语音合成TTS
学习李宏毅课程。
输入文字,输出语音。
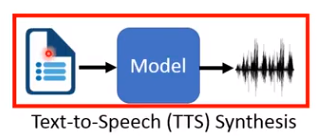
端到端之前TTS
18世纪就有,能找到demo的是1939年VODER。
就像电子琴一样,用手控制发出不同声音。

到1960年,IBM计算机能合成出歌唱声。
波形拼接
过去最常用的商用语音合成系统:
就是在库里对每个音都存起来,比如说你好吗,就把这三个字的音从数据库里找出来,拼接在一起。
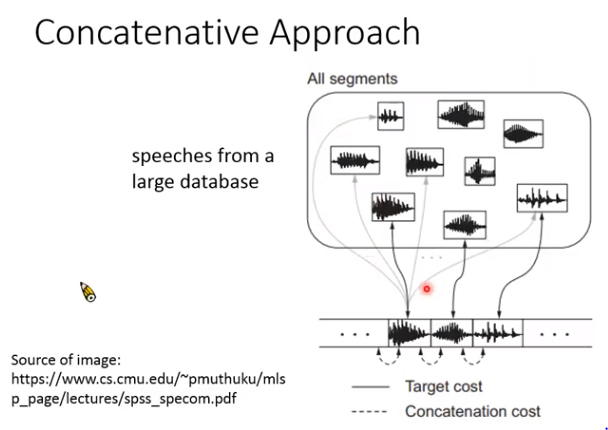
局限性:1. 不自然;2. 要男女声都有,数据库非常大。
随着机器学习的发展,出现了:
参数合成
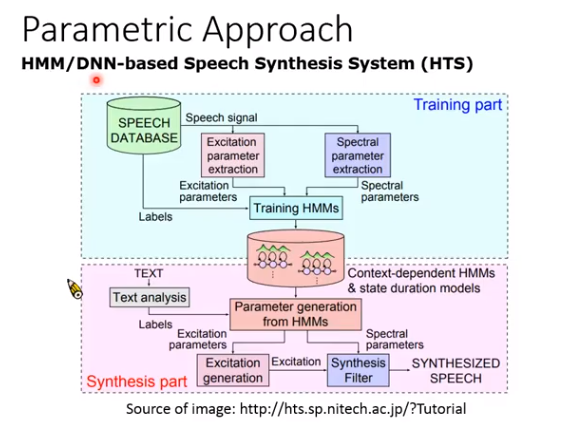
机器输出概率最大的那个,但概率最大的讲就是均值,所以很长一段都是同样的输出,听起来比较奇怪,但也有人解决这个问题,不过解决方法都很复杂。
后来,进入深度学习时代。
Deep Voice
每个蓝色模块都是基于深度学习的。当时人们只是想到对每个部分进行训练。
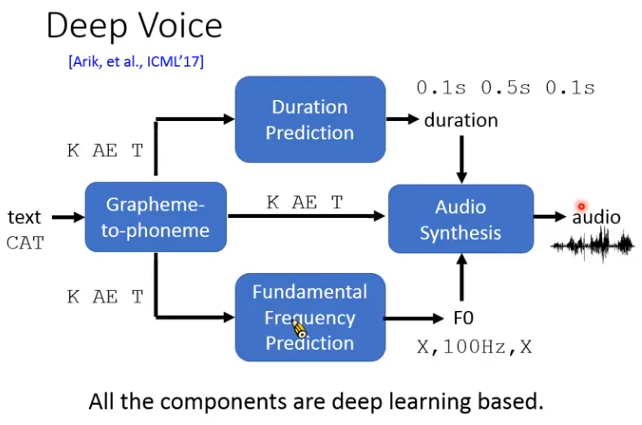
如果把上面每个模块都串起来一起train,就是端到端TTS。
端到端TTS
早期端到端TTS
早期人们尝试输入音素,输出如基频,频谱等声学特征,然后用声码器合成。或者输入字,输出声学特征。

Tacotron
而tacotron是最狂的,输入文字,直接输出语谱图,然后就能线性变换到波形。

tacotron字面是什么意思呢?
taco是一种食物,墨西哥卷饼。tron就只是为了增加科技感。

Tacotron结构
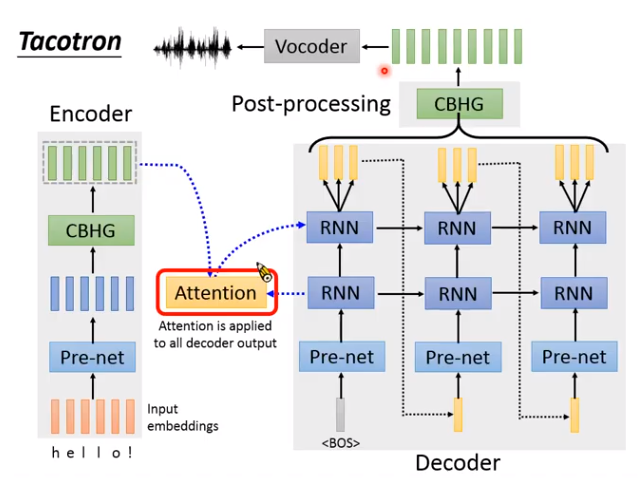
Encoder:
把输入的文字转成一组向量。
甚至输入可以有标点符号,让机器学到逗号就是停顿,句号就是结束,感叹号就很惊讶的样子等等。
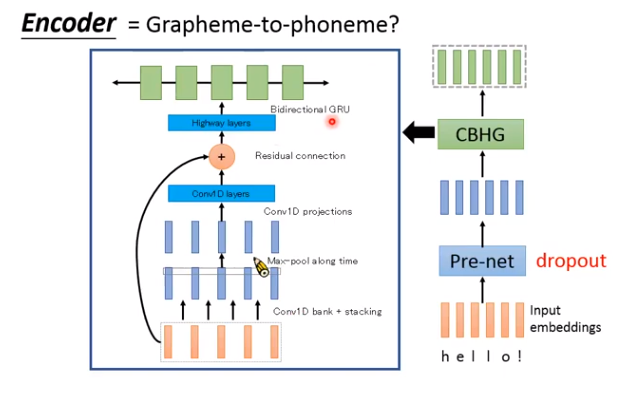
- Pre-net:就是几层全连接的神经网络。
- CBHG:一个比较复杂的模块。(CB就是Conv Bank;H就是Highway layers ;G就是GRU)
为什么要用CBHG,可以不用吗?
可以,v2版本就没用了。

