目录
1. 更加简单的存储对象
1.1 配置扫描路径
1.2 使用五大类注解存储 bean 对象
1.2.1 五大类注解之间的关系
1.2.2 关于 bean 的命名规则
1.3 使用方法注解存储 bean 对象
1.3.1 bean 的重命名
2. 更加简单的获取对象 (DI)
2.1 属性注入
2.1.1 属性注入优缺点分析
2.2 Setter 注入
2.2.1 Setter 注入优缺点分析
2.3 构造方法注入
2.3.1 构造方法注入优点分析
2.4 三种注入方式场景分析
1. 更加简单的存储对象
【前置工作】
首先我们要创建出一个 Spring 项目(具体操作见上一篇博客)
- 创建一个 Maven 项目【无需模板】
- 添加 Spring 依赖
- 创建一个启动类
上一篇博客中讲到的存储 bean 对象到 Spring 中主要就是两个步骤
- 创建一个 bean 对象
- 将 bean 以 Spring 配置文件的方式注册到 Spring 中
其中第一步是必不可少的, 此处可以优化第二步操作, 我们无须再通过加 <bean> 标签的方式进行存储 bean 对象了, 这样的方式去存储对象时, 一个对象需要加一个 bean 标签, 显得太麻烦, 太笨拙了.
1.1 配置扫描路径
我们需要通过注解的方式将 bean 对象存储在 Spring 中的前提是我们先要配置好扫描路径, Spring 在加载的时候, 就能针对性的去扫描这个路径下的哪些类加了五大类注解或者方法注解, 就会将这些对象存储在 bean 中.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:content="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<content:component-scan base-package="com.hl.controller"></content:component-scan>
</beans>这部分代码不需要背下来, 每次用到的时候只需要复制张贴即可, 可以保存在码云的代码片段中, 这样挺方便的. 这里的配置文件相比上一篇博客中的配置文件就多了下面这一行代码:
<content:component-scan base-package="com.hl.controller">
</content:component-scan>表示的意思是当 Spring 在加载的时候, 会去这个路径下去扫描有没有加了五大类注解/方法注解的类, 如果有就将其存储在 Spring 中.
【为什么要配置扫描路径?】
如果不配置扫描路径的话, 就有两种做法, 一种是还是使用原来的 <bean> 标签, 但是又过于麻烦; 另一种就是扫描全部的类, 这种做法不太科学, 如果我的项目非常大的话, 底下的类可能成千上万个, 那么 Spring 在加载的时候速度就会非常的慢. 而配置了扫描路径, 假设我有一百个类需要存储在 Spring 中, 那么我要扫描的路径例如: com.hl.controller下面可能也就一百多个类, 这样就能提高效率.
1.2 使用五大类注解存储 bean 对象
通过注解的方式存储对象有两种类型:
1. 使用类注解(五大类注解)
- @Controller【控制器】
- @Service【服务】
- @Repository【仓库】
- @Component【组件】
- @Configuration【配置】
2. 使用方法注解: @Bean
以 @Controller 为例, 其他四个类注解的使用方式都是一样的.
a. 在 com.hl.controller 包下创建一个 Controller 类, 并在类的顶端加上一个 @Controller 注解
@Controller
public class UserController {
public void doUserController() {
System.out.println("do user controller!");
}
}
当我们在类上面加上五大类注解之一时, 前面配置好的 Spring-config.xml 就能扫描到这个路径下的这个类, 并将其存储在 Spring 中. (扫描路径至少写一个包名, 例如 com , 否则运行时会报错).
b. 然后在启动类中还是以原来的方式去使用 bean:
- 得到 Spring 上下文
- 获取 bean 对象
- 使用 bean 对象
public class App {
public static void main(String[] args) {
// 1. 得到 Spring 上下文
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2. 获取 bean 对象
UserController userController =
context.getBean("userController", UserController.class);
// 3. 使用 bean
userController.doUserController();
}
}此时获取 bean 对象时就不再是通过传统的 id 标识来获取了. 使用注解存储对象, 获取对象时候, 它的命名规则默认是 "类名小驼峰", 例如 UserController -> userController .
此时运行程序, 可以发现我们是可以正常拿到 bean 对象的, 其他类注解也是一样, 只需要两步: 1. 配置扫描路径 2. 在需要存储的 bean 对象的相关类上加上注解.
