文章目录
- 接口的注意事项
- 获取对象的属性或方法,先 判断对象是否为空!
- 修改老接口,思考接口的兼容性
- 重点接口,考虑线程池隔离
- 调用第三方接口考虑超时、重试
- 接口的熔断、降级
- 接口,需要考虑限流
- 接口要打印好日志
- 接口考虑热点数据隔离性
- 多线程情况下,考虑线程安全问题
- 考虑接口的幂等性
- 接口要考虑异常处理
- 优化接口
- guava工具包
- 考虑使用文件 / MQ等其他方式暂存数据,异步再落地DB
- mysql优化
- 优化索引
- 选错索引
- 查询数据库由单线程改成多线程(异步处理)
- 分批调用接口、批量查询数据
- 数据量比较大,批量操作数据入库
- 压缩
- 并行处理数据
- 并行调用
- 集群横向扩容,分摊每台服务器的请求量
- 减少接口中的业务,非核心业务异步执行
- 预取数据
- 接口安全以及参数校验
- 注意大文件、大事务、大对象
- 分页处理
- 同步调用
- 异步调用
- 使用缓存
- 设计模式优化代码
- 优化专栏
接口的注意事项
获取对象的属性或方法,先 判断对象是否为空!
if (list != null) {
list.size();
}
修改老接口,思考接口的兼容性
// 老接口
void oldService(A, B) {
// 兼容新接口,穿个null 代替C
newService(A, B, null);
}
//新接口,暂时不能删除老接口,需要做兼容
void newService(A, B, C) {
}
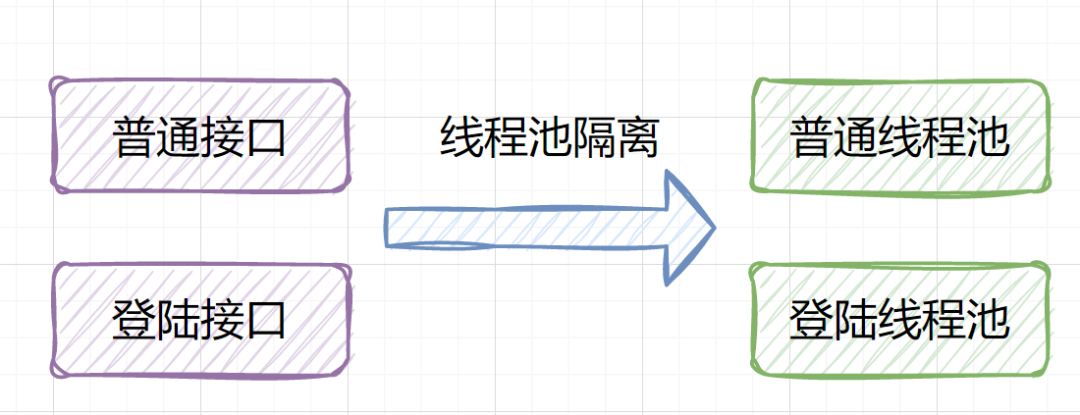
重点接口,考虑线程池隔离
一些登陆、转账交易、下单等重要接口,
考虑线程池隔离哈。如果你所有业务都共用一个线程池,有些业务出bug导致线程池阻塞打满的话,那就杯具了,所有业务都影响
调用第三方接口考虑超时、重试
接口超时
没法 预估对方接口一般多久返回,一般设置个超时断开时间,以保护你的接口。之前 见过一个生产问题,就是http调用不设置超时时间,最后响应方进程假死,请求一直占着 线程不释放,拖垮线程池
重试次数
优雅实现接口重试
你的
接口调失败,需不需要重试?重试几次?接口的幂等性处理?需要站在业务上角度思考这个问题
接口的熔断、降级
Hystrix 请求合并、请求隔离、优化
优化
分布式系统中经常会出现某个
基础服务不可用,最终导致整个系统不可用的情况, 这种现象被称为服务雪崩效应
熔断和降级。最简单是加开关控制,当下游系统出问题时,开关降级,不再调用下游系统。还可以选用开源组件Hystrix
接口,需要考虑限流
高并发接口限流
Redis+Lua的分布式限流
sentinel限流
接口要打印好日志
打印日志注意事项
开始、结束、入参、异常
public void transfer(TransferDTO transferDTO) {
log.debug("transfer begin");
//打印入参,
log.debug("transfer,parameters:{}", transferDTO);
try {
res = transferDTO.transfer(transferDTO);
} catch (Exception e) {
