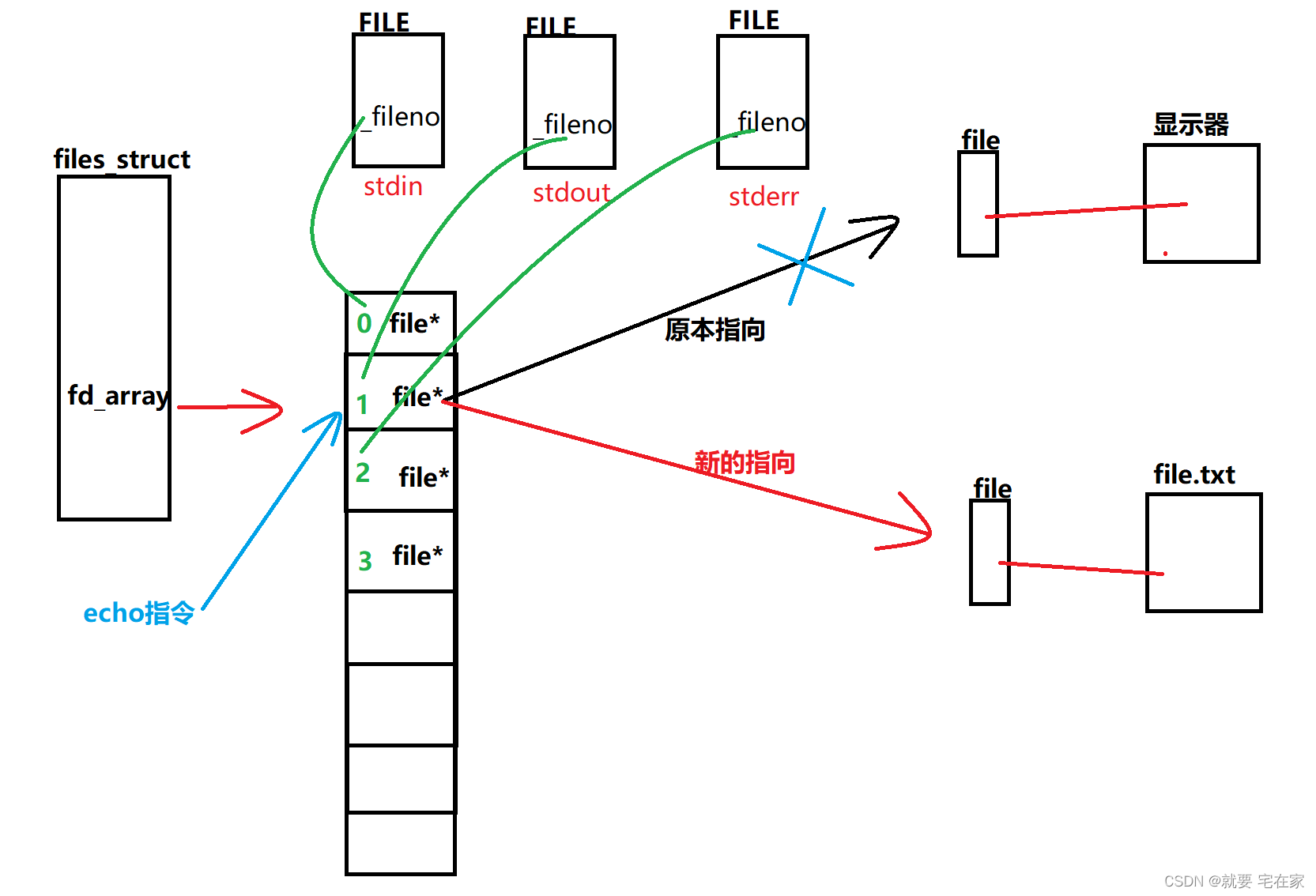
DRY原则
Don’t Repeat Yourself。中文直译为:不要重复自己。即,不要写重复的代码。
我们主要讲三种典型的代码重复情况:实现逻辑重复、功能语义重复和代码执行重复。
实现逻辑重复
public class UserAuthenticator {
public void authenticate(String username, String password) {
if (!isValidUsername(username)) {
// ...throw InvalidUsernameException...
}
if (!isValidPassword(password)) {
// ...throw InvalidPasswordException...