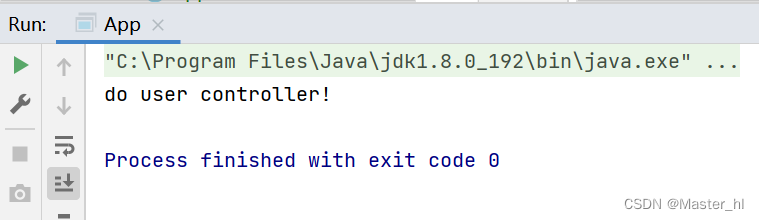
【问题】扫描路径的做法是否可以和 <bean> 标签混用使用 ?
当配置文件的扫描路径外的其他包下有一个类也是需要注册到 Spring 中的时候, 这时候我们试试以 <bean> 标签的做法来存储对象和扫描路径能不能混合使用:
【配置文件】
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:content="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<content:component-scan base-package="com.hl.controller"></content:component-scan>
<bean id="userRepository" class="com.hl.repository.UserRepository"></bean>
</beans>【启动类】
public class App {
public static void main(String[] args) {
// 1. 得到 Spring 上下文
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2. 获取 bean 对象
UserController userController =
context.getBean("userController", UserController.class);
UserRepository userRepository =
context.getBean("userRepository", UserRepository.class);
// 3. 使用 bean
userController.doUserController();
userRepository.doUserRepository();
}
}【com.hl.repository.UserRepository.java】此处是没有加类注解的。
public class UserRepository {
public void doUserRepository() {
System.out.println("do user repository!");
}
}运行程序时, 发现依旧可以正常获取到 bean 对象::
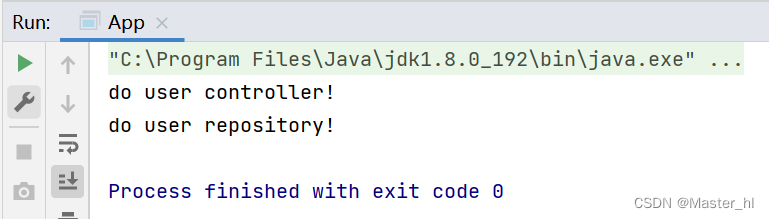
【结论】配置扫描路径的方式可以和 <bean> 标签的方式混合使用!!
【问题】既然这些注解的用法都大致相同, 那为什么需要这么搞五个注解, 而不是用一个就行了呢 ?
这就好比小作坊时代和工厂时代的区别一样, 在小作坊时代, 一般都是一个师傅啥都会, 而到了工厂时代, 一般都是分工明确的, 一个师傅一个岗位, 就做一件事, 做到极致. 软件开发也是一样, 越来越模块化, 各司其职, 并且在代码可读性的层面会有更加的体验 !! (查找和维护代码更加的方便和快捷).
【五大类注解各自 "岗位"】
- @Controller【控制器】 : 验证前端传递的参数【安全检查】
- @Service【服务】: 服务调用的编排和汇总
- @Repository【仓库】: 直接操作数据库
- @Component【组件】: 通用化的工具类
- @Configuration【配置】: 项目的所有配置
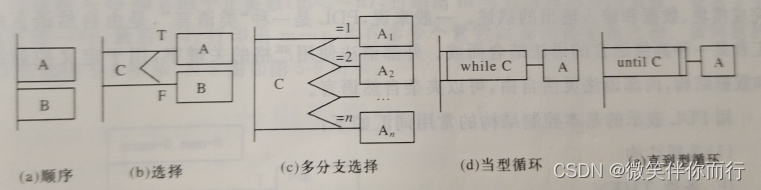
程序应用的分层流程图:

1.2.1 五大类注解之间的关系
要想知道五大类注解之间的关系, 就需要去分析这五大类注解的源码了:

【结论】
1. 通过查看类注解的底层源码时, 我们可以在 @Controller, @Service, @Repository, @Configuration 这四个类注解的源码上都可以看见一个 @Component 注解.
2. 由此可以得出结论, 在逻辑上可以认为 @Controller, @Service, @Repository, @Configuration 都是 @Component 的 "子类" , 都是基于 @Component 去扩充和拓展的, 并且它们的共同作用都是将 bean 存储在 Spring 中.
1.2.2 关于 bean 的命名规则
前面在讲以类注解的方式存储 bean 时, 我们在获取 bean 时, 它的命名规则默认是 "类名小驼峰",
【特殊情况】
但是还有一种特殊的情况, 当我们写出这样一个类名时 : UController, 或者 SController (UserController, StudentController 的简写). 此时 bean 的命名规则就不在是 "类名小驼峰" 了!!
