工具库 transformers 的开源方 Hugging Face 发布了一个专注于 diffuser 模型的开源库,我们可以基于它,仅仅通过几行代码就开始生成自己的艺术作画。不过这个 diffuser 库是一个基础实现版本,训练和学习的数据也没有 OpenAI 的 DALL-E2、谷歌的 Imagen 和 Midjourney 的产品多。本次实验就是windows环境下的文本生成图像的尝鲜体验版。
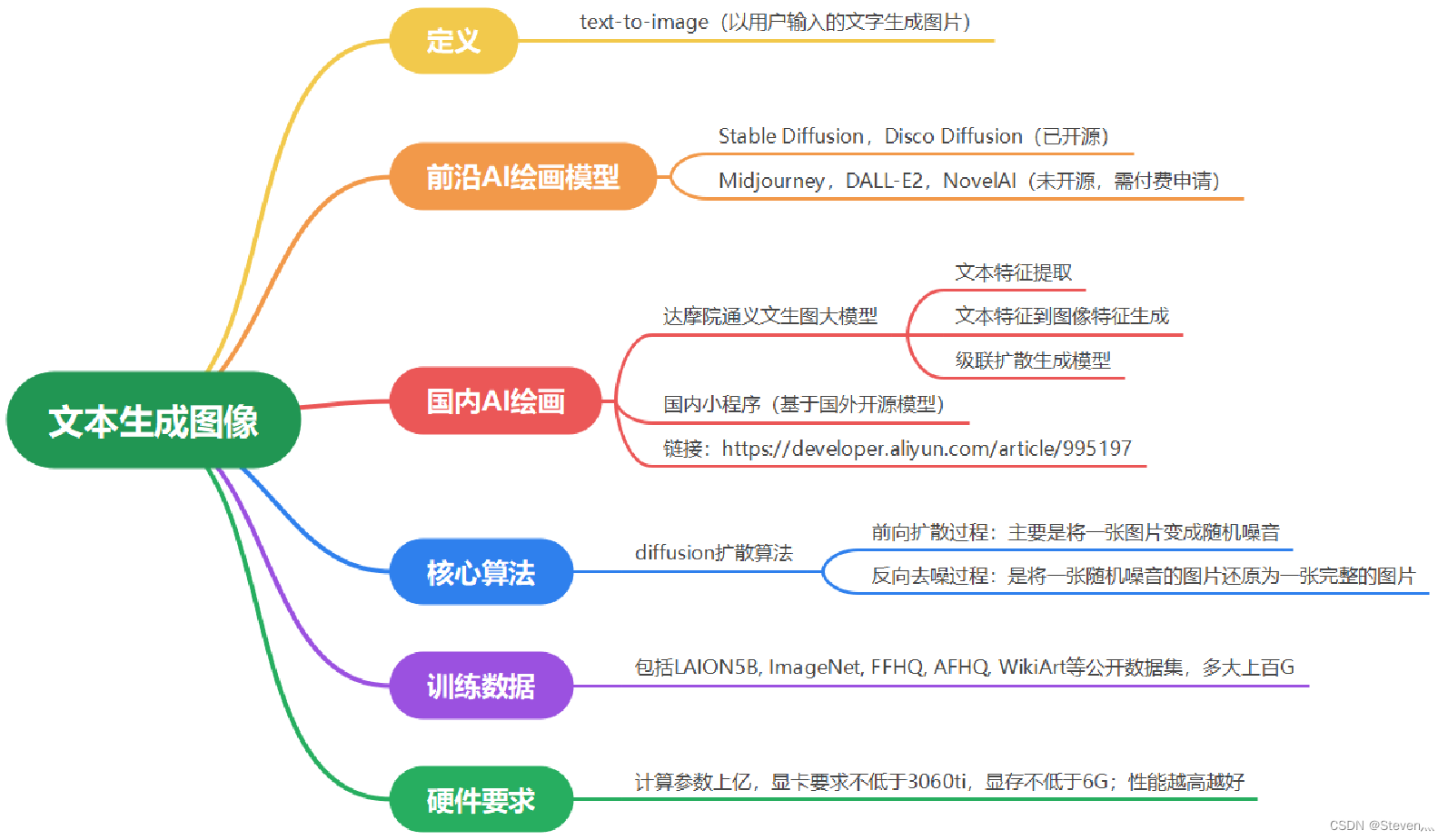
文本生成图像大致情况概览:
本地环境:
| 操作系统 | windows10 专业版 |
| Python版本 | Python3.8.8 |
| 硬件环境 | i5 8G内存,没有显卡 |
快速体验:
安装本次使用到的工具库diffusers
pip install diffusers然后导入我们需要用到的模块和功能(在这里我们调用整个扩散模型流水线 DiffusionPipeline),并且我们导入一个小型预训练模型ldm-text2im-large-256:
from diffusers import DiffusionPipeline
model_id = "CompVis/ldm-text2im-large-256"
# 预训练模型
ldm = DiffusionPipeline.from_pretrained(model_id)接着我们就可以基于这个预训练模型作画啦,我们唯一需要做的事情就是给模型一句文本提示(在 diffuser 模型里叫 prompt 提示)。下面我们尝试生成一幅『老虎和她的孩子在玩篮球』的画作:
# 给定文本提示和作画
# prompt = "A painting of a squirrel eating a banana"
# prompt = "A robot couple was sitting on the beach drinking"
prompt = "The tiger and her children are playing basketball"
images = ldm([prompt], num_inference_steps=50, eta=.3, guidance_scale=6)
print(images[0])
# 显示图像
images[0][0].show()