}
//...省略其他代码...
}
private boolean isValidUsername(String username) {
// check not null, not empty
if (StringUtils.isBlank(username)) {
return false;
}
// check length: 4~64
int length = username.length();
if (length < 4 || length > 64) {
return false;
}
// contains only lowcase characters
if (!StringUtils.isAllLowerCase(username)) {
return false;
}
// contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = username.charAt(i);
if (!(c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.') {
return false;
}
}
return true;
}
private boolean isValidPassword(String password) {
// check not null, not empty
if (StringUtils.isBlank(password)) {
return false;
}
// check length: 4~64
int length = password.length();
if (length < 4 || length > 64) {
return false;
}
// contains only lowcase characters
if (!StringUtils.isAllLowerCase(password)) {
return false;
}
// contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = password.charAt(i);
if (!(c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.') {
return false;
}
}
return true;
}
}
在代码中,有两处非常明显的重复的代码片段:isValidUserName() 函数和 isValidPassword() 函数。重复的代码被敲了两遍,或者简单 copy-paste 了一下,看起来明显违反 DRY 原则。为了移除重复的代码,我们对上面的代码做下重构,将 isValidUserName() 函数和 isValidPassword() 函数,合并为一个更通用的函数 isValidUserNameOrPassword()。重构后的代码如下所示:
public class UserAuthenticatorV2 {
public void authenticate(String userName, String password) {
if (!isValidUsernameOrPassword(userName)) {
// ...throw InvalidUsernameException...
}
if (!isValidUsernameOrPassword(password)) {
// ...throw InvalidPasswordException...
}
}
private boolean isValidUsernameOrPassword(String usernameOrPassword) {
//省略实现逻辑
//跟原来的isValidUsername()或isValidPassword()的实现逻辑一样...
return true;
}
}
经过重构之后,代码行数减少了,也没有重复的代码了,是不是更好了呢?答案是否定的!
单从名字上看,我们就能发现,合并之后的 isValidUserNameOrPassword() 函数,负责两件事情:验证用户名和验证密码,违反了“单一职责原则”和“接口隔离原则”。实际上,即便将两个函数合并成 isValidUserNameOrPassword(),代码仍然存在问题。
因为 isValidUserName() 和 isValidPassword() 两个函数,虽然从代码实现逻辑上看起来是重复的,但是从语义上并不重复。所谓“语义不重复”指的是:从功能上来看,这两个函数干的是完全不重复的两件事情,一个是校验用户名,另一个是校验密码。尽管在目前的设计中,两个校验逻辑是完全一样的,但如果按照第二种写法,将两个函数的合并,那就会存在潜在的问题。在未来的某一天,如果我们修改了密码的校验逻辑,比如,允许密码包含大写字符,允许密码的长度为 8 到 64 个字符,那这个时候,isValidUserName() 和 isValidPassword() 的实现逻辑就会不相同。我们就要把合并后的函数,重新拆成合并前的那两个函数。
尽管代码的实现逻辑是相同的,但语义不同,我们判定它并不违反 DRY 原则。对于包含重复代码的问题,我们可以通过抽象成更细粒度函数的方式来解决。比如将校验只包含 az、09、dot 的逻辑封装成 boolean onlyContains(String str, String charlist); 函数。
功能语义重复
在同一个项目代码中有下面两个函数:isValidIp() 和 checkIfIpValid()。尽管两个函数的命名不同,实现逻辑不同,但功能是相同的,都是用来判定 IP 地址是否合法的。
尽管两段代码的实现逻辑不重复,但语义重复,也就是功能重复,我们认为它违反了 DRY 原则。我们应该在项目中,统一一种实现思路,所有用到判断 IP 地址是否合法的地方,都统一调用同一个函数。
代码执行重复
UserService 中 login() 函数用来校验用户登录是否成功。如果失败,就返回异常;如果成功,就返回用户信息。具体代码如下所示:
public class UserService {
private UserRepo userRepo;//通过依赖注入或者IOC框架注入
public User login(String email, String password) {
boolean existed = userRepo.checkIfUserExisted(email, password);
if (!existed) {
// ... throw AuthenticationFailureException...