【代码示例】
UController.java
@Controller
public class UController {
public void doUController() {
System.out.println("do U Controller");
}
}
启动类:
public class App {
public static void main(String[] args) {
// 1. 得到 Spring 上下文
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2. 获取 bean 对象
UController uController =
context.getBean("uController", UController.class);
// 3. 使用 bean
uController.doUController();
}
}当我运行程序时, 就会抛出以下异常:
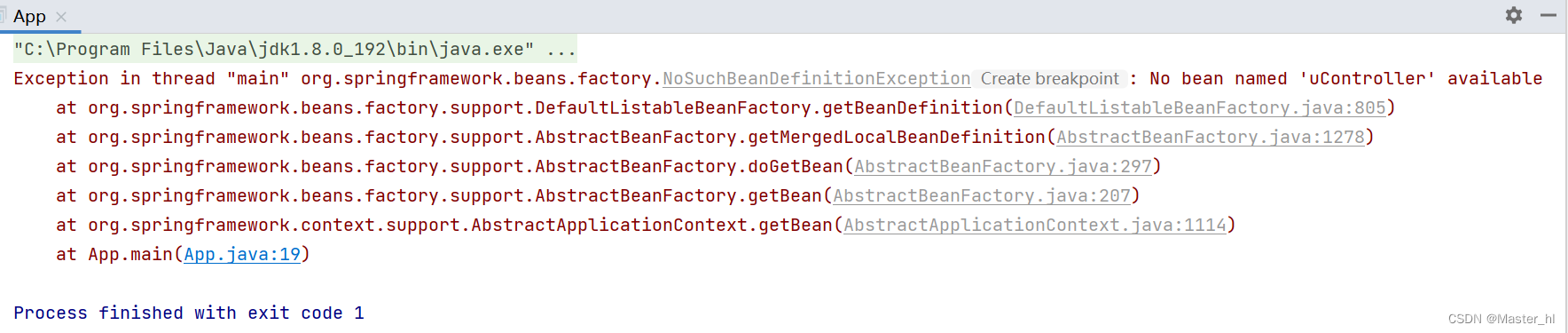
遇到这种特殊情况时, bean 的命名规则就不再是 "类名小驼峰" 了, 而是 "原类名".
【正确写法】
UController uController =
context.getBean("UController", UController.class);【结论】
1. 当类名首字母和第二个字母都是大写的情况, bean 的命名规则为 "原类名" !!
2. 对于这两种情况, 其实站在开发的角度上也是可以理解的, 我们在写项目的时候, 基本上是不会出现相同类名的情况, 所以无论是使用 "类名小驼峰" 还是 "原类名" 都是而已定义到唯一一个类的.
【问题】为什么是这样的结论? 我们去分析源码:
1. 在 IDEA 中双击 shift, 打开搜索框输入 beanName, 找到 AnnotationBeanNameGenerator 类, 去找下面的方法.
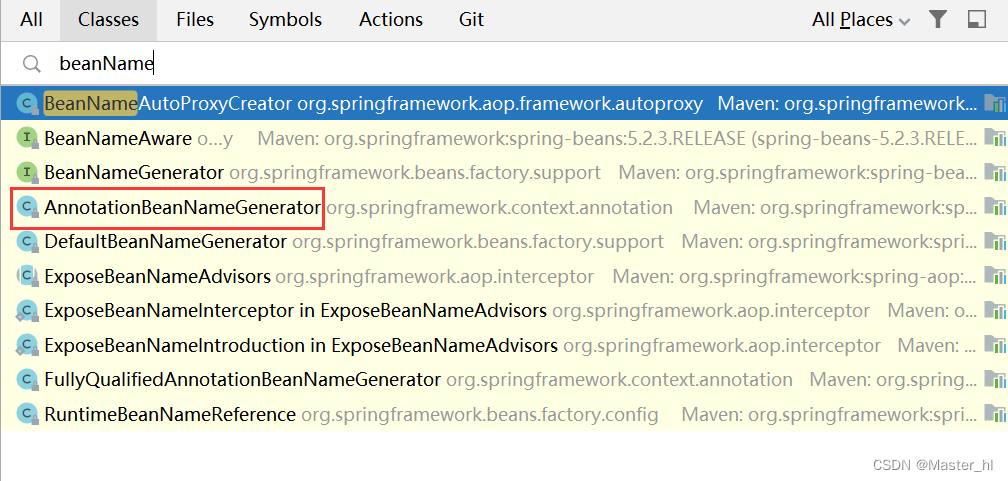
2. 找到 buildDefaultBeanName() 方法, 继续往下去找它调用的方法..
