🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
标量、向量和空间
处理计数
二值化
量化或合并
固定宽度装箱
分位数分级
日志转换
日志转换在行动
数据可视化的重要性
幂变换:对数变换的推广
特征缩放或归一化
最小-最大缩放
标准化(方差缩放)
不要“居中”稀疏数据!
ℓ 2归一化
数据空间与特征空间
交互功能
特征选择
概括
在深入研究文本和图像等复杂数据类型之前,让我们先从最简单的数据开始:数字数据。这可能来自各种来源:一个地方或一个人的地理定位、购买价格、来自传感器的测量、交通计数等。数字数据已经采用数学模型可以轻松获取的格式。但这并不意味着不再需要特征工程。好的特征不仅应该代表数据的显着方面,还应该符合模型的假设。因此,转换通常是必要的。数字特征工程技术是基础。只要将原始数据转换为数字特征,就可以应用它们。
数字数据的第一个健全性检查是量级是否重要。我们只需要知道它是正面的还是负面的?或者也许我们只需要知道非常粗粒度的大小?这种健全性检查对于自动累积的数字尤其重要,例如计数——每天访问网站的次数、餐厅获得的评论数量等。
接下来,考虑要素的规模。最大和最小值分别是多少?它们跨越几个数量级吗?作为输入特征平滑函数的模型对输入的尺度很敏感。例如,3 x + 1 是输入x的简单线性函数,其输出的尺度直接取决于输入的尺度。其他示例包括k均值聚类、最近邻方法、径向基函数 (RBF) 核以及使用欧几里得距离的任何方法。对于这些模型和建模组件,对特征进行归一化通常是个好主意,以便输出保持在预期范围内。
另一方面,逻辑函数对输入特征尺度不敏感。无论输入是什么,它们的输出都是二进制的。例如,逻辑 AND 取任意两个变量,当且仅当两个输入都为真时输出 1。逻辑函数的另一个例子是阶跃函数(例如,输入x是否大于 5?)。决策树模型由输入特征的阶跃函数组成。因此,基于空间划分树(决策树、梯度提升机、随机森林)的模型对规模不敏感。唯一的例外是如果输入的规模随着时间的推移而增长,如果特征是某种累积计数就是这种情况——最终它将增长到树训练的范围之外。如果是这种情况,则可能需要定期重新调整输入。另一种解决方案是第 5 章中讨论的分箱计数法。
考虑数字特征的分布也很重要。分布总结了取特定值的概率。输入特征的分布对某些模型比其他模型更重要。例如,线性回归模型的训练过程假设预测误差像高斯分布一样。这通常很好,除非预测目标分布在几个数量级上。在这种情况下,高斯误差假设可能不再成立。解决这个问题的一种方法是改变产出目标,以控制增长幅度。(严格来说,这是目标工程,而不是特征工程。)对数变换是一种幂变换,采用分布变量更接近高斯分布。
除了根据模型或训练过程的假设定制特征外,多个特征还可以组合成更复杂的特征。希望复杂的特征能够更简洁地捕捉原始数据中的重要信息。使输入特征更“雄辩”可以让模型本身更简单,更容易训练和评估,并做出更好的预测。极端地说,复杂的特征本身可能是统计模型的输出。这是一个称为模型堆叠的概念,我们将在第7章和第8章中更详细地讨论它。在本章中,我们给出复杂特征的最简单示例:交互特征。
交互特征很容易制定,但是特征的组合导致更多的特征被输入到模型中。为了减少计算开销,通常需要使用自动特征选择来修剪输入特征。
我们将从标量、向量和空间的基本概念开始,然后讨论尺度、分布、交互特征和特征选择。
标量、向量和空间
在我们继续之前,我们需要定义一些构成本书其余部分基础的基本概念。单个数字特征也称为标量。一个有序列表标量被称为矢量。向量坐在向量空间内。在绝大多数机器学习应用程序中,模型的输入通常表示为数字向量。本书的其余部分将讨论将原始数据转换为数字向量的最佳实践策略。
矢量可以可视化为空间中的一个点。(有时人们会从原点画一条线或箭头到那个点。在本书中,我们主要只使用这个点。)例如,假设我们有一个二维向量v = [1, –1]。该向量包含两个数字:在第一个方向d 1,向量的值为 1,在第二个方向d 2,向量的值为 –1。我们可以在二维图中绘制v ,如图 2-1所示。

图 2-1。单个向量
在数据世界中,抽象向量及其特征维度具有实际意义。例如,一个向量可以代表一个人对歌曲的偏好。每首歌都是一个特征,其中值 1 相当于竖起大拇指,–1 相当于竖起大拇指。假设向量v代表听众 Bob 的偏好。Bob 喜欢 Bob Dylan 的“Blowin' in the Wind”和 Lady Gaga 的“Poker Face”。其他人可能有不同的偏好。总的来说,一组数据可以在特征空间中可视化为点云。
反之,一首歌可以代表一群人的个人喜好。假设只有两个听众,Alice 和 Bob。Alice 喜欢 Leonard Cohen 的“Poker Face”、“Blowin' in the Wind”和“Hallelujah”,但讨厌 Katy Perry 的“Roar”和 Radiohead 的“Creep”。Bob 喜欢“Roar”、“Hallelujah”和“Blowin' in the Wind”,但讨厌“Poker Face”和“Creep”。每首歌都是听众空间中的一个点。就像我们可以在特征空间中可视化数据一样,我们也可以在数据空间中可视化特征。图 2-2显示了这个例子。
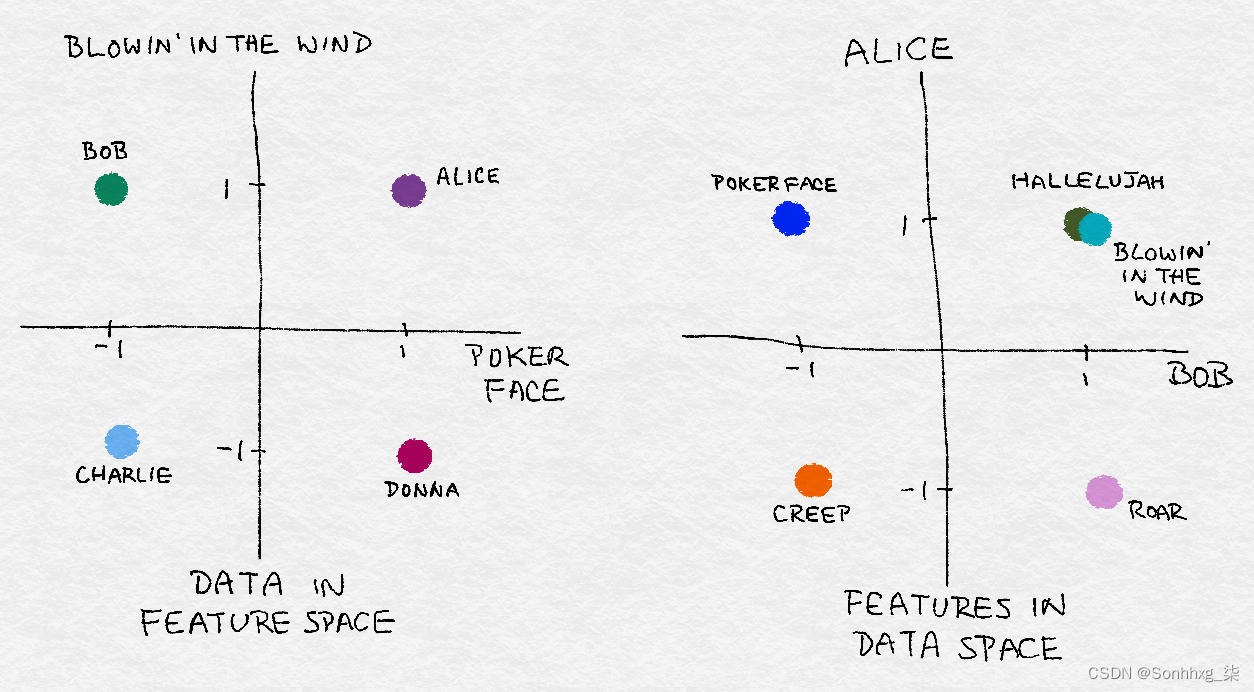
图 2-2。特征空间与数据空间的图示
处理计数
在大数据时代,计数可以无限制地快速累积。用户可能放一首歌或无限播放的电影或使用脚本反复检查热门节目的门票可用性,这将导致播放次数或网站访问次数快速上升。当可以以高容量和高速度生成数据时,它很可能包含一些极值。最好检查比例并确定是将数据保留为原始数字,将它们转换为二进制值以指示存在,还是将它们分类为更粗粒度。为了说明这些想法,让我们看几个例子。
二值化
Echo Nest Taste Profile 子集是 Million Song Dataset的官方用户数据集合,包含了 Echo Nest 上一百万用户的完整音乐收听历史。以下是有关数据集的一些相关统计数据:
ECHO NEST 口味概况数据集的统计数据
-
用户ID、歌曲ID、收听次数三元组超过4800万。
-
完整的数据集包含 1,019,318 个独立用户和 384,546 首独特歌曲。
假设我们的任务是构建一个推荐器来向用户推荐歌曲。推荐系统的一个组成部分可能会预测用户对一首特定歌曲的喜爱程度。由于数据包含实际收听次数,那应该是预测的目标吗?如果大量的收听次数意味着用户真的很喜欢这首歌而低的收听次数意味着他们对此不感兴趣,那么这将是正确的做法。然而,数据显示,虽然 99% 的收听次数为 24 次或更低,但也有部分收听次数达到数千次,最高可达 9,667 次。(如图 2-3显示,直方图在最接近 0 的 bin 中达到峰值。但是超过 10,000 个三元组具有更大的计数,其中有几千个。)这些值异常大;如果我们要尝试预测实际的收听次数,那么模型将因这些大值而偏离路线。
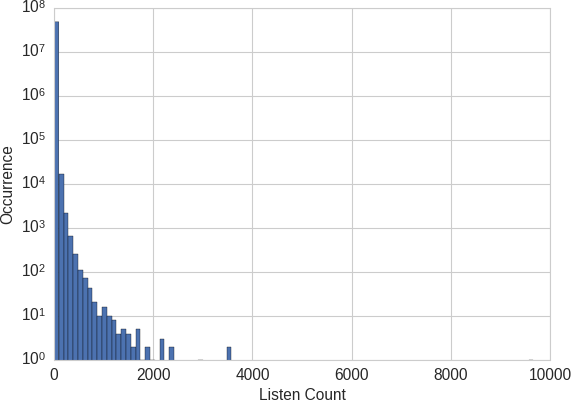
图 2-3。Million Song Dataset的 Taste Profile 子集中的收听次数直方图——请注意,y 轴是对数刻度
在百万歌曲数据集中,原始收听次数并不是衡量用户品味的可靠指标。(在统计术语中,稳健性意味着方法在各种条件下工作。)用户有不同的收听习惯。有些人可能会无限循环播放他们最喜欢的歌曲,而其他人可能只在特殊场合才细细品味。我们不能说听一首歌 20 次的人对这首歌的喜爱程度一定是听 10 次的人的两倍。
更可靠的用户偏好表示是将计数二值化并将所有大于 1 的计数裁剪为 1,如示例 2-1所示。换句话说,如果用户至少听过一次歌曲,那么我们就将其视为喜欢这首歌的用户。这样,模型就不需要花费周期来预测原始计数之间的微小差异。二元目标是用户偏好的简单而可靠的度量。
示例 2-1。百万歌曲数据集中的二值化收听计数
import pandas as pd
listen_count = pd.read_csv('millionsong/train_triplets.txt.zip',
header=None, delimiter='\t')