log.error("transfer fail,account:{}", transferDTO.getAccount());
log.error("transfer fail,exception:{}", e);
}
log.debug("transfer end ");
}
接口考虑热点数据隔离性
瞬时间的高并发,可能会打垮你的系统。可以做一些热点数据的隔离。比如业务隔离、系统隔离、用户隔离、数据隔离等。
- 业务隔离性,比如12306的
分时段售票,将 热点数据分散处理,降低 系统负载压力。 - 系统隔离:比如把系统分成了
用户、商品、社区三个板块。这三个块分别使用不同的域名、服务器和数据库,做到从接入层到应用层再到数据层三层完全隔离。 - 用户隔离:重点用户请求 到配置更好的机器。
- 数据隔离:使用单独的缓存集群或者数据库服务热点数据。
多线程情况下,考虑线程安全问题
高并发场景下,不能 使用HashMap会造成 死循环,可以使用ConcurrentHashMap 代替
HashMap、List、LinkedList、TreeMap都是线程不安全的
考虑接口的幂等性
查询类的请求,其实不用防重
转账类接口,并发不高的话,推荐使用数据库防重表,以唯一流水号作为主键或者唯一索引
接口幂等设计
接口要考虑异常处理
SpringBoot封装响应数据和异常处理
- 不用
e.printStackTrace(),而是使用log 打印出来 - catch 住异常时,建议打印出具体的 exception,方便定位
- 用finally块关闭资源或者 ·try-with-resource·–>实现AutoCloseable接口的 流可以自动关闭
- 优先捕获具体的异常
- 不要用一个Exception 捕捉所有的异常
- 尽量
减少try....catch的使用 - 运行时异常RuntimeException ,
不应该通过catch的方式来处理,而是先预检查,比如:NullPointerException处理
优化接口
guava工具包
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
考虑使用文件 / MQ等其他方式暂存数据,异步再落地DB
MQ专栏
如果数据太大,落地数据库实在是慢的话,可以考虑先用文件的方式保存,或者考虑MQ,先落地,再异步保存到数据库~
本次转账接口,如果是并发开启,10个并发度,每个批次1000笔数据,数据库插入会特别耗时,大概10秒左右,这个跟我们公司的数据库同步机制有关,并发情况下,因为优先保证同步,所以并行的插入变成串行啦,就很耗时
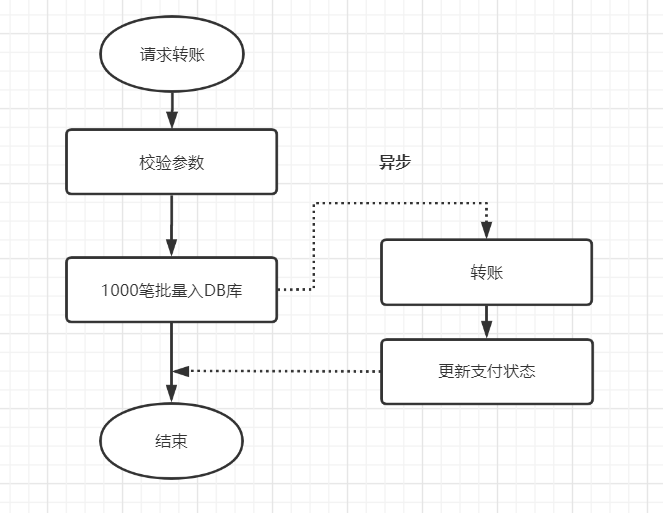
优化前:
优化前,1000笔先落地DB数据库,再异步转账,如下:
优化后:
先保存数据到文件,再异步下载下来,插入数据库,如下:
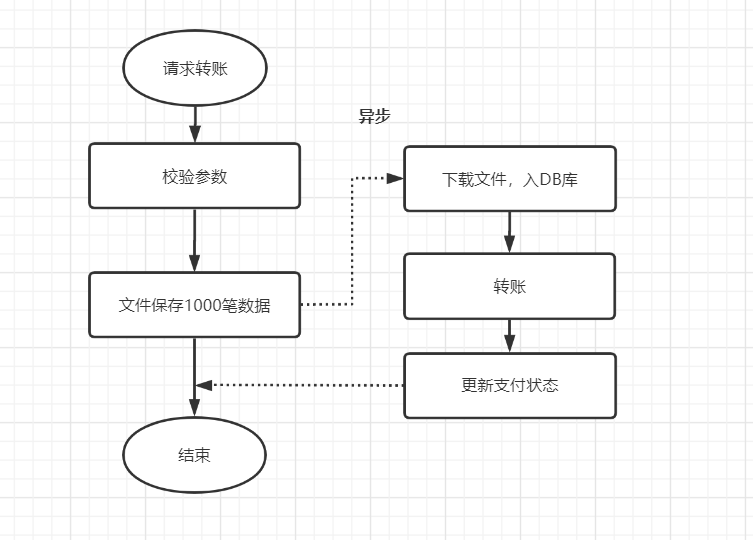
解析:
如果你的耗时瓶颈就在数据库插入操作这里了,那就 考虑文件保存或者MQ或者其他方式暂存吧,文件保存数据,对比一下耗时,有时候会有意想不到的效果哦。
mysql优化
mysql专栏
优化索引
单列索引可以 使用联合索引进行优化
选错索引
为了防止选错索引,force index 来 强制查询sql走某个索引
