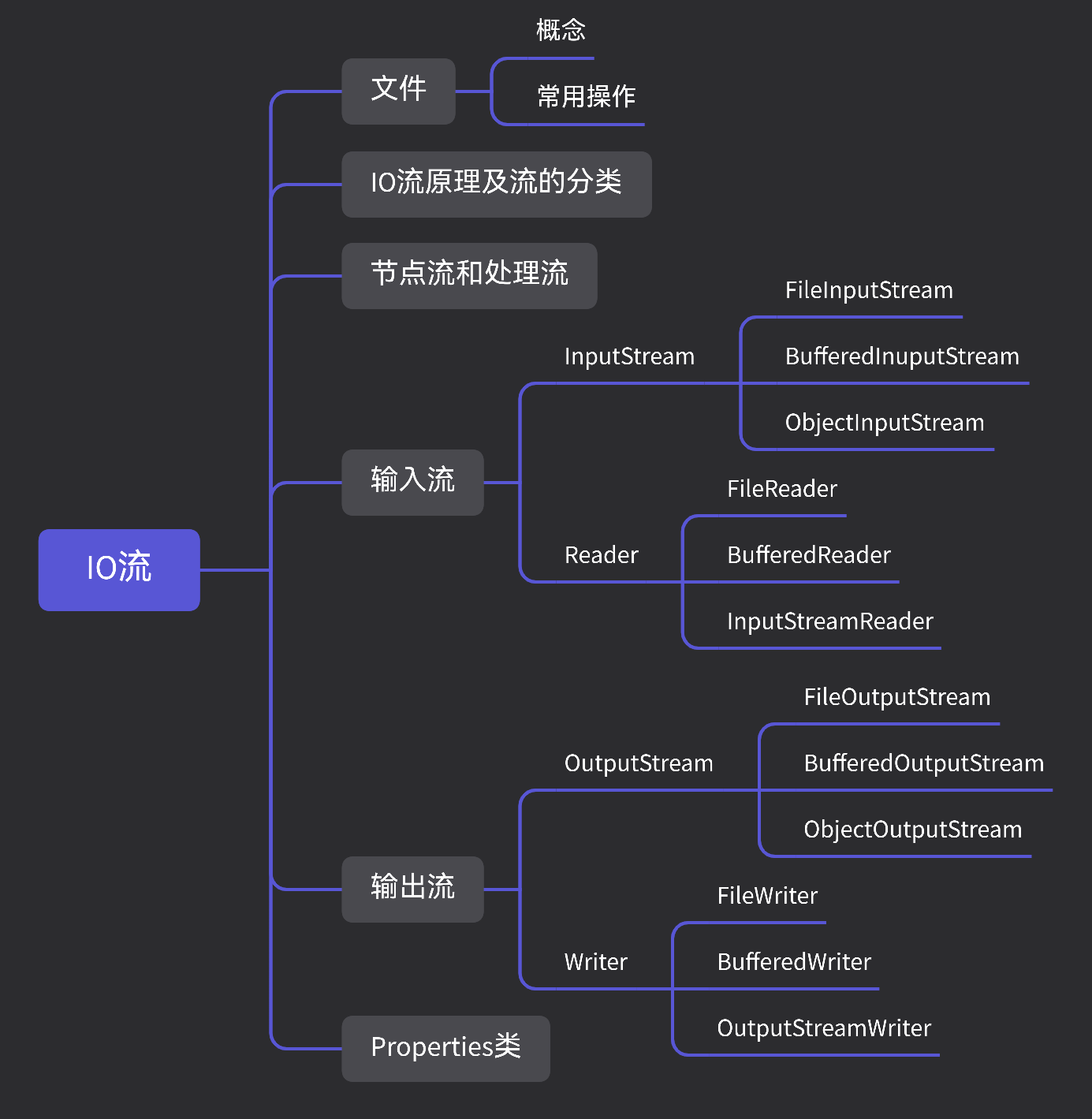
Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
扩散自编码器:面向有意义和可解码的表示
code:https://github.com/phizaz/diffae
A CVPR 2022 (ORAL) paper (paper, site, 5-min video)
Diffusion probabilistic models (DPMs) have achieved remarkable quality in image generation that rivals GANs’. But unlike GANs, DPMs use a set of latent variables that lack semantic meaning and cannot serve as a useful representation for other tasks. This paper explores the possibility of using DPMs for representation learning and seeks to extract a meaningful and decodable representation of an input image via autoencoding. Our key idea is to use a learnable encoder for discovering the high-level semantics, and a DPM as the decoder for modeling the remaining stochastic variations. Our method can encode any image into a two-part latent code where the first part is semantically meaningful and linear, and the second part captures stochastic details, allowing near-exact reconstruction. This capability enables challenging applications that currently foil GAN-based methods, such as attribute manipulation on real images. We also show that this two-level encoding improves denoising efficiency and naturally facilitates various downstream tasks including few-shot conditional sampling. Our novel latent space is more readily discriminative than StyleGAN-W (via inversion) when used to encode real input images.

