目录
- 概述
- 前向过程
- 逆向过程
- DDPM
概述
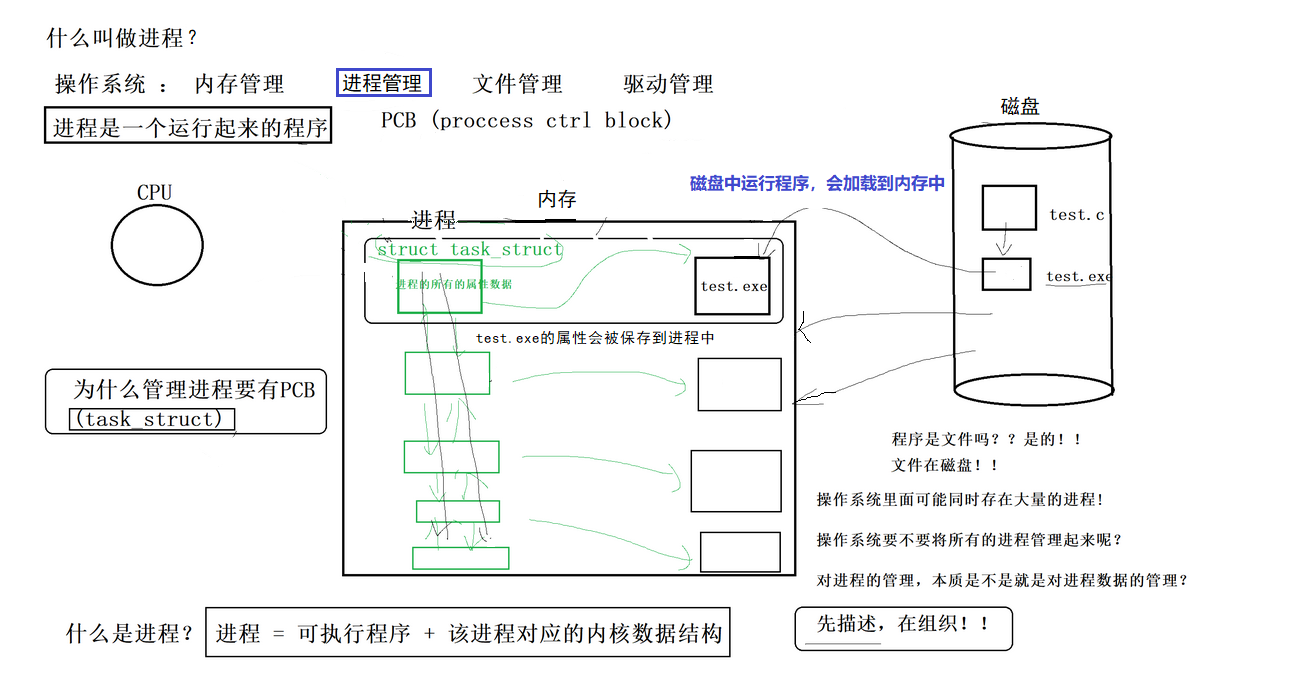
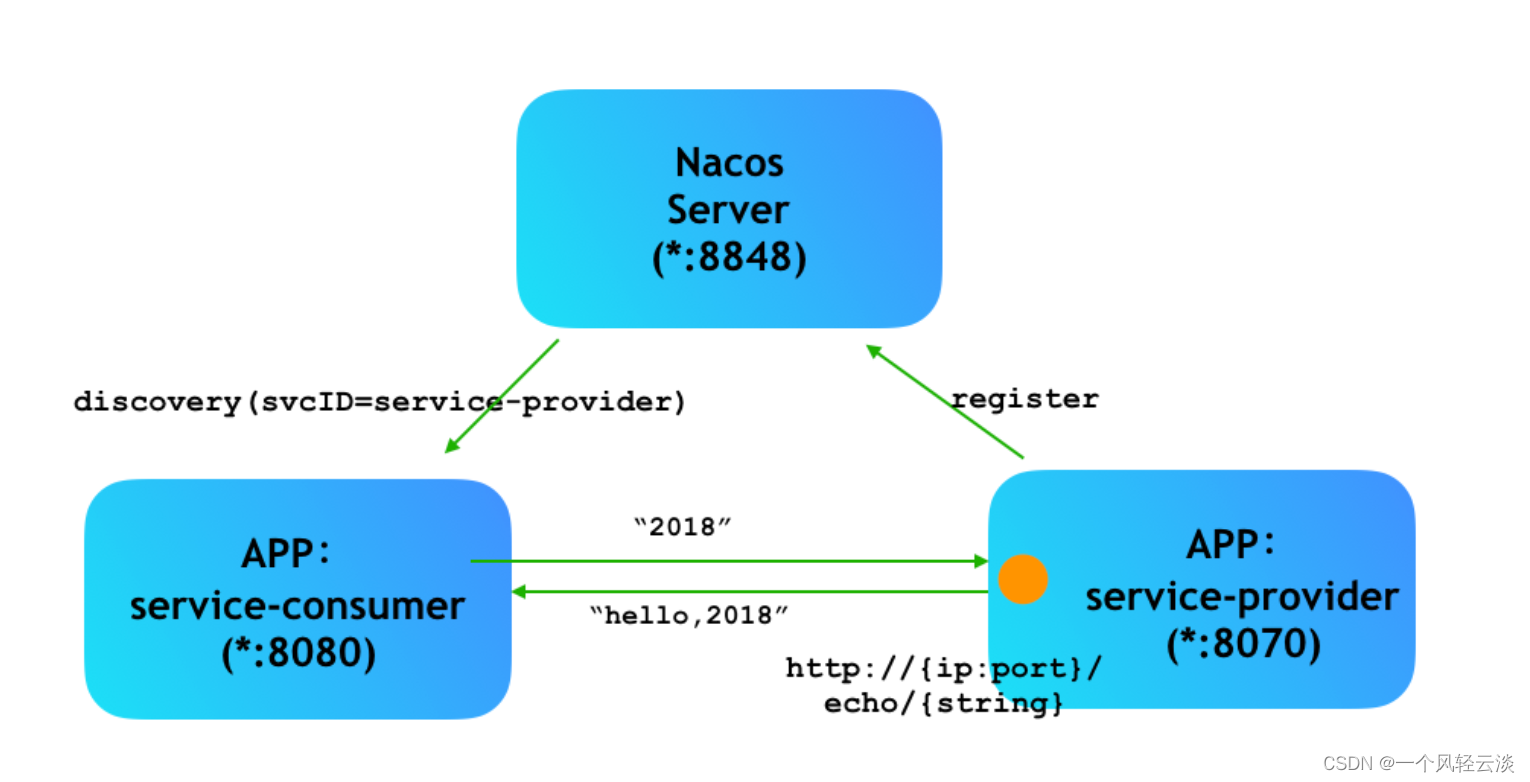
近几年扩散模型不断涌现,但都来源于一个基础模型:DDPM(Denoising Diffusion Probabilistic Model)。扩散模型本质是生成模型,过去我们常用的生成模型包括GAN和VAE,利用随机噪声生成图像样本。GAN和VAE有一个共同点,它们都是使用一个网络直接一步式生成结果,如果要获得好的生成结果,不得不追求更复杂的网络,但是这会导致训练困难。
相反,DDPM中包含了一个新的想法,对于前向过程,我们对
x
0
x_{0}
x0 逐步加噪声,得到一系列的数据
x
t
−
1
,
x
t
,
.
.
.
