首先区分加密与编码并不是一回事,
本节主要讲述常见的三种编解码方式,分别为:Unicode、URL、Base64。
-
常见编码算法:
- Unicode编码:每一字符都可变成以 \u 开头,长度为6的字符串。
- URL编码:以百分号%开头,全大写。由于中文在utf-8中大多数以3字节(即24比特位)表示,所以每个汉字都会变成以百分号%开头、紧接着2位16进制数,一共三份、总长度为9的字符串。
- Base64编码:把二进制数据变成文本格式,这样在很多文本中就可以处理二进制数据。例如要在电子邮件中添加一个二进制文件,就可以使用Base64编码,然后以文本的形式传送;或者将其他加密方式产生的二进制密文转化为十六进制的字符串密文。它会把原始数据的长度【约】增加1/3,但其他编码算法并不一定比其更优。
-
Java常见解码思路:
- 首先获取被编码的字符流,即byte[]。因为byte是二进制数0/1,相当于获取了最原始的二进制数据,1字节等于8位二进制数bit,范围从-128 ~ 127。
- 利用String等方式尝试不同的字符集,解码。
【本质】:用对应的“字符集”来解二进制码。
// 指定了一种编码方式 byte[] bytes = "中文".getBytes("GBK"); // 用相对应的 “字符集” 方式来解码 String msg = new String(bytes, "GBK"); -
Unicode编解码
- 需编写固定逻辑,较麻烦,直接使用hutool框架即可。
// Unicode编码 String en = UnicodeUtil.toUnicode("中国"); // Unicode解码,\u4e2d\u6587 String msg="\\u4e2d\\u6587"; String s = UnicodeUtil.toString(en); -
URL编解码(Java原生)
- URLEncoder
- URLDecoder
