目录
前言
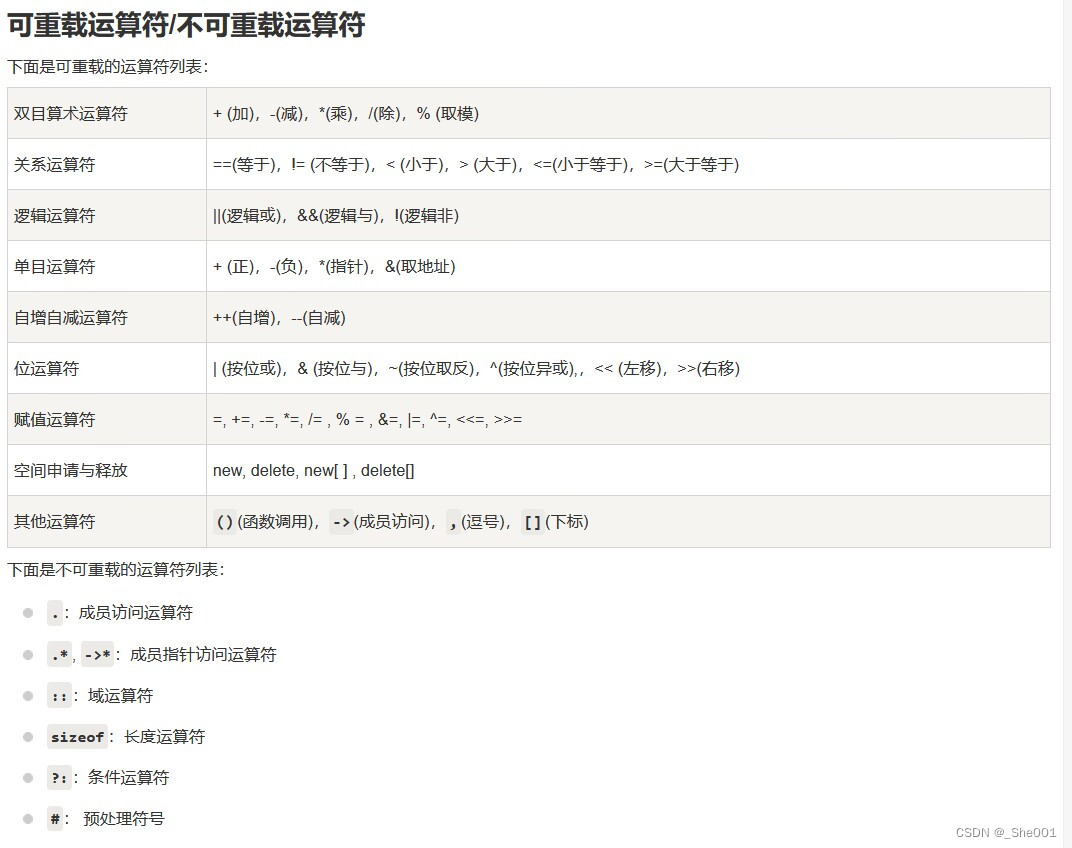
1. InnoDB常见的索引
2. B+树索引
2.1 二分查找法
2.2 二叉查找树
2.3 平衡二叉树
2.4 B树索引
2.5 B+树索引
2.5.1 聚集索引
2.5.2 非聚集索引
2.5.3 聚集索引与非聚集索引区别
前言
索引的本质是让mysql以最高效、扫描行数最少的方式找到需要的数据。索引作用很大,但是也不索引越多,查询性能就越高。同样索引太少,也不行。所以如何给应用程序创建合适的索引至关重要。我认为最好的方式,是根据业务发展的需要,可以动态的对创建索引进行调整。如业务初期数据量不多的时候,可以先不建索引,待业务增速比较快的时候,对查询的需求增多的时候,可以根据具体的业务场景的数据流进行创建或者调整。当然,如果可以提交预判业务上的查询需求,可以在初期的时候把索引创建好。创建合适的索引也是非常有技术含量的。
1. InnoDB常见的索引
B+树索引、全文索引、哈希索引
2. B+树索引
B+树索引的结构类似于二叉树,可以根据键值快速的找到数据。这里需要注意的是,B+树索引实际找到并不是具体的行,而被查找数据行所在的页,然后把页读取到内存中,再在内存中查询与查询条件匹配的数据,最后返回。为了更好的理解B+树的结构和算法,先熟悉一下与B+树结构类似的二叉树和二分查询法
2.1 二分查找法
二分查找法的基本思想是:
1、将记录按有序化(升序或降序)排列;
2、以排好序列的中点位置为比较对象,如果要查找的元素小于该中点元素,则待查找的序列范围可以缩小到左半部分,否则为右半部分。
3、通过一次比较,查找范围可以缩小一半,以此类推,直到找到结果。
2.2 二叉查找树
二叉树规则:左子树的键值总是小于根节点的键值,右子树的键值总是大于根节点的键值。
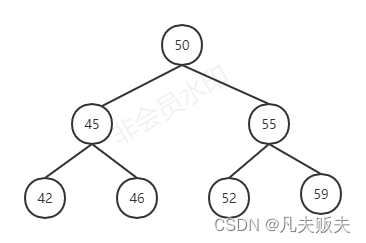
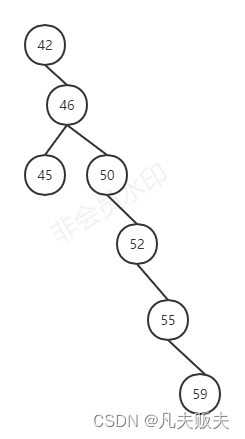