Figure 1. Attribute manipulation and interpolation on real images.
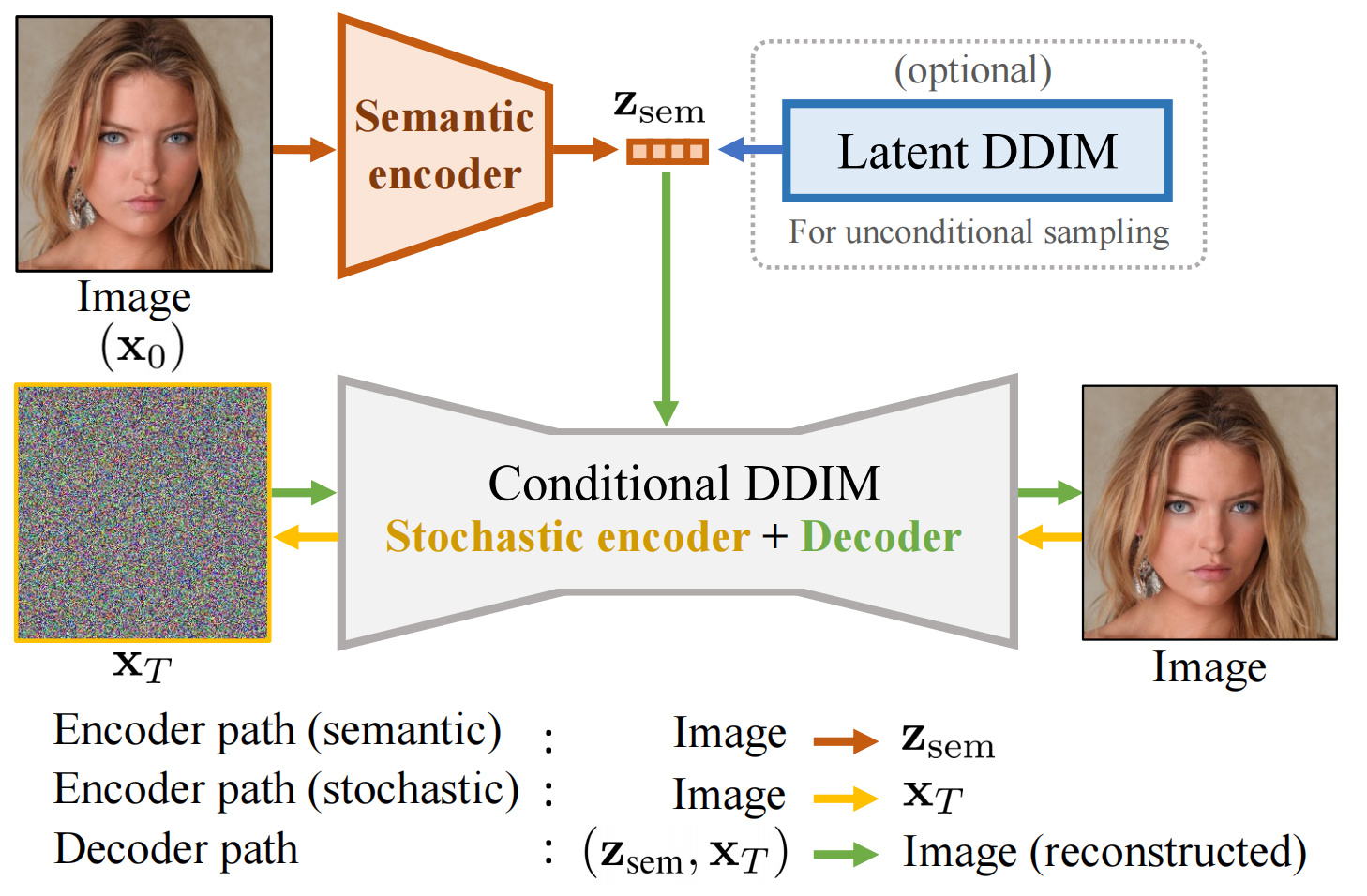
Figure 2: Overview of our diffusion autoencoder.
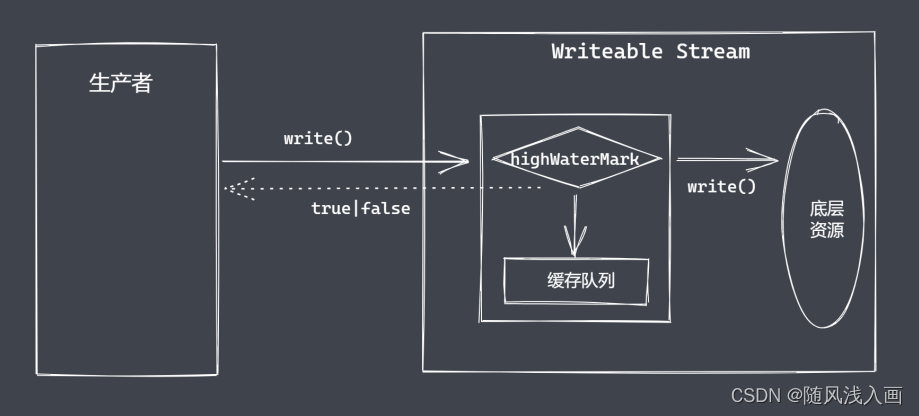
Autoencoder由4部分组成, Z s e m Z_{sem} Zsem 捕获了高级语义【semantics】, while X T X_T XT 捕获了低级的随机变化【stochastic variations / stochastic subcode】, 它俩一起可以精准的decoder回原始图像。
- a “semantic” encoder that maps the input image to the semantic subcode ( X 0 → Z s e m X_0 \to Z_{sem} X0→Zsem),
- a conditional DDIM that acts both as a “stochastic” encoder ( X 0 → X T X_0 \to X_{T} X0→XT )
- a decoder ( ( ( z s e m , x T ) → X 0 ) \left(\left(\mathbf{z}_{\mathrm{sem}}, \mathbf{x}_{T}\right) \rightarrow X_{0}\right) ((zsem,xT)→X0)).
- 为了从autoencoder采样(为了无条件图像生成), we fit a latent DDIM to the distribution of Z s e m Z_{sem} Zsemand sample ( z s e m , x T ∼ N ( 0 , I ) ) \left(\mathbf{z}_{\mathrm{sem}}, \mathbf{x}_{T} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\right) (zsem,xT∼N(0,I)) for decoding.

