更加平滑友好的操作体验。
TairSearch 是Tair自主研发的高性能、低延时、基于内存的实时搜索特性,不但增强了 Tair 在实时计算领域的能力,还和现有的其他数据结构一起为用户提供一站式的数据解决方案。Tair采用了和 ElasticSearch(下文称之为ES)相似的基于 JSON 的查询语法,满足了灵活性的同时还兼容ES用户的使用习惯。Tair 除了支持 ES 常用的分词器,还新增JIEBA 和 IK 中文分词器,对中文分词更加友好。Tair支持丰富的查询语义和聚合能力,并且支持索引实时更新和局部更新。Tair 可以通过 msearch 方案实现索引的分片和搜索能力,并通过读写分离架构实现搜索性能的水平扩展。

判店场景使用 Tair 解决热点商家判店
随着同城购业务的兴起,商户判店场景越来越流行,判店就是商家给自己的一个门店圈出来一个销售范围,可以是行政区域,也可以是不规则形状,或者按照半径圈选,如果消费者在这个销售范围内就认为门店对该消费者可售,如果不在消费范围内则不可售,抽象此模型则是:点和多边形包含关系的判断。
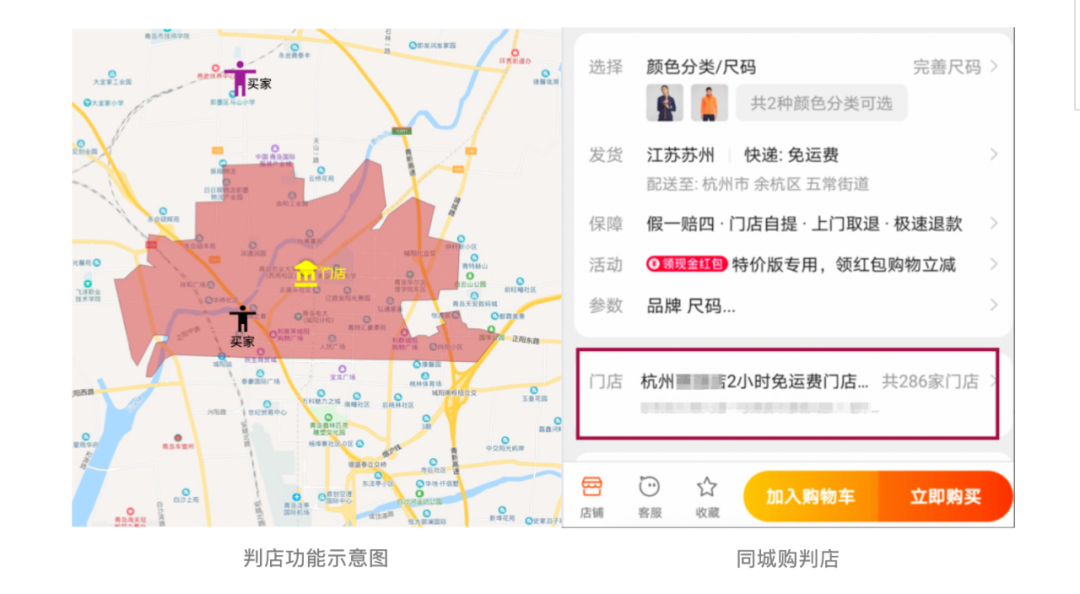
传统的判店架构使用 MySQL 或者 PostGis 数据库,虽然其对 GIS 相关能力有专业的支持,API 也比较完备,但是由于其本身磁盘存储的特性,查询速度较慢,特别是数据量较大的场景下,产生多次磁盘读 IO,导致业务查询超时。
新一代判店系统,依托 Tair 的 Gis 能力,底层使用 RTree 结构,支持常见的 Contains, Within, Intersects 等关系判断,可以在 ms 级别返回查询数据,目前已经在淘菜菜、天猫超市、淘鲜达、盒马、同城购等多个业务使用。
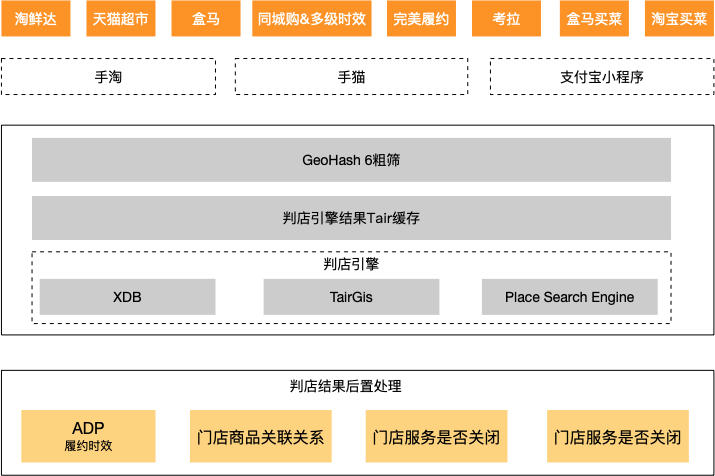
TairGis 的新一代判店系统