# The table contains user-song-count triplets. Only nonzero counts are
# included. Hence, to binarize the count, we just need to set the entire
# count column to 1.
listen_count[2] = 1量化或合并
对于本练习,我们从Yelp 数据集挑战的第 6 轮中获取数据,并创建一个小得多的分类数据集。Yelp 数据集包含来自北美和欧洲 10 个城市的企业的用户评论。每个企业都标有零个或多个类别。
YELP 评论数据集的统计数据(第 6 轮)
有782个业务类别。
完整数据集包含 1,569,264 (≈1.6M) 条评论和 61,184 (61K) 条企业。
“餐厅”(990,627 条评论)和“夜生活”(210,028 条评论)是最受欢迎的类别,评论数量。
没有企业被归类为餐厅和夜生活场所。因此,两组评论之间没有重叠。
每个企业都有一个评论计数。假设我们的任务是使用协同过滤来预测用户可能给企业的评级。评论计数可能是一个有用的输入特征,因为受欢迎程度和良好评级之间通常存在很强的相关性。现在的问题是,我们应该使用原始评论计数还是进一步处理它?图 2-4由示例 2-2生成,显示了所有业务评论计数的直方图。我们看到与前面示例中的收听计数相同的模式:大多数计数很小,但有些企业有数千条评论。
示例 2-2。可视化 Yelp 数据集中的商业评论计数
import pandas as pd
import json
# Load the data about businesses
biz_file = open('yelp_academic_dataset_business.json')
biz_df = pd.DataFrame([json.loads(x) for x in biz_file.readlines()])
biz_file.close()
import matplotlib.pyplot as plt
import seaborn as sns
# Plot the histogram of the review counts
sns.set_style('whitegrid')
fig, ax = plt.subplots()
biz_df['review_count'].hist(ax=ax, bins=100)
ax.set_yscale('log')
ax.tick_params(labelsize=14)
ax.set_xlabel('Review Count', fontsize=14)
ax.set_ylabel('Occurrence', fontsize=14)跨越几个数量级的原始计数对于许多模型来说都是有问题的。在线性模型中,相同的线性系数必须适用于所有可能的计数值。大量计数也可能对无监督学习方法造成严重破坏,例如k均值聚类,它使用欧几里得距离作为相似度函数来衡量数据点之间的相似度。数据向量的一个元素中的大量计数将超过所有其他元素中的相似性,这可能会影响整个相似性测量。
一种解决方案是通过量化计数来包含比例。换句话说,我们将计数分组到 bin 中,并去掉实际计数值。量化将连续数映射为离散数。我们可以将离散化数字视为表示强度度量的有序 bin 序列。
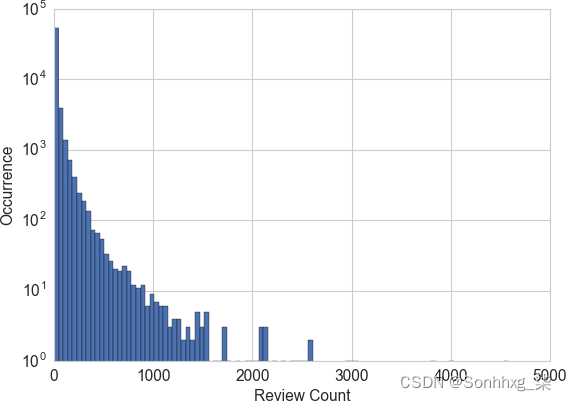
图 2-4。Yelp 评论数据集中商业评论计数的直方图——y 轴为对数刻度
为了量化数据,我们必须决定每个 bin 的宽度。解决方案分为两类:固定宽度或自适应。我们将给出每种类型的示例。
固定宽度装箱
使用固定宽度分箱,每个分箱都包含一个特定的数字范围。范围可以自定义设计或自动分段,并且可以线性缩放或指数缩放。例如,我们可以按十年将人们分组到年龄范围内:0-9 岁在 bin 1 中,10-19 岁在 bin 2 中,等等。要将计数映射到 bin,我们只需除以 bin 的宽度并取整数部分。
定制设计的年龄范围更符合人生阶段也很常见,例如:
-
0-12岁
-
12-17岁
-
18-24岁
-
25-34岁
-
35-44岁
-
45-54岁
-
55-64岁
-
65-74岁
-
75 岁或以上
当数字跨越多个量级时,最好按 10 的幂(或任何常数的幂)分组:0–9、10–99、100–999、1000–9999 等。bin 宽度呈指数增长,去从O (10),到O (100),O (1000),甚至更多。为了从计数映射到 bin,我们取计数的对数。指数宽度分箱与我们在“对数变换”中讨论的对数变换密切相关。示例 2-3说明了其中的几种装箱方法。
示例 2-3。使用固定宽度的 bin 量化计数
import numpy as np
# Generate 20 random integers uniformly between 0 and 99
>>> small_counts = np.random.randint(0, 100, 20)
small_counts
# array([30, 64, 49, 26, 69, 23, 56, 7, 69, 67, 87, 14, 67, 33, 88, 77, 75,
# 47, 44, 93])
# Map to evenly spaced bins 0-9 by division
np.floor_divide(small_counts, 10)
# array([3, 6, 4, 2, 6, 2, 5, 0, 6, 6, 8, 1, 6, 3, 8, 7, 7, 4, 4, 9], dtype=int32)
# An array of counts that span several magnitudes
large_counts = [296, 8286, 64011, 80, 3, 725, 867, 2215, 7689, 11495, 91897,
44, 28, 7971, 926, 122, 22222]
# Map to exponential-width bins via the log function
np.floor(np.log10(large_counts))
# array([ 2., 3., 4., 1., 0., 2., 2., 3., 3., 4., 4., 1., 1.,
3., 2., 2., 4.])分位数分级
固定宽度分箱很容易计算。但如果计数之间存在较大差距,则会出现许多没有数据的空箱。这个问题可以通过基于数据分布自适应地定位 bin 来解决。这可以使用分布的分位数来完成。
分位数是将数据分成相等部分的值。例如,中位数将数据分成两半;一半的数据点比中位数小,一半比中位数大。四分位数将数据分为四分之一,十分位数分为十分之一等。示例 2-4演示了如何计算 Yelp 业务评论计数的十分位数,图 2-5将十分位数叠加在直方图上。这可以更清楚地了解偏向于较小计数的情况。
示例 2-4。计算 Yelp 业务评论计数的十分位数
deciles = biz_df['review_count'].quantile([.1, .2, .3, .4, .5, .6, .7, .8, .9])
deciles0.1 3.0
0.2 4.0
0.3 5.0
0.4 6.0
0.5 8.0
0.6 12.0
0.7 17.0
0.8 28.0
0.9 58.0
Name: review_count, dtype: float64# Visualize the deciles on the histogram
sns.set_style('whitegrid')
fig, ax = plt.subplots()
biz_df['review_count'].hist(ax=ax, bins=100)
for pos in deciles:
handle = plt.axvline(pos, color='r')
ax.legend([handle], ['deciles'], fontsize=14)
ax.set_yscale('log')
ax.set_xscale('log')
ax.tick_params(labelsize=14)
ax.set_xlabel('Review Count', fontsize=14)
ax.set_ylabel('Occurrence', fontsize=14)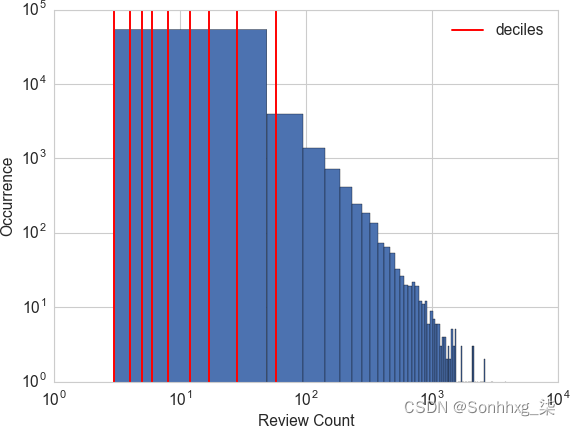
图 2-5。Yelp 评论数据集中评论计数的十分位数——x 轴和 y 轴均采用对数刻度
计算分位数和映射将数据放入分位数箱中,我们可以使用 Pandas 库,如示例 2-5所示。pandas.DataFrame.quantile并pandas.Series.quantile计算分位数。pandas.qcut将数据映射到所需数量的分位数。
示例 2-5。按分位数分箱计数
# Continue example 2-3 with large_counts
import pandas as pd
# Map the counts to quartiles
pd.qcut(large_counts, 4, labels=False)
# array([1, 2, 3, 0, 0, 1, 1, 2, 2, 3, 3, 0, 0, 2, 1, 0, 3], dtype=int64)
# Compute the quantiles themselves
large_counts_series = pd.Series(large_counts)