查询数据库由单线程改成多线程(异步处理)
但由于 该接口 是要将查询出的所有数据,都返回回去的,所以要获取查询结果
使用多线程调用,并且要获取返回值,这种场景使用 java8 中
要使用线程池!!!!
CompleteFuture 非常合适
代码调整为:
ThreadPoolConfig线程池配置
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
import java.util.concurrent.ThreadPoolExecutor;
@Configuration
public class ThreadPoolConfig {
/**
* 核心线程数量,默认 1
*/
private int corePoolSize = 8;
/**
* 最大线程数量,默认 Integer.MAX_VALUE 约 21亿;
*/
private int maxPoolSize = 10;
/**
* 空闲线程 存活时间
*/
private int keepAliveSeconds = 60;
/**
* 线程阻塞 队列容量,默认 Integer.MAX_VALUE
*/
private int queueCapacity = 1;
/**
* 是否允许 核心线程超时
*/
private boolean allowCoreThreadTimeOut = false;
@Bean("asyncExecutor")
public Executor asyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveSeconds);
executor.setAllowCoreThreadTimeOut(allowCoreThreadTimeOut);
// 设置拒绝策略,直接在 execute 方法的调用线程中运行被拒绝的任务
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 执行初始化
executor.initialize();
return executor;
}
}
执行的代码
@Resource
private ThreadPoolTaskExecutor asyncExecutor;
public String handlerData(List<String> dataList) {
CompletableFuture[] futureArray = dataList.stream()
.map(data -> CompletableFuture
// query 查询数据库 和一些其他逻辑,使用 自定义的线程池
.supplyAsync(() -> query(data), asyncExecutor)
.whenComplete((result, th) -> {
}))
.toArray(CompletableFuture[]::new);
CompletableFuture.allOf(futureArray).join();
return "";
}
分批调用接口、批量查询数据
限制
一次性查询的记录条数
比如:查询 500条数据,之前是 一次性查询完成,现在是分5次查询,一次查询100条记录,可以使用多线程处理!!