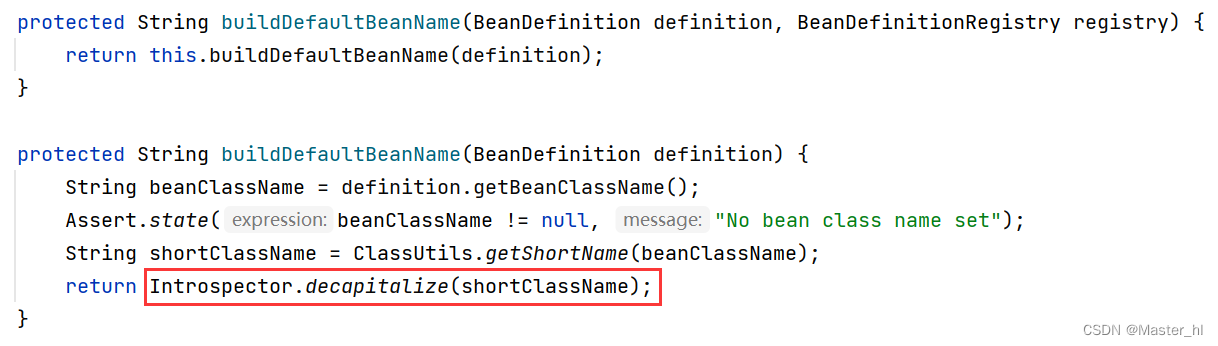
3. 分析关键源码:
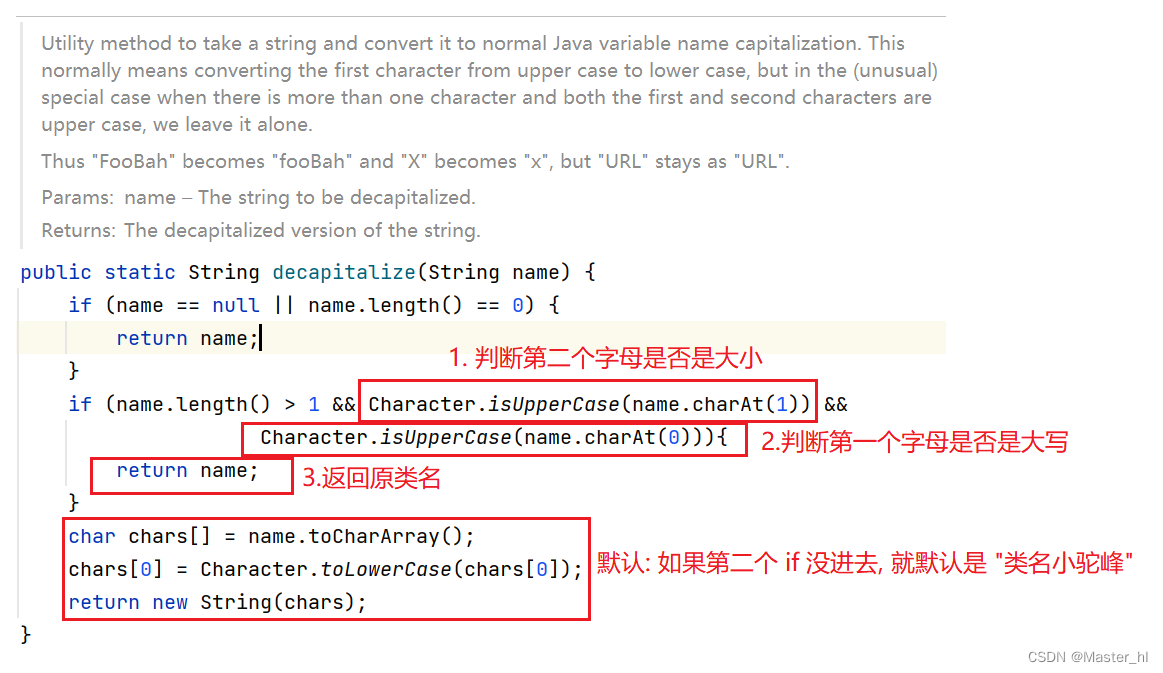
我们还可以自己分两种情况去写代码验证真伪:
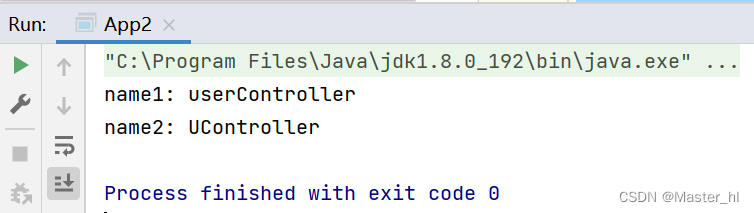
【代码示例】
public class App2 {
public static void main(String[] args) {
String name1 = "UserController";
String name2 = "UController";
// 类名小驼峰
System.out.println("name1: " + Introspector.decapitalize(name1));
// 原类名
System.out.println("name2: " + Introspector.decapitalize(name2));
}
}
运行结果: (进一步验证了上述结论)
1.3 使用方法注解存储 bean 对象
使用方法注解存储 bean 有三个注意事项:
- @bean 注解一定要搭配五大类注解使用.
