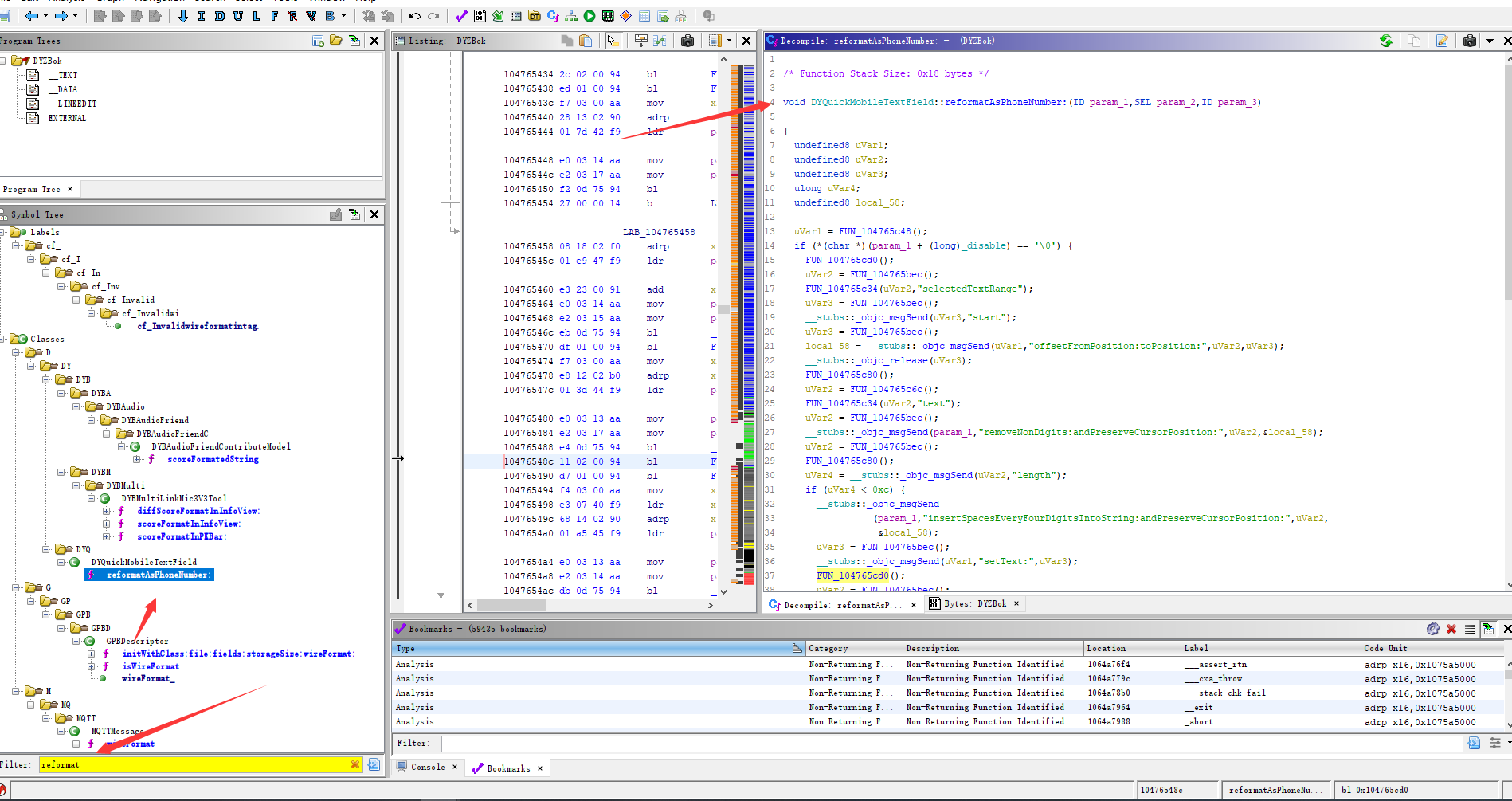
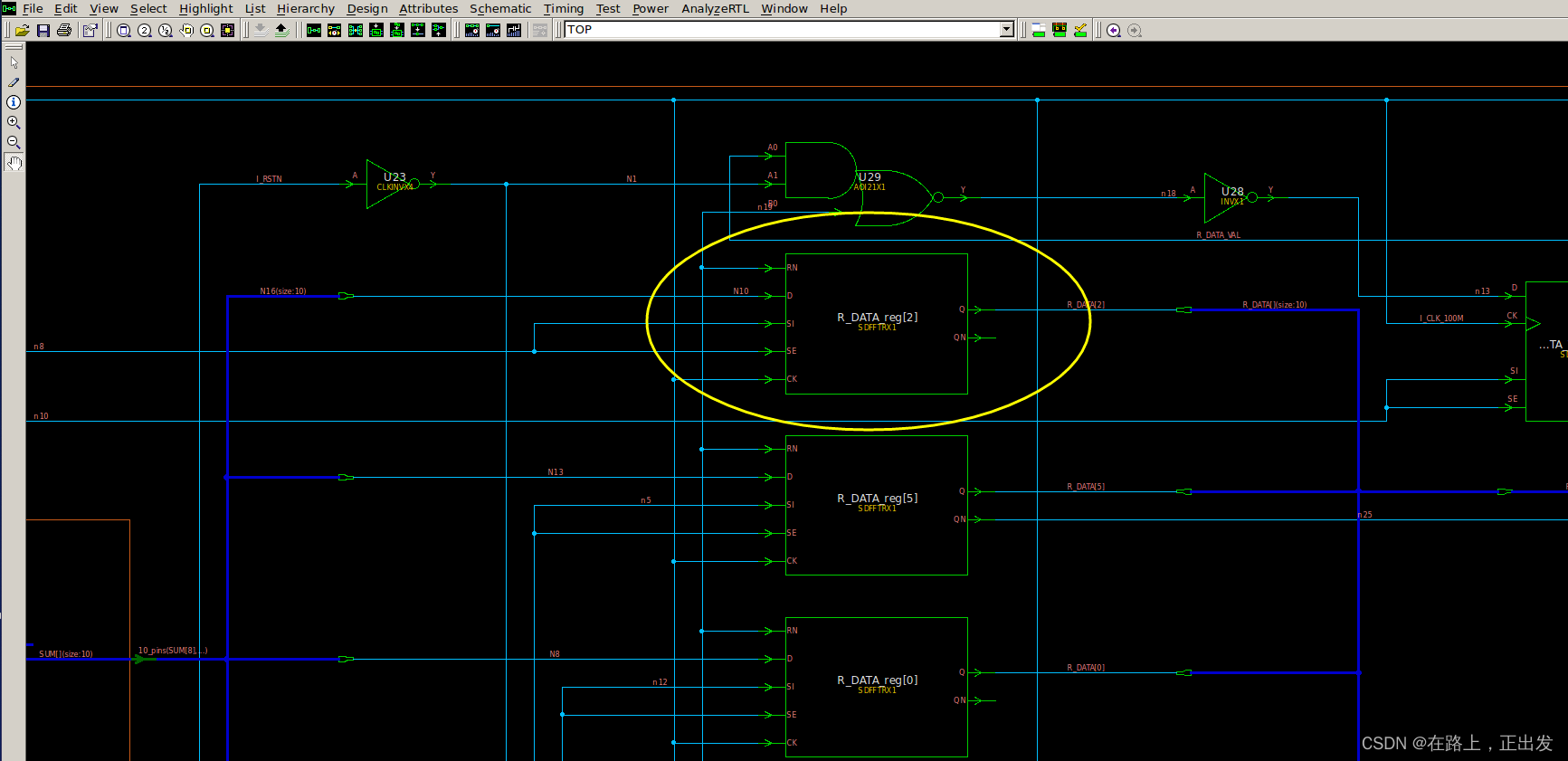
Node.js诞生之初就是为了提高IO性能,文件操作系统和网络模块实现了流接口,Node.js中流就是处理流式数据的抽象接口。
那么应用程序为什么使用流来处理数据?