数据量比较大,批量操作数据入库
优化前:
//for循环单笔入库
for(TransDetail detail:list){
insert(detail);
}
优化后:
// 批量入库,mybatis demo实现
<insert id="insertBatch" parameterType="java.util.List">
insert into trans_detail( id,amount,payer,payee) values
<foreach collection="list" item="item" index="index" separator=",">(
#{item.id}, #{item.amount},
#{item.payer},#{item.payee}
)
</foreach>
</insert>
压缩
Nginx专栏
Nginx 配置
server {
listen 80;
server_name localhost;
gzip on;
gzip_vary on;
gzip_buffers 32 4K;
gzip_min_length 1024;
gzip_proxied expired no-cache no-store private auth;
gzip_types text/plain text/css text/xml text/javascript application/xjavascript application/xml;
gzip_disable "MSIE [1-6]\.";
gzip_static on; #如果有压缩好的,直接使用
location / {
proxy_pass http://127.0.0.1:8080;
}
}
开启
服务端配置:
server:
port: 8888
compression:
enabled: true
min-response-size: 1024
mime-types: [ "text/html","text/xml","application/xml","application/json","application/octet-stream" ]
开启
客户端配置:
feign:
okhttp:
enabled: true
httpclient:
enabled: false
并行处理数据
CompletableFuture优化代码
我们可以 把 这个接口,拆分成 顺序执行的两部分,在 某个部分都 可以并行的获取数据。
那就按照这种分析结果改造试试吧,使用 concurrent 包里的 CountDownLatch,
实现了
并取功能
CountDownLatch latch = new CountDownLatch(jobSize);
//submit job
executor.execute(() -> {
//job code,countDown方法 让计数器 -1
latch.countDown();
});
executor.execute(() -> {
latch.countDown();
});
...
//end submit,让主线程等待
latch.await(timeout, TimeUnit.MILLISECONDS);