,
x
T
x_{t-1},x_{t},...,x_{T}
xt−1,xt,...,xT。如下图所示:

虽然前向步骤和图像生成没有关系,但这是构建训练样本GT的重要步骤。
前向过程的每个时刻 t t t只与时刻 t − 1 t-1 t−1有关,所以可以看作马尔可夫过程,扩散的目的是通过马尔可夫过程将 x 0 x_{0} x0逐渐映射到多维正态分布(高斯噪声)。其中每一步的随机过程为 q ( x t ∣ x t − 1 ) q(x_{t}|x_{t-1}) q(xt∣xt−1),这个过程由我们自己定义(是已知的),通常,我们把加噪声的过程定义为(利用了重参数方式): x t = α t x t − 1 + β t ϵ t , ϵ t ∼ N ( 0 , I ) x_{t}=\alpha_{t}x_{t-1}+\beta_{t}\epsilon_{t},\epsilon_{t}\sim N(0,I) xt=αtxt−1+βtϵt,ϵt∼N(0,I)其中, α t , β t \alpha_{t},\beta_{t} αt,βt是系数,并且满足调和关系: α t 2 + β t 2 = 1 \alpha_{t}^{2}+\beta_{t}^{2}=1 αt2+βt2=1其中, β t \beta_{t} βt是随着 t t t的增加不断变大的。
从 x T x_{T} xT到 x 0 x_{0} x0的过程是扩散的逆向过程,图像慢慢从高斯噪声变换到正常图像,每一步的随机过程为 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_{t}) q(xt−1∣xt),该过程是未知的,因此扩散模型要做的是定义一个可学习的为 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_{t}) pθ(xt−1∣xt)的逆向过程,通过优化参数 θ \theta θ,使得该过程尽可能接近真实逆向过程 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_{t}) q(xt−1∣xt),从而使我们能通过一个高斯噪声生成正常图像。
前向过程
DDPM定义的前向过程为: q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , β t I ) q(x_{t}|x_{t-1})=N(x_{t};\sqrt{\alpha_{t}}x_{t-1},\beta_{t}I) q(xt∣xt−1)=N(xt;αtxt−1,βtI)由于高斯分布的性质,可以得到: q ( x t ∣ x 0 ) = N ( x t ; α ‾ t x 0 , ( 1 − α ‾ t ) I ) q(x_{t}|x_{0})=N(x_{t};\sqrt{\overline{\alpha}_{t}}x_{0},(1-\overline{\alpha}_{t})I) q(xt∣x0)=N(xt;αtx0,(1−αt)I)其中 I I I为单位矩阵, α ‾ t = ∏ i = 1 t α i \overline{\alpha}_{t}=\prod_{i=1}^{t}\alpha_{i} αt=∏i=1tαi,由于 α t \alpha_{t} αt是逐渐减小的,所以当 t t t接近无穷时, q ( x t ∣ 0 ) = N ( x t ; 0 , I ) q(x_{t}|0)=N(x_{t};0,I) q(xt∣0)=N(xt;0,I),即此时 x t x_{t} xt服从标准正态分布。
关于 N ( x t ; 0 , I ) N(x_{t};0,I) N(xt;0,I),指的是 x t ∼ N ( 0 , I ) x_{t}\sim N(0,I) xt∼N(0,I)。
逆向过程
对于逆向的随机过程 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_{t}) q(xt−1∣xt)是无法求出的,但是在已知 x 0 x_{0} x0的情况下,我们可以通过贝叶斯公式求出: q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) = N ( x t − 1 ; μ ~ t ( x t , x 0 ) , β ~ t I ) q(x_{t-1}|x_{t},x_{0})=q(x_{t}|x_{t-1},x_{0})\frac{q(x_{t-1}|x_{0})}{q(x_{t}|x_{0})}\\=N(x_{t-1};\widetilde{\mu}_{t}(x_{t},x_{0}),\widetilde{\beta}_{t}I) q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)=N(xt−1;μ t(xt,x0),β tI)其中: μ ~ t ( x t , x 0 ) = α t ( 1 − α ‾ t − 1 ) 1 − α ‾ t x t + α ‾ t − 1 β t 1 − α ‾ t x 0 \widetilde{\mu}_{t}(x_{t},x_{0})=\frac{\sqrt{\alpha_{t}(1-\overline{\alpha}_{t-1})}}{1-\overline{\alpha}_{t}}x_{t}+\frac{\sqrt{\overline{\alpha}_{t-1}}\beta_{t}}{1-\overline{\alpha}_{t}}x_{0} μ t(xt,x0)=1−αtαt(1−αt−1)xt+1−αtαt−1βtx0 β ~ t = 1 − α ‾ t − 1 1 − α ‾ t β t \widetilde{\beta}_{t}=\frac{1-\overline{\alpha}_{t-1}}{1-\overline{\alpha}_{t}}\beta_{t} β t=1−αt1−αt−1βt对随机过程 q ( x t ∣ x 0 ) q(x_{t}|x_{0}) q(xt∣x0)使用重参数方法,得到 x t x_{t} xt关于 x 0 x_{0} x0的表达式,并且表达式中包含一个高斯噪声 ϵ t ∼ N ( 0 , I ) \epsilon_{t}\sim N(0,I) ϵt∼N(0,I),再转换一下变量,就得到: x 0 = x t − 1 − α ‾ t ϵ t α t x_{0}=\frac{x_{t}-\sqrt{1-\overline{\alpha}_{t}}\epsilon_{t}}{\sqrt{\alpha_{t}}} x0=αtxt−1−αtϵt把 x 0 x_{0} x0代入 μ ~ t ( x t , x 0 ) \widetilde{\mu}_{t}(x_{t},x_{0}) μ t(xt,x0)得到: μ ~ t = 1 α t ( x t − β t 1 − α ‾ t ϵ t ) \widetilde{\mu}_{t}=\frac{1}{\sqrt{\alpha_{t}}}(x_{t}-\frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}\epsilon_{t}) μ t=αt1(xt−1−αtβtϵt)到这里,我们发现,如果我们假设我们知道了 x 0 x_{0} x0,我们可以根据 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_{t},x_{0}) q(xt−1∣xt,x0)采样出 x t − 1 x_{t-1} xt−1,但问题在于,在重参数过程中有一个随机噪声 ϵ t \epsilon_{t} ϵt,尽管它服从标准正态分布,但是要还原到 x 0 x_{0} x0,我们必须确保逆向过程的每一步都能准确预测出每一步的 ϵ \epsilon ϵ的具体噪声值。所以,DDPM使用UNet来预测这个噪声值。
DDPM
我们先设: p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , β ~ t I ) p_{\theta}(x_{t-1}|x_{t})=N(x_{t-1};\mu_{\theta}(x_{t},t),\widetilde{\beta}_{t}I) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),β tI)而 μ θ ( x t , t ) \mu_{\theta}(x_{t},t) μθ(xt,t)的表达式为: μ θ ( x t , t ) = 1 α t ( x t − β t 1 − α ‾ t ϵ θ ( x t , t ) ) \mu_{\theta}(x_{t},t)=\frac{1}{\sqrt{\alpha_{t}}}(x_{t}-\frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}\epsilon_{\theta}(x_{t},t)) μθ(xt,t)=αt1(xt−1−αtβtϵθ(xt,t))其中, ϵ θ \epsilon_{\theta} ϵθ就是这个UNet, θ \theta θ是网络参数,网络输入 x t x_{t} xt和 t t t,然后预测出该时刻的噪声 ϵ ^ t \widehat{\epsilon}_{t} ϵ t,然后根据下面式子从 x t x_{t} xt回到 x t − 1 x_{t-1} xt−1: x t = α t x t − 1 + β t ϵ t → x t − 1 = x t − β t ϵ ^ t α t x_{t}=\alpha_{t}x_{t-1}+\beta_{t}\epsilon_{t}\rightarrow x_{t-1}=\frac{x_{t}-\beta_{t}\widehat{\epsilon}_{t}}{\alpha_{t}} xt=αtxt−1+βtϵt→xt−1=αtxt−βtϵ t因此,对于训练,只需要让UNet在每个时刻的输出拟合前向过程对应时刻采样出的噪声即可: L t = ∣ ∣ ϵ t − ϵ ^ t ∣ ∣ = ∣ ∣ ϵ t − ϵ ^ ( x t , t ) ∣ ∣ L_{t}=||\epsilon_{t}-\widehat{\epsilon}_{t}||=||\epsilon_{t}-\widehat{\epsilon}(x_{t},t)|| Lt=∣∣ϵt−ϵ t∣∣=∣∣ϵt−ϵ (xt,t)∣∣