large_counts_series.quantile([0.25, 0.5, 0.75])0.25 122.0
0.50 926.0
0.75 8286.0
dtype: float64日志转换
在上一节中,我们简要介绍了采用计数的对数将数据映射到指数宽度的 bin 的概念。现在让我们仔细看看。
对数函数是指数函数的反函数。它被定义为 log a ( a x ) = x,其中a是一个正常数,x可以是任何正数。由于a 0 = 1,我们有 log a (1) = 0。这意味着 log 函数将 (0, 1) 之间的小范围数字映射到整个负数范围 (–∞, 0)。函数 log 10 ( x ) 将范围 [1, 10] 映射到 [0, 1],将 [10, 100] 映射到 [1, 2],依此类推。也就是说,log函数压缩了大数的范围,扩大了小数的范围。较大的x即,较慢的 log( x ) 增量。
通过查看对数函数图可以更容易地理解这一点(见图 2-6)。请注意从 100 到 1,000 的水平x值如何在垂直y范围内被压缩到 2.0 到 3.0,而x值的微小水平部分小于 100 被映射到垂直范围的其余部分。
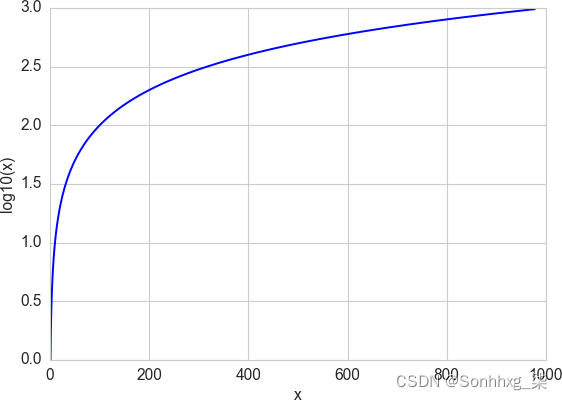
图 2-6。log函数压缩高数值范围,扩大低数值范围
对数变换是处理重尾正数的强大工具分配。(与高斯分布相比,重尾分布在尾部范围内放置了更多的概率质量。)它将分布高端的长尾压缩为较短的尾部,并将低端扩展为较长的头部。图2-7对数转换前后Yelp 业务评论数直方图对比(见例2-6). y 轴现在都在正常(线性)尺度上。底部图中在 (0.5, 1] 范围内增加的 bin 间距是由于 1 和 10 之间只有 10 个可能的整数计数。请注意,原始评论计数非常集中在低计数区域,异常值拉伸超过 4,000。对数转换后,直方图在低端的集中度较低,而在 x 轴上分布较多。
示例 2-6。可视化日志转换前后评论数的分布
fig, (ax1, ax2) = plt.subplots(2,1)
biz_df['review_count'].hist(ax=ax1, bins=100)
ax1.tick_params(labelsize=14)
ax1.set_xlabel('review_count', fontsize=14)
ax1.set_ylabel('Occurrence', fontsize=14)
biz_df['log_review_count'].hist(ax=ax2, bins=100)
ax2.tick_params(labelsize=14)
ax2.set_xlabel('log10(review_count))', fontsize=14)
ax2.set_ylabel('Occurrence', fontsize=14)
图 2-7。日志改造前(上)和改造后(下)Yelp 业务评论数对比
作为另一个例子,让我们考虑来自 UC Irvine 机器学习库的在线新闻流行度数据集(Fernandes 等人,2015 年)。
在线新闻流行度数据集统计
-
该数据集包括 Mashable 在 2 年内发布的一组 39,797 篇新闻文章的 60 个特征。
我们的目标是使用这些功能根据社交媒体上的分享数量来预测文章的受欢迎程度。在这个例子中,我们将只关注一个特征——文章中的单词数。图 2-8显示了对数变换前后特征的直方图(见例 2-7)。请注意,经过对数转换后,分布看起来更符合高斯分布,但长度为零(无内容)的文章数量激增。
示例 2-7。使用和不使用日志转换可视化新闻文章流行度的分布
fig, (ax1, ax2) = plt.subplots(2,1)
df['n_tokens_content'].hist(ax=ax1, bins=100)
ax1.tick_params(labelsize=14)
ax1.set_xlabel('Number of Words in Article', fontsize=14)
ax1.set_ylabel('Number of Articles', fontsize=14)
df['log_n_tokens_content'].hist(ax=ax2, bins=100)
ax2.tick_params(labelsize=14)
ax2.set_xlabel('Log of Number of Words', fontsize=14)
ax2.set_ylabel('Number of Articles', fontsize=14)
图 2-8。Mashable 新闻文章在日志转换之前(顶部)和之后(底部)的字数比较
日志转换在行动
让我们看看日志转换如何执行监督学习。我们将在这里使用之前的两个数据集。对于 Yelp 评论数据集,我们将使用评论数量来预测企业的平均评分(参见示例 2-8)。对于 Mashable 新闻文章,我们将使用文章中的字数来预测其受欢迎程度。由于输出是连续的数字,我们将使用简单的线性回归作为模型。我们使用scikit-learn对具有和不具有对数转换的特征执行线性回归的 10 折交叉验证。模型通过R 平方分数进行评估,它衡量经过训练的回归模型预测新数据的能力。好的模型具有较高的 R 平方分数。一个完美的模型得到最高分 1。分数可以是负数,而一个坏模型可以得到任意低的负分。使用交叉验证,我们不仅获得了分数的估计值,还获得了方差,这有助于我们衡量两个模型之间的差异是否有意义。
示例 2-8。使用对数转换的 Yelp 评论计数来预测平均商业评级
import pandas as pd
import numpy as np
import json
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
# Using the previously loaded Yelp reviews DataFrame,
# compute the log transform of the Yelp review count.
# Note that we add 1 to the raw count to prevent the logarithm from
# exploding into negative infinity in case the count is zero.
biz_df['log_review_count'] = np.log10(biz_df['review_count'] + 1)
# Train linear regression models to predict the average star rating of a business,
# using the review_count feature with and without log transformation.
# Compare the 10-fold cross validation score of the two models.
m_orig = linear_model.LinearRegression()
scores_orig = cross_val_score(m_orig, biz_df[['review_count']],
biz_df['stars'], cv=10)
m_log = linear_model.LinearRegression()
scores_log = cross_val_score(m_log, biz_df[['log_review_count']],
biz_df['stars'], cv=10)
print("R-squared score without log transform: %0.5f (+/- %0.5f)"
% (scores_orig.mean(), scores_orig.std() * 2))
print("R-squared score with log transform: %0.5f (+/- %0.5f)"
% (scores_log.mean(), scores_log.std() * 2))R-squared score without log transform: -0.03683 (+/- 0.07280)R-squared score with log transform: -0.03694 (+/- 0.07650)
从实验的输出来看,两个简单模型(有和没有对数变换)在预测目标方面同样糟糕,对数变换特征表现稍差。多么令人失望!鉴于它们都只使用一个特性,因此它们都不是很好也就不足为奇了,但是人们希望对数转换特性可能表现得更好。
现在让我们看看对数转换如何对在线新闻流行度数据集(例 2-9)进行处理。
示例 2-9。使用在线新闻流行度数据集中的对数转换字数来预测文章流行度
# Download the Online News Popularity dataset from UCI, then use
# Pandas to load the file into a DataFrame.
df = pd.read_csv('OnlineNewsPopularity.csv', delimiter=', ')
# Take the log transform of the 'n_tokens_content' feature, which
# represents the number of words (tokens) in a news article.
df['log_n_tokens_content'] = np.log10(df['n_tokens_content'] + 1)
