(声明:本文章是在学习他人视频的学习笔记,图片出处均来自该up主,侵权删 up主链接:同济子豪兄的个人空间_哔哩哔哩_bilibili)
卷积神经网络就像一个黑箱,有输入和输出,输入是一个图像阵列也就是一个图片,输出就是这个图片是啥
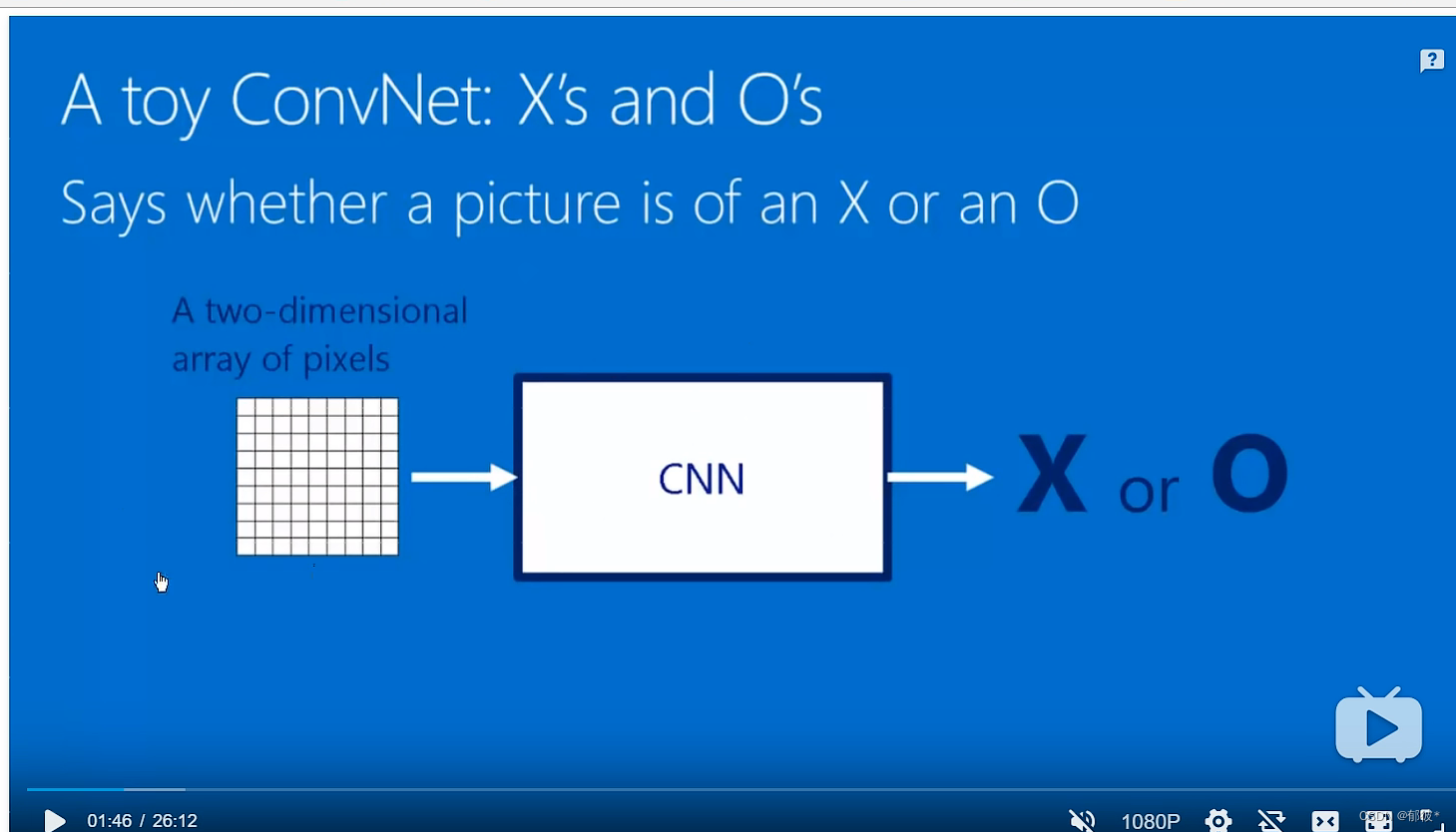
比如说图片是一个X那么它就输出一个X,O就输出一个O
