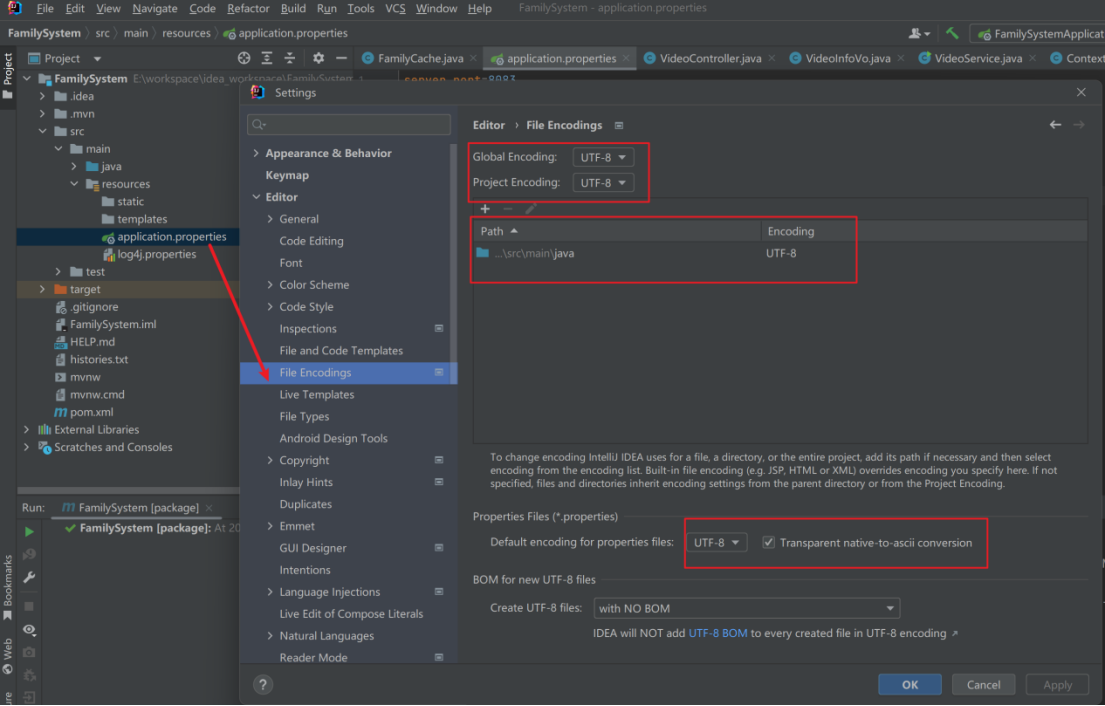
Flink 处理机制的核心,就是“有状态的流式计算”。在流处理中,数据是连续不断到来和处理的。每个任务进行计算处理时,可以基于当前数据直接转换得到输出结果;也可以依赖一些其他数据。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态。(聚合算子、窗口算子都属于有状态的算子)
- 算子任务接收到上游发来的数据;
- 获取当前状态;
- 根据业务逻辑进行计算,更新状态;
- 得到计算结果,输出发送到下游任务;
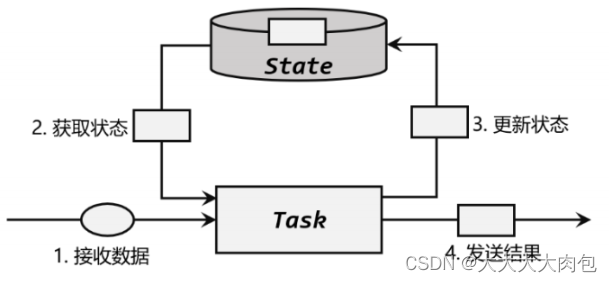
算子状态(Operator State)
状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个“分区”,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的。算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别——因为本地变量的作用域也是当前任务实例。
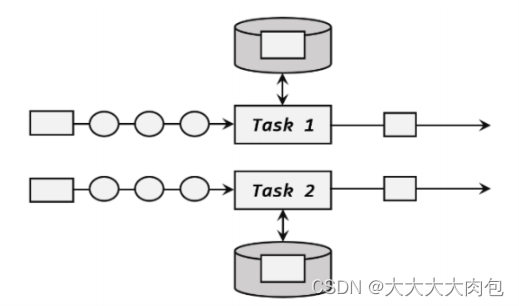
按键分区状态(Keyed State)
状态是根据输入流中定义的键(key)来维护和访问的,相当于用key来进行物理隔离,所以只能定义在按键分区流(KeyedStream)中,也就 keyBy 之后才可以使用。
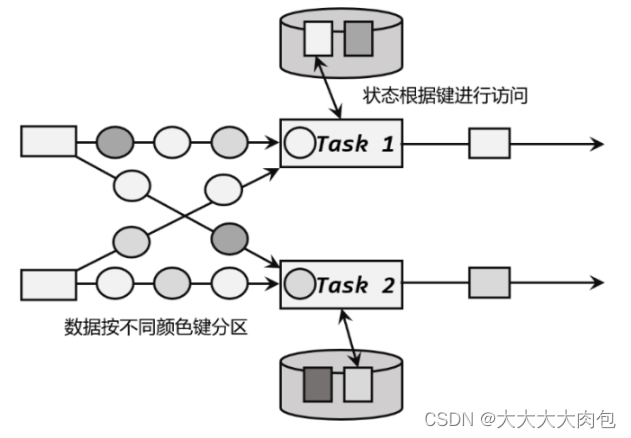
不同 key 对应的 Keyed State可以进一步组成所谓的键组(key groups),每一组都对应着一个并行子任务。键组是 Flink 重新分配 Keyed State 的单元,键组的数量就等于定义的最大并行度。当算子并行度发生改变时,Keyed State 就会按照当前的并行度重新平均分配,保证运行时各个子任务的负载相同。
支持的结构类型
1. 值状态(ValueState)
顾名思义,状态中只保存一个“值”(value)。ValueState<T>本身是一个接口。
2. 列表状态(ListState)