# Train two linear regression models to predict the number of shares
# of an article, one using the original feature and the other the
# log transformed version.
m_orig = linear_model.LinearRegression()
scores_orig = cross_val_score(m_orig, df[['n_tokens_content']],
df['shares'], cv=10)
m_log = linear_model.LinearRegression()
scores_log = cross_val_score(m_log, df[['log_n_tokens_content']],
df['shares'], cv=10)
print("R-squared score without log transform: %0.5f (+/- %0.5f)"
% (scores_orig.mean(), scores_orig.std() * 2))
print("R-squared score with log transform: %0.5f (+/- %0.5f)"
% (scores_log.mean(), scores_log.std() * 2))
R-squared score without log transform: -0.00242 (+/- 0.00509)R-squared score with log transform: -0.00114 (+/- 0.00418)
置信区间仍然重叠,但具有对数转换特征的模型比没有的模型表现更好。为什么对数转换在此数据集上如此成功?我们可以通过查看输入特征和目标值的散点图(示例 2-10 )来获得线索。从图 2-9的底部面板可以看出,对数变换改变了 x 轴的形状,将目标值中具有较大异常值(>200,000 股)的文章进一步拉向轴的右侧。这为线性模型在输入特征空间的低端提供了更多的“喘息空间”。如果没有对数变换(上图),模型在输入变化非常小的情况下会承受更大的压力来适应非常不同的目标值。
示例 2-10。可视化新闻流行度预测问题中输入和输出之间的相关性
fig2, (ax1, ax2) = plt.subplots(2,1)
ax1.scatter(df['n_tokens_content'], df['shares'])
ax1.tick_params(labelsize=14)
ax1.set_xlabel('Number of Words in Article', fontsize=14)
ax1.set_ylabel('Number of Shares', fontsize=14)
ax2.scatter(df['log_n_tokens_content'], df['shares'])
ax2.tick_params(labelsize=14)
ax2.set_xlabel('Log of the Number of Words in Article', fontsize=14)
ax2.set_ylabel('Number of Shares', fontsize=14)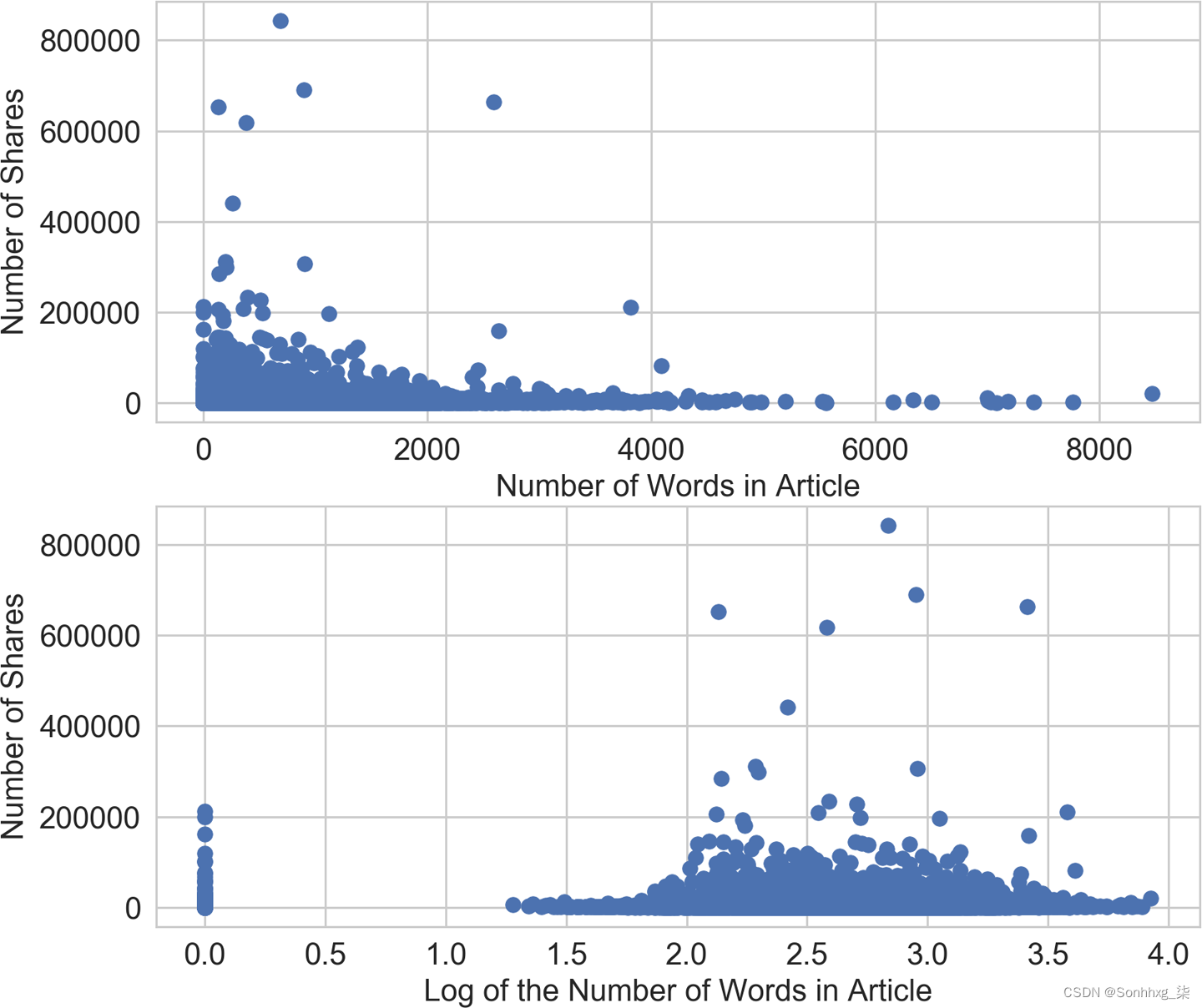
图 2-9。在线新闻流行度数据集中词数(输入)与分享数(目标)的散点图——上图可视化原始特征,下图显示对数转换后的散点图
将其与应用于 Yelp 评论数据集的相同散点图(示例 2-11)进行比较。图 2-10看起来与图 2-9非常不同。平均星级以从 1 到 5 的半星增量离散化。高评论数(大约 >2,500 条评论)确实与较高的平均星级相关,但这种关系远非线性关系。没有明确的方法可以画一条线来预测基于任一输入的平均星级评分。从本质上讲,该图表明评论数及其对数都是平均星级评分的不良线性预测指标。