}
User user = userRepo.getUserByEmail(email);
return user;
}
}
public class UserRepo {
public boolean checkIfUserExisted(String email, String password) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
if (!PasswordValidation.validate(password)) {
// ... throw InvalidPasswordException...
}
//...query db to check if email&password exists...
}
public User getUserByEmail(String email) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
//...query db to get user by email...
}
}
上面这段代码,既没有逻辑重复,也没有语义重复,但仍然违反了 DRY 原则。这是因为代码中存在“执行重复”。
重复执行最明显的一个地方,就是在 login() 函数中,email 的校验逻辑被执行了两次。一次是在调用 checkIfUserExisted() 函数的时候,另一次是调用 getUserByEmail() 函数的时候。我们只需要将校验逻辑从 UserRepo 中移除,统一放到 UserService 中就可以了。
除此之外,代码中还有一处比较隐蔽的执行重复,实际上,login() 函数并不需要调用 checkIfUserExisted() 函数,只需要调用一次 getUserByEmail() 函数,从数据库中获取到用户的 email、password 等信息,然后跟用户输入的 email、password 信息做对比,依次判断是否登录成功。
实际上,这样的优化是很有必要的。因为 checkIfUserExisted() 函数和 getUserByEmail() 函数都需要查询数据库,而数据库这类的 I/O 操作是比较耗时的。我们在写代码的时候,应当尽量减少这类 I/O 操作。
重构如下:
public class UserService {
private UserRepo userRepo;//通过依赖注入或者IOC框架注入
public User login(String email, String password) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
if (!PasswordValidation.validate(password)) {
// ... throw InvalidPasswordException...
}
User user = userRepo.getUserByEmail(email);
if (user == null || !password.equals(user.getPassword()) {
// ... throw AuthenticationFailureException...
}
return user;
}
}
public class UserRepo {
public boolean checkIfUserExisted(String email, String password) {
//...query db to check if email&password exists
}
public User getUserByEmail(String email) {
//...query db to get user by email...
}
}
怎么提高代码复用性?
减少代码耦合
对于高度耦合的代码,当我们希望复用其中的一个功能,想把这个功能的代码抽取出来成为一个独立的模块、类或者函数的时候,往往会发现牵一发而动全身。移动一点代码,就要牵连到很多其他相关的代码。所以,高度耦合的代码会影响到代码的复用性,我们要尽量减少代码耦合。
满足单一职责原则
如果职责不够单一,模块、类设计得大而全,那依赖它的代码或者它依赖的代码就会比较多,进而增加了代码的耦合。根据上一点,也就会影响到代码的复用性。相反,越细粒度的代码,代码的通用性会越好,越容易被复用。
模块化
这里的“模块”,不单单指一组类构成的模块,还可以理解为单个类、函数。我们要善于将功能独立的代码,封装成模块。独立的模块就像一块一块的积木,更加容易复用,可以直接拿来搭建更加复杂的系统。
业务与非业务逻辑分离
越是跟业务无关的代码越是容易复用,越是针对特定业务的代码越难复用。所以,为了复用跟业务无关的代码,我们将业务和非业务逻辑代码分离,抽取成一些通用的框架、类库、组件等。
通用代码下沉
从分层的角度来看,越底层的代码越通用、会被越多的模块调用,越应该设计得足够可复用。一般情况下,在代码分层之后,为了避免交叉调用导致调用关系混乱,我们只允许上层代码调用下层代码及同层代码之间的调用,杜绝下层代码调用上层代码。所以,通用的代码我们尽量下沉到更下层。
继承、多态、抽象、封装
利用继承,可以将公共的代码抽取到父类,子类复用父类的属性和方法。利用多态,我们可以动态地替换一段代码的部分逻辑,让这段代码可复用。除此之外,抽象和封装,从更加广义的层面、而非狭义的面向对象特性的层面来理解的话,越抽象、越不依赖具体的实现,越容易复用。代码封装成模块,隐藏可变的细节、暴露不变的接口,就越容易复用。
应用模板等设计模式
一些设计模式,也能提高代码的复用性。比如,模板模式利用了多态来实现,可以灵活地替换其中的部分代码,整个流程模板代码可复用。
除此之外,还有一些跟编程语言相关的特性,也能提高代码的复用性,比如泛型编程等。复用意识也非常重要。在写代码的时候,我们要多去思考一下,这个部分代码是否可以抽取出来,作为一个独立的模块、类或者函数供多处使用。在设计每个模块、类、函数的时候,要像设计一个外部 API 那样,去思考它的复用性。