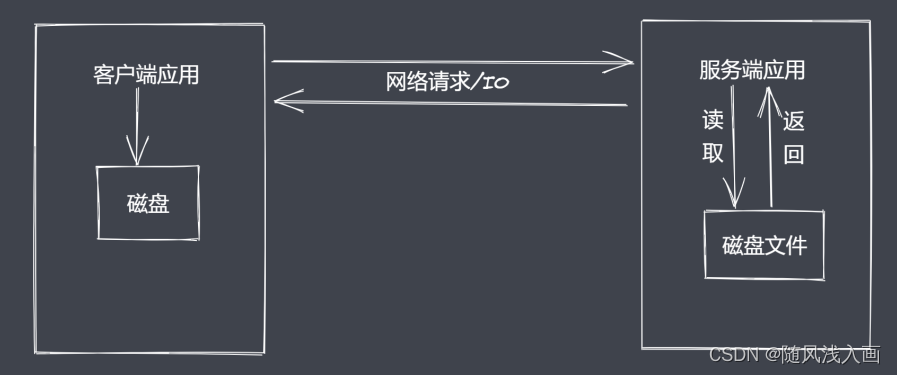
常见问题
- 同步读取资源文件,用户需要等待数据读取完成
- 资源文件最终一次性加载至内存,开销较大
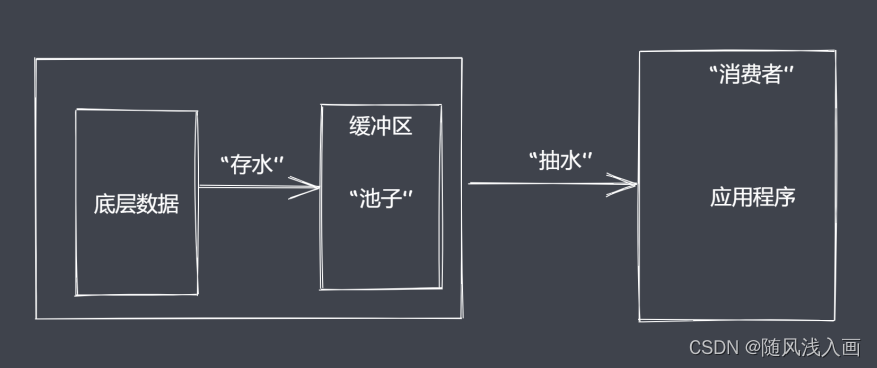

流处理数据的优势
- 时间效率: 流的分段处理可以同时操作对个数据chunk
- 空间效率: 同一时间流无序占据大内存空间
- 使用方便: 流配合管理,扩展程序变得简单
Node.js中流的分类
- Readable: 可读流,能够实现数据的读取
- Writeeale: 可写流,能够实现数据的写操作
- Duplex:双工流,季可读又可写
- Tranform:转换流,可读可写,还能实现数据转换
Node.js流特点
- Sream 模块实现了四个具体的抽象
- 所有流都继承自EventEmitter
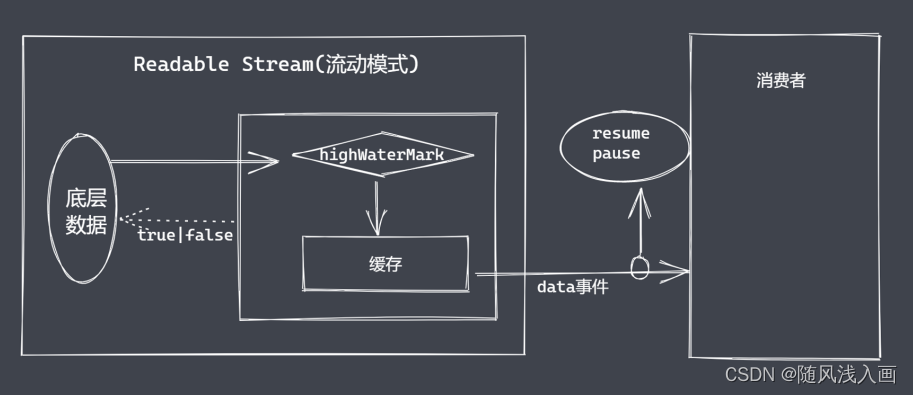
可读流
生产供程序消费数据的流,如何自定义可读流?