示例 2-11。可视化 Yelp 业务评论预测中输入和输出之间的相关性
fig, (ax1, ax2) = plt.subplots(2,1)
ax1.scatter(biz_df['review_count'], biz_df['stars'])
ax1.tick_params(labelsize=14)
ax1.set_xlabel('Review Count', fontsize=14)
ax1.set_ylabel('Average Star Rating', fontsize=14)
ax2.scatter(biz_df['log_review_count'], biz_df['stars'])
ax2.tick_params(labelsize=14)
ax2.set_xlabel('Log of Review Count', fontsize=14)
ax2.set_ylabel('Average Star Rating', fontsize=14)数据可视化的重要性
对数变换对两个不同数据集的影响的比较说明了数据可视化的重要性。在这里,我们有意使输入变量和目标变量保持简单,以便我们可以轻松地将它们之间的关系可视化。类似图 2-10中的图立即表明所选模型(线性)不可能代表所选输入和目标之间的关系。另一方面,在给定平均星级评分的情况下,可以令人信服地对评论数的分布进行建模。构建模型时,最好直观地检查输入和输出之间以及不同输入特征之间的关系。
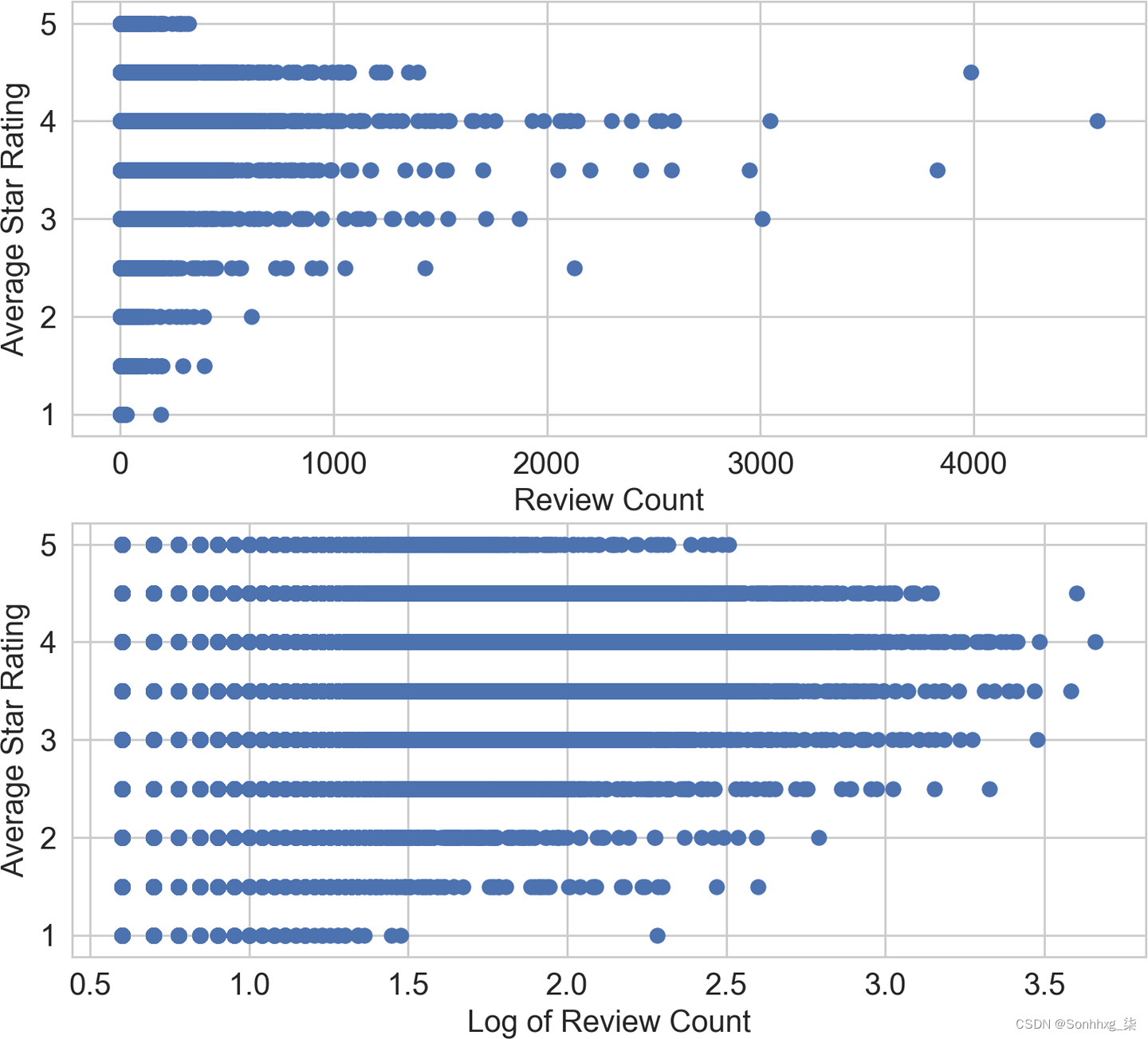
图 2-10。Yelp 评论数据集中评论数(输入)与平均星级(目标)的散点图——顶部面板绘制原始评论数,底部面板绘制日志转换后的评论数
幂变换:对数变换的推广
日志转换是一个具体的例子的称为幂变换的一系列变换。用统计学术语来说,这些是方差稳定变换。了解为什么会出现差异稳定性好,考虑泊松分布。这是一个方差等于其均值的重尾分布:因此,其质心越大,方差越大,尾部越重。幂变换改变变量的分布,使方差不再依赖于均值。例如,假设随机变量X服从泊松分布。如果我们通过取其平方根来变换X ,则方差为X˜=X大致恒定,而不是等于平均值。
图 2-11说明了 λ,它表示分布的均值。随着 λ 的增加,不仅分布的模式向右移动,而且质量分散并且方差变大。
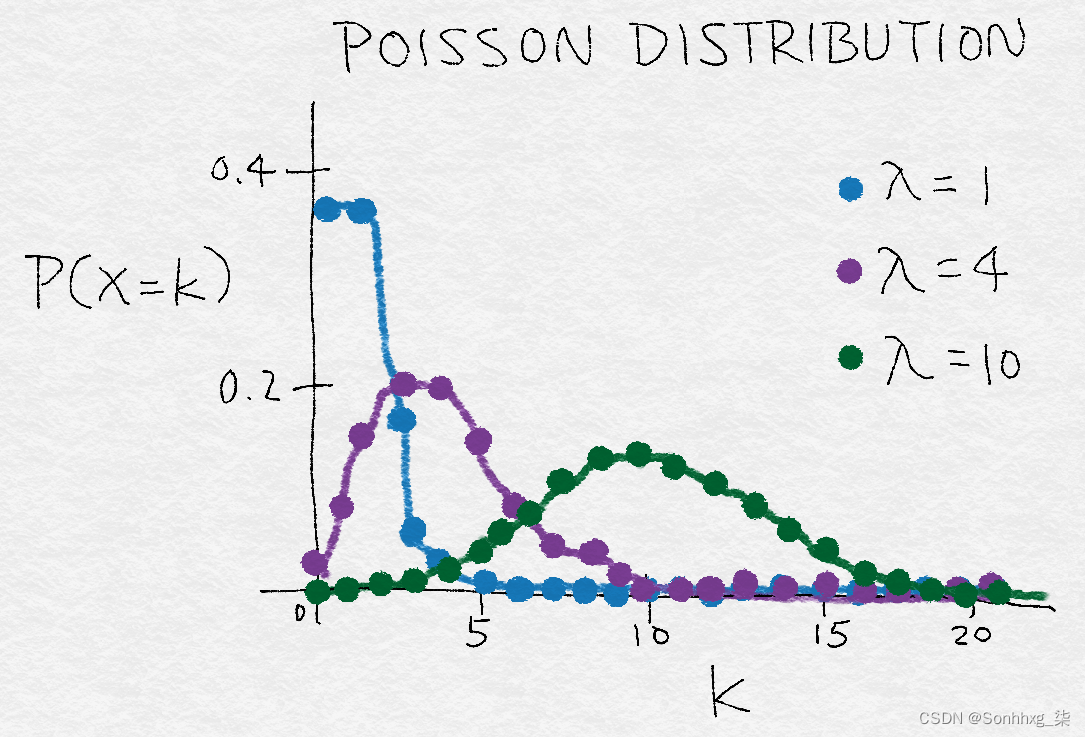
图 2-11。泊松分布的粗略图示,这是一个方差随均值增加的示例分布
平方根变换和对数变换的简单概括称为 Box-Cox 变换:

图 2-12显示了 Box-Coxλ = 0(对数变换)、λ = 0.25、λ = 0.5(平方根变换的缩放和移位版本)、λ = 0.75 和 λ = 1.5。将 λ 设置为小于 1 会压缩较高的值,将 λ 设置为高于 1 会产生相反的效果。
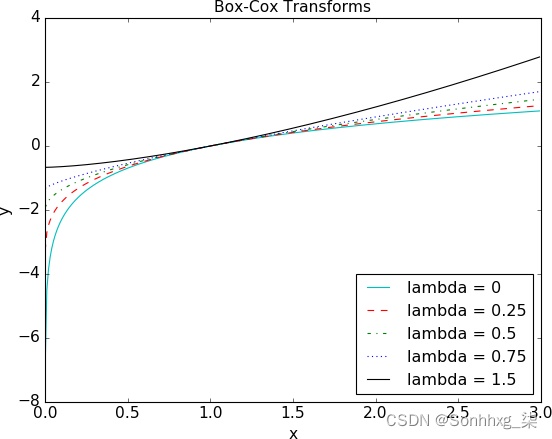
图 2-12。不同 λ 值的 Box-Cox 变换
Box-Cox 公式仅在数据为正时才有效。对于非正数据,可以通过添加固定常数来移动值。在应用 Box-Cox 变换或更一般的幂变换时,我们必须确定参数λ的值。这可以通过最大似然法(找到使所得变换信号的高斯似然性最大化的λ )或贝叶斯方法来完成。Box-Cox 和一般幂变换的使用的完整处理超出了本书的范围。感兴趣的读者可以在Johnston 和 DiNardo (1997)的《计量经济学方法》中找到更多关于幂变换的信息。还好SciPy的stats包包含 Box-Cox 变换的实现,其中包括找到最佳变换参数。示例 2-12演示了它在 Yelp 评论数据集上的使用。