实际上,除非有非常明确的复用需求,否则,为了暂时用不到的复用需求,花费太多的时间、精力,投入太多的开发成本,并不是一个值得推荐的做法。这也违反我们之前讲到的 YAGNI 原则。
除此之外,有一个著名的原则,叫作“Rule of Three”。也就是说,第一次编写代码的时候,我们不考虑复用性;第二次遇到复用场景的时候,再进行重构使其复用。需要注意的是,“Rule of Three”中的“Three”并不是真的就指确切的“三”,这里就是指“二”。
迪米特法则
“高内聚、松耦合”是一个非常重要的设计思想,能够有效地提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。很多设计原则都以实现代码的“高内聚、松耦合”为目的,比如单一职责原则、基于接口而非实现编程等。
实际上,“高内聚、松耦合”是一个比较通用的设计思想,可以用来指导不同粒度代码的设计与开发,比如系统、模块、类,甚至是函数,也可以应用到不同的开发场景中,比如微服务、框架、组件、类库等。
“高内聚”用来指导类本身的设计,“松耦合”用来指导类与类之间依赖关系的设计。不过,这两者并非完全独立不相干。高内聚有助于松耦合,松耦合又需要高内聚的支持。
高内聚:就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一个类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中,代码容易维护。单一职责原则就是实现代码高内聚非常有效的设计原则。单一职责原则
松耦合:在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动不会或者很少导致依赖类的代码改动。实际上,我们前面讲的依赖注入、接口隔离、基于接口而非实现编程,以及迪米特法则,都是为了实现代码的松耦合。
迪米特法则理论描述
Law of Demeter,缩写是 LOD。The Least Knowledge Principle最小知识原则。
Each unit should have only limited knowledge about other units: only units “closely” related to the current unit. Or: Each unit should only talk to its friends; Don’t talk to strangers.
每个模块(unit)只应该了解那些与它关系密切的模块(units: only units “closely” related to the current unit)的有限知识(knowledge)。或者说,每个模块只和自己的朋友“说话”(talk),不和陌生人“说话”(talk)。
将模块换成类:①不该有直接依赖关系的类之间,不要有依赖;②有依赖关系的类之间,尽量只依赖必要的接口(也就是定义中的“有限知识”)。
①不该有直接依赖关系的类之间,不要有依赖
这个例子实现了简化版的搜索引擎爬取网页的功能。代码中包含三个主要的类。其中,NetworkTransporter 类负责底层网络通信,根据请求获取数据;HtmlDownloader 类用来通过 URL 获取网页;Document 表示网页文档,后续的网页内容抽取、分词、索引都是以此为处理对象。具体的代码实现如下所示:
public class NetworkTransporter {
// 省略属性和其他方法...
public Byte[] send(HtmlRequest htmlRequest) {
//...
}
}
public class HtmlDownloader {
private NetworkTransporter transporter;//通过构造函数或IOC注入
public Html downloadHtml(String url) {
Byte[] rawHtml = transporter.send(new HtmlRequest(url));
return new Html(rawHtml);
}
}
public class Document {
private Html html;
private String url;
public Document(String url) {
this.url = url;
HtmlDownloader downloader = new HtmlDownloader();
this.html = downloader.downloadHtml(url);
}
//...
}
NetworkTransporter 类,作为一个底层网络通信类,我们希望它的功能尽可能通用,而不只是服务于下载 HTML,所以,我们不应该直接依赖太具体的发送对象 HtmlRequest。NetworkTransporter 类的设计违背迪米特法则,依赖了不该有直接依赖关系的 HtmlRequest 类。
假如你现在要去商店买东西,你肯定不会直接把钱包给收银员,让收银员自己从里面拿钱,而是你从钱包里把钱拿出来交给收银员。这里的 HtmlRequest 对象就相当于钱包,HtmlRequest 里的 address 和 content 对象就相当于钱。我们应该把 address 和 content 交给 NetworkTransporter,而非是直接把 HtmlRequest 交给 NetworkTransporter。根据这个思路,NetworkTransporter 重构之后的代码如下所示:
public class NetworkTransporter {
// 省略属性和其他方法...
public Byte[] send(String address, Byte[] data) {
//...
}
}
Document 类的问题比较多,主要有三点。第一,构造函数中的 downloader.downloadHtml() 逻辑复杂,耗时长,不应该放到构造函数中,会影响代码的可测试性。第二,HtmlDownloader 对象在构造函数中通过 new 来创建,违反了基于接口而非实现编程的设计思想,也会影响到代码的可测试性。第三,从业务含义上来讲,Document 网页文档没必要依赖 HtmlDownloader 类,违背了迪米特法则。
public class Document {
private Html html;
private String url;
public Document(String url, Html html) {
this.html = html;
this.url = url;
}
//...
}
// 通过一个工厂方法来创建Document
public class DocumentFactory {
private HtmlDownloader downloader;
public DocumentFactory(HtmlDownloader downloader) {
this.downloader = downloader;
}
public Document createDocument(String url) {
Html html = downloader.downloadHtml(url);
return new Document(url, html);
}
}
②有依赖关系的类之间,尽量只依赖必要的接口
Serialization 类负责对象的序列化和反序列化
public class Serialization {
public String serialize(Object object) {
String serializedResult = ...;
//...
return serializedResult;
}
public Object deserialize(String str) {
Object deserializedResult = ...;
//...
return deserializedResult;
}
}
假设在我们的项目中,有些类只用到了序列化操作,而另一些类只用到反序列化操作。这显然违反了迪米特法则,于是拆分为两个更小粒度的类,一个只负责序列化(Serializer 类),一个只负责反序列化(Deserializer 类)。拆后却违背了高内聚的设计思想。高内聚要求相近的功能要放到同一个类中,这样可以方便功能修改的时候,修改的地方不至于过于分散。
怎么两全?通过引入两个接口就能轻松解决这个问题。运用“接口隔离原则”。
public interface Serializable {
String serialize(Object object);
}
public interface Deserializable {
Object deserialize(String text);
}
public class Serialization implements Serializable, Deserializable {
@Override
public String serialize(Object object) {
String serializedResult = ...;
...
return serializedResult;
}
@Override
public Object deserialize(String str) {
Object deserializedResult = ...;
...
return deserializedResult;
}
}
public class DemoClass_1 {
private Serializable serializer;
public Demo(Serializable serializer) {
this.serializer = serializer;
}
//...
}
public class DemoClass_2 {
private Deserializable deserializer;
public Demo(Deserializable deserializer) {
this.deserializer = deserializer;
}
//...
}
尽管我们还是要往 DemoClass_1 的构造函数中,传入包含序列化和反序列化的 Serialization 实现类,但是,我们依赖的 Serializable 接口只包含序列化操作,DemoClass_1 无法使用 Serialization 类中的反序列化接口,对反序列化操作无感知,这也就符合了迪米特法则后半部分所说的“依赖有限接口”的要求。
实际上,上面的的代码实现思路,也体现了“基于接口而非实现编程”的设计原则,结合迪米特法则,我们可以总结出一条新的设计原则,那就是“基于最小接口而非最大实现编程”。新的设计模式和设计原则是怎么创造出来的,实际上,就是在大量的实践中,针对开发痛点总结归纳出来的套路。
为了举例子,其实上面只包含两个操作,确实没有太大必要拆分成两个接口。
但是遇到下面这种多函数多功能的时候,很有必要拆开了。
public class Serializer { // 参看JSON的接口定义
public String serialize(Object object) { //... }
public String serializeMap(Map map) { //... }
public String serializeList(List list) { //... }
public Object deserialize(String objectString) { //... }
public Map deserializeMap(String mapString) { //... }
public List deserializeList(String listString) { //... }
}
1.单一职责原则
适用对象:模块,类,接口
侧重点:高内聚,低耦合
思考角度:自身
2.接口隔离原则
适用对象:接口,函数
侧重点:低耦合
思考角度:调用者
3.基于接口而非实现编程
适用对象:接口,抽象类
侧重点:低耦合
思考角度:调用者
4.迪米特法则
适用对象:模块,类
侧重点:低耦合
思考角度:类关系