二叉树的定义规则比较简单,查询的思想就是二分查找法,有些情况下查找效率比较高,如图下:树的高度比较平衡、低,有些情况下会变成顺序查找,效率就不高了,如图二:根限情况下,二叉查找树变成了一个单向链表了。
2.3 平衡二叉树
为了解决二叉查找树在某些情况下查找效率低的问题,平衡二叉树出现了。平衡二叉树的定义规则除了要满足基本二叉树的定义规则外,还必须满足任何节点的两个子树的高度最大差为1。上图一,是满足平衡二叉树的定义,图二就不满足。平衡二叉树的查找速度的确很快,不过维护平衡二叉树的代价也是比较大的,即当树增加或减少节点的时候,需要通过左旋或右旋操作,来调整树的树结构,使其继续保持平衡。
2.4 B树索引
mysql的InnoDB存储引擎早期的索引结构是B树,其本质就是平衡二叉树。
上一篇文章已经分享过msyql的InnoDB存储引擎的逻辑存储结构分别是由表空间、段、区、页、行组成,页是InnoDB存储引擎磁盘管理的最小单位。B树索引的结构如下图,节点的基本单位是页,叶子节点中存入的行数据,非叶子节点存储的是索引键和指针,根节点、非叶子节点、叶子节点之间以指针相连。
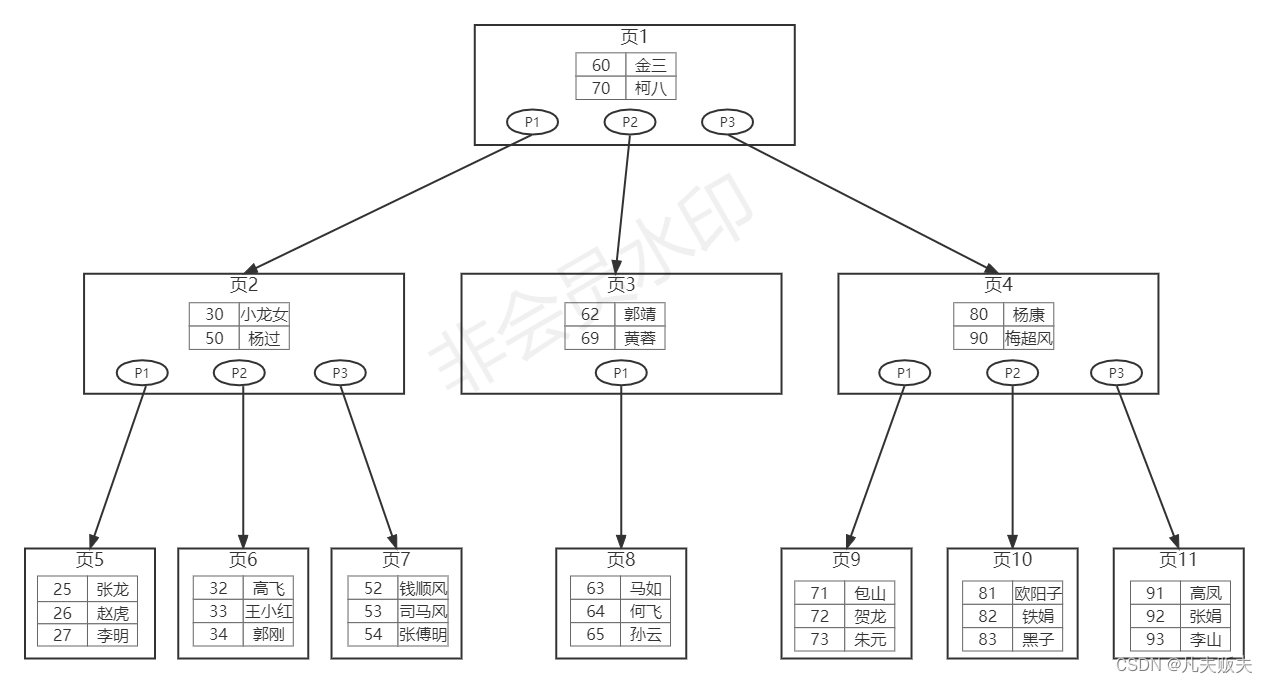
假如我要查找id=33的王小红,那么其查询流程是这样的:
1、先找到根节点,也就是页1,这里特别说明一下,mysql的B树索引的根节点一般会提前缓存到内存中,比较发现33小于60,那么根据页1中的指针p1找到了页2;
2、找到页2后,与页2中的键值比较后,发现33在30与50之间,那么根据页2中的指针p2找到页6;
3、页6已经是叶子节点了,把页6中数据读取到内存中,然后匹配到id=33的王小红,最后返回。
2.5 B+树索引
B+树的实质是B树的进一步优化,再来看一下B+树的结构图:

与B树不的点:
1、非叶子节点是不存储数据的,仅存键值,B树的非叶子节点不仅有键值,还会存储数据。
2、叶子节点与非叶子节点之间通过双向链表相连。
小结一下,我们可以得到一个结论:
1、B树和B+树索引的根节点是缓存到内存中,每向下查找一次都要进行一次磁盘读取 ,那如果树的高度越低,读取磁盘的次数就越少,查询性能就越高。
2、B树和B+树索引的结构是平衡二叉树,为了保持树的平衡性,每次对表的增、删、改操作都需要对索引结构进行分裂调整,如果索引列建的很多,那么分裂调整索引占用的资源就越多,数据库的整体性能就会下降,这下明白为啥索引不一定越多越好了吧。
3、页是mysql的InnoDB存储引擎最小的磁盘管理单位,其大小是固定的,默认是16k,如果有限的页空间里存储是键值,而不是数据,那么页中就会存储更大键值范围,那么树的高度就会更低,读取磁盘的次数更少,查询性能也就更高,所以B+树索引要优于B树。
4、B+树的叶子节点存储的是数据,且叶子节点之间是双向链表相连,数据内部是单向链表,那么B+树索引的列在范围查询、排序更有优势。(索引从结构上分有B+树索引、全文索引、哈希索引,使用的时候应该根据实际场景选择,而不是瞎建。)
2.5.1 聚集索引
其实B+树还可以细分,表按主键构造一颗B+树索引,那这样的索引就称为聚集索引。通常情况下,每张表都会建一个自增主键,那么这个id就是键值,叶子节点上与键值相对应的就是数据行。
2.5.2 非聚集索引
按非主键列构建的B+树索引,就是非聚集索引。
2.5.3 聚集索引与非聚集索引区别
1、根本区别在于聚集索引的叶子节点存储有键值和数据行,非聚集索引的叶子节点存储的是键值和指向聚集索引的指针。
2、通过聚集索引查询数据的时候,在叶子节点匹配到数据后就可以直接返回了;通过非聚集索引列查询数据的时候,在叶子节点匹配到的不是数据行,而是指向聚集索引的指标,所以需要再根据指针再去取实际的数据,通常这个动作叫回表查询。(现在明白为啥有人反复说,表一定要有一个主键了吧)

![[附源码]java毕业设计养老院管理系统](https://img-blog.csdnimg.cn/b69d6fffdcd5404ab81c3ef14f73c569.png)