- 使用 @bean 注解时, bean 的命名规则是 @bean注解方法名.
- @Bean 注解只能使用在无参的方法上, 因为 Spring 初始化存储时, 无法提供相应参数.
【代码示例】
bean 类
public class User {
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
测试数据类
@Controller
public class UserBean {
@Bean
public User user1() {
// 构造测试数据
User user = new User();
user.setId(1);
user.setName("张三");
user.setId(19);
return user;
}
}启动类
public class App {
public static void main(String[] args) {
// 1. 得到 Spring 上下文
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2. 获取 bean 对象
User user = context.getBean("user1", User.class);
// 3. 使用 bean
System.out.println("userId: " + user.getId());
System.out.println("userName: " + user.getName());
}
}
运行结果:

【问题】为什么使用 @Bean 注解的时候, 命名规则是方法名? 为什么需要搭配五大类注解使用?
这又得回到我们前面所配置的文件扫描路径, 为什么要精细的配置文件扫描路径, 就是为了在加载的时候有针对性的去扫描加了类注解的类, 缩小了扫描范围, 而不是大海捞针. 此处也是一样.
【理由】
为什么要搭配五大类注解?
- 为了提升程序的性能, 我只扫描加了类注解的方法, 从这些方法中去找哪些方法加了 @Bean 注解.
为什么命名规则是方法名?
- 当我有多个方法返回同一个类型的对象时, 如果还按照类注解的方式去取对象, 此时就无法区分我要获取的是哪一个对象. 那有有人会说方法名也可能相同啊! 方法名确实存在相同的可能性, 但是返回类型相同的概率一定是比方法名相同的概率大很多的, 所以选择最优的策略 (方法名命名)
1.3.1 bean 的重命名
如果我们的方法真的重名了, 我们该怎么处理? 比如我不同类下有两个方法名, 返回类型都相同的类型, 那我再按照前面的方式去读取, 会发生什么的事情?
代码就不重复展示了, 简单梳理: 当我在 controller 包下再创建一个 UserBean2 类, 该类和 UserBean1 在同一个包下, 并且他们都有一个相同方法名, 相同返回类型的 user() 方法, 那么此时按照前面的步骤去读取对象的时候, 它只能读到前面 UserBean1 中的 user 对象, 我 UserBean2 也是同样的返回类型, 同样的方法名却读不到, 这显然不合理.
该如何解决?
这时候就有两种手段来解决:
- 修改方法名, 不要让方法重名 (不推荐)
- 重命名 bean (更优雅)
当我就是不想修改方法名的时候, 这时候我们可以重命名 bean , 来区分两个相同的方法.
(重命名 bean 时, 它有两个方法, 一个是 name ,一个是 value , 效果都是一样的. )
【代码示例】
@Controller
public class UserBean2 {
// 重命名 bean
@Bean(name = "user2")
public User user1() {
// 构造测试数据
User user = new User();
user.setId(1);
user.setName("userBean2: 李四");
user.setId(19);
return user;
}
}
UserBean1 中测试数据是张三, UserBean2 中测试数据是李四, 此时运行启动类:
public class App {
public static void main(String[] args) {
// 1. 得到 Spring 上下文
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2. 获取 bean 对象
User user = context.getBean("user2", User.class);
// 3. 使用 bean
System.out.println("userId: " + user.getId());
System.out.println("userName: " + user.getName());
}
}
运行结果:(由此可以看出重命名 bean 确实解决了方法名相同的问题)

重命名 bean 的三种典型写法:
写法一:
@Bean(name = "user2")写法二:
@Bean("user2")写法三:
@Bean(name = {"Bean_user1"}) // 可以有一个名字
@Bean(name = {"Bean_user1, Bean_user2"}) // 也可以有多个名字重命名 bean 后的注意事项:
重命名后的 bean , 再使用原来的方法名就无法获取到 bean 对象了!