结果非常让人满意,我们的接口耗时,又减少了接近一半!此时,接口耗时已经降低到 2 秒以下。
并发编程一定要小心,尤其是在业务代码中的并发编程。我们构造了专用的线程池,来支撑这个并发获取的功能。
final ThreadPoolExecutor executor = new ThreadPoolExecutor(
100,
200,
1,
TimeUnit.HOURS,
new ArrayBlockingQueue<>(100));
并行调用
上面说到,既然串行调用多个远程接口性能很差,为什么不改成并行呢?
如下图所示:
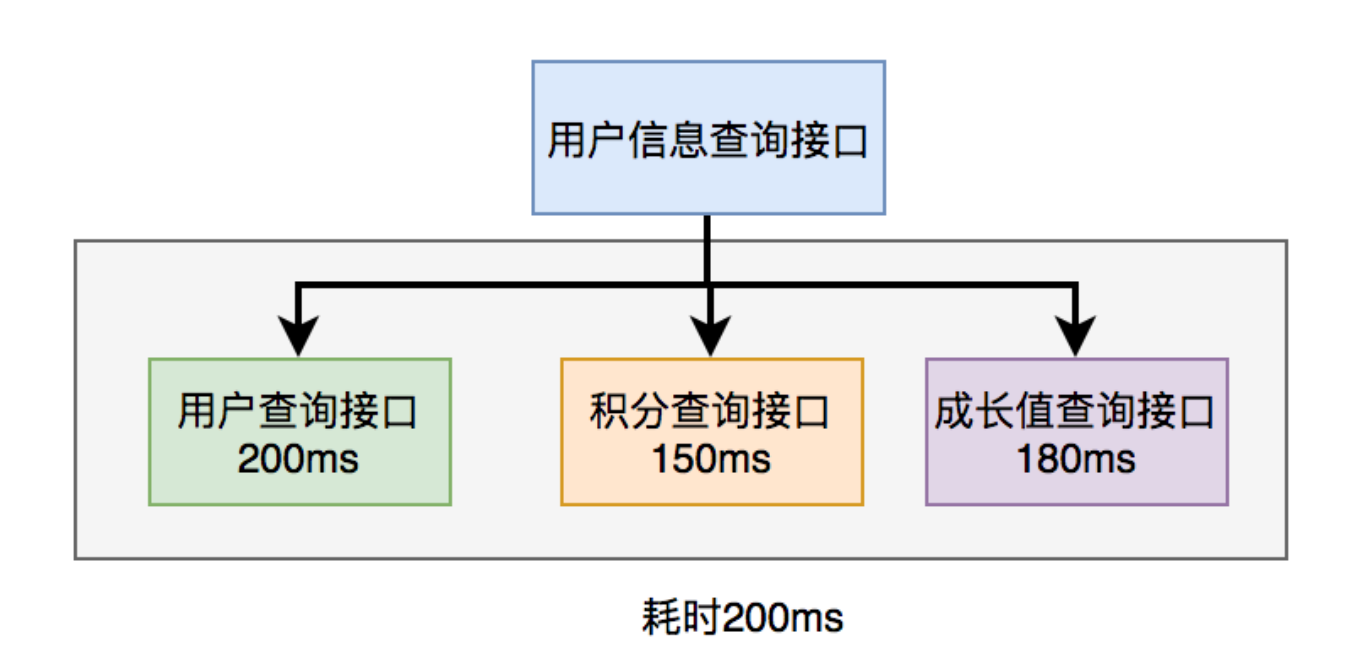
调用远程接口总耗时 200ms = 200ms(即 耗时最长的那次远程接口调用)
在 java8 之前可以通过实现 Callable 接口,获取线程返回结果。
java8 以后通 过 CompleteFuture 类实现该功能
CompleteFuture为例:
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo ();
CompletableFuture userFuture = CompletableFuture.supplyAsync (() -> {
getRemoteUserAndFill (id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync (() -> {
getRemoteBonusAndFill (id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture growthFuture = CompletableFuture.supplyAsync (() -> {
getRemoteGrowthAndFill (id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf (userFuture, bonusFuture, growthFuture).join ();
userFuture.get ();
bonusFuture.get ();
growthFuture.get ();
return userInfo;
}
温馨提醒:这两种方式
别忘了使用线程池。示例中我用到了 executor,表示自定义的线程池,为了防止高并发场景下,出现线程过多的问题
集群横向扩容,分摊每台服务器的请求量
减少接口中的业务,非核心业务异步执行
预取数据
在哪些实际场景会用呢?
- 视频或直播类网站
播放前 先缓冲一小段时间, 是预取数据。有的在播放时不仅预取这一条数据,甚至还会预测下一个要看的其他内容,提前把数据取到本地;
- 热点资源 提前预分配到各个实例
比如:秒杀、售票的库存性质的数据;分布式唯一 ID 等
接口安全以及参数校验
接口不对外暴露,仅内部使用
接口安全
入参是否为空,长度符合预期,范围符合预期
入参 出参校验是每个程序员必备的基本素养。你设计的接口,必须先校验参数。比如入参是否允许为空,入参长度是否符合你的预期长度