# 保存图像到本地
images[0][0].save("demo2.png")完整代码如下:
from diffusers import DiffusionPipeline
model_id = "CompVis/ldm-text2im-large-256"
# 预训练模型
ldm = DiffusionPipeline.from_pretrained(model_id)
# 给定文本提示和作画
# prompt = "A painting of a squirrel eating a banana"
# prompt = "A robot couple was sitting on the beach drinking"
prompt = "The tiger and her children are playing basketball"
images = ldm([prompt], num_inference_steps=50, eta=.3, guidance_scale=6)
print(images[0])
images[0][0].show()
images[0][0].save("demo2.png")注意:首次运行需要下载模型文件,大约5G左右,预计个把小时,下载的时候确保网络不能断,否则下载中断失败。如遇加载模型失败,多尝试几次。
下载完成后,程序运行需要约10分钟左右生成一张图片,慢的离谱qaq……配置太差,配置好可能稍微快一点。
生成图像结果:


上面就是模型最终生成的图像,当然受限于我们的计算资源和预训练模型大小,我们生成的图像不像 DALL-E 2 那样令人惊艳,但是我们仅仅用几行代码也生成了一副和提示文本匹配的图像,还是很让人感觉神奇。
国内大厂都有相应的文本生成图像体验平台,大家可以去感受一下,整体还可以。但国内的一般大厂还有小程序基本都未开源或者需要收费,使用人多还需要排队。
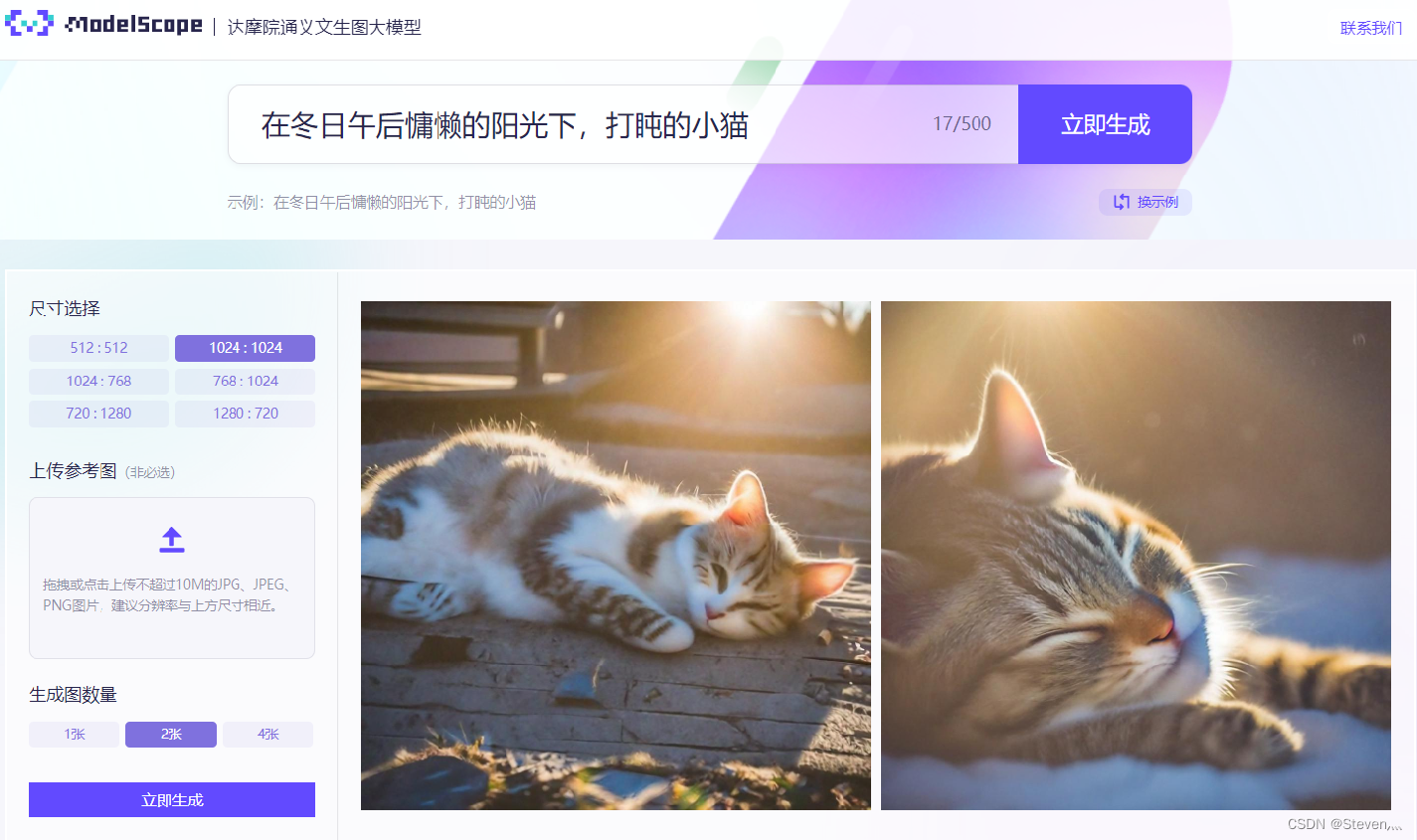
达摩院在线体验平台:
达摩院通义文生图大模型:达摩院通义文生图大模型
生成完成大概需要30s左右。
百度文生图体验平台
百度的文心一格:文心一格 - AI艺术和创意辅助平台
参考链接:
Hugging Face发布diffuser模型AI绘画库初尝鲜! - 掘金
国内外Ai绘画软件汇总