将需要保存的数据,以列表(List)的形式组织起来。在 ListState<T>接口中同样有一个类型参数 T,表示列表中数据的类型。ListState 也提供了一系列的方法来操作状态,使用方式与一般的 List 非常相似。
3. 映射状态(MapState)
把一些键值对(key-value)作为状态整体保存起来,可以认为就是一组 key-value 映射的列表。对应的 MapState<UK, UV>接口中,就会有 UK、UV 两个泛型,分别表示保存的 key和 value 的型。 同样,MapState 提供了操作映射状态的方法,与 Map 的使用非常类似。
4. 归约状态(ReducingState)
类似于值状态(Value),不过需要对添加进来的所有数据进行归约,将归约聚合之后的值作为状态保存下来。ReducintState<T>这个接口调用的方法类似于 ListState,只不过它保存的只是一个聚合值,所以调用.add()方法时,不是在状态列表里添加元素,而是直接把新数据和之前的状态进行归约,并用得到的结果更新状态。
归约逻辑的定义,是在归约状态描述器(ReducingStateDescriptor)中,通过传入一个归约函数(ReduceFunction)来实现的。这里的归约函数,就是我们之前介绍 reduce 聚合算子时讲到的 ReduceFunction,所以状态类型跟输入的数据类型是一样的。
5. 聚合状态(AggregatingState)
与归约状态非常类似,聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。
与 ReducingState 不同的是,它的聚合逻辑是由在描述器中传入一个更加一般化的聚合函数
(AggregateFunction)来定义的;这也就是之前我们讲过的 AggregateFunction,里面通过一个
累加器(Accumulator)来表示状态,所以聚合的状态类型可以跟添加进来的数据类型完全不
同,使用更加灵活。
同样地,AggregatingState 接口调用方法也与 ReducingState 相同,调用.add()方法添加元素
时,会直接使用指定的 AggregateFunction 进行聚合并更新状态。