// URL编码 String en = URLEncoder.encode("中文", StandardCharsets.UTF_8); String en = URLEncoder.encode("中文", "utf-8");// URL解码 String de = URLDecoder.decode("%E4%B8%AD%E6%96%87", "utf-8"); -
Base64编解码
-
原理解释:原先是8位一字节,即8位二进制数可以表示一字符;现在我们令6位表示一字符,所以如果原来是【Man】,则会被翻译为【TWFu】,即虽然底层的数据量没变(还是24位),但是所表示的数据长度增加了1/3(由 size = 3 变为 size = 4 )。
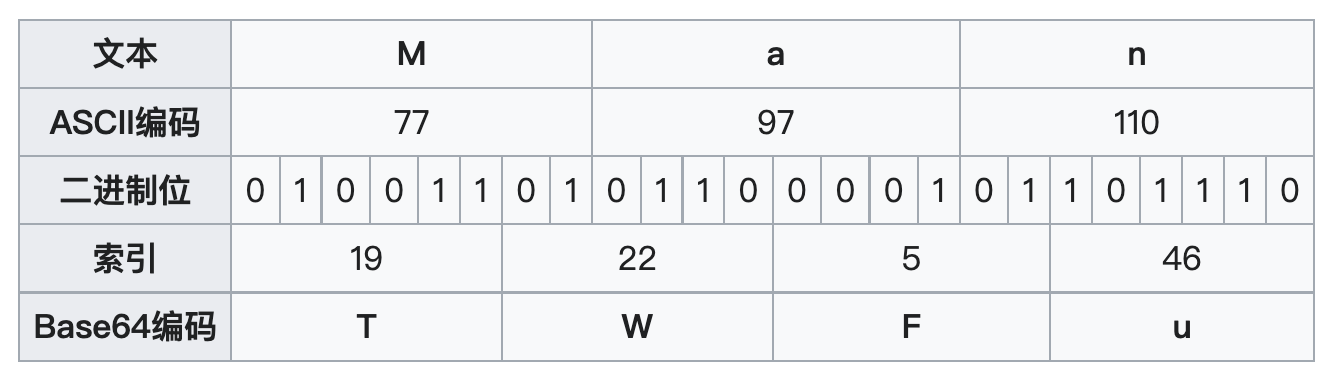
(3个字节相当于24个比特,对应于4个Base64单元)
-
另外,如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。【然后】因为被补足的地方会用等于号
=作后缀(此时为补足号=而不是6个0代表的索引“A”,这点要分清),所以我们才能经常看到编码的末尾出现等号。
(8与16不能被3整除,24才能被3整除)
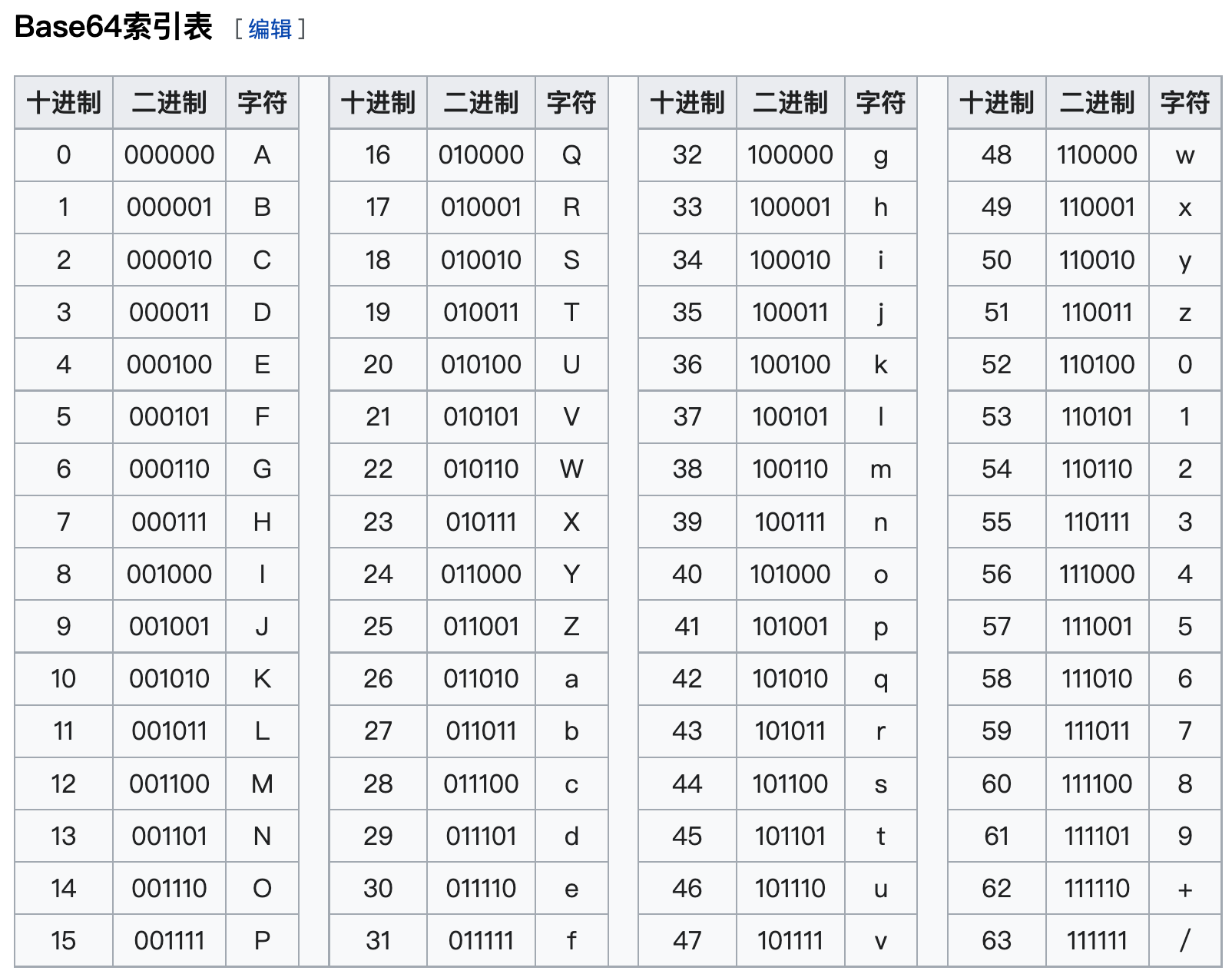
(总共65字符 = 64个字符 + 补足符
=) -
Java原生
// Base64编码 Base64.getEncoder().encodeToString("中国".getBytes()); // Base64解码 byte[] bytes = Base64.getDecoder().decode(a); String decode = new String(bytes);- hutool框架:本质还是源于Java原生的方式,只是作了层简易“封装”,如无必要不建议导入使用。
String encode = Base64.encode("中国"); String decode = Base64.decodeStr(encode); -