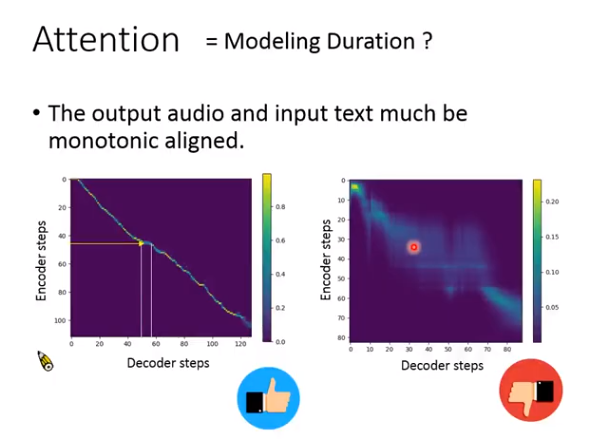
Attention
文字和声音要有个对应的顺序。
哪段文本,对用声音的哪段语谱。这个对应关系的建模就用attention机制,如下图,如果是左边很好的一条对角线,就说明结果比较好,右边的比较模糊,说明模型有问题。
Decoder
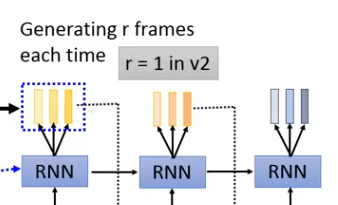
将encoder编码的向量,解码成语谱。注意,Decoder每次会输出好几个向量(why?因为语音信号比较长,一个向量才几毫秒,太短了,多输出几个减少运算量)。第一代里r=3或5。第二代r=1。
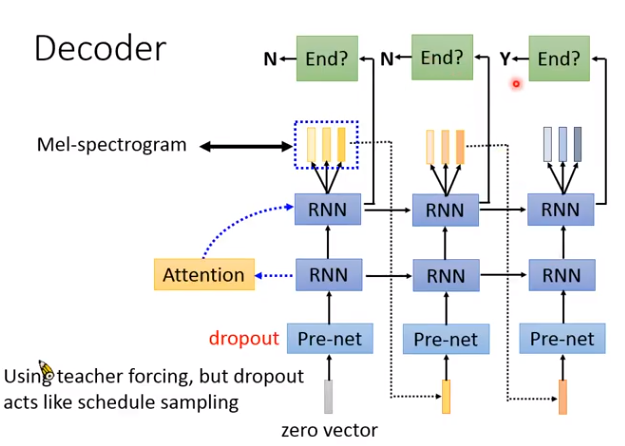
Decoder整体结构如下,如何判断句子结束呢?把RNN接上一个二分类器,输出小于0.5就继续,大于0.5就结束。
训练的时候,输入有正确答案,测试的时候没有,导致mismatch。但有个dropout机制,在训练的时候模拟出错的情况。
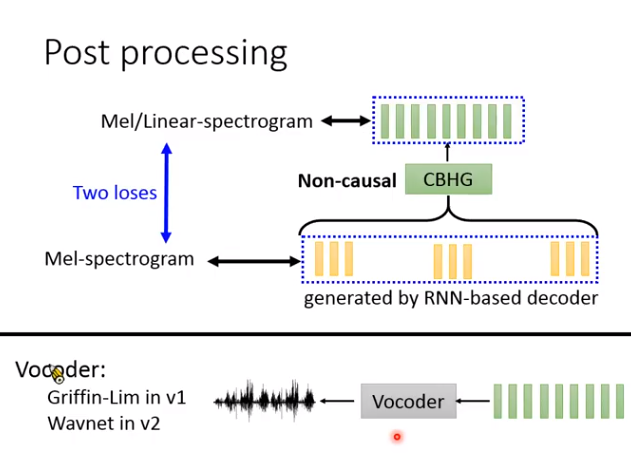
Post processing
在第一代里是CBHG模块,第二代里就是一堆卷积。
后处理的神经网络作用:
Non-causal,就是可以看整段向量是什么。
对Decoder输出的向量做检查修正。
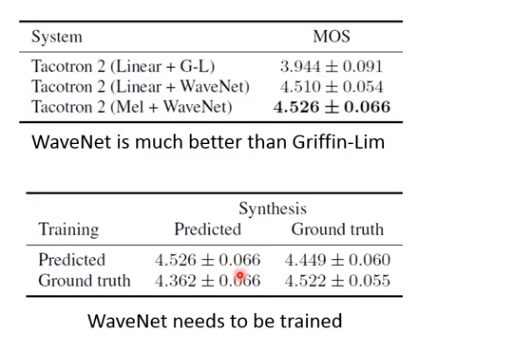
Tacotron系统好坏?
可以看到第二代很强,一个关键原因是换成了神经网络声码器。

有个很重要的发现:
Tacotron在推理阶段要加dropout!!!
为什么呢?一般dropout在训练时用,推理时要去掉。但Tacotron推理要是不用的话压根出不来人声。目前还没有好的解释为什么。