 就算这个图片经过一些变换,它的结果仍然不变,并不会被误导也就是它的鲁棒性和抗干扰能力比较强
就算这个图片经过一些变换,它的结果仍然不变,并不会被误导也就是它的鲁棒性和抗干扰能力比较强

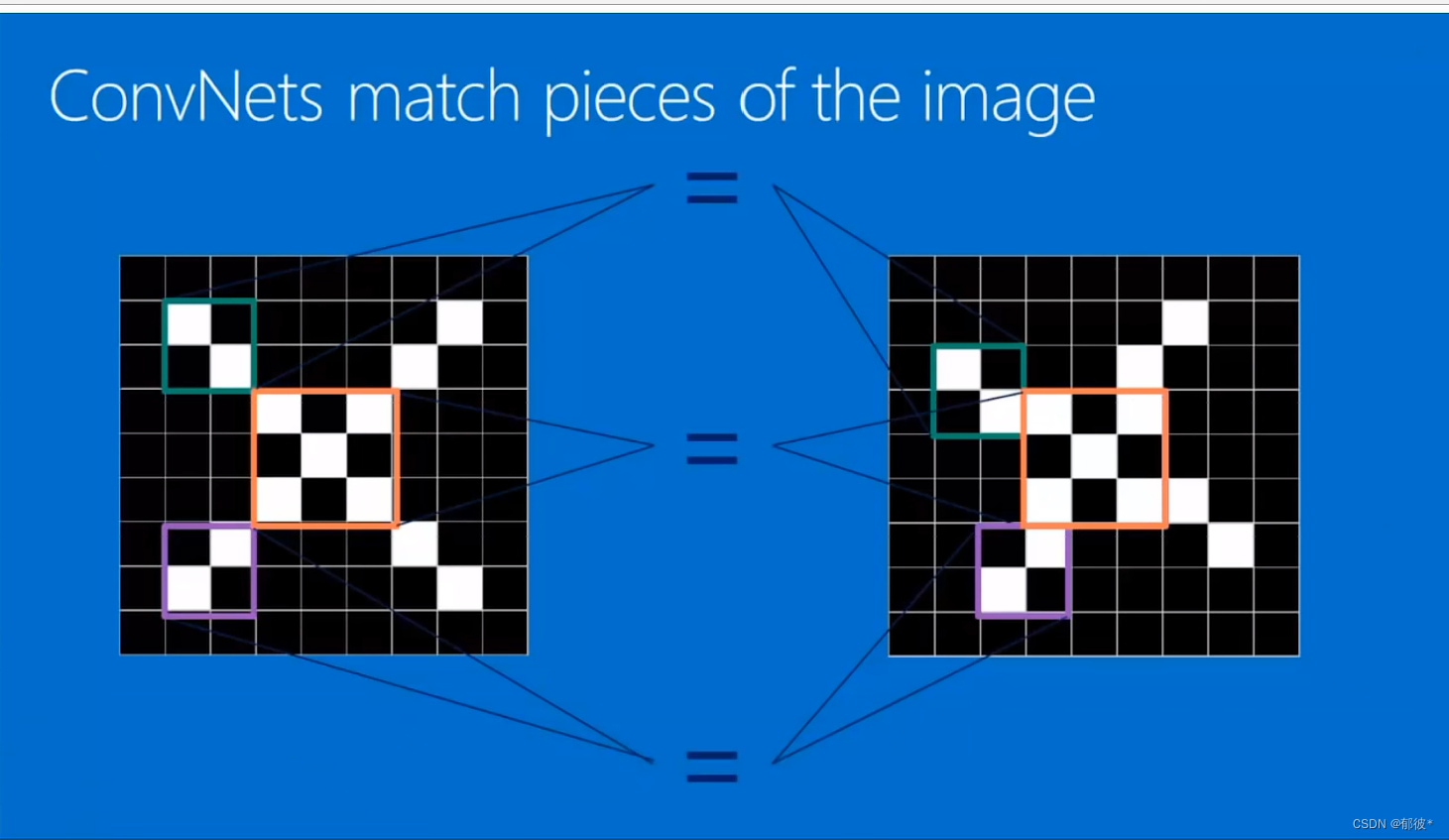
对于计算机来说要识别一些变换的图像是非常难的

但是我们可以通过识别这些不变的关键点来识别变换后的图形,识别出它与原图的相似性
 那么卷积神经网络是怎么运算的呢?