2. 更加简单的获取对象 (DI)
获取对象 (UserService) 的三部曲:
1. 最早: new UserService();
2. Spring时代: a. 得到 Spring 对象 b.使用 getBean() 读取到 UserService 对象.
3. 更加简单的读取方式: 对象注入(a. 属性注入 b. Setter 注入 c. 构造方法注入)
获取 bean 对象也叫作对象注入(对象装配 / 依赖注入), 对象注入有三种方式:
- 属性注入 (Field Injection)
- Setter 注入(Setter Injection)
- 构造方法注入(Constructor Injection)
2.1 属性注入
例子: 在 controller 包下的 UserController 类中注入 service 包下的 UserService 对象:
此时我们的扫描配置文件路径要涵盖这两个包, 不然无法将对象注册到 Spring 中.
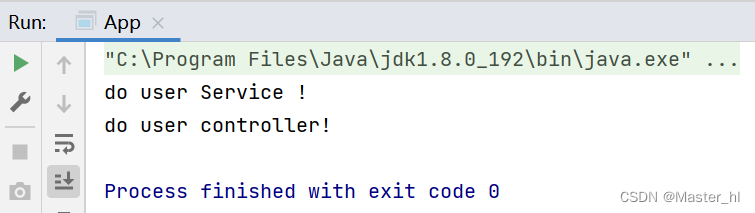
【代码示例】
@Controller
public class UserController {
@Autowired
private UserService userService;
public void doUserController() {
userService.doUserService();
System.out.println("do user controller!");
}
}启动类:
public class App {
public static void main(String[] args) {
// 1. 得到 Spring 上下文
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2. 获取 bean 对象
UserController userController =
context.getBean("userController", UserController.class);
// 3. 使用 bean
userController.doUserController();
}
}
运行结果:
【问题】既然属性注入对象这么方便, 那我们为什么在启动类中不这么用呢 ?
当我们写出这样一个代码时:
public class App {
@Autowired
private UserController userController;
public static void main(String[] args) {
userController.doUserController();
}
}IDEA 就会报错, 为什么呢?
是因为 static 方法执行时机比 Spring 执行时机较早, 所以我们的 main 方法中的 userController 还没来及加载就去使用肯定就会报错!!
【问题】注入对象的时候, bean 的名称是否也要遵循五大类注解的默认命名方式呢?
我能否随意命名?
@Autowired
private UserService aaa;
答案是可以随便命名的. 因为我们的 Autowired 注解比较强大, 当对象在自动装配的时候, 它会先根据类型查询, 再根据名称查询, 所以不管你如何命名, 它都是能够找到这个对象的.
2.1.1 属性注入优缺点分析
优点: 实现简单, 使用简单
缺点: 首先官方就不推荐使用, 专业版 IDAE 会报警告提示.
- 功能方面的问题: 无法注入一个被 final 修饰的对象
- 通用性方面的问题: 只适用于 IoC 容器
- 设计原则方面的问题: 更加容易违背单一设计原则
🍁缺点一: 功能缺陷
属性注入无法注入一个不可变的对象.

【原因】
这和 Java 中 final 关键字的规定有关:
final 修饰的变量:
- 使用时直接赋值
- 通过构造方法赋值
🍁缺点二:通用性缺陷
属性注入的方式只适用于 IoC 容器, 在非 IoC 框架中使用不了, 可移植性不高, 所以属性注入的通用性不是很好.
🍁缺点三: 设计原则上的缺陷
由于属性注入的写法相对来说非常简单, 所以就会导致属性注入这种方式滥用的概率就越大, 所以更容易违背单一设计原则. 第三个缺点是一个概率问题, 并不是说它百分百会违背单一设计原则.
2.2 Setter 注入
Setter 注入就和属性的 Setter 方法是一样的, 只不过需要在方法上加上一个 @Autowired 注解.
