摘要:这是发表于CVPR 2020的一篇论文的复现模型。
本文分享自华为云社区《Panoptic Deeplab(全景分割PyTorch)》,作者:HWCloudAI 。
这是发表于CVPR 2020的一篇论文的复现模型,B. Cheng et al, “Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation”, CVPR 2020,此模型在原论文的基础上,使用HRNet作为backbone,得到了高于原论文的精度,PQ达到了63.7%,mIoU达到了80.3%,AP达到了37.3%。该算法会载入Cityscapes上的预训练模型(HRNet),我们提供了训练代码和可用于训练的模型,用于实际场景的微调训练。训练后生成的模型可直接在ModelArts平台部署成在线服务。
具体算法介绍:AI Gallery_算法_模型_云市场-华为云
注意事项:
1.本案例使用框架:PyTorch1.4.0
2.本案例使用硬件:GPU: 1*NVIDIA-V100NV32(32GB) | CPU: 8 核 64GB
3.运行代码方法: 点击本页面顶部菜单栏的三角形运行按钮或按Ctrl+Enter键 运行每个方块中的代码
4.JupyterLab的详细用法: 请参考《ModelAtrs JupyterLab使用指导》
5.碰到问题的解决办法: 请参考《ModelAtrs JupyterLab常见问题解决办法》
1.下载数据和代码
运行下面代码,进行数据和代码的下载
本案例使用cityscapes数据集。
import os
import moxing as mox
# 数据代码下载
mox.file.copy_parallel('s3://obs-aigallery-zc/algorithm/panoptic-deeplab','./panoptic-deeplab')2.模型训练
2.1依赖库加载
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from __future__ import print_function
import os
root_path = './panoptic-deeplab/'
os.chdir(root_path)
# 获取当前目录结构信息,以便进行代码调试
print('os.getcwd():', os.getcwd())
import time
import argparse
import time
import datetime
import math
import sys
import shutil
import moxing as mox # ModelArts上专用的moxing模块,可用于与OBS的数据交互,API文档请查看:https://github.com/huaweicloud/ModelArts-Lab/tree/master/docs/moxing_api_doc
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True2.2训练参数设置
parser = argparse.ArgumentParser(description='Panoptic Deeplab')
parser.add_argument('--training_dataset', default='/home/ma-user/work/panoptic-deeplab/', help='Training dataset directory') # 在ModelArts中创建算法时,必须进行输入路径映射配置,输入映射路径的前缀必须是/home/work/modelarts/inputs/,作用是在启动训练时,将OBS的数据拷贝到这个本地路径中供本地代码使用。
parser.add_argument('--train_url', default='./output', help='the path to save training outputs') # 在ModelArts中创建训练作业时,必须指定OBS上的一个训练输出位置,训练结束时,会将输出映射路径拷贝到该位置
parser.add_argument('--num_gpus', default=1, type=int, help='num of GPUs to train')
parser.add_argument('--eval', default='False', help='whether to eval')
parser.add_argument('--load_weight', default='trained_model/model/model_final.pth',type=str) # obs路径 断点模型 pth文件 如果是评估 则是相对于src的路径
parser.add_argument('--iteration', default=100, type=int)
parser.add_argument('--learning_rate', default=0.001, type=float)
parser.add_argument('--ims_per_batch', default=8, type=int)
args, unknown = parser.parse_known_args() # 必须将parse_args改成parse_known_args,因为在ModelArts训练作业中运行时平台会传入一个额外的init_method的参数
# dir
fname = os.getcwd()
project_dir = os.path.join(fname, "panoptic-deeplab")
detectron2_dir = os.path.join(fname, "detectron2-0.3+cu102-cp36-cp36m-linux_x86_64.whl")
panopticapi_dir = os.path.join(fname, "panopticapi-0.1-py3-none-any.whl")
cityscapesscripts_dir = os.path.join(fname, "cityscapesScripts-2.1.7-py3-none-any.whl")
requirements_dir = os.path.join(project_dir, "requirements.txt")
output_dir = "/home/work/modelarts/outputs/train_output"
# config strings
evalpath = ''
MAX_ITER = 'SOLVER.MAX_ITER ' + str(args.iteration+90000)
BASE_LR = 'SOLVER.BASE_LR ' + str(args.learning_rate)
IMS_PER_BATCH = 'SOLVER.IMS_PER_BATCH ' + str(args.ims_per_batch)
SCRIPT_PATH = os.path.join(project_dir, "tools_d2/train_panoptic_deeplab.py")
CONFIG_PATH = os.path.join(fname, "configs/config.yaml")
CONFIG_CMD = '--config-file ' + CONFIG_PATH
EVAL_CMD = ''
GPU_CMD = ''
OPTS_CMD = MAX_ITER + ' ' + BASE_LR + ' ' + IMS_PER_BATCH
RESUME_CMD = ''
#functions
def merge_cmd(scirpt_path, config_cmd, gpu_cmd, eval_cmd, resume_cmd, opts_cmd):
return "python " + scirpt_path + " "+ config_cmd + " " + gpu_cmd + " " + eval_cmd + " " + resume_cmd + " " + OPTS_CMD
if args.eval == 'True':