那么卷积神经网络是怎么运算的呢?
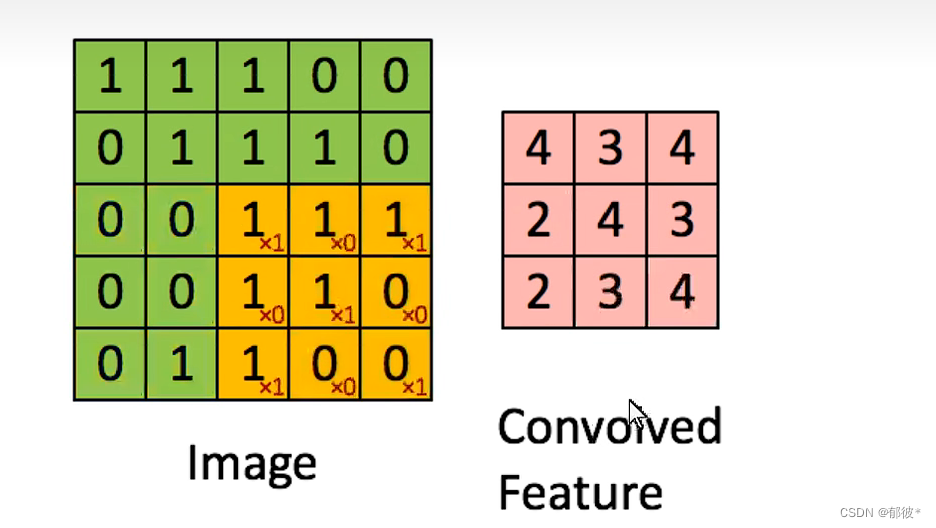
绿色区域为图片像素矩阵,CNN将黄色区域的值算出来并记录在粉色区域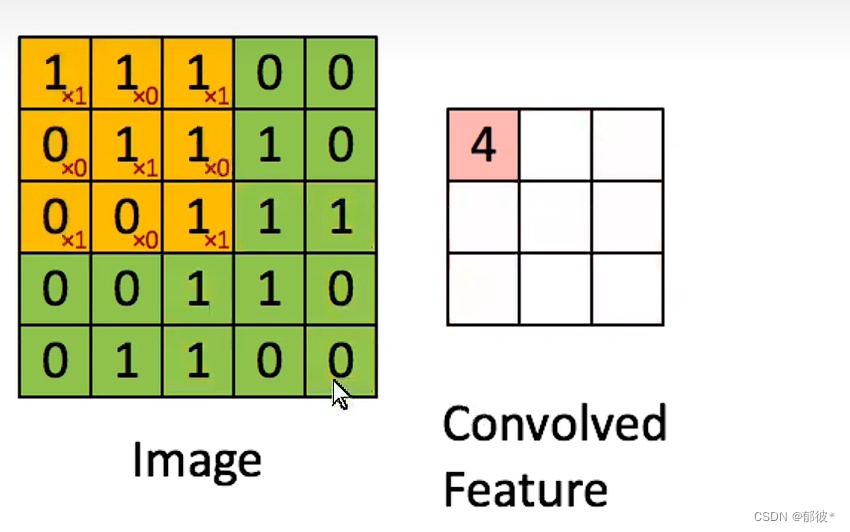
直到算到最后一个区域
将X图像与它的三个特征作卷积运算就会得到旁边这三个特征图(feature map),仔细看你会发现这三个feature map会与他们做卷积的特征图相似,说明X图像中含有这三个特征,但如果你用O的图像与这三个特征图做卷积运算得出来的feature map就不会与原来的特征图相似,是一个乱码图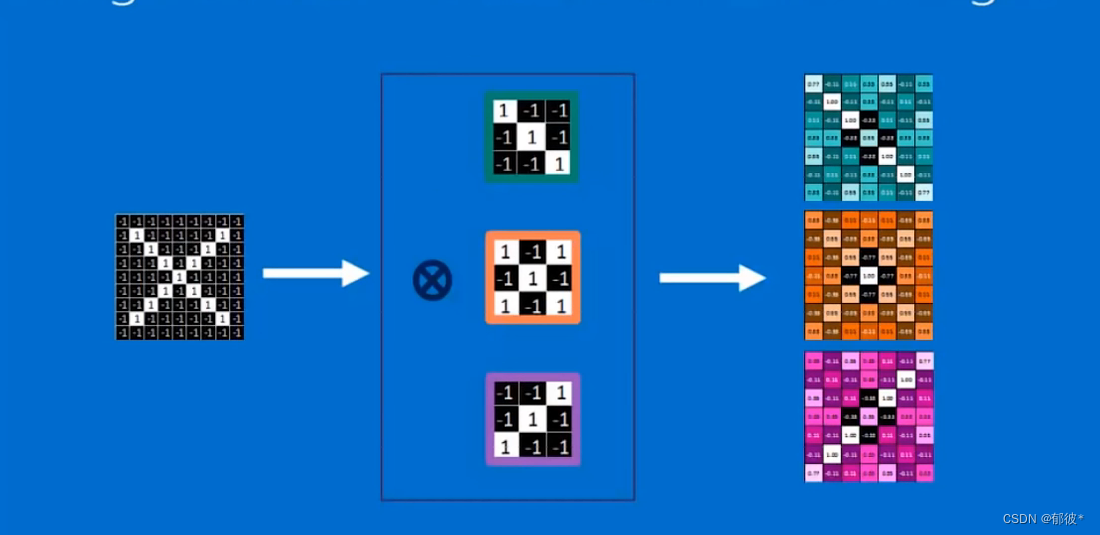