示例 2-12。Yelp 业务评论计数的 Box-Cox 转换
from scipy import stats
# Continuing from the previous example, assume biz_df contains
# the Yelp business reviews data.
# The Box-Cox transform assumes that input data is positive.
# Check the min to make sure.
biz_df['review_count'].min()
# 3
# Setting input parameter lmbda to 0 gives us the log transform (without
# constant offset)
rc_log = stats.boxcox(biz_df['review_count'], lmbda=0)
# By default, the scipy implementation of Box-Cox transform finds the lambda
# parameter that will make the output the closest to a normal distribution
rc_bc, bc_params = stats.boxcox(biz_df['review_count'])
bc_params
# -0.4106510862321085图 2-13提供了原始计数和转换后计数分布的直观比较(参见示例 2-13)。
示例 2-13。可视化原始计数、对数变换计数和 Box-Cox 变换计数的直方图
fig, (ax1, ax2, ax3) = plt.subplots(3,1)
# original review count histogram
biz_df['review_count'].hist(ax=ax1, bins=100)
ax1.set_yscale('log')
ax1.tick_params(labelsize=14)
ax1.set_title('Review Counts Histogram', fontsize=14)
ax1.set_xlabel('')
ax1.set_ylabel('Occurrence', fontsize=14)
# review count after log transform
biz_df['rc_log'].hist(ax=ax2, bins=100)
ax2.set_yscale('log')
ax2.tick_params(labelsize=14)
ax2.set_title('Log Transformed Counts Histogram', fontsize=14)
ax2.set_xlabel('')
ax2.set_ylabel('Occurrence', fontsize=14)
# review count after optimal Box-Cox transform
biz_df['rc_bc'].hist(ax=ax3, bins=100)
ax3.set_yscale('log')
ax3.tick_params(labelsize=14)
ax3.set_title('Box-Cox Transformed Counts Histogram', fontsize=14)
ax3.set_xlabel('')
ax3.set_ylabel('Occurrence', fontsize=14)
图 2-13。Yelp 业务评论计数(底部)的 Box-Cox 转换与原始(顶部)和日志转换(中间)直方图相比
概率图或 probplot 是一种简单的方法直观地比较数据的经验分布与理论分布。这本质上是观察到的分位数与理论分位数的散点图。图 2-14显示了原始和转换后的 Yelp 评论计数数据相对于正态分布的概率图(参见示例 2-14). 由于观察到的数据严格为正,而高斯分布可能为负,因此分位数永远不会在负端匹配。因此,我们的重点是积极的一面。在这方面,原始计数显然比正态分布更重尾。(有序值上升到 4,000,而理论分位数仅延伸到 4。)普通对数变换和最优 Box-Cox 变换都使正尾更接近正常。最佳 Box-Cox 变换比对数变换更能缩小尾部,从尾部在红色对角线等价线下方变平这一事实可以明显看出。
示例 2-14。原始计数和转换计数相对于正态分布的概率图
fig2, (ax1, ax2, ax3) = plt.subplots(3,1)
prob1 = stats.probplot(biz_df['review_count'], dist=stats.norm, plot=ax1)
ax1.set_xlabel('')
ax1.set_title('Probplot against normal distribution')
prob2 = stats.probplot(biz_df['rc_log'], dist=stats.norm, plot=ax2)
ax2.set_xlabel('')
ax2.set_title('Probplot after log transform')
prob3 = stats.probplot(biz_df['rc_bc'], dist=stats.norm, plot=ax3)
ax3.set_xlabel('Theoretical quantiles')
ax3.set_title('Probplot after Box-Cox transform')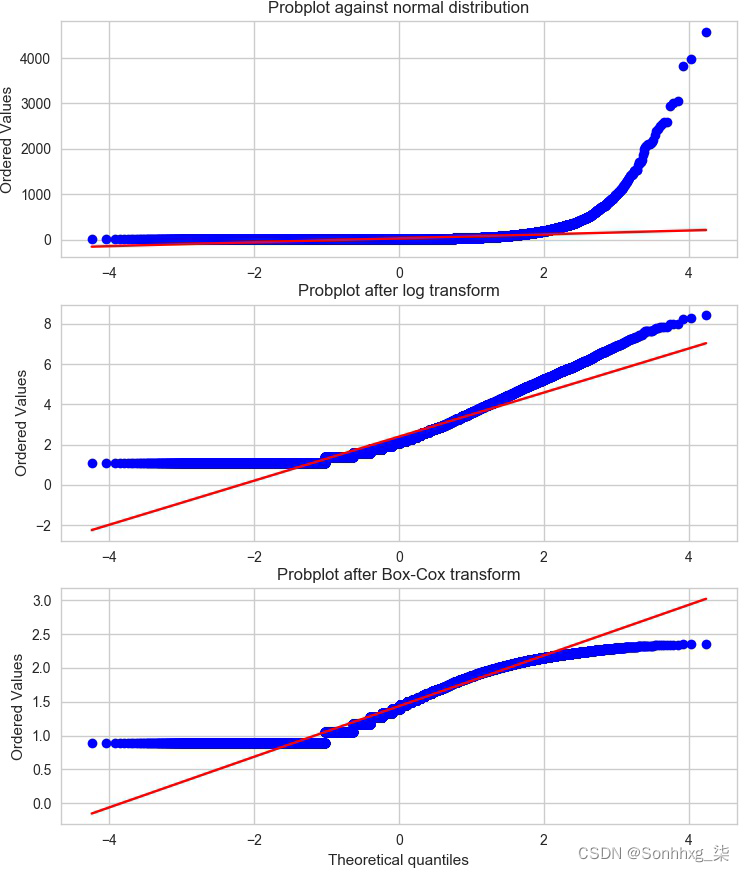
图 2-14。比较原始和转换评论计数的分布与正态分布
特征缩放或归一化
某些特征(例如纬度或经度)的值是有限的。其他数字特征(例如计数)可能会无限制地增加。作为输入的平滑函数的模型,例如线性回归、逻辑回归或任何涉及矩阵的模型,都会受到输入规模的影响。另一方面,基于树的模型并不在乎。如果您的模型对输入特征的规模敏感,特征缩放可能会有所帮助。顾名思义,特征缩放会改变特征的尺度。有时人们也称之为特征归一化。特征缩放通常针对每个特征单独完成。接下来,我们将讨论几种常见的缩放操作,每种操作都会导致不同的特征值分布。
最小-最大缩放
令x为单个特征值(即某个数据点中的特征值),min( x ) 和 max( x ) 分别为该特征在整个数据集上的最小值和最大值。最小-最大缩放将所有特征值压缩(或拉伸)到 [0, 1] 范围内。图 2-15演示了这个概念。最小-最大缩放比例的公式为:

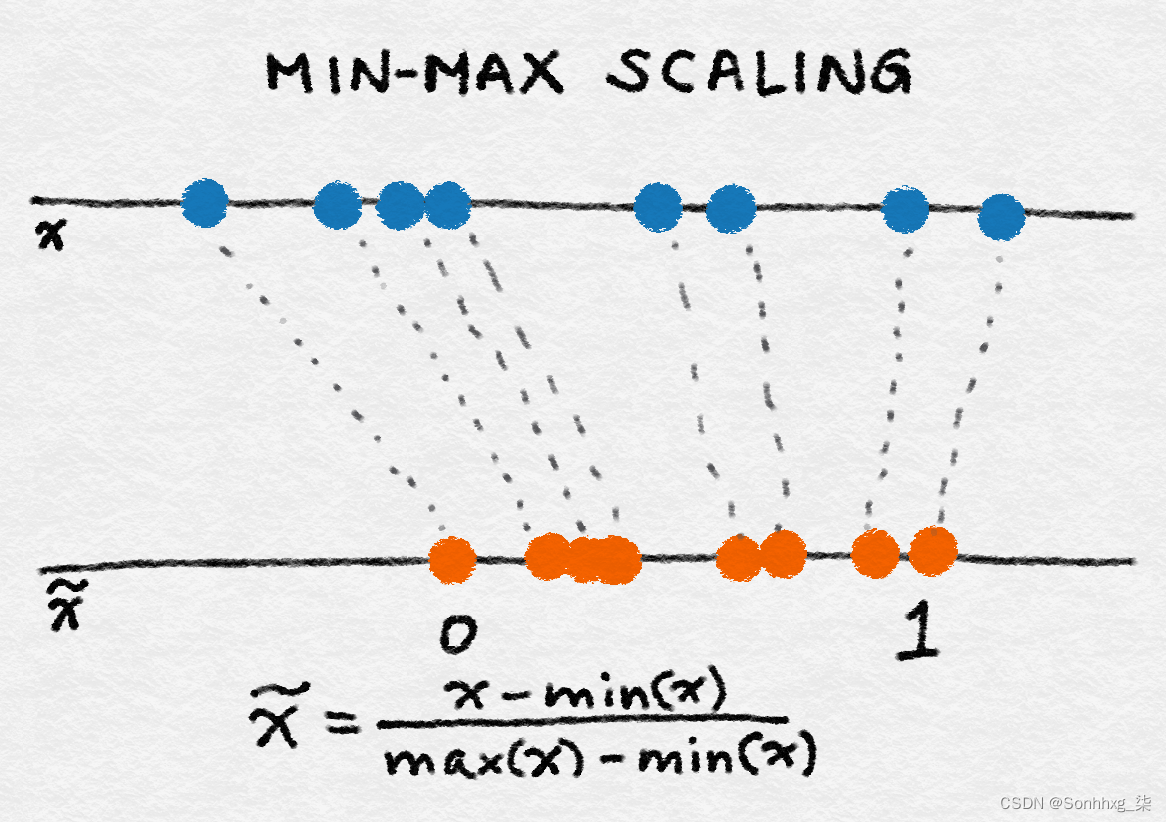
图 2-15。最小-最大缩放的图示
标准化(方差缩放)
特征标准化定义为:
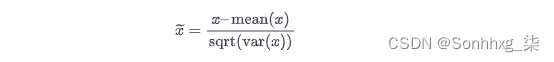
它减去特征的平均值(在所有数据点上)并除以方差。因此,它也可以称为方差缩放。生成的缩放特征的均值为 0,方差为 1。如果原始特征服从高斯分布,则缩放后的特征也服从高斯分布。图 2-16是标准化的图示。