比如你的数据库表字段设置为
varchar(16),对方传了一个32位的字符串过来,如果你不校验参数,插入数据库直接异常
出参也是,比如你定义的接口报文,参数是不为空的,但是你的接口返回参数,没有做校验,因为程序某些原因,直返回别人一个null值
参数校验
注意大文件、大事务、大对象
- 读取大文件时,
不要Files.readAllBytes直接读取到内存,这样会OOM的,建议使用BufferedReader一行一行来。 - 大事务可能
导致死锁、回滚时间长、主从延迟等问题,开发中尽量避免大事务。 - 注意一些
大对象的使用,因为大对象是直接进入老年代的,可能会触发fullGC
大事务引发的问题
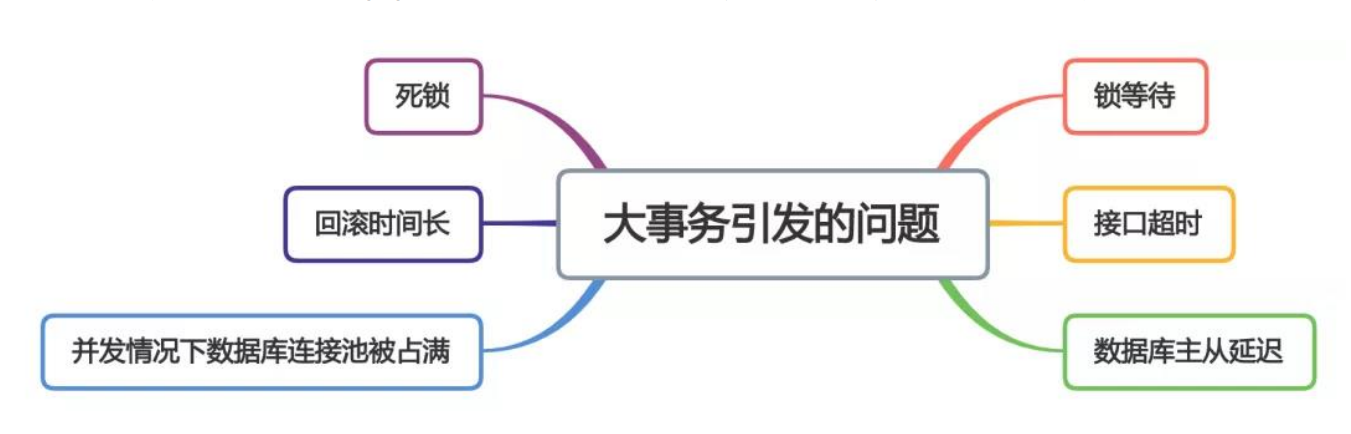
事务回调编程,在事务提交后 执行代码,可以优化代码逻辑
事务回调编程
我们该
如何优化大事务呢?
- 少用@Transactional 注解
- 将查询(select)方法放到事务外
- 事务中避免远程调用
- 事务中避免一次性处理太多数据
- 有些功能可以非事务执行
- 有些功能可以异步处理
分页处理
比如:通过用户 id 批量查询出用户信息,然后给这些用户送积分
但如果你一次性查询的用户数量太多了,比如一次查询 2000 个用户的数据。参数中传入了 2000 个用户的 id,远程调用接口,会发现该用户
查询接口经常超时
同步调用
具体示例代码如下:
// guava工具类
List<List<Long>> allIds = Lists.partition (ids, 200);
for (List<Long> batchIds : allIds) {
List<User> users = remoteCallUser (batchIds);
}
代码中我用的 google 的 guava 工具中的 Lists.partition() 方法,用它来做分页
异步调用
除了需要考虑远程调用接口的耗时之外,还需要考虑该接口本身的总耗时,也不能超时 500ms
List<List<Long>> allIds = Lists.partition (ids, 200);
final List<User> result = Lists.newArrayList ();
allIds.stream ().forEach ((batchIds) -> {
CompletableFuture.supplyAsync (() -> {
result.addAll (remoteCallUser (batchIds));
return Boolean.TRUE;
}, executor);
});
使用 CompletableFuture 类,多个线程异步调用远程接口,最后汇总结果统一返回
使用缓存
哪些场景适合使用缓存?读多写少 且 数据时效要求越低的场景
redis专栏
Redis+Caffeine两级缓存,让访问速度纵享丝滑!
设计模式优化代码
设计模式专栏
优化专栏
优化专栏



![[附源码]java毕业设计养老院管理系统](https://img-blog.csdnimg.cn/b69d6fffdcd5404ab81c3ef14f73c569.png)