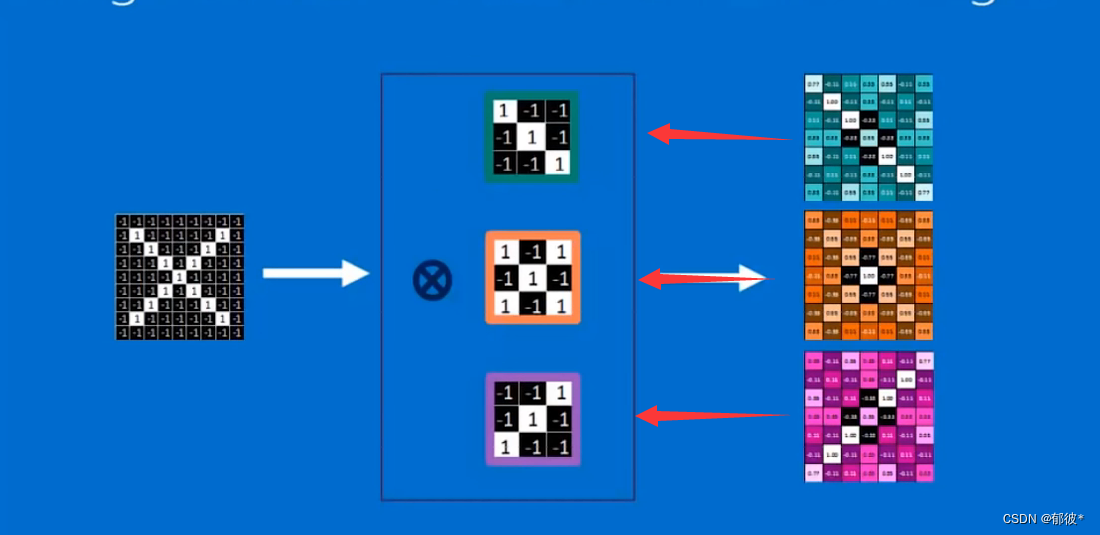
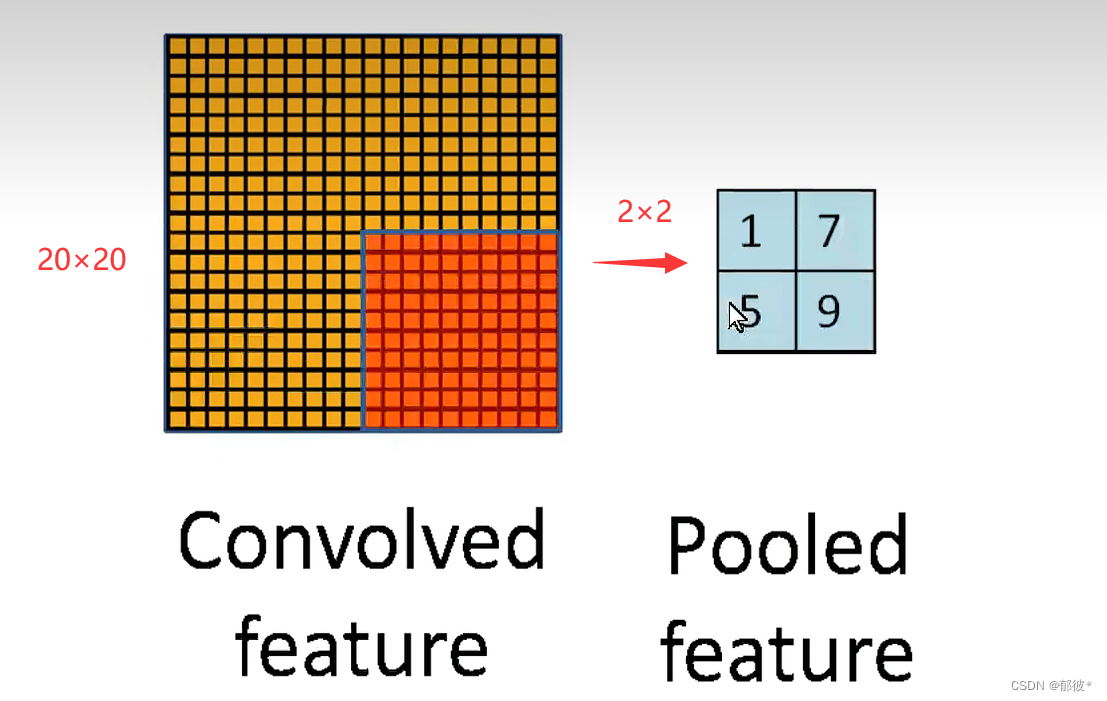
但在实践运用中需要检测的特征点太多了,每个都作卷积运算的话,这个运算量是非常非常大的,因此我们需要对图像进行压缩,即进行池化(pooling)
如图就是池化,将原来20×20的图像变为2×2的图像 ,这样做注定会丢失一部分数据,但这是在我们可接受的范围内的
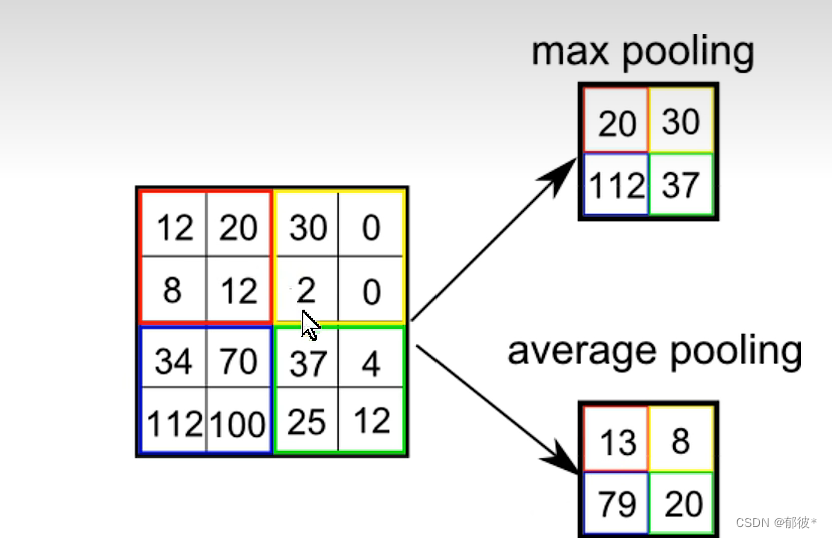
池化分为两种:一种是最大值池化(将区域内的最大值来代替这个区域的所有值),另外一种是平均值池化(将区域内的所有数的平均值来代表这个区别的所有值)
在进行最大值池化后,可以发现这个feature map仍然保留了对角线的特征
ReLUs是对所有小于0的值取0 
我们反复的进行卷积、ReLUs、池化就可以得到一个很小的feature map
再把这些值进行全连接,就是feature map的每一个值拿出来排列
feature map的每一个数字都有它的权重,把数字乘以权重再加起来就可以得到是X的概率
 每一个像素的权重,最后算完得出X的概率为0.92
每一个像素的权重,最后算完得出X的概率为0.92