assert args.load_weight, 'load_weight empty when trying to evaluate' # 如果评估时为空,则报错
if args.load_weight != 'trained_model/model/model_final.pth':
#将model拷贝到本地,并获取模型路径
modelpath, modelname = os.path.split(args.load_weight)
mox.file.copy_parallel(args.load_weight, os.path.join(fname, modelname))
evalpath = os.path.join(fname,modelname)
else:
evalpath = os.path.join(fname,'trained_model/model/model_final.pth')
EVAL_CMD = '--eval-only MODEL.WEIGHTS ' + evalpath
else:
GPU_CMD = '--num-gpus ' + str(args.num_gpus)
if args.load_weight:
RESUME_CMD = '--resume'
if args.load_weight != 'trained_model/model/model_final.pth':
modelpath, modelname = os.path.split(args.load_weight)
mox.file.copy_parallel(args.load_weight, os.path.join('/cache',modelname))
with open('/cache/last_checkpoint','w') as f: #创建last_checkpoint文件
f.write(modelname)
f.close()
else:
os.system('cp ' + os.path.join(fname, 'trained_model/model/model_final.pth') + ' /cache/model_final.pth')
with open('/cache/last_checkpoint','w') as f: #创建last_checkpoint文件
f.write('model_final.pth')
f.close()
os.environ['DETECTRON2_DATASETS'] = args.training_dataset #添加数据库路径环境变量
cmd = merge_cmd(SCRIPT_PATH, CONFIG_CMD, GPU_CMD, EVAL_CMD, RESUME_CMD, OPTS_CMD)
# os.system('mkdir -p ' + args.train_url)
print('*********Train Information*********')
print('Run Command: ' + cmd)
print('Num of GPUs: ' + str(args.num_gpus))
print('Evaluation: ' + args.eval)
if args.load_weight:
print('Load Weight: ' + args.load_weight)
else:
print('Load Weight: None (train from scratch)')
print('Iteration: ' + str(args.iteration))
print('Learning Rate: ' + str(args.learning_rate))
print('Images Per Batch: ' + str(args.ims_per_batch))2.3安装依赖库
安装依赖库需要几分钟,请耐心等待
def install_dependecies(r,d, p, c):
os.system('pip uninstall pytorch> out1.txt')
os.system('pip install torch==1.7.0> out2.txt')
os.system('pip install --upgrade pip')
os.system('pip install --upgrade numpy')
os.system('pip install torchvision==1.7.0> out3.txt')
os.system('pip install pydot')
os.system('pip install --upgrade pycocotools')
os.system('pip install tensorboard')
os.system('pip install -r ' + r + ' --ignore-installed PyYAML')
os.system('pip install ' + d)
os.system('pip install ' + p)
os.system('pip install ' + c)
os.system('pip install pyyaml ==5.1.0')
# 安装依赖
print('*********Installing Dependencies*********')
install_dependecies(requirements_dir,detectron2_dir, panopticapi_dir, cityscapesscripts_dir)
*********Installing Dependencies*********2.4开始训练
print('*********Training Begin*********')
print(cmd)
start = time.time()
ret = os.system(cmd+ " >out.txt")
if ret == 0:
print("success")
else:
print('fail')
end_time=time.time()
print('done')
print(end_time-start)
if args.eval == 'False':
os.system('mv /cache/model_final.pth ' + os.path.join(fname, 'output/model_final.pth')) #/cache模型移动到输出文件夹
if os.path.exists(os.path.join(fname, 'pred_results')):
os.system('mv ' + os.path.join(fname, 'pred_results') + ' ' + args.train_url)训练完成之后,可以在out.txt中看运行日志
在./panoptic-deeplab/output/pred_results/文件目录下,有该模型全景分割,实例分割,语义分割的评估结果
3.模型测试
3.1加载测试函数
from test import *3.2开始预测
if __name__ == '__main__':
img_path = r'/home/ma-user/work/panoptic-deeplab/cityscapes/leftImg8bit/val/frankfurt/frankfurt_000000_003920_leftImg8bit.png' # TODO 修改测试图片路径
model_path = r'/home/ma-user/work/panoptic-deeplab/output/model_final.pth' # TODO 修改模型路径
my_model = ModelClass(model_path)
result = my_model.predict(img_path)
print(result)
点击关注,第一时间了解华为云新鲜技术~


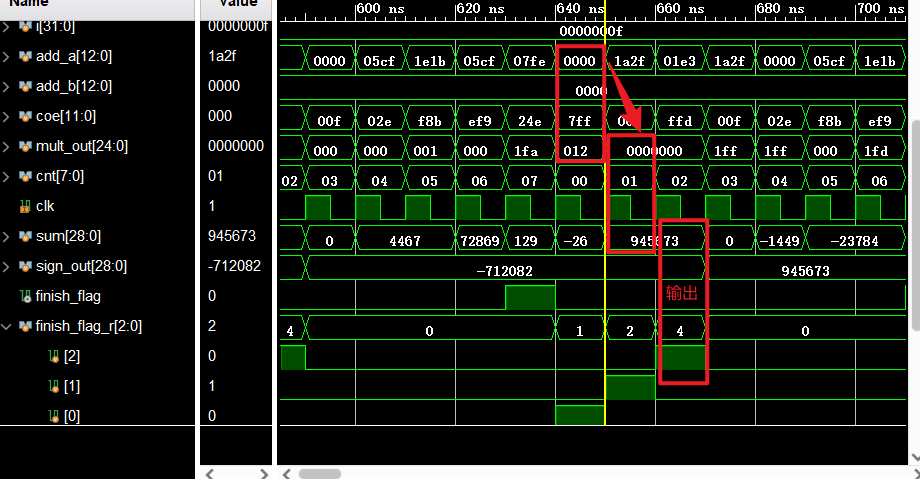







![[前端基础] JavaScript 基础篇(下)](https://img-blog.csdnimg.cn/770057b05f0b4f73809ee5a4915fa6ae.png#pic_center)