【代码示例】
@Controller
public class UserController {
private UserService userService;
@Autowired
public void setUserService(UserService userService) {
this.userService = userService;
}
public void doUserController() {
userService.doUserService();
System.out.println("do user controller!");
}
}
程序运行照样是能正常打印出结果的.
2.2.1 Setter 注入优缺点分析
优点: Setter 注入完全符合单一设计原则, 一个 Setter 方法只针对一个对象.
缺点: 两大缺点.
- 不能注入 final 修饰的对象.
- 注入的对象有被修改的风险. (可被修改).
🍁缺点一: 不能注入 final 修饰的对象
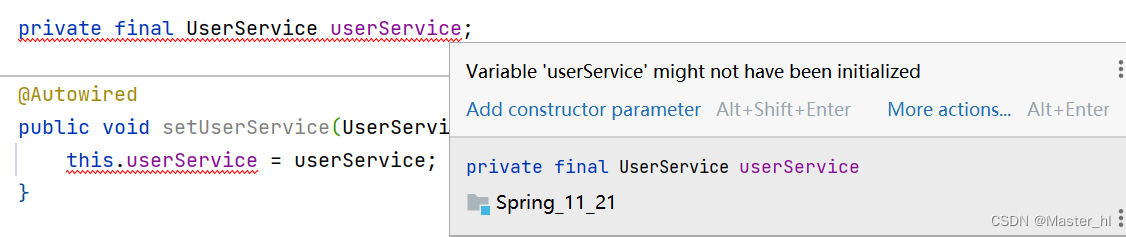
原因和属性注入一样, 都和 final 关键字的规定有关: 要么使用时直接赋值, 要么在构造方法中赋值.
🍁缺点二: 注入的对象可被修改
因为 Setter 注入提供了 setXXX() 方法, 就意味着 setXXX() 可以被调用多次, 所以在任何地方都有可能调用了 setXXX() 方法, 所以 Setter 注入的对象随时都有被修改的风险.
2.3 构造方法注入
【代码示例】
@Controller
public class UserController {
private UserService userService;
@Autowired
public UserController(UserService userService) {
this.userService = userService;
}
public void doUserController() {
userService.doUserService();
System.out.println("do user controller!");
}
}使用构造方法注入, 当只有一个构造法方式时, @Autowired 注解是可以省略的.
省略了运行程序依旧可以正常打印结果:
@Controller
public class UserController {
private UserService userService;
public UserController(UserService userService) {
this.userService = userService;
}
public void doUserController() {
userService.doUserService();
System.out.println("do user controller!");
}
}
运行结果:

2.3.1 构造方法注入优点分析
四大优点:
- 优点一: 可以注入不可变对象 (final 修饰的对象).
- 优点二: 注入的对象不会被修改
- 优点三: 依赖对象在使用前一定会被完全初始化.
- 优点四: 通用性更好.
🍁优点一: 可以注入不可变对象.
@Controller
public class UserController {
private final UserService userService;
@Autowired
public UserController(UserService userService) {
this.userService = userService;
}
public void doUserController() {
userService.doUserService();
System.out.println("do user controller!");
}
}当我们写出以上代码时, IDEA 不会报错, 并且程序运行能正确显示结果.
🍁优点二: 注入的对象不会被修改
构造方法注入, 在程序执行的时候, 它只会执行一次, 所以不会像 Setter 注入那样被调用多次, 也就不存在被修改的情况.
🍁优点三: 对象完全初始
由于我们要注入的对象的过程是在构造方法中执行的, 而构造方法的执行时间要比累的创建时机早, 所以我们要使用的注入的对象, 一定是被完全初始化的.
🍁优点四: 通用性更好
构造方法是 JDK 支持的, 往往越底层的框架, 它的可移植性就越好, 所以换做其他任何框架都是适用的.
2.4 三种注入方式场景分析
- 属性注入; 如果你只是简单的场景, 只需要使用一次, 你可以使用属性注入.
- Setter 注入: 如果你的应用场景更倾向于要符合单一设计原则, 那么你可以考虑使用 Setter 注入.
- 构造方法注入: 如果你想要通用性, 可移植性更好, 那么你可以选择构造方法注入.
依赖注入 -> 官方推荐用法:
Spring 4.2 之前, 官方推荐使用 Setter 注入, 更侧重于单一设计原则.
Spring 4.2 之后, 官方推荐使用 构造方法注入.