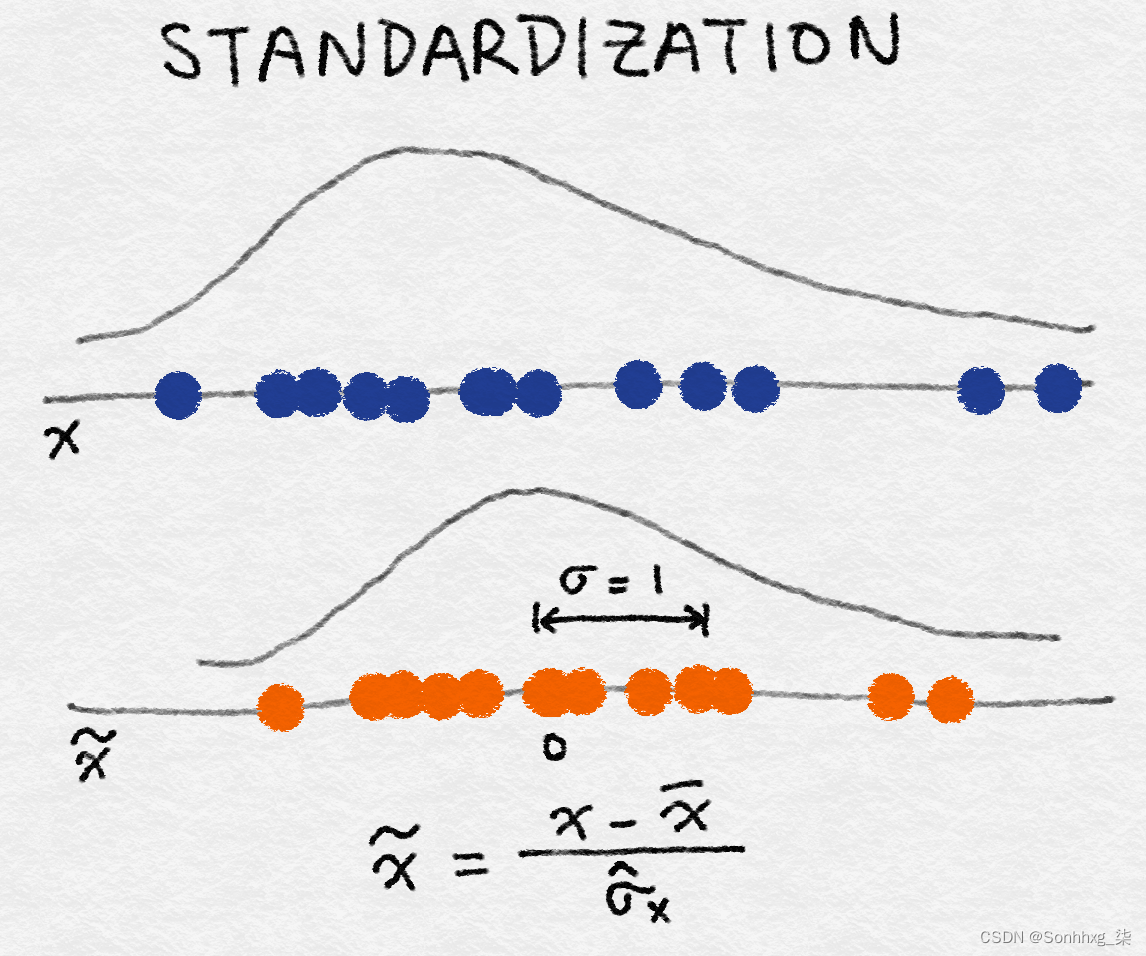
图 2-16。特征标准化示意图
ℓ 2归一化
这种技术归一化(划分)原来的特征值采用所谓的ℓ 2范数,也称为欧几里得范数。它的定义如下:

ℓ 2范数测量坐标空间中向量的长度。该定义可以从著名的毕达哥拉斯定理推导出来在给定边长的情况下,它给出了直角三角形斜边的长度:

ℓ 2范数对数据点的特征值的平方求和,然后取平方根。ℓ 2归一化后,特征列的范数为 1。这有时也称为ℓ 2缩放。(粗略地说,缩放意味着乘以一个常数,而归一化可能涉及许多操作。)图 2-17说明了ℓ 2归一化。
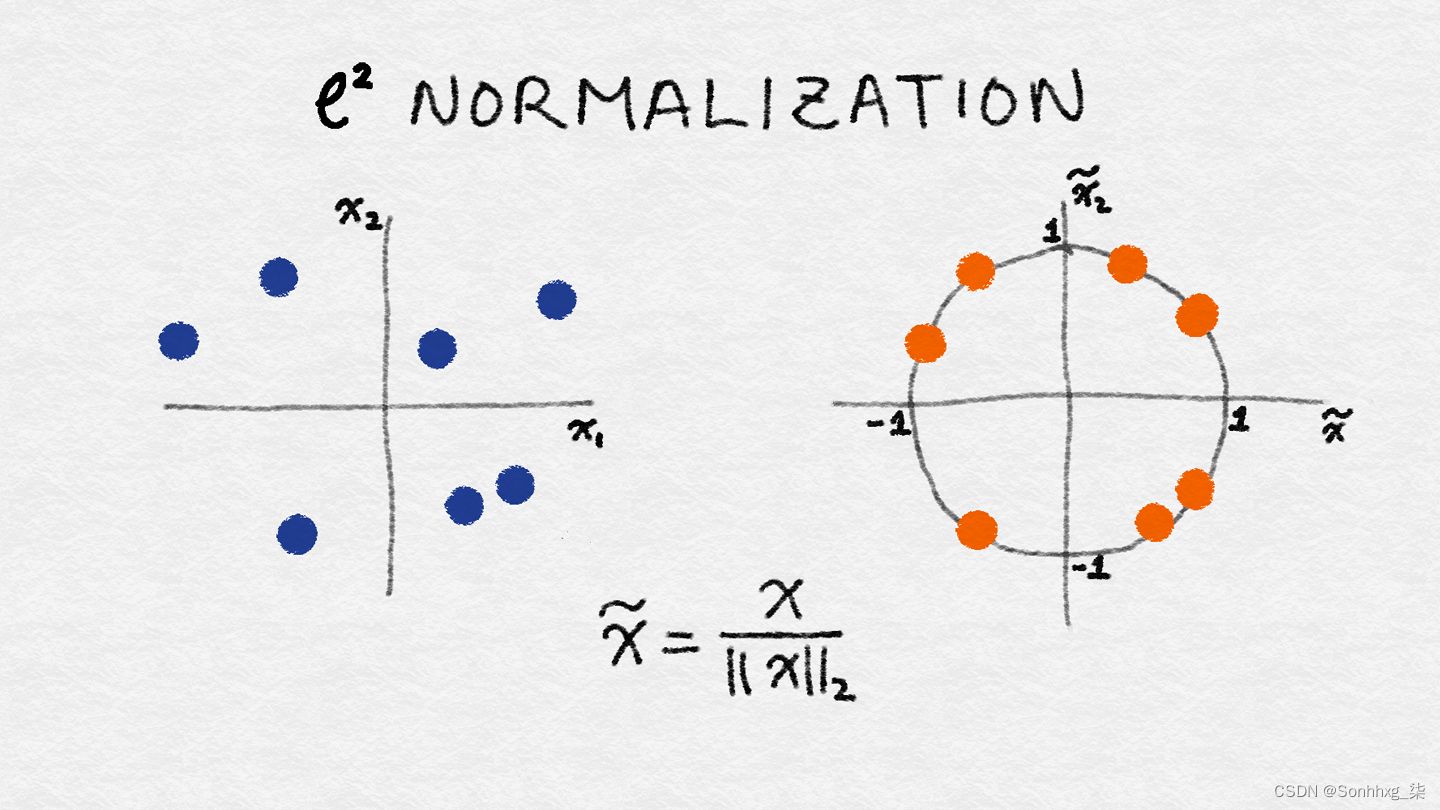
图 2-17。ℓ 2特征归一化示意图
数据空间与特征空间
请注意,图 2-17中的图示是在数据空间中,而不是特征空间中。也可以对数据点而不是特征进行ℓ 2归一化,这将导致数据向量具有单位范数(范数为 1)。请参阅“词袋”中关于数据向量和特征向量的互补性的讨论。
无论缩放方法如何,特征缩放总是将特征除以一个常数(称为归一化常数)。因此,它不会改变单特征分布的形状。我们将用在线新闻文章标记计数来说明这一点(参见示例 2-15)。
示例 2-15。特征缩放示例
import pandas as pd
import sklearn.preprocessing as preproc
# Load the Online News Popularity dataset
df = pd.read_csv('OnlineNewsPopularity.csv', delimiter=', ')
# Look at the original data - the number of words in an article
df['n_tokens_content'].as_matrix()
# array([ 219., 255., 211., ..., 442., 682., 157.])
# Min-max scaling
df['minmax'] = preproc.minmax_scale(df[['n_tokens_content']])
# df['minmax'].as_matrix()
# array([ 0.02584376, 0.03009205, 0.02489969, ..., 0.05215955,
# 0.08048147, 0.01852726])
# Standardization - note that by definition, some outputs will be negative
df['standardized'] = preproc.StandardScaler().fit_transform(df[['n_tokens_content']])
df['standardized'].as_matrix()
# array([-0.69521045, -0.61879381, -0.71219192, ..., -0.2218518 ,
# 0.28759248, -0.82681689])
# L2-normalization
df['l2_normalized'] = preproc.normalize(df[['n_tokens_content']], axis=0)
df['l2_normalized'].as_matrix()
# array([ 0.00152439, 0.00177498, 0.00146871, ..., 0.00307663,
# 0.0047472 , 0.00109283])我们还可以使用不同的特征缩放方法可视化数据的分布(图 2-18)。如示例 2-16所示,与对数变换不同,特征缩放不会改变分布的形状;只有数据的规模发生了变化。
示例 2-16。绘制原始数据和缩放数据的直方图
fig, (ax1, ax2, ax3, ax4) = plt.subplots(4,1)
fig.tight_layout()
df['n_tokens_content'].hist(ax=ax1, bins=100)
ax1.tick_params(labelsize=14)
ax1.set_xlabel('Article word count', fontsize=14)
ax1.set_ylabel('Number of articles', fontsize=14)
df['minmax'].hist(ax=ax2, bins=100)
ax2.tick_params(labelsize=14)
ax2.set_xlabel('Min-max scaled word count', fontsize=14)
ax2.set_ylabel('Number of articles', fontsize=14)
df['standardized'].hist(ax=ax3, bins=100)
ax3.tick_params(labelsize=14)
ax3.set_xlabel('Standardized word count', fontsize=14)
ax3.set_ylabel('Number of articles', fontsize=14)
df['l2_normalized'].hist(ax=ax4, bins=100)
ax4.tick_params(labelsize=14)
ax4.set_xlabel('L2-normalized word count', fontsize=14)
ax4.set_ylabel('Number of articles', fontsize=14)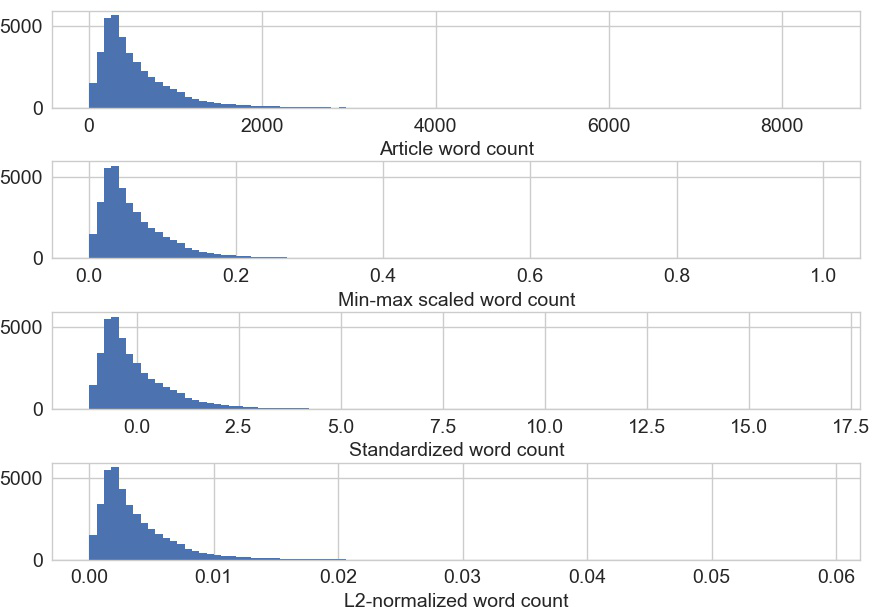
图 2-18。原始和按比例缩放的新闻文章字数——请注意,只有 x 轴的比例发生变化;分布的形状与特征缩放保持一致
特征缩放在一组输入特征的比例差异很大的情况下很有用。例如,一个流行的电子商务网站的每日访问者数量可能为十万,而实际销售额可能为数千。如果这两个特征都被放入模型中,那么模型将需要在确定要做什么的同时平衡其规模。输入特征的剧烈变化可能会导致模型训练算法出现数值稳定性问题。在这些情况下,将功能标准化是个好主意。第 4 章详细介绍了处理自然文本时的特征缩放,包括使用示例。
交互功能
一个简单的成对交互特征是两个特征的乘积。类比是逻辑与。它以条件对的形式表达结果:“购买来自邮政编码 98121”和“用户的年龄在 18 到 35 岁之间。” 基于决策树模型免费获得此功能,但广义线性模型通常会发现交互功能非常有用。
一个简单的线性模型使用单个输入特征x 1 , x 2 , ... x n的线性组合来预测结果y:
y = w1x1 + w2x2 + ... + wnxn
扩展线性模型的一种简单方法是包括成对输入特征的组合,如下所示:
y = w1x1 + w2x2 + ... + wnxn + w1,1x1x1 + w1,2x1x2 + w1,3 x1x3 + .. .