Figure 3. 由改变随机子码
X
T
X_T
XT 引起的变化和重建结果. 每一行对应一个不同的
Z
s
e
m
Z_{sem}
Zsem, 它完全改变了人,而改变随机子码
X
T
X_T
XT 只影响次要的细节。

Figure 5. 通过移动被线性分类器发现的
Z
s
e
m
Z_{sem}
Zsem 的正向或逆向
Z
s
e
m
Z_{sem}
Zsem 改变人脸的属性。

Figure 6. 逆向生成
x
0
x_0
x0 at
t
9
,
8
,
7
,
5
,
2
,
0
(
T
=
10
)
t_{9,8,7,5,2,0} (T=10)
t9,8,7,5,2,0(T=10). 通过以
Z
s
e
m
Z_{sem}
Zsem 为条件, 我们的方法生成与
x
0
x_0
x0相似的图像更快。
写在最后: 其实这种通过改变latent的方式改变外观/一些属性的方法并不好,因为真实的效果很差,他们只展示效果比较好的,并且你在训练的时候需要标注大量的数据集,比如眼睛的位置、嘴巴的位置、…










![[前端基础] JavaScript 基础篇(下)](https://img-blog.csdnimg.cn/770057b05f0b4f73809ee5a4915fa6ae.png#pic_center)