自定义可读流
- 继承stream里的Readable
- 重写_read方法调用push产出数据
自定义可读流的问题
- 底层数据读取完成之后如何处理?
- 消费者如何获取可读流中的数据?
消费数据为什么存在两种方式
- 流动模式
- 暂停模式
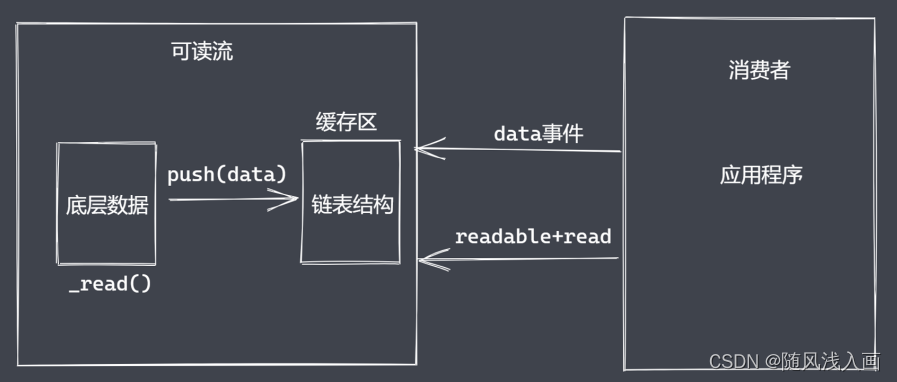
消费数据
- readable事件:当流中存在可读取数据时触发
- data事件: 当流中数据块传给消费者后触发
可读流总结
- 明确数据产生与消费流程
- 利用API实现自定义可读流
- 明确数据消费的事件使用
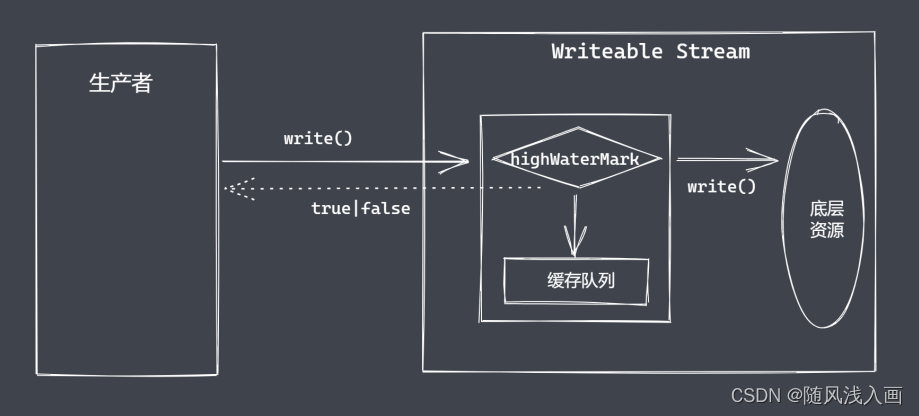
可写流
用于消费数据的流
自定义可写流
- 继承stream模块的Writeable
- 重写_write方法,调用write执行写入
可写流事件
- pipe事件:可读流调用pipe()方法时触发
- unpipe事件:可读流调用unpipe()方法时触发
- drain事件:write返回false,数据可执行写入时触发
Duple &&Transform
Node.js中stream是流操作的抽象接口集合,可读、可写、双攻、转换是单一抽象的具体实现。流操作的核心功能就是处理数据。Node.js诞生之初就是解决密集型IO事务。Node.js中处理数据模块继承了流和EventEmitter
stream、四种类型流、实现流操作的模块
Duplex是双工流,技能生成又能消费
自定义双工流
- 继承Duplex类
- 重写_read方法,调用push生产数据
- 重写_write方法,调用write消费数据
- Transform也是一个双工流
自定义转换流
- 继承Transform类
- 重写_transform类,调用push和callback
- 重写_flush方法,处理剩余数据
Node.js中的四种流
- Readable可读流
- 继承Readable与EventEmitter
- Writeable可写流
- Duplex双工流
- Transform转换流
- drain与写入速度
背压机制
Node.js的stream已实现了背压机制
数据读写时可能存在的问题
内存溢出、GC频繁调用、其它进程变慢