互动场景使用 Tair 多种高性能数据结构快速支撑业务
双十一主互动场景一直是技术挑战最大的场景之一,一方面参与活动的用户数量大,在活动时间集中活跃,带来的大量的访问请求对数据库层面的冲击尤其巨大;另一方面要求活动体验不降级,对延时的要求更高。今年主互动活动--猜价格,使用了 Tair 单一数据库的模式支撑了整个互动活动。在主互动场景中,Tair 作为KV数据库支撑几乎所有的数据存储和读写,后端无 DB 兜底,是唯一的数据源,除了要求读写的低延迟、高并发以外,还要求数据的绝对安全无丢失。
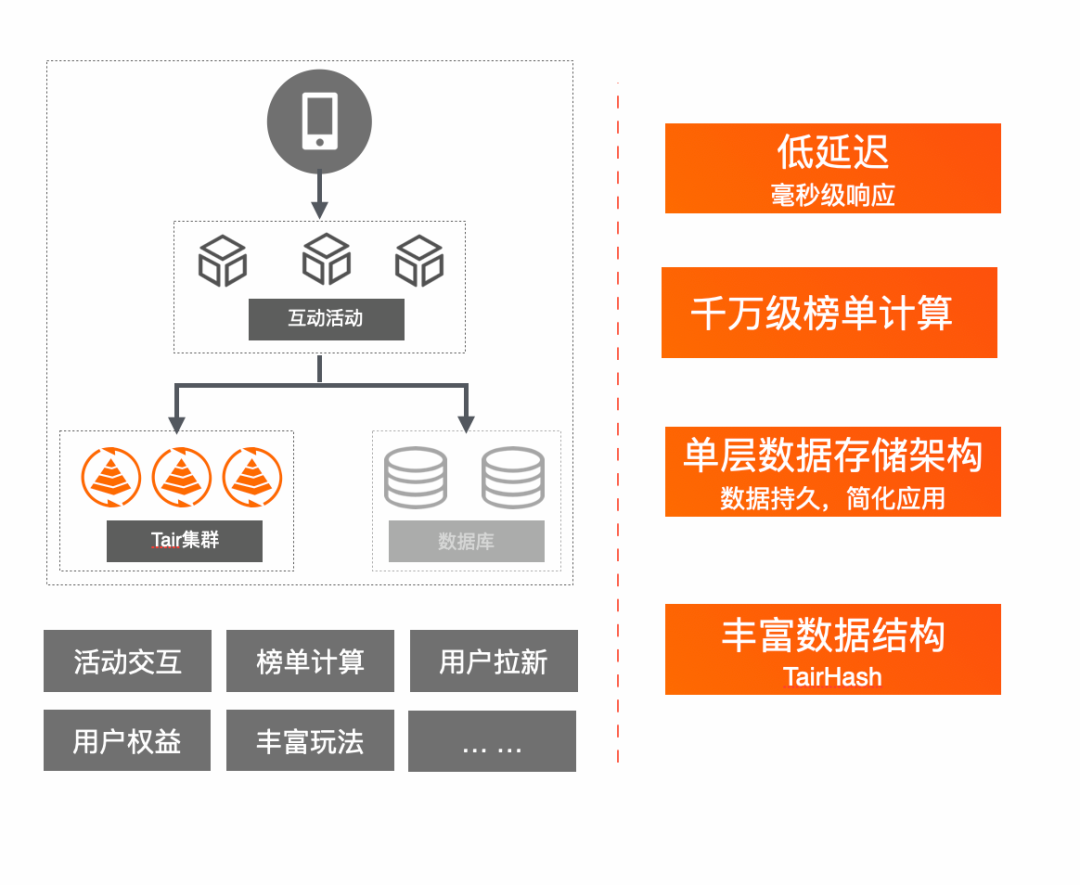
TairHash 提供的高并发写入能力确保了千万级用户的答案提交顺畅;TairZSet 提供的有序数据结构,帮助应用在10s内计算出千万体量的用户分数排行榜,并支撑快速查询;带有二级Key 主动过期的 TairHash 为业务设计复活卡、拉新、锦鲤抽奖等多种玩法提供了方便而强大的技术支撑。
Tair 已经在这一类需要低延迟、高并发、数据安全、快速开发的业务场景中表现出了强大的能力,还将持续追求更高性能、更易用、更安全。
写在最后
在产品力上,Tair 提供了远远不止以上围绕着低延时来打造的产品能力,比如数据多副本管理、全球多活、任意时间点恢复、审计日志等等。同时 Tair 在兼容 Redis 之外,提供了丰富的数据处理能力和基于不同存储介质的混合引擎来提升性价比。
2022 年还有一些其它的事情在发生:Tair 的论文发表在数据库领域顶会 VLDB ,云原生内存数据库 Tair 独立产品上线阿里云官网,Tair 全自研 Redis 兼容内核在公共云所有 Region 上线等等。有一些成绩,也有很多挑战,还有更多机会。Tair 会将已经具备的能力建设得更通用,并在新的领域寻求新的突破,在更丰富的低延时场景承担起更重要的责任,为客户创造更多价值。