这使我们能够捕获特征之间的交互,因此这些对被称为交互特征。如果x 1和x 2是二元的,则它们的乘积x 1 x 2是逻辑函数x 1 AND x 2。假设问题是根据客户的个人资料信息预测他们的偏好。在我们的示例中,交互功能允许模型根据处于特定年龄和特定位置的用户进行预测,而不是仅根据用户的年龄或位置进行预测。
在示例 2-17中,我们使用来自 UCI 在线新闻流行度数据集的成对交互特征来预测每篇新闻文章的分享数。正如结果所示,交互特征导致了比单例特征更高的准确性。两者都比示例 2-9表现得更好,示例 2-9将文章正文中的单词数用作单个预测器(使用或不使用对数转换)。
示例 2-17。预测中的交互特征示例
from sklearn import linear_model
from sklearn.model_selection import train_test_split
import sklearn.preprocessing as preproc
# Assume df is a Pandas DataFrame containing the UCI Online News Popularity dataset
df.columnsIndex(['url', 'timedelta', 'n_tokens_title', 'n_tokens_content',
'n_unique_tokens', 'n_non_stop_words', 'n_non_stop_unique_tokens',
'num_hrefs', 'num_self_hrefs', 'num_imgs', 'num_videos',
'average_token_length', 'num_keywords', 'data_channel_is_lifestyle',
'data_channel_is_entertainment', 'data_channel_is_bus',
'data_channel_is_socmed', 'data_channel_is_tech',
'data_channel_is_world', 'kw_min_min', 'kw_max_min', 'kw_avg_min',
'kw_min_max', 'kw_max_max', 'kw_avg_max', 'kw_min_avg', 'kw_max_avg',
'kw_avg_avg', 'self_reference_min_shares', 'self_reference_max_shares',
'self_reference_avg_sharess', 'weekday_is_monday', 'weekday_is_tuesday',
'weekday_is_wednesday', 'weekday_is_thursday', 'weekday_is_friday',
'weekday_is_saturday', 'weekday_is_sunday', 'is_weekend', 'LDA_00',
'LDA_01', 'LDA_02', 'LDA_03', 'LDA_04', 'global_subjectivity',
'global_sentiment_polarity', 'global_rate_positive_words',
'global_rate_negative_words', 'rate_positive_words',
'rate_negative_words', 'avg_positive_polarity', 'min_positive_polarity',
'max_positive_polarity', 'avg_negative_polarity',
'min_negative_polarity', 'max_negative_polarity', 'title_subjectivity',
'title_sentiment_polarity', 'abs_title_subjectivity',
'abs_title_sentiment_polarity', 'shares'],
dtype='object')# Select the content-based features as singleton features in the model,
# skipping over the derived features
features = ['n_tokens_title', 'n_tokens_content',
'n_unique_tokens', 'n_non_stop_words', 'n_non_stop_unique_tokens',
'num_hrefs', 'num_self_hrefs', 'num_imgs', 'num_videos',
'average_token_length', 'num_keywords', 'data_channel_is_lifestyle',
'data_channel_is_entertainment', 'data_channel_is_bus',
'data_channel_is_socmed', 'data_channel_is_tech',
'data_channel_is_world']
X = df[features]
y = df[['shares']]
# Create pairwise interaction features, skipping the constant bias term
X2 = preproc.PolynomialFeatures(include_bias=False).fit_transform(X)
X2.shape(39644, 170)# Create train/test sets for both feature sets
X1_train, X1_test, X2_train, X2_test, y_train, y_test = \
train_test_split(X, X2, y, test_size=0.3, random_state=123)
def evaluate_feature(X_train, X_test, y_train, y_test):
"""Fit a linear regression model on the training set and
score on the test set"""
model = linear_model.LinearRegression().fit(X_train, y_train)
r_score = model.score(X_test, y_test)
return (model, r_score)
# Train models and compare score on the two feature sets
(m1, r1) = evaluate_feature(X1_train, X1_test, y_train, y_test)
(m2, r2) = evaluate_feature(X2_train, X2_test, y_train, y_test)
print("R-squared score with singleton features: %0.5f" % r1)
print("R-squared score with pairwise features: %0.10f" % r2)R-squared score with singleton features: 0.00924R-squared score with pairwise features: 0.0113276523
交互特征的制定非常简单,但使用起来却很昂贵。具有成对交互特征的线性模型的训练和评分时间将从O ( n ) 到O ( n 2 ),其中n是单例特征的数量。
有几种方法可以解决高阶交互特征的计算开销。可以在所有交互特征之上执行特征选择。或者,可以更仔细地制作较少数量的复杂特征。
这两种策略都有其优点和缺点。特征选择采用计算方法来为问题选择最佳特征。(该技术不限于交互特征。)但是,一些特征选择技术仍然需要训练具有大量特征的多个模型。
手工制作的复杂特征可以具有足够的表现力,以至于只需要其中的一小部分,这减少了模型的训练时间——但特征本身的计算成本可能很高,这增加了模型评分阶段的计算成本。可以在第 8 章中找到手工(或机器学习)复杂特征的好例子。现在让我们看看一些特征选择技术。
特征选择
特征选择技术会删除无用的特征,以降低生成模型的复杂性。最终目标是一个计算速度更快、预测精度几乎没有或没有下降的简约模型。为了得到这样的模型,一些特征选择技术需要训练多个候选模型。换句话说,特征选择不是要减少训练时间——事实上,一些技术会增加整体训练时间——而是要减少模型评分时间。
粗略地说,特征选择技术分为三类:
过滤
过滤技术预处理特征以删除不太可能对模型有用的特征。例如,可以计算每个特征与响应变量之间的相关性或互信息,并过滤掉低于阈值的特征。第 3 章讨论了这些文本特征技术的示例。过滤技术比接下来描述的包装器技术便宜得多,但它们没有考虑所采用的模型。因此,他们可能无法为模型选择正确的特征。最好保守地进行预过滤,以免在它们进入模型训练步骤之前无意中消除有用的特征。
包装方法
这些技术很昂贵,但它们允许您尝试功能的子集,这意味着您不会不小心删掉那些本身无用但组合使用时有用的功能。wrapper 方法将模型视为一个黑盒子,它提供了建议的特征子集的质量分数。有一种单独的方法可以迭代地优化子集。
嵌入式方法
这些方法将特征选择作为模型训练过程的一部分。例如,决策树本质上执行特征选择,因为它选择一个特征来在每个特征上分割树训练步骤。另一个例子是ℓ1regularizer,可以添加到任何线性模型的训练目标中。这ℓ1regularizer 鼓励使用少量特征而不是大量特征的模型,因此它也被称为模型的稀疏约束。嵌入式方法将特征选择作为模型训练过程的一部分。它们不如包装器方法强大,但也远不及它昂贵。与过滤相比,嵌入式方法选择特定于模型的特征。从这个意义上说,嵌入式方法在计算开销和结果质量之间取得了平衡。
特征选择的完整处理超出了本书的范围。有兴趣的读者可以参考 Guyon 和 Elisseeff (2003) 的调查论文。
概括
本章讨论了一些常见的数字特征工程技术,例如量化、缩放(又名归一化)、对数变换(一种幂变换)和交互特征,并简要总结了特征选择技术,这些技术是处理大数据所必需的。大量的交互特征。在统计机器学习中,所有数据最终都归结为数字特征。因此,所有的道路最终都会通向某种数字特征工程技术。将这些工具放在手边,以便